 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
A Review of Differentiable Digital Signal Processing for Music & Speech Synthesis
Aug 29, 2023
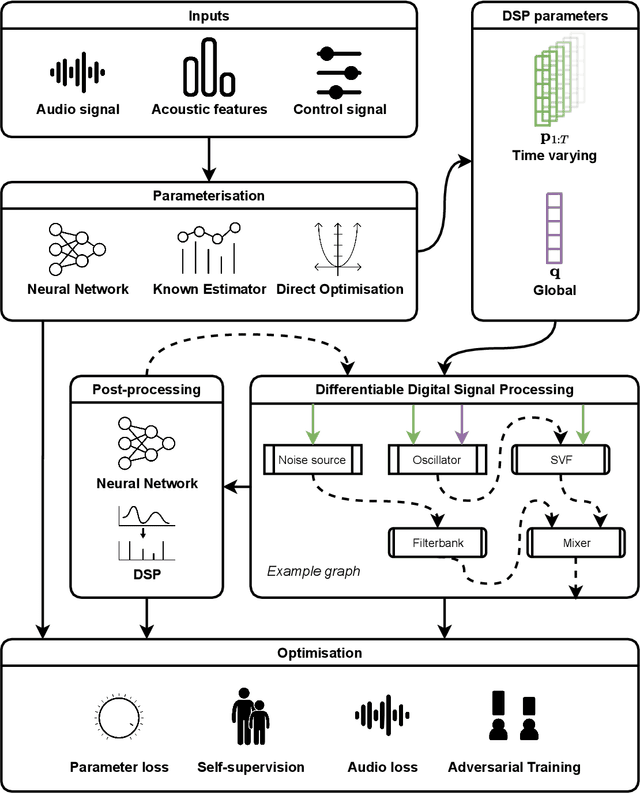
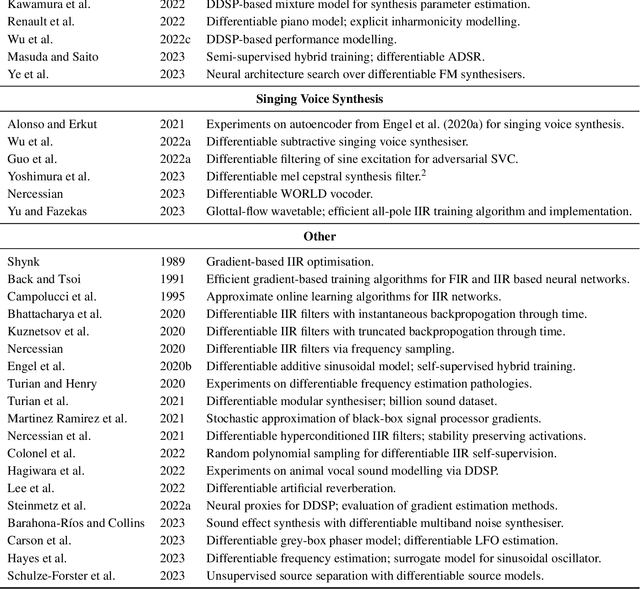
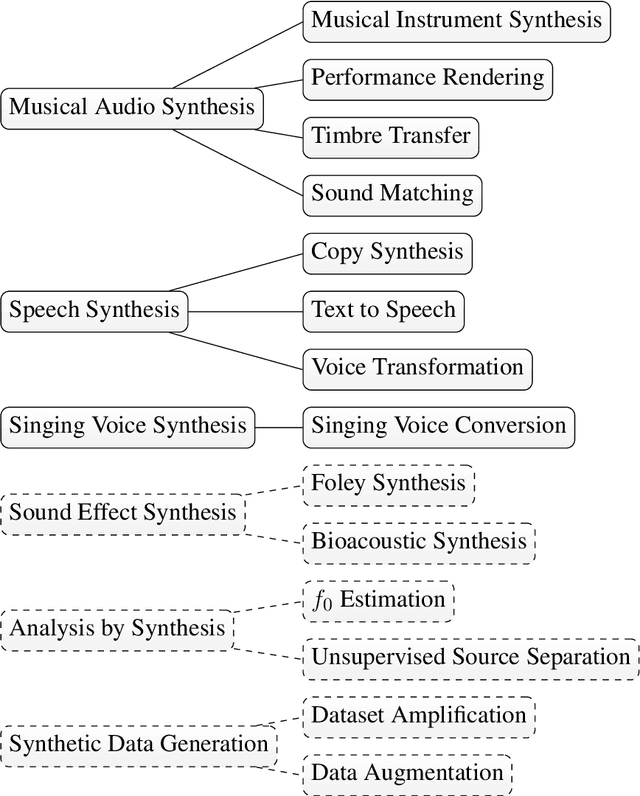
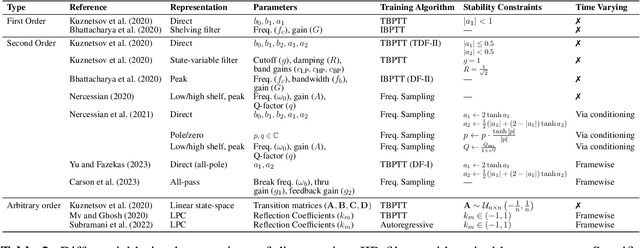
The term "differentiable digital signal processing" describes a family of techniques in which loss function gradients are backpropagated through digital signal processors, facilitating their integration into neural networks. This article surveys the literature on differentiable audio signal processing, focusing on its use in music & speech synthesis. We catalogue applications to tasks including music performance rendering, sound matching, and voice transformation, discussing the motivations for and implications of the use of this methodology. This is accompanied by an overview of digital signal processing operations that have been implemented differentiably. Finally, we highlight open challenges, including optimisation pathologies, robustness to real-world conditions, and design trade-offs, and discuss directions for future research.
Beat-Aligned Spectrogram-to-Sequence Generation of Rhythm-Game Charts
Nov 22, 2023In the heart of "rhythm games" - games where players must perform actions in sync with a piece of music - are "charts", the directives to be given to players. We newly formulate chart generation as a sequence generation task and train a Transformer using a large dataset. We also introduce tempo-informed preprocessing and training procedures, some of which are suggested to be integral for a successful training. Our model is found to outperform the baselines on a large dataset, and is also found to benefit from pretraining and finetuning.
Subnetwork-to-go: Elastic Neural Network with Dynamic Training and Customizable Inference
Dec 06, 2023Deploying neural networks to different devices or platforms is in general challenging, especially when the model size is large or model complexity is high. Although there exist ways for model pruning or distillation, it is typically required to perform a full round of model training or finetuning procedure in order to obtain a smaller model that satisfies the model size or complexity constraints. Motivated by recent works on dynamic neural networks, we propose a simple way to train a large network and flexibly extract a subnetwork from it given a model size or complexity constraint during inference. We introduce a new way to allow a large model to be trained with dynamic depth and width during the training phase, and after the large model is trained we can select a subnetwork from it with arbitrary depth and width during the inference phase with a relatively better performance compared to training the subnetwork independently from scratch. Experiment results on a music source separation model show that our proposed method can effectively improve the separation performance across different subnetwork sizes and complexities with a single large model, and training the large model takes significantly shorter time than training all the different subnetworks.
Neural Graph Collaborative Filtering Using Variational Inference
Dec 02, 2023The customization of recommended content to users holds significant importance in enhancing user experiences across a wide spectrum of applications such as e-commerce, music, and shopping. Graph-based methods have achieved considerable performance by capturing user-item interactions. However, these methods tend to utilize randomly constructed embeddings in the dataset used for training the recommender, which lacks any user preferences. Here, we propose the concept of variational embeddings as a means of pre-training the recommender system to improve the feature propagation through the layers of graph convolutional networks (GCNs). The graph variational embedding collaborative filtering (GVECF) is introduced as a novel framework to incorporate representations learned through a variational graph auto-encoder which are embedded into a GCN-based collaborative filtering. This approach effectively transforms latent high-order user-item interactions into more trainable vectors, ultimately resulting in better performance in terms of recall and normalized discounted cumulative gain(NDCG) metrics. The experiments conducted on benchmark datasets demonstrate that our proposed method achieves up to 13.78% improvement in the recall over the test data.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023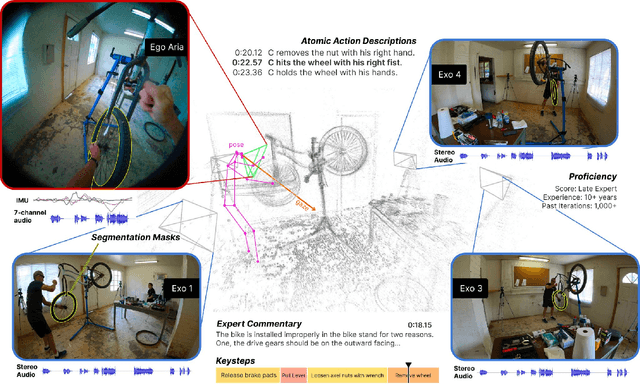
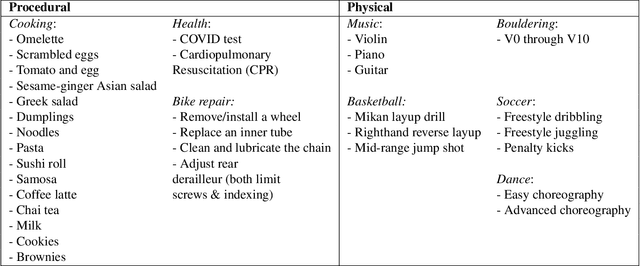


We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies
Aug 03, 2023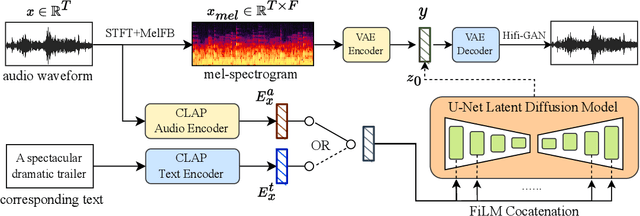
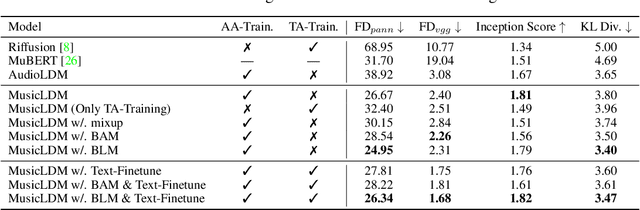
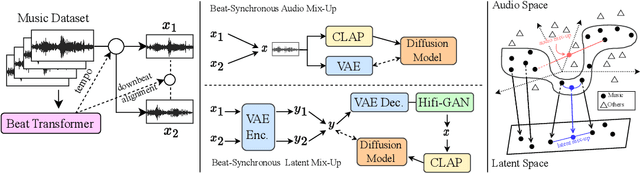
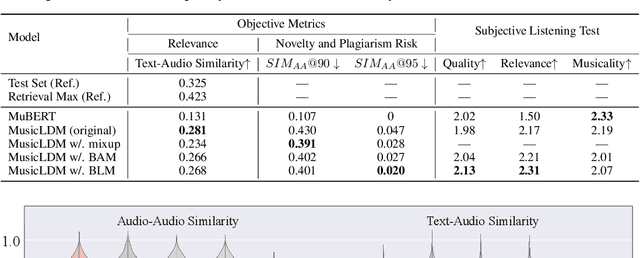
Diffusion models have shown promising results in cross-modal generation tasks, including text-to-image and text-to-audio generation. However, generating music, as a special type of audio, presents unique challenges due to limited availability of music data and sensitive issues related to copyright and plagiarism. In this paper, to tackle these challenges, we first construct a state-of-the-art text-to-music model, MusicLDM, that adapts Stable Diffusion and AudioLDM architectures to the music domain. We achieve this by retraining the contrastive language-audio pretraining model (CLAP) and the Hifi-GAN vocoder, as components of MusicLDM, on a collection of music data samples. Then, to address the limitations of training data and to avoid plagiarism, we leverage a beat tracking model and propose two different mixup strategies for data augmentation: beat-synchronous audio mixup and beat-synchronous latent mixup, which recombine training audio directly or via a latent embeddings space, respectively. Such mixup strategies encourage the model to interpolate between musical training samples and generate new music within the convex hull of the training data, making the generated music more diverse while still staying faithful to the corresponding style. In addition to popular evaluation metrics, we design several new evaluation metrics based on CLAP score to demonstrate that our proposed MusicLDM and beat-synchronous mixup strategies improve both the quality and novelty of generated music, as well as the correspondence between input text and generated music.
Music Genre Classification with ResNet and Bi-GRU Using Visual Spectrograms
Jul 20, 2023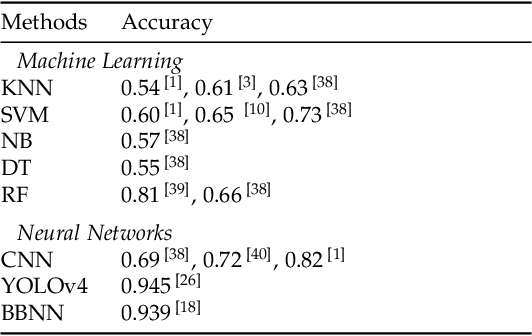

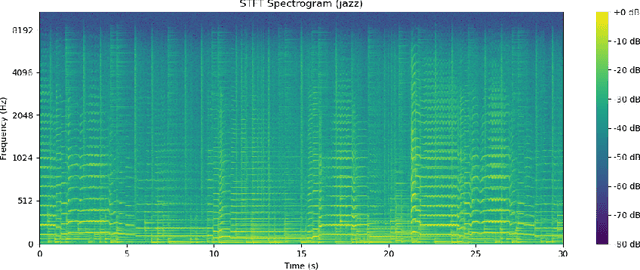
Music recommendation systems have emerged as a vital component to enhance user experience and satisfaction for the music streaming services, which dominates music consumption. The key challenge in improving these recommender systems lies in comprehending the complexity of music data, specifically for the underpinning music genre classification. The limitations of manual genre classification have highlighted the need for a more advanced system, namely the Automatic Music Genre Classification (AMGC) system. While traditional machine learning techniques have shown potential in genre classification, they heavily rely on manually engineered features and feature selection, failing to capture the full complexity of music data. On the other hand, deep learning classification architectures like the traditional Convolutional Neural Networks (CNN) are effective in capturing the spatial hierarchies but struggle to capture the temporal dynamics inherent in music data. To address these challenges, this study proposes a novel approach using visual spectrograms as input, and propose a hybrid model that combines the strength of the Residual neural Network (ResNet) and the Gated Recurrent Unit (GRU). This model is designed to provide a more comprehensive analysis of music data, offering the potential to improve the music recommender systems through achieving a more comprehensive analysis of music data and hence potentially more accurate genre classification.
BigWavGAN: A Wave-To-Wave Generative Adversarial Network for Music Super-Resolution
Aug 12, 2023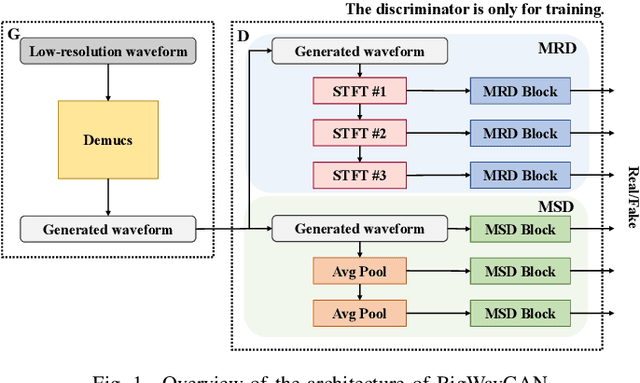
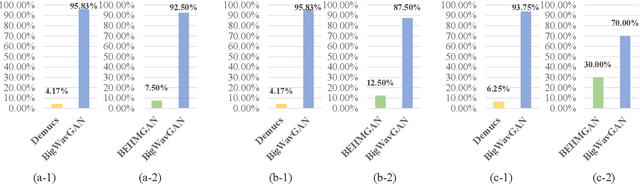
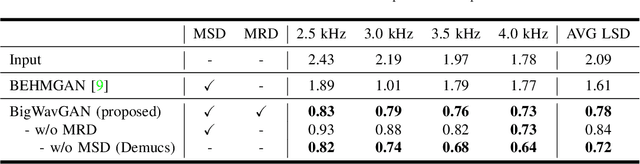
Generally, Deep Neural Networks (DNNs) are expected to have high performance when their model size is large. However, large models failed to produce high-quality results commensurate with their scale in music Super-Resolution (SR). We attribute this to that DNNs cannot learn information commensurate with their size from standard mean square error losses. To unleash the potential of large DNN models in music SR, we propose BigWavGAN, which incorporates Demucs, a large-scale wave-to-wave model, with State-Of-The-Art (SOTA) discriminators and adversarial training strategies. Our discriminator consists of Multi-Scale Discriminator (MSD) and Multi-Resolution Discriminator (MRD). During inference, since only the generator is utilized, there are no additional parameters or computational resources required compared to the baseline model Demucs. Objective evaluation affirms the effectiveness of BigWavGAN in music SR. Subjective evaluations indicate that BigWavGAN can generate music with significantly high perceptual quality over the baseline model. Notably, BigWavGAN surpasses the SOTA music SR model in both simulated and real-world scenarios. Moreover, BigWavGAN represents its superior generalization ability to address out-of-distribution data. The conducted ablation study reveals the importance of our discriminators and training strategies. Samples are available on the demo page.
EmoGen: Eliminating Subjective Bias in Emotional Music Generation
Jul 03, 2023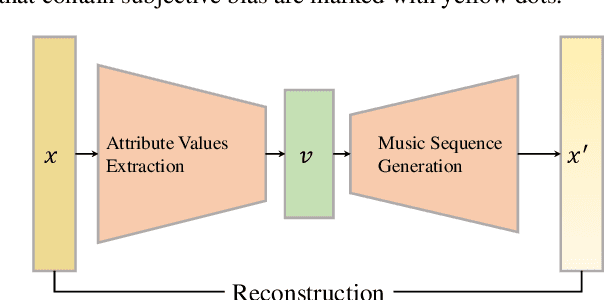

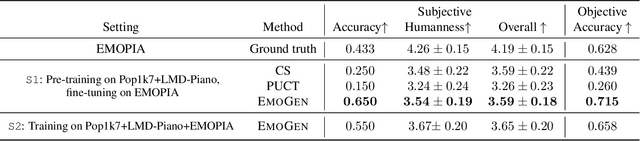
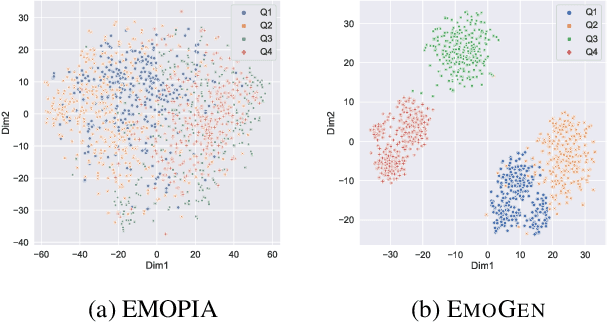
Music is used to convey emotions, and thus generating emotional music is important in automatic music generation. Previous work on emotional music generation directly uses annotated emotion labels as control signals, which suffers from subjective bias: different people may annotate different emotions on the same music, and one person may feel different emotions under different situations. Therefore, directly mapping emotion labels to music sequences in an end-to-end way would confuse the learning process and hinder the model from generating music with general emotions. In this paper, we propose EmoGen, an emotional music generation system that leverages a set of emotion-related music attributes as the bridge between emotion and music, and divides the generation into two stages: emotion-to-attribute mapping with supervised clustering, and attribute-to-music generation with self-supervised learning. Both stages are beneficial: in the first stage, the attribute values around the clustering center represent the general emotions of these samples, which help eliminate the impacts of the subjective bias of emotion labels; in the second stage, the generation is completely disentangled from emotion labels and thus free from the subjective bias. Both subjective and objective evaluations show that EmoGen outperforms previous methods on emotion control accuracy and music quality respectively, which demonstrate our superiority in generating emotional music. Music samples generated by EmoGen are available via this link:https://ai-muzic.github.io/emogen/, and the code is available at this link:https://github.com/microsoft/muzic/.
ChoralSynth: Synthetic Dataset of Choral Singing
Nov 21, 2023Choral singing, a widely practiced form of ensemble singing, lacks comprehensive datasets in the realm of Music Information Retrieval (MIR) research, due to challenges arising from the requirement to curate multitrack recordings. To address this, we devised a novel methodology, leveraging state-of-the-art synthesizers to create and curate quality renditions. The scores were sourced from Choral Public Domain Library(CPDL). This work is done in collaboration with a diverse team of musicians, software engineers and researchers. The resulting dataset, complete with its associated metadata, and methodology is released as part of this work, opening up new avenues for exploration and advancement in the field of singing voice research.