 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
LaunchpadGPT: Language Model as Music Visualization Designer on Launchpad
Jul 07, 2023


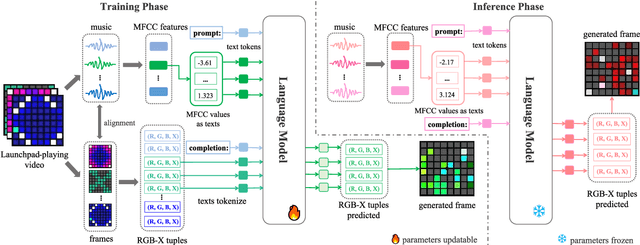
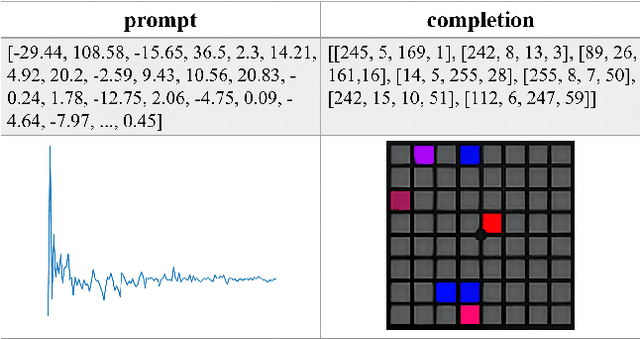
Launchpad is a musical instrument that allows users to create and perform music by pressing illuminated buttons. To assist and inspire the design of the Launchpad light effect, and provide a more accessible approach for beginners to create music visualization with this instrument, we proposed the LaunchpadGPT model to generate music visualization designs on Launchpad automatically. Based on the language model with excellent generation ability, our proposed LaunchpadGPT takes an audio piece of music as input and outputs the lighting effects of Launchpad-playing in the form of a video (Launchpad-playing video). We collect Launchpad-playing videos and process them to obtain music and corresponding video frame of Launchpad-playing as prompt-completion pairs, to train the language model. The experiment result shows the proposed method can create better music visualization than random generation methods and hold the potential for a broader range of music visualization applications. Our code is available at https://github.com/yunlong10/LaunchpadGPT/.
A Distributed Algorithm for Personal Sound Zones Systems
Nov 21, 2023A Personal Sound Zones (PSZ) system aims to generate two or more independent listening zones that allow multiple users to listen to different music/audio content in a shared space without the need for wearing headphones. Most existing studies assume that the acoustic paths between loudspeakers and microphones are measured beforehand in a stationary environment. Recently, adaptive PSZ systems have been explored to adapt the system in a time-varying acoustic environment. However, because a PSZ system usually requires multiple loudspeakers, the multichannel adaptive algorithms impose a high computational load on the processor. To overcome that problem, this paper proposes an efficient distributed algorithm for PSZ systems, which not only spreads the computational burden over multiple nodes but also reduces the overall computational complexity, at the expense of a slight decrease in performance. Simulation results with true room impulse responses measured in a Hemi-Anechoic chamber are performed to verify the proposed distributed PSZ system.
ChoralSynth: Synthetic Dataset of Choral Singing
Nov 14, 2023Choral singing, a widely practiced form of ensemble singing, lacks comprehensive datasets in the realm of Music Information Retrieval (MIR) research, due to challenges arising from the requirement to curate multitrack recordings. To address this, we devised a novel methodology, leveraging state-of-the-art synthesizers to create and curate quality renditions. The scores were sourced from Choral Public Domain Library(CPDL). This work is done in collaboration with a diverse team of musicians, software engineers and researchers. The resulting dataset, complete with its associated metadata, and methodology is released as part of this work, opening up new avenues for exploration and advancement in the field of singing voice research.
Music Generation based on Generative Adversarial Networks with Transformer
Sep 16, 2023
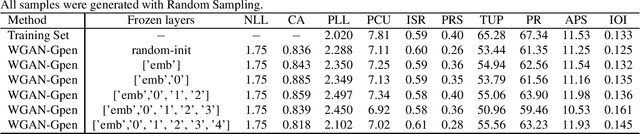
Autoregressive models based on Transformers have become the prevailing approach for generating music compositions that exhibit comprehensive musical structure. These models are typically trained by minimizing the negative log-likelihood (NLL) of the observed sequence in an autoregressive manner. However, when generating long sequences, the quality of samples from these models tends to significantly deteriorate due to exposure bias. To address this issue, we leverage classifiers trained to differentiate between real and sampled sequences to identify these failures. This observation motivates our exploration of adversarial losses as a complement to the NLL objective. We employ a pre-trained Span-BERT model as the discriminator in the Generative Adversarial Network (GAN) framework, which enhances training stability in our experiments. To optimize discrete sequences within the GAN framework, we utilize the Gumbel-Softmax trick to obtain a differentiable approximation of the sampling process. Additionally, we partition the sequences into smaller chunks to ensure that memory constraints are met. Through human evaluations and the introduction of a novel discriminative metric, we demonstrate that our approach outperforms a baseline model trained solely on likelihood maximization.
Deriving Comprehensible Theories from Probabilistic Circuits
Nov 22, 2023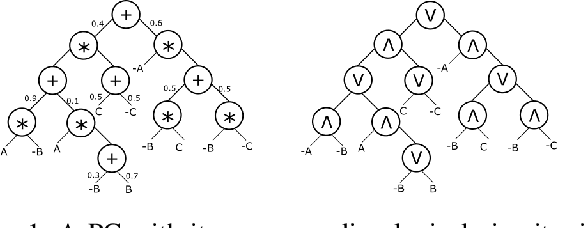

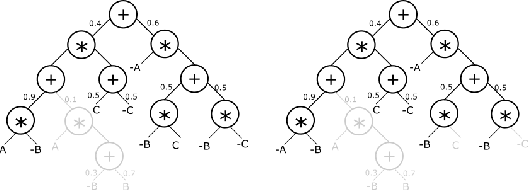

The field of Explainable AI (XAI) is seeking to shed light on the inner workings of complex AI models and uncover the rationale behind their decisions. One of the models gaining attention are probabilistic circuits (PCs), which are a general and unified framework for tractable probabilistic models that support efficient computation of various probabilistic queries. Probabilistic circuits guarantee inference that is polynomial in the size of the circuit. In this paper, we improve the explainability of probabilistic circuits by computing a comprehensible, readable logical theory that covers the high-density regions generated by a PC. To achieve this, pruning approaches based on generative significance are used in a new method called PUTPUT (Probabilistic circuit Understanding Through Pruning Underlying logical Theories). The method is applied to a real world use case where music playlists are automatically generated and expressed as readable (database) queries. Evaluation shows that this approach can effectively produce a comprehensible logical theory that describes the high-density regions of a PC and outperforms state of the art methods when exploring the performance-comprehensibility trade-off.
Bootstrapping Contrastive Learning Enhanced Music Cold-Start Matching
Aug 05, 2023We study a particular matching task we call Music Cold-Start Matching. In short, given a cold-start song request, we expect to retrieve songs with similar audiences and then fastly push the cold-start song to the audiences of the retrieved songs to warm up it. However, there are hardly any studies done on this task. Therefore, in this paper, we will formalize the problem of Music Cold-Start Matching detailedly and give a scheme. During the offline training, we attempt to learn high-quality song representations based on song content features. But, we find supervision signals typically follow power-law distribution causing skewed representation learning. To address this issue, we propose a novel contrastive learning paradigm named Bootstrapping Contrastive Learning (BCL) to enhance the quality of learned representations by exerting contrastive regularization. During the online serving, to locate the target audiences more accurately, we propose Clustering-based Audience Targeting (CAT) that clusters audience representations to acquire a few cluster centroids and then locate the target audiences by measuring the relevance between the audience representations and the cluster centroids. Extensive experiments on the offline dataset and online system demonstrate the effectiveness and efficiency of our method. Currently, we have deployed it on NetEase Cloud Music, affecting millions of users. Code will be released in the future.
* Accepted by WWW'2023
DISCO-10M: A Large-Scale Music Dataset
Jun 23, 2023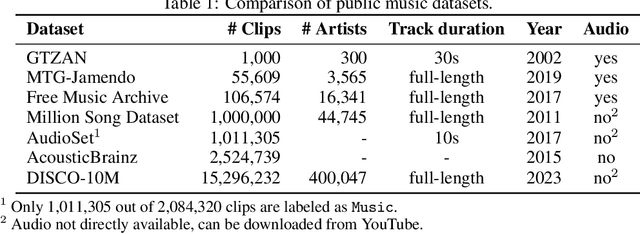
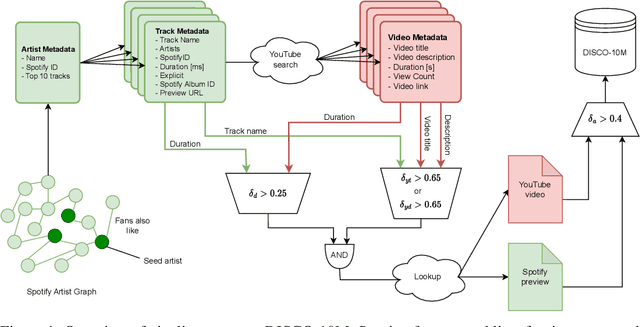
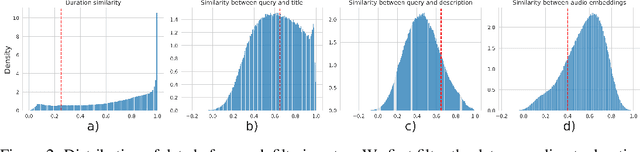
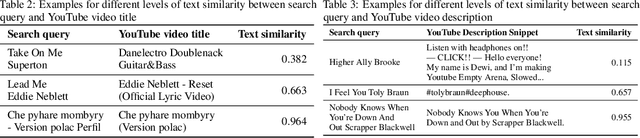
Music datasets play a crucial role in advancing research in machine learning for music. However, existing music datasets suffer from limited size, accessibility, and lack of audio resources. To address these shortcomings, we present DISCO-10M, a novel and extensive music dataset that surpasses the largest previously available music dataset by an order of magnitude. To ensure high-quality data, we implement a multi-stage filtering process. This process incorporates similarities based on textual descriptions and audio embeddings. Moreover, we provide precomputed CLAP embeddings alongside DISCO-10M, facilitating direct application on various downstream tasks. These embeddings enable efficient exploration of machine learning applications on the provided data. With DISCO-10M, we aim to democratize and facilitate new research to help advance the development of novel machine learning models for music.
Advancements in Generative AI: A Comprehensive Review of GANs, GPT, Autoencoders, Diffusion Model, and Transformers
Nov 21, 2023The launch of ChatGPT has garnered global attention, marking a significant milestone in the field of Generative Artificial Intelligence. While Generative AI has been in effect for the past decade, the introduction of ChatGPT has ignited a new wave of research and innovation in the AI domain. This surge in interest has led to the development and release of numerous cutting-edge tools, such as Bard, Stable Diffusion, DALL-E, Make-A-Video, Runway ML, and Jukebox, among others. These tools exhibit remarkable capabilities, encompassing tasks ranging from text generation and music composition, image creation, video production, code generation, and even scientific work. They are built upon various state-of-the-art models, including Stable Diffusion, transformer models like GPT-3 (recent GPT-4), variational autoencoders, and generative adversarial networks. This advancement in Generative AI presents a wealth of exciting opportunities and, simultaneously, unprecedented challenges. Throughout this paper, we have explored these state-of-the-art models, the diverse array of tasks they can accomplish, the challenges they pose, and the promising future of Generative Artificial Intelligence.
Emotion-Guided Music Accompaniment Generation Based on Variational Autoencoder
Jul 08, 2023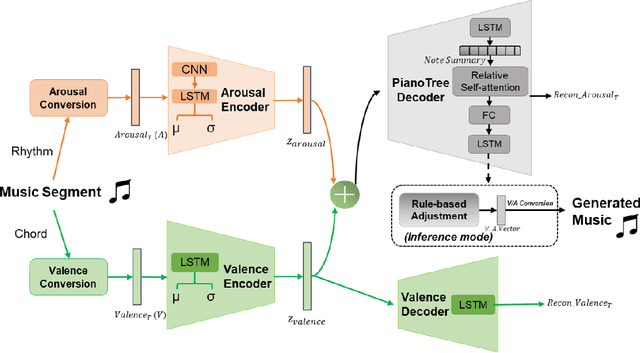
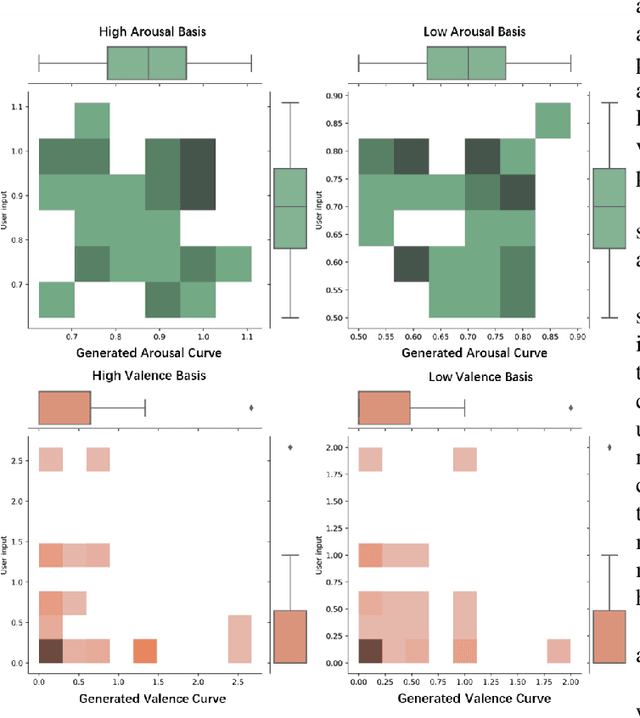
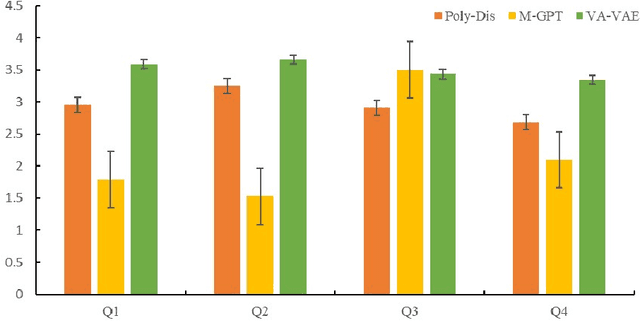
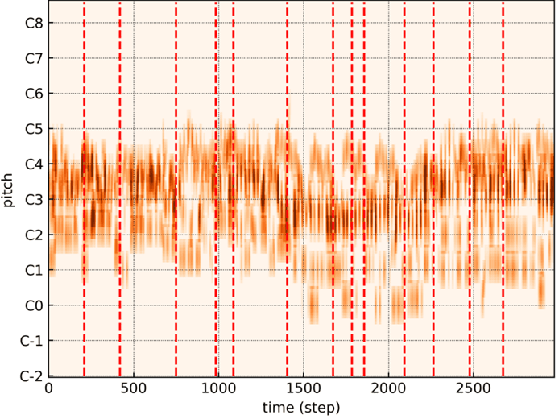
Music accompaniment generation is a crucial aspect in the composition process. Deep neural networks have made significant strides in this field, but it remains a challenge for AI to effectively incorporate human emotions to create beautiful accompaniments. Existing models struggle to effectively characterize human emotions within neural network models while composing music. To address this issue, we propose the use of an easy-to-represent emotion flow model, the Valence/Arousal Curve, which allows for the compatibility of emotional information within the model through data transformation and enhances interpretability of emotional factors by utilizing a Variational Autoencoder as the model structure. Further, we used relative self-attention to maintain the structure of the music at music phrase level and to generate a richer accompaniment when combined with the rules of music theory.
Graph Variational Embedding Collaborative Filtering
Nov 20, 2023The customization of recommended content to users holds significant importance in enhancing user experiences across a wide spectrum of applications such as e-commerce, music, and shopping. Graph-based methods have achieved considerable performance by capturing user-item interactions. However, these methods tend to utilize randomly constructed embeddings in the dataset used for training the recommender, which lacks any user preferences. Here, we propose the concept of variational embeddings as a means of pre-training the recommender system to improve the feature propagation through the layers of graph convolutional networks (GCNs). The graph variational embedding collaborative filtering (GVECF) is introduced as a novel framework to incorporate representations learned through a variational graph auto-encoder which are embedded into a GCN-based collaborative filtering. This approach effectively transforms latent high-order user-item interactions into more trainable vectors, ultimately resulting in better performance in terms of recall and normalized discounted cumulative gain(NDCG) metrics. The experiments conducted on benchmark datasets demonstrate that our proposed method achieves up to 13.78% improvement in the recall over the test data.