 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Automatic Music Playlist Generation via Simulation-based Reinforcement Learning
Oct 13, 2023
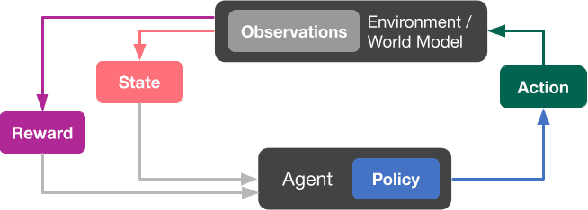
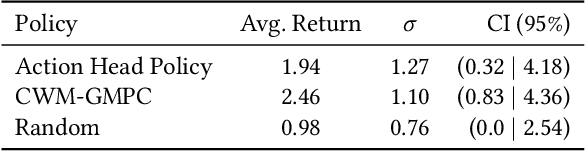
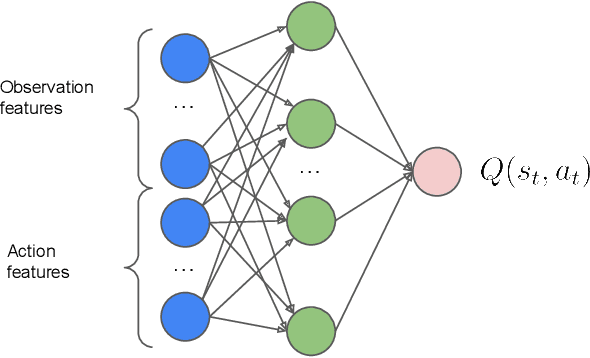
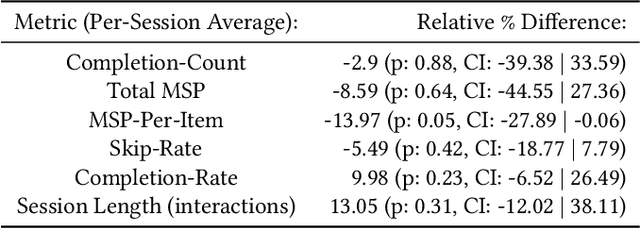
Personalization of playlists is a common feature in music streaming services, but conventional techniques, such as collaborative filtering, rely on explicit assumptions regarding content quality to learn how to make recommendations. Such assumptions often result in misalignment between offline model objectives and online user satisfaction metrics. In this paper, we present a reinforcement learning framework that solves for such limitations by directly optimizing for user satisfaction metrics via the use of a simulated playlist-generation environment. Using this simulator we develop and train a modified Deep Q-Network, the action head DQN (AH-DQN), in a manner that addresses the challenges imposed by the large state and action space of our RL formulation. The resulting policy is capable of making recommendations from large and dynamic sets of candidate items with the expectation of maximizing consumption metrics. We analyze and evaluate agents offline via simulations that use environment models trained on both public and proprietary streaming datasets. We show how these agents lead to better user-satisfaction metrics compared to baseline methods during online A/B tests. Finally, we demonstrate that performance assessments produced from our simulator are strongly correlated with observed online metric results.
miditok: A Python package for MIDI file tokenization
Oct 26, 2023Recent progress in natural language processing has been adapted to the symbolic music modality. Language models, such as Transformers, have been used with symbolic music for a variety of tasks among which music generation, modeling or transcription, with state-of-the-art performances. These models are beginning to be used in production products. To encode and decode music for the backbone model, they need to rely on tokenizers, whose role is to serialize music into sequences of distinct elements called tokens. MidiTok is an open-source library allowing to tokenize symbolic music with great flexibility and extended features. It features the most popular music tokenizations, under a unified API. It is made to be easily used and extensible for everyone.
Holodeck: Language Guided Generation of 3D Embodied AI Environments
Dec 14, 2023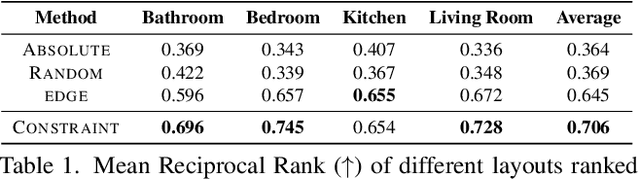
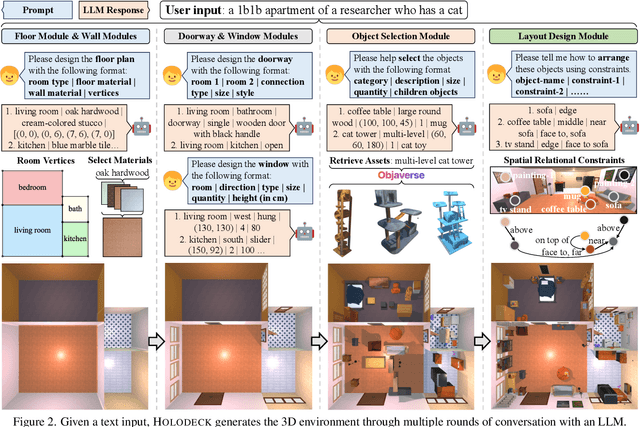

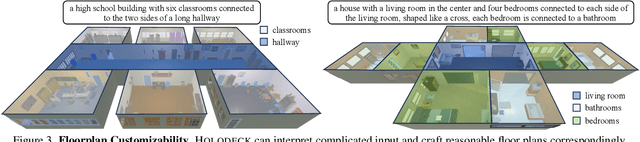
3D simulated environments play a critical role in Embodied AI, but their creation requires expertise and extensive manual effort, restricting their diversity and scope. To mitigate this limitation, we present Holodeck, a system that generates 3D environments to match a user-supplied prompt fully automatedly. Holodeck can generate diverse scenes, e.g., arcades, spas, and museums, adjust the designs for styles, and can capture the semantics of complex queries such as "apartment for a researcher with a cat" and "office of a professor who is a fan of Star Wars". Holodeck leverages a large language model (GPT-4) for common sense knowledge about what the scene might look like and uses a large collection of 3D assets from Objaverse to populate the scene with diverse objects. To address the challenge of positioning objects correctly, we prompt GPT-4 to generate spatial relational constraints between objects and then optimize the layout to satisfy those constraints. Our large-scale human evaluation shows that annotators prefer Holodeck over manually designed procedural baselines in residential scenes and that Holodeck can produce high-quality outputs for diverse scene types. We also demonstrate an exciting application of Holodeck in Embodied AI, training agents to navigate in novel scenes like music rooms and daycares without human-constructed data, which is a significant step forward in developing general-purpose embodied agents.
A Survey of AI Music Generation Tools and Models
Aug 24, 2023
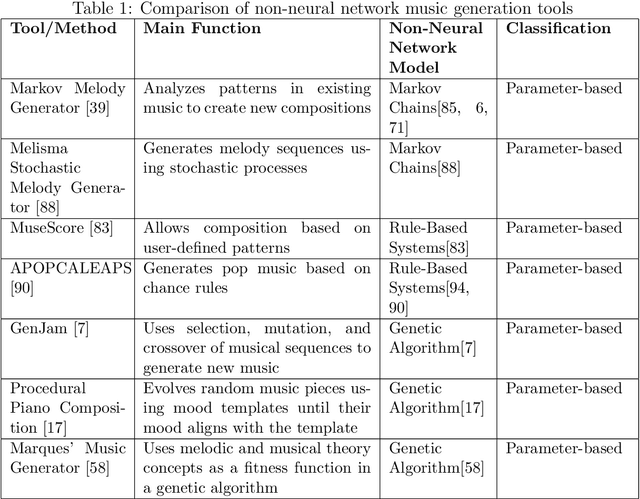
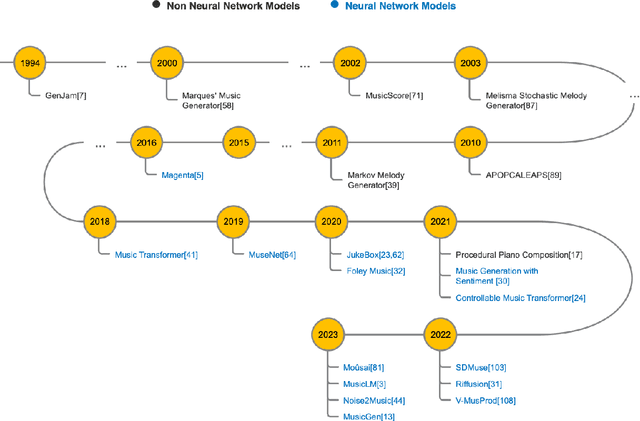
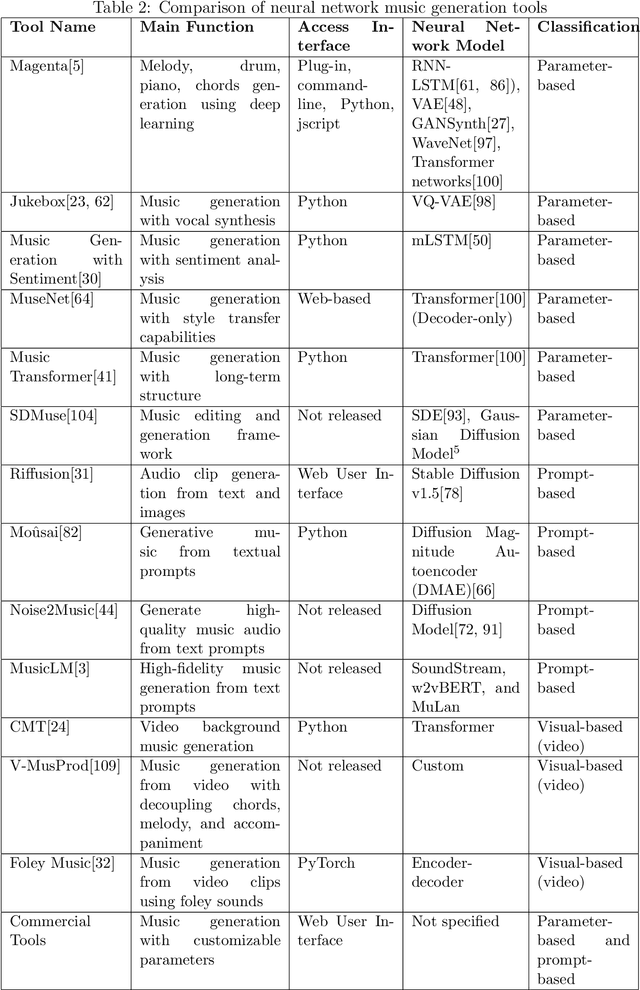
In this work, we provide a comprehensive survey of AI music generation tools, including both research projects and commercialized applications. To conduct our analysis, we classified music generation approaches into three categories: parameter-based, text-based, and visual-based classes. Our survey highlights the diverse possibilities and functional features of these tools, which cater to a wide range of users, from regular listeners to professional musicians. We observed that each tool has its own set of advantages and limitations. As a result, we have compiled a comprehensive list of these factors that should be considered during the tool selection process. Moreover, our survey offers critical insights into the underlying mechanisms and challenges of AI music generation.
Modeling Bends in Popular Music Guitar Tablatures
Aug 22, 2023Tablature notation is widely used in popular music to transcribe and share guitar musical content. As a complement to standard score notation, tablatures transcribe performance gesture information including finger positions and a variety of guitar-specific playing techniques such as slides, hammer-on/pull-off or bends.This paper focuses on bends, which enable to progressively shift the pitch of a note, therefore circumventing physical limitations of the discrete fretted fingerboard. In this paper, we propose a set of 25 high-level features, computed for each note of the tablature, to study how bend occurrences can be predicted from their past and future short-term context. Experiments are performed on a corpus of 932 lead guitar tablatures of popular music and show that a decision tree successfully predicts bend occurrences with an F1 score of 0.71 anda limited amount of false positive predictions, demonstrating promising applications to assist the arrangement of non-guitar music into guitar tablatures.
JEN-1: Text-Guided Universal Music Generation with Omnidirectional Diffusion Models
Aug 09, 2023
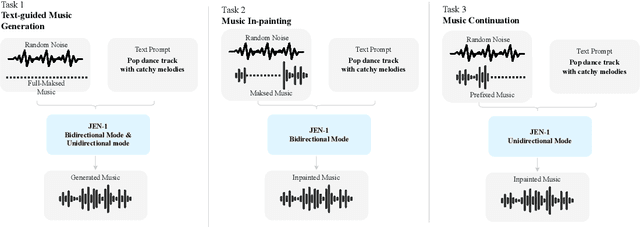
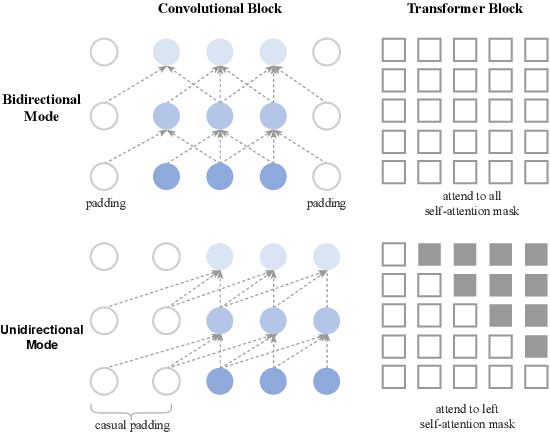
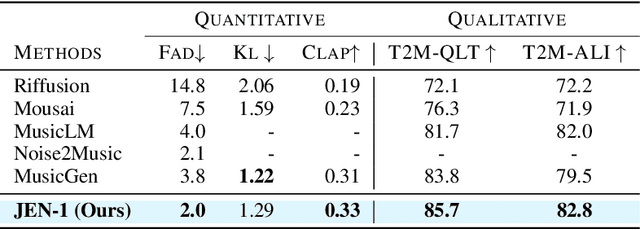
Music generation has attracted growing interest with the advancement of deep generative models. However, generating music conditioned on textual descriptions, known as text-to-music, remains challenging due to the complexity of musical structures and high sampling rate requirements. Despite the task's significance, prevailing generative models exhibit limitations in music quality, computational efficiency, and generalization. This paper introduces JEN-1, a universal high-fidelity model for text-to-music generation. JEN-1 is a diffusion model incorporating both autoregressive and non-autoregressive training. Through in-context learning, JEN-1 performs various generation tasks including text-guided music generation, music inpainting, and continuation. Evaluations demonstrate JEN-1's superior performance over state-of-the-art methods in text-music alignment and music quality while maintaining computational efficiency. Our demos are available at http://futureverse.com/research/jen/demos/jen1
Exploring how a Generative AI interprets music
Jul 31, 2023We use Google's MusicVAE, a Variational Auto-Encoder with a 512-dimensional latent space to represent a few bars of music, and organize the latent dimensions according to their relevance in describing music. We find that, on average, most latent neurons remain silent when fed real music tracks: we call these "noise" neurons. The remaining few dozens of latent neurons that do fire are called "music neurons". We ask which neurons carry the musical information and what kind of musical information they encode, namely something that can be identified as pitch, rhythm or melody. We find that most of the information about pitch and rhythm is encoded in the first few music neurons: the neural network has thus constructed a couple of variables that non-linearly encode many human-defined variables used to describe pitch and rhythm. The concept of melody only seems to show up in independent neurons for longer sequences of music.
Music Source Separation with Band-Split RoPE Transformer
Sep 10, 2023
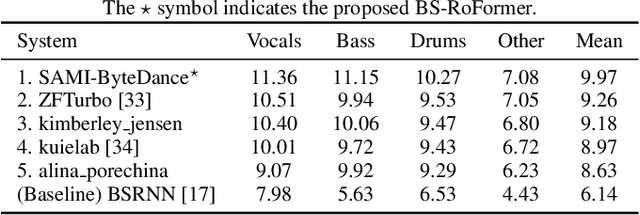
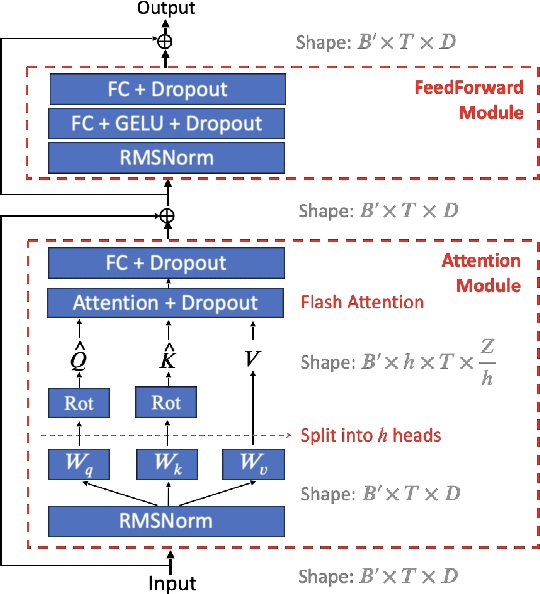
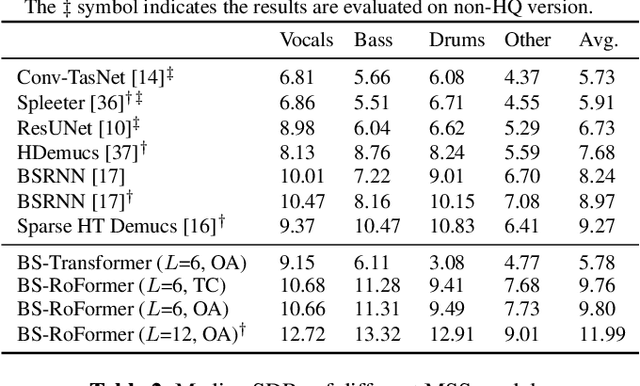
Music source separation (MSS) aims to separate a music recording into multiple musically distinct stems, such as vocals, bass, drums, and more. Recently, deep learning approaches such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been used, but the improvement is still limited. In this paper, we propose a novel frequency-domain approach based on a Band-Split RoPE Transformer (called BS-RoFormer). BS-RoFormer relies on a band-split module to project the input complex spectrogram into subband-level representations, and then arranges a stack of hierarchical Transformers to model the inner-band as well as inter-band sequences for multi-band mask estimation. To facilitate training the model for MSS, we propose to use the Rotary Position Embedding (RoPE). The BS-RoFormer system trained on MUSDB18HQ and 500 extra songs ranked the first place in the MSS track of Sound Demixing Challenge (SDX23). Benchmarking a smaller version of BS-RoFormer on MUSDB18HQ, we achieve state-of-the-art result without extra training data, with 9.80 dB of average SDR.
Harmony and Duality: An introduction to Music Theory
Sep 18, 2023
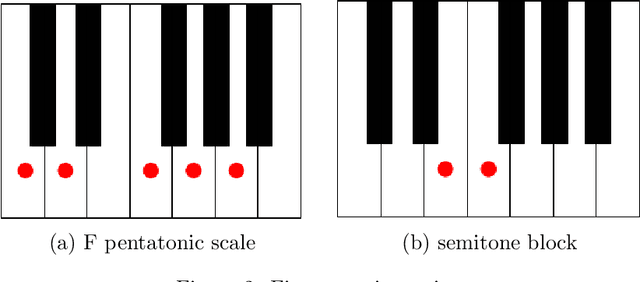
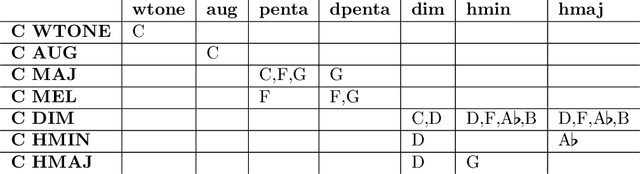
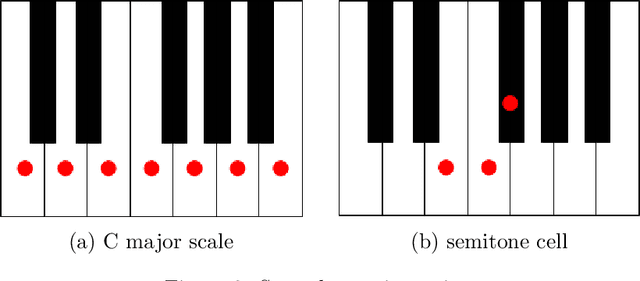
We develop aspects of music theory related to harmony, such as scales, chord formation and improvisation from a combinatorial perspective. The goal is to provide a foundation for this subject by deriving the basic structure from a few assumptions, rather than writing down long lists of chords/scales to memorize without an underlying principle. Our approach involves introducing constraints that limit the possible scales we can consider. For example, we may impose the constraint that two voices cannot be only a semitone apart as this is too dissonant. We can then study scales that do not contain notes that are a semitone apart. A more refined constraint avoids three voices colliding by studying scales that do not have three notes separated only by semitones. Additionally, we require that our scales are complete, which roughly means that they are the maximal sets of tones that satisfy these constraints. As it turns out, completeness as applied to these simple two/three voice constraints characterizes the types of scales that are commonly used in music composition. Surprisingly, there is a correspondence between scales subject to the two-voice constraint and those subject to the three-voice constraint. We formulate this correspondence as a duality statement that provides a way to understand scales subject to one type of constraint in terms of scales subject to the other. Finally, we combine these constraint ideas to provide a classification of chords.
Choir Transformer: Generating Polyphonic Music with Relative Attention on Transformer
Aug 01, 2023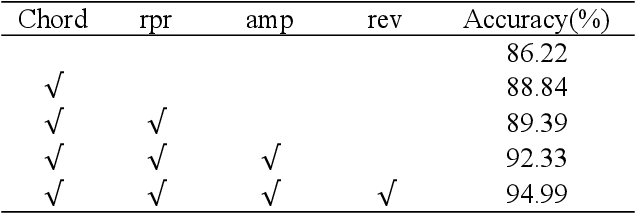
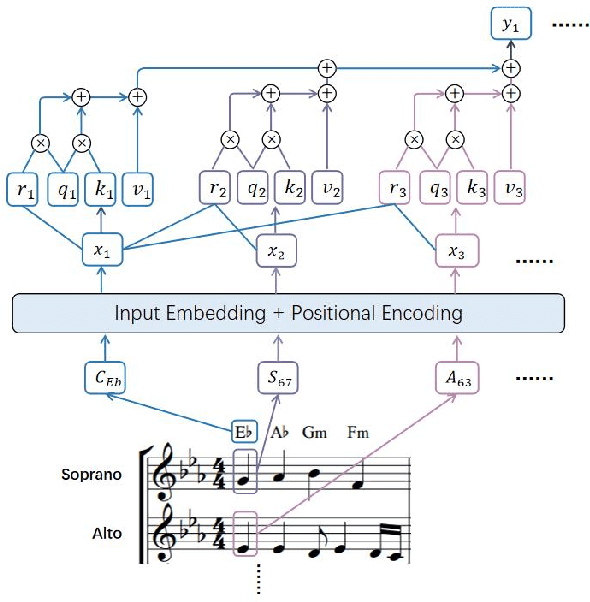
Polyphonic music generation is still a challenge direction due to its correct between generating melody and harmony. Most of the previous studies used RNN-based models. However, the RNN-based models are hard to establish the relationship between long-distance notes. In this paper, we propose a polyphonic music generation neural network named Choir Transformer[ https://github.com/Zjy0401/choir-transformer], with relative positional attention to better model the structure of music. We also proposed a music representation suitable for polyphonic music generation. The performance of Choir Transformer surpasses the previous state-of-the-art accuracy of 4.06%. We also measures the harmony metrics of polyphonic music. Experiments show that the harmony metrics are close to the music of Bach. In practical application, the generated melody and rhythm can be adjusted according to the specified input, with different styles of music like folk music or pop music and so on.