 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
On the Effectiveness of Speech Self-supervised Learning for Music
Jul 11, 2023
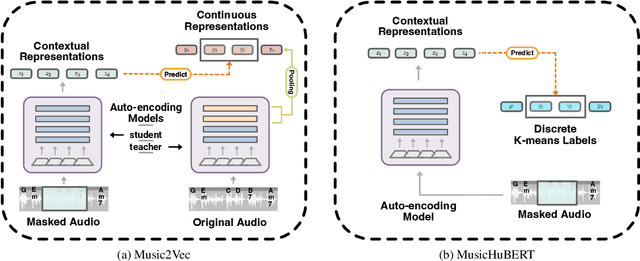
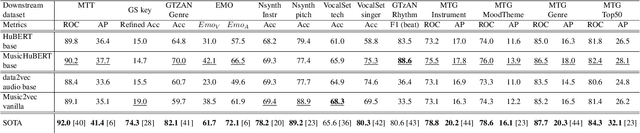

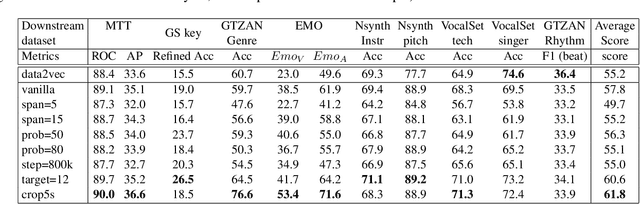
Self-supervised learning (SSL) has shown promising results in various speech and natural language processing applications. However, its efficacy in music information retrieval (MIR) still remains largely unexplored. While previous SSL models pre-trained on music recordings may have been mostly closed-sourced, recent speech models such as wav2vec2.0 have shown promise in music modelling. Nevertheless, research exploring the effectiveness of applying speech SSL models to music recordings has been limited. We explore the music adaption of SSL with two distinctive speech-related models, data2vec1.0 and Hubert, and refer to them as music2vec and musicHuBERT, respectively. We train $12$ SSL models with 95M parameters under various pre-training configurations and systematically evaluate the MIR task performances with 13 different MIR tasks. Our findings suggest that training with music data can generally improve performance on MIR tasks, even when models are trained using paradigms designed for speech. However, we identify the limitations of such existing speech-oriented designs, especially in modelling polyphonic information. Based on the experimental results, empirical suggestions are also given for designing future musical SSL strategies and paradigms.
Optimizing Feature Extraction for Symbolic Music
Jul 11, 2023
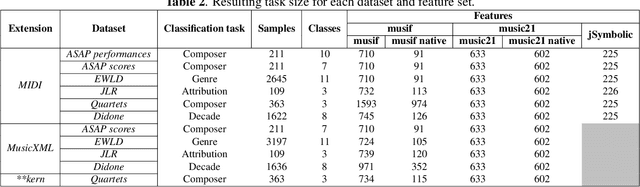
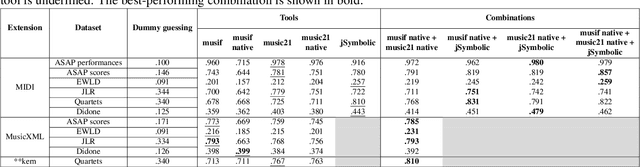
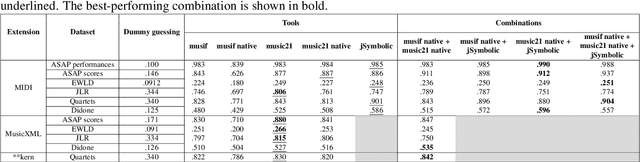
This paper presents a comprehensive investigation of existing feature extraction tools for symbolic music and contrasts their performance to determine the set of features that best characterizes the musical style of a given music score. In this regard, we propose a novel feature extraction tool, named musif, and evaluate its efficacy on various repertoires and file formats, including MIDI, MusicXML, and **kern. Musif approximates existing tools such as jSymbolic and music21 in terms of computational efficiency while attempting to enhance the usability for custom feature development. The proposed tool also enhances classification accuracy when combined with other sets of features. We demonstrate the contribution of each set of features and the computational resources they require. Our findings indicate that the optimal tool for feature extraction is a combination of the best features from each tool rather than those of a single one. To facilitate future research in music information retrieval, we release the source code of the tool and benchmarks.
Music Mode: Transforming Robot Movement into Music Increases Likability and Perceived Intelligence
Jun 05, 2023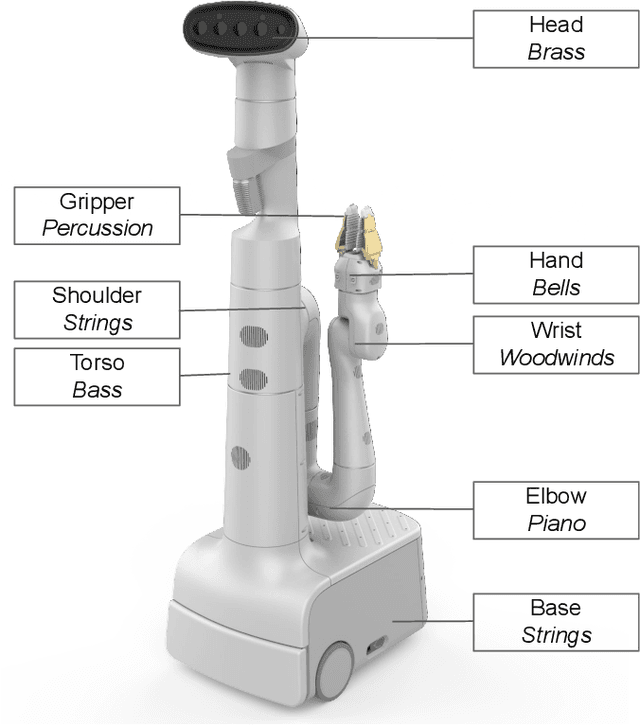
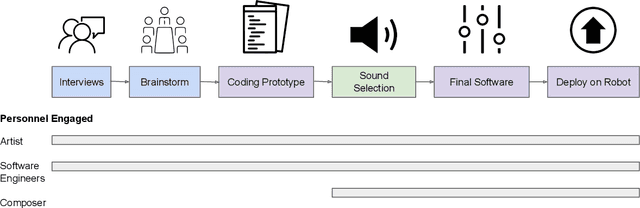
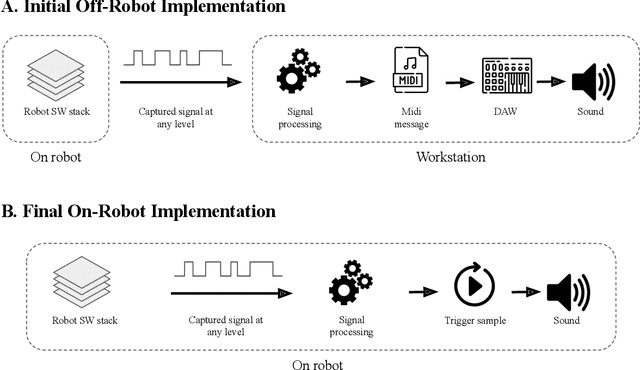
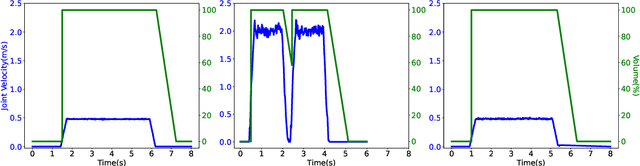
As robots enter everyday spaces like offices, the sounds they create affect how they are perceived. We present "Music Mode", a novel mapping between a robot's joint motions and sounds, programmed by artists and engineers to make the robot generate music as it moves. Two experiments were designed to characterize the effect of this musical augmentation on human users. In the first experiment, a robot performed three tasks while playing three different sound mappings. Results showed that participants observing the robot perceived it as more safe, animate, intelligent, anthropomorphic, and likable when playing the Music Mode Orchestral software. To test whether the results of the first experiment were due to the Music Mode algorithm, rather than music alone, we conducted a second experiment. Here the robot performed the same three tasks, while a participant observed via video, but the Orchestral music was either linked to its movement or random. Participants rated the robots as more intelligent when the music was linked to the movement. Robots using Music Mode logged approximately two hundred hours of operation while navigating, wiping tables, and sorting trash, and bystander comments made during this operating time served as an embedded case study. The contributions are: (1) an interdisciplinary choreographic, musical, and coding design process to develop a real-world robot sound feature, (2) a technical implementation for movement-based sound generation, and (3) two experiments and an embedded case study of robots running this feature during daily work activities that resulted in increased likeability and perceived intelligence of the robot.
From West to East: Who can understand the music of the others better?
Jul 19, 2023Recent developments in MIR have led to several benchmark deep learning models whose embeddings can be used for a variety of downstream tasks. At the same time, the vast majority of these models have been trained on Western pop/rock music and related styles. This leads to research questions on whether these models can be used to learn representations for different music cultures and styles, or whether we can build similar music audio embedding models trained on data from different cultures or styles. To that end, we leverage transfer learning methods to derive insights about the similarities between the different music cultures to which the data belongs to. We use two Western music datasets, two traditional/folk datasets coming from eastern Mediterranean cultures, and two datasets belonging to Indian art music. Three deep audio embedding models are trained and transferred across domains, including two CNN-based and a Transformer-based architecture, to perform auto-tagging for each target domain dataset. Experimental results show that competitive performance is achieved in all domains via transfer learning, while the best source dataset varies for each music culture. The implementation and the trained models are both provided in a public repository.
Deriving Comprehensible Theories from Probabilistic Circuits
Nov 22, 2023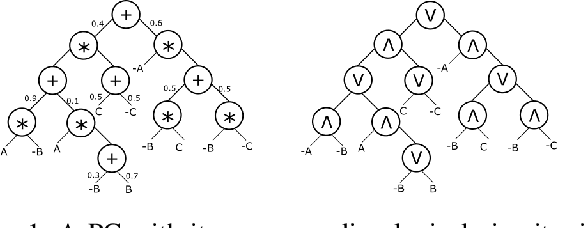

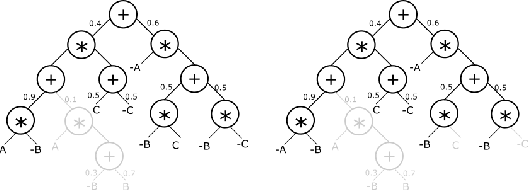

The field of Explainable AI (XAI) is seeking to shed light on the inner workings of complex AI models and uncover the rationale behind their decisions. One of the models gaining attention are probabilistic circuits (PCs), which are a general and unified framework for tractable probabilistic models that support efficient computation of various probabilistic queries. Probabilistic circuits guarantee inference that is polynomial in the size of the circuit. In this paper, we improve the explainability of probabilistic circuits by computing a comprehensible, readable logical theory that covers the high-density regions generated by a PC. To achieve this, pruning approaches based on generative significance are used in a new method called PUTPUT (Probabilistic circuit Understanding Through Pruning Underlying logical Theories). The method is applied to a real world use case where music playlists are automatically generated and expressed as readable (database) queries. Evaluation shows that this approach can effectively produce a comprehensible logical theory that describes the high-density regions of a PC and outperforms state of the art methods when exploring the performance-comprehensibility trade-off.
Stack-and-Delay: a new codebook pattern for music generation
Sep 15, 2023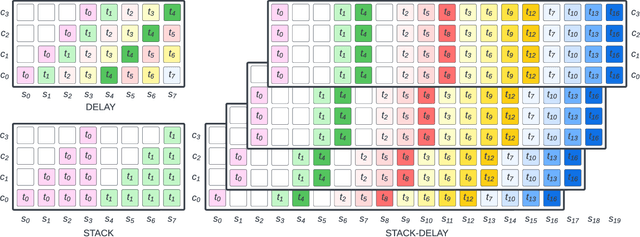
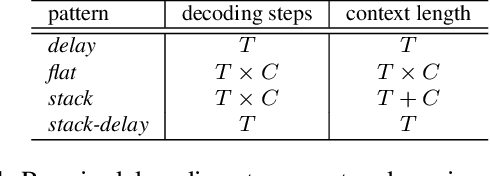
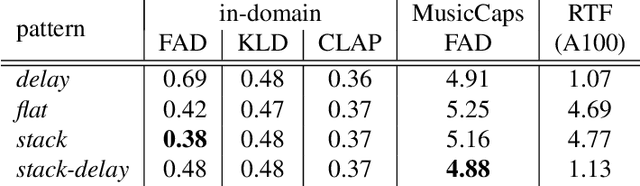
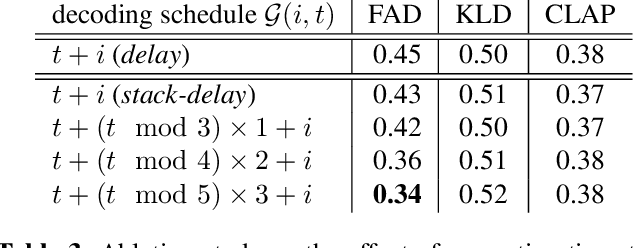
In language modeling based music generation, a generated waveform is represented by a sequence of hierarchical token stacks that can be decoded either in an auto-regressive manner or in parallel, depending on the codebook patterns. In particular, flattening the codebooks represents the highest quality decoding strategy, while being notoriously slow. To this end, we propose a novel stack-and-delay style of decoding strategy to improve upon the flat pattern decoding where generation speed is four times faster as opposed to vanilla flat decoding. This brings the inference time close to that of the delay decoding strategy, and allows for faster inference on GPU for small batch sizes. For the same inference efficiency budget as the delay pattern, we show that the proposed approach performs better in objective evaluations, almost closing the gap with the flat pattern in terms of quality. The results are corroborated by subjective evaluations which show that samples generated by the new model are slightly more often preferred to samples generated by the competing model given the same text prompts.
Advancements in Generative AI: A Comprehensive Review of GANs, GPT, Autoencoders, Diffusion Model, and Transformers
Nov 21, 2023The launch of ChatGPT has garnered global attention, marking a significant milestone in the field of Generative Artificial Intelligence. While Generative AI has been in effect for the past decade, the introduction of ChatGPT has ignited a new wave of research and innovation in the AI domain. This surge in interest has led to the development and release of numerous cutting-edge tools, such as Bard, Stable Diffusion, DALL-E, Make-A-Video, Runway ML, and Jukebox, among others. These tools exhibit remarkable capabilities, encompassing tasks ranging from text generation and music composition, image creation, video production, code generation, and even scientific work. They are built upon various state-of-the-art models, including Stable Diffusion, transformer models like GPT-3 (recent GPT-4), variational autoencoders, and generative adversarial networks. This advancement in Generative AI presents a wealth of exciting opportunities and, simultaneously, unprecedented challenges. Throughout this paper, we have explored these state-of-the-art models, the diverse array of tasks they can accomplish, the challenges they pose, and the promising future of Generative Artificial Intelligence.
Track Mix Generation on Music Streaming Services using Transformers
Jul 06, 2023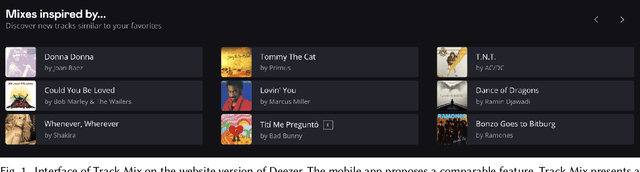
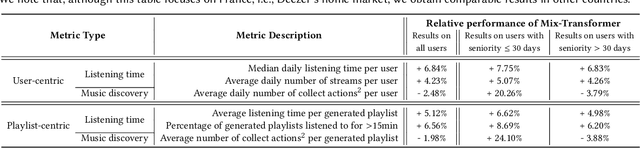
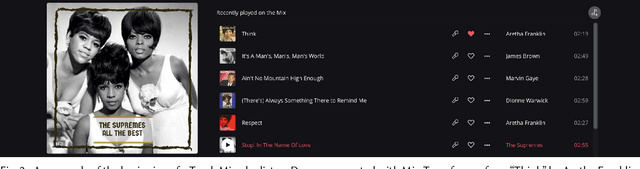
This paper introduces Track Mix, a personalized playlist generation system released in 2022 on the music streaming service Deezer. Track Mix automatically generates "mix" playlists inspired by initial music tracks, allowing users to discover music similar to their favorite content. To generate these mixes, we consider a Transformer model trained on millions of track sequences from user playlists. In light of the growing popularity of Transformers in recent years, we analyze the advantages, drawbacks, and technical challenges of using such a model for mix generation on the service, compared to a more traditional collaborative filtering approach. Since its release, Track Mix has been generating playlists for millions of users daily, enhancing their music discovery experience on Deezer.
Graph Variational Embedding Collaborative Filtering
Nov 20, 2023The customization of recommended content to users holds significant importance in enhancing user experiences across a wide spectrum of applications such as e-commerce, music, and shopping. Graph-based methods have achieved considerable performance by capturing user-item interactions. However, these methods tend to utilize randomly constructed embeddings in the dataset used for training the recommender, which lacks any user preferences. Here, we propose the concept of variational embeddings as a means of pre-training the recommender system to improve the feature propagation through the layers of graph convolutional networks (GCNs). The graph variational embedding collaborative filtering (GVECF) is introduced as a novel framework to incorporate representations learned through a variational graph auto-encoder which are embedded into a GCN-based collaborative filtering. This approach effectively transforms latent high-order user-item interactions into more trainable vectors, ultimately resulting in better performance in terms of recall and normalized discounted cumulative gain(NDCG) metrics. The experiments conducted on benchmark datasets demonstrate that our proposed method achieves up to 13.78% improvement in the recall over the test data.
DiVa: An Iterative Framework to Harvest More Diverse and Valid Labels from User Comments for Music
Aug 09, 2023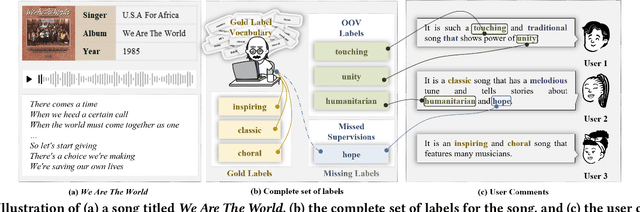

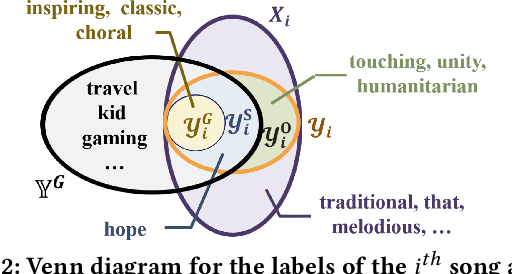
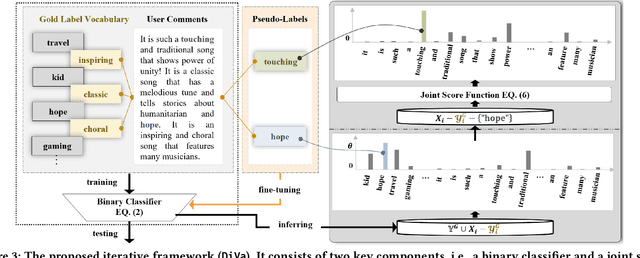
Towards sufficient music searching, it is vital to form a complete set of labels for each song. However, current solutions fail to resolve it as they cannot produce diverse enough mappings to make up for the information missed by the gold labels. Based on the observation that such missing information may already be presented in user comments, we propose to study the automated music labeling in an essential but under-explored setting, where the model is required to harvest more diverse and valid labels from the users' comments given limited gold labels. To this end, we design an iterative framework (DiVa) to harvest more $\underline{\text{Di}}$verse and $\underline{\text{Va}}$lid labels from user comments for music. The framework makes a classifier able to form complete sets of labels for songs via pseudo-labels inferred from pre-trained classifiers and a novel joint score function. The experiment on a densely annotated testing set reveals the superiority of the Diva over state-of-the-art solutions in producing more diverse labels missed by the gold labels. We hope our work can inspire future research on automated music labeling.