 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Integrated Sensing and Communication enabled Multiple Base Stations Cooperative UAV Detection
Apr 19, 2024
Integrated sensing and communication (ISAC) exhibits notable potential for sensing the unmanned aerial vehicles (UAVs), facilitating real-time monitoring of UAVs for security insurance. Due to the low sensing accuracy of single base stations (BSs), a cooperative UAV sensing method by multi-BS is proposed in this paper to achieve high-accuracy sensing. Specifically, a multiple signal classification (MUSIC)-based symbol-level fusion method is proposed for UAV localization and velocity estimation, consisting of a single-BS preprocessing step and a lattice points searching step. The preprocessing procedure enhances the single-BS accuracy by superposing multiple spectral functions, thereby establishing a reference value for subsequent lattice points searching. Furthermore, the lattice point with minimal error compared to the preprocessing results is determined as the fusion result. Extensive simulation results reveal that the proposed symbol-level fusion method outperforms the benchmarking methods in localization and velocity estimation.
LM2D: Lyrics- and Music-Driven Dance Synthesis
Mar 14, 2024
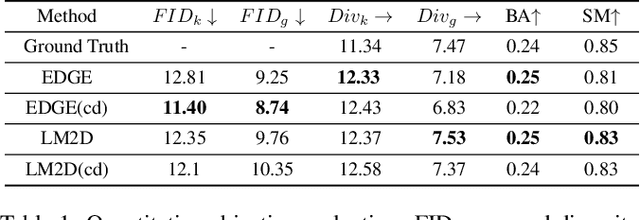
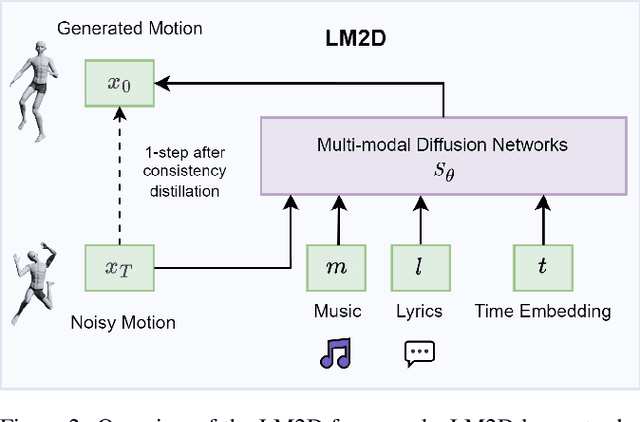
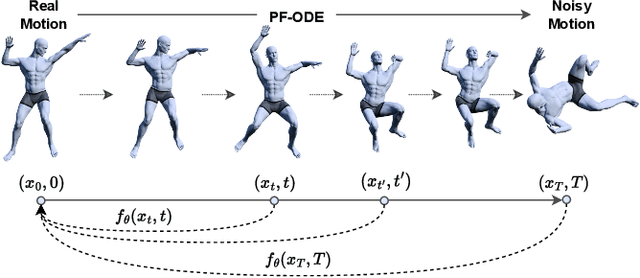
Dance typically involves professional choreography with complex movements that follow a musical rhythm and can also be influenced by lyrical content. The integration of lyrics in addition to the auditory dimension, enriches the foundational tone and makes motion generation more amenable to its semantic meanings. However, existing dance synthesis methods tend to model motions only conditioned on audio signals. In this work, we make two contributions to bridge this gap. First, we propose LM2D, a novel probabilistic architecture that incorporates a multimodal diffusion model with consistency distillation, designed to create dance conditioned on both music and lyrics in one diffusion generation step. Second, we introduce the first 3D dance-motion dataset that encompasses both music and lyrics, obtained with pose estimation technologies. We evaluate our model against music-only baseline models with objective metrics and human evaluations, including dancers and choreographers. The results demonstrate LM2D is able to produce realistic and diverse dance matching both lyrics and music. A video summary can be accessed at: https://youtu.be/4XCgvYookvA.
MCM: Multi-condition Motion Synthesis Framework
Apr 19, 2024Conditional human motion synthesis (HMS) aims to generate human motion sequences that conform to specific conditions. Text and audio represent the two predominant modalities employed as HMS control conditions. While existing research has primarily focused on single conditions, the multi-condition human motion synthesis remains underexplored. In this study, we propose a multi-condition HMS framework, termed MCM, based on a dual-branch structure composed of a main branch and a control branch. This framework effectively extends the applicability of the diffusion model, which is initially predicated solely on textual conditions, to auditory conditions. This extension encompasses both music-to-dance and co-speech HMS while preserving the intrinsic quality of motion and the capabilities for semantic association inherent in the original model. Furthermore, we propose the implementation of a Transformer-based diffusion model, designated as MWNet, as the main branch. This model adeptly apprehends the spatial intricacies and inter-joint correlations inherent in motion sequences, facilitated by the integration of multi-wise self-attention modules. Extensive experiments show that our method achieves competitive results in single-condition and multi-condition HMS tasks.
Robust and tractable multidimensional exponential analysis
Apr 17, 2024Motivated by a number of applications in signal processing, we study the following question. Given samples of a multidimensional signal of the form \begin{align*} f(\bs\ell)=\sum_{k=1}^K a_k\exp(-i\langle \bs\ell, \w_k\rangle), \\ \w_1,\cdots,\w_k\in\mathbb{R}^q, \ \bs\ell\in \ZZ^q, \ |\bs\ell| <n, \end{align*} determine the values of the number $K$ of components, and the parameters $a_k$ and $\w_k$'s. We develop an algorithm to recuperate these quantities accurately using only a subsample of size $\O(qn)$ of this data. For this purpose, we use a novel localized kernel method to identify the parameters, including the number $K$ of signals. Our method is easy to implement, and is shown to be stable under a very low SNR range. We demonstrate the effectiveness of our resulting algorithm using 2 and 3 dimensional examples from the literature, and show substantial improvements over state-of-the-art techniques including Prony based, MUSIC and ESPRIT approaches.
Music Enhancement with Deep Filters: A Technical Report for The ICASSP 2024 Cadenza Challenge
Apr 17, 2024In this challenge, we disentangle the deep filters from the original DeepfilterNet and incorporate them into our Spec-UNet-based network to further improve a hybrid Demucs (hdemucs) based remixing pipeline. The motivation behind the use of the deep filter component lies at its potential in better handling temporal fine structures. We demonstrate an incremental improvement in both the Signal-to-Distortion Ratio (SDR) and the Hearing Aid Audio Quality Index (HAAQI) metrics when comparing the performance of hdemucs against different versions of our model.
Analyzing Musical Characteristics of National Anthems in Relation to Global Indices
Apr 04, 2024Music plays a huge part in shaping peoples' psychology and behavioral patterns. This paper investigates the connection between national anthems and different global indices with computational music analysis and statistical correlation analysis. We analyze national anthem musical data to determine whether certain musical characteristics are associated with peace, happiness, suicide rate, crime rate, etc. To achieve this, we collect national anthems from 169 countries and use computational music analysis techniques to extract pitch, tempo, beat, and other pertinent audio features. We then compare these musical characteristics with data on different global indices to ascertain whether a significant correlation exists. Our findings indicate that there may be a correlation between the musical characteristics of national anthems and the indices we investigated. The implications of our findings for music psychology and policymakers interested in promoting social well-being are discussed. This paper emphasizes the potential of musical data analysis in social research and offers a novel perspective on the relationship between music and social indices. The source code and data are made open-access for reproducibility and future research endeavors. It can be accessed at http://bit.ly/na_code.
Learning Multidimensional Disentangled Representations of Instrumental Sounds for Musical Similarity Assessment
Apr 10, 2024To achieve a flexible recommendation and retrieval system, it is desirable to calculate music similarity by focusing on multiple partial elements of musical pieces and allowing the users to select the element they want to focus on. A previous study proposed using multiple individual networks for calculating music similarity based on each instrumental sound, but it is impractical to use each signal as a query in search systems. Using separated instrumental sounds alternatively resulted in less accuracy due to artifacts. In this paper, we propose a method to compute similarities focusing on each instrumental sound with a single network that takes mixed sounds as input instead of individual instrumental sounds. Specifically, we design a single similarity embedding space with disentangled dimensions for each instrument, extracted by Conditional Similarity Networks, which is trained by the triplet loss using masks. Experimental results have shown that (1) the proposed method can obtain more accurate feature representation than using individual networks using separated sounds as input, (2) each sub-embedding space can hold the characteristics of the corresponding instrument, and (3) the selection of similar musical pieces focusing on each instrumental sound by the proposed method can obtain human consent, especially in drums and guitar.
Musical Listening Qualia: A Multivariate Approach
Apr 10, 2024French and American participants listened to new music stimuli and evaluated the stimuli using either adjectives or quantitative musical dimensions. Results were analyzed using correspondence analysis (CA), hierarchical cluster analysis (HCA), multiple factor analysis (MFA), and partial least squares correlation (PLSC). French and American listeners differed when they described the musical stimuli using adjectives, but not when using the quantitative dimensions. The present work serves as a case study in research methodology that allows for a balance between relaxing experimental control and maintaining statistical rigor.
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Apr 16, 2024Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
Little Pilot is Needed for Channel Estimation with Integrated Super-Resolution Sensing and Communication
Apr 16, 2024Integrated super-resolution sensing and communication (ISSAC) is a promising technology to achieve extremely high sensing performance for critical parameters, such as the angles of the wireless channels. In this paper, we propose an ISSAC-based channel estimation method, which requires little or even no pilot, yet still achieves accurate channel state information (CSI) estimation. The key idea is to exploit the fact that subspace-based super-resolution algorithms such as multiple signal classification (MUSIC) do not require a priori known pilots for accurate parameter estimation. Therefore, in the proposed method, the angles of the multi-path channel components are first estimated in a pilot-free manner while communication data symbols are sent. After that, the multi-path channel coefficients are estimated, where very little pilots are needed. The reasons are two folds. First, compared to the conventional channel estimation methods purely relying on channel training, much fewer parameters need to be estimated once the multi-path angles are accurately estimated. Besides, with angles obtained, the beamforming gain is also enjoyed when pilots are sent to estimate the channel path gains. To rigorously study the performance of the proposed method, we first consider the basic line-of-sight (LoS) channel. By analyzing the minimum mean square error (MMSE) of channel estimation and the resulting beamforming gains, we show that our proposed method significantly outperforms the conventional methods purely based on channel training. We then extend the study to the more general multipath channels. Simulation results are provided to demonstrate our theoretical results.