 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
The Persian Piano Corpus: A Collection Of Instrument-Based Feature Extracted Data Considering Dastgah
Nov 18, 2023
The research in the field of music is rapidly growing, and this trend emphasizes the need for comprehensive data. Though researchers have made an effort to contribute their own datasets, many data collections lack the requisite inclusivity for comprehensive study because they are frequently focused on particular components of music or other specific topics. We have endeavored to address data scarcity by employing an instrument-based approach to provide a complete corpus related to the Persian piano. Our piano corpus includes relevant labels for Persian music mode (Dastgah) and comprehensive metadata, allowing for utilization in various popular research areas. The features extracted from 2022 Persian piano pieces in The Persian Piano Corpus (PPC) have been collected and made available to researchers, aiming for a more thorough understanding of Persian music and the role of the piano in it in subsequent steps.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 10, 2023
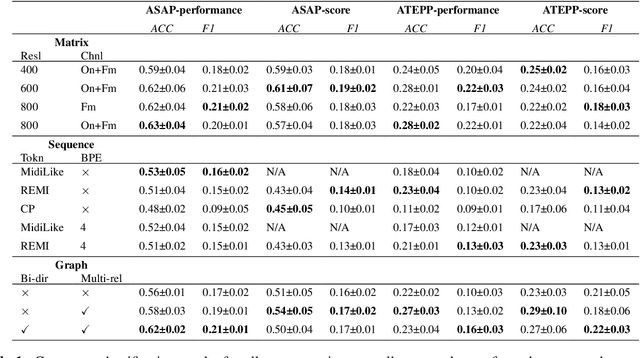
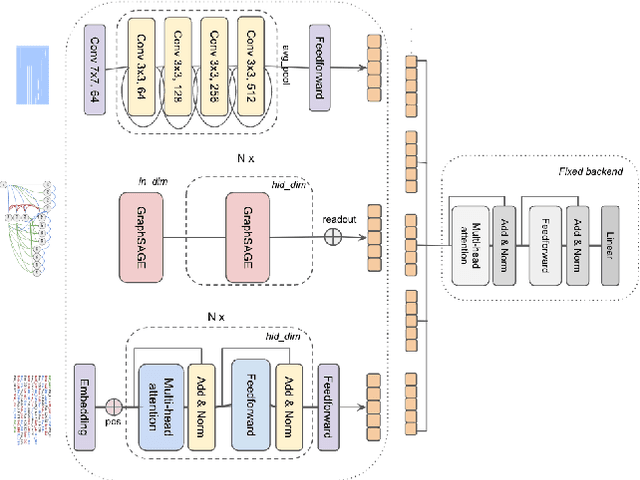
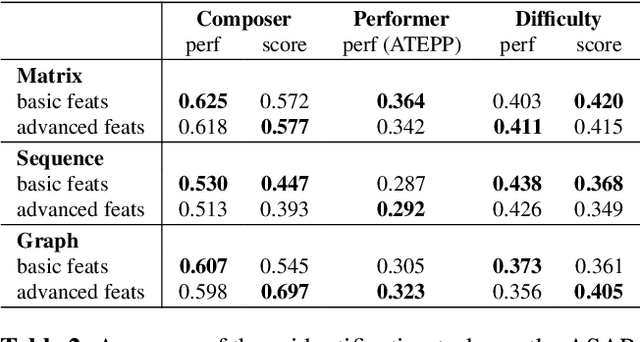
Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.
* To be published in the Proceedings of the 24th International Society for Music Information Retrieval Conference (ISMIR 2023), Milan, Italy
8+8=4: Formalizing Time Units to Handle Symbolic Music Durations
Oct 23, 2023This paper focuses on the nominal durations of musical events (notes and rests) in a symbolic musical score, and on how to conveniently handle these in computer applications. We propose the usage of a temporal unit that is directly related to the graphical symbols in musical scores and pair this with a set of operations that cover typical computations in music applications. We formalize this time unit and the more commonly used approach in a single mathematical framework, as semirings, algebraic structures that enable an abstract description of algorithms/processing pipelines. We then discuss some practical use cases and highlight when our system can improve such pipelines by making them more efficient in terms of data type used and the number of computations.
A Long-Tail Friendly Representation Framework for Artist and Music Similarity
Sep 08, 2023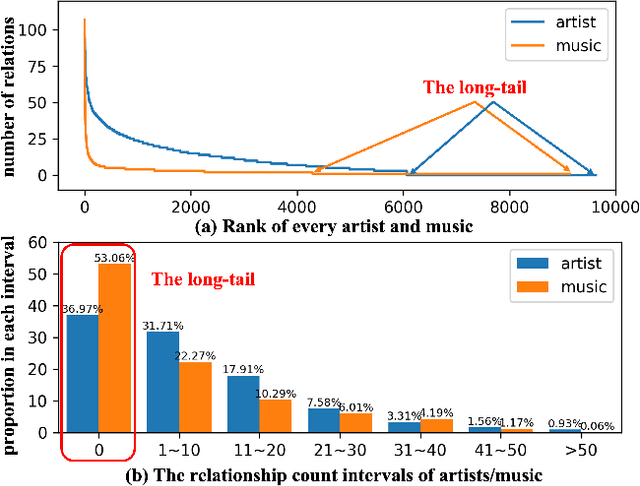
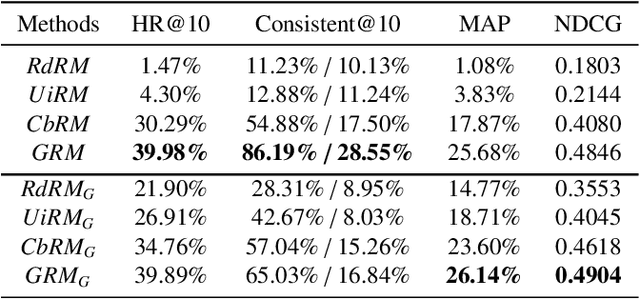
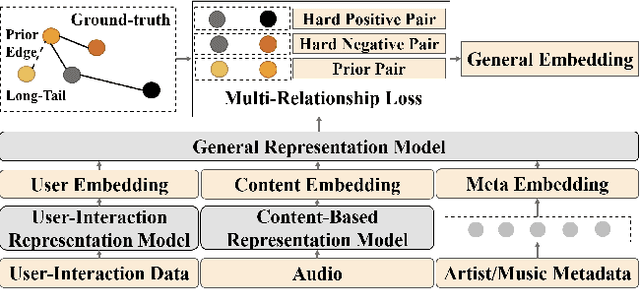
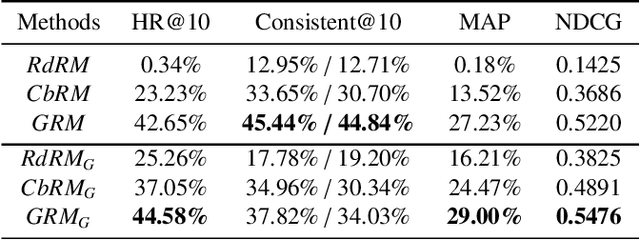
The investigation of the similarity between artists and music is crucial in music retrieval and recommendation, and addressing the challenge of the long-tail phenomenon is increasingly important. This paper proposes a Long-Tail Friendly Representation Framework (LTFRF) that utilizes neural networks to model the similarity relationship. Our approach integrates music, user, metadata, and relationship data into a unified metric learning framework, and employs a meta-consistency relationship as a regular term to introduce the Multi-Relationship Loss. Compared to the Graph Neural Network (GNN), our proposed framework improves the representation performance in long-tail scenarios, which are characterized by sparse relationships between artists and music. We conduct experiments and analysis on the AllMusic dataset, and the results demonstrate that our framework provides a favorable generalization of artist and music representation. Specifically, on similar artist/music recommendation tasks, the LTFRF outperforms the baseline by 9.69%/19.42% in Hit Ratio@10, and in long-tail cases, the framework achieves 11.05%/14.14% higher than the baseline in Consistent@10.
Exploiting Time-Frequency Conformers for Music Audio Enhancement
Aug 24, 2023
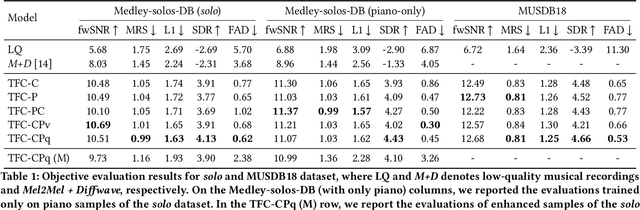
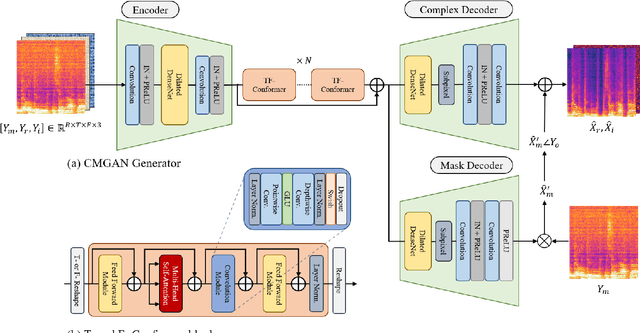
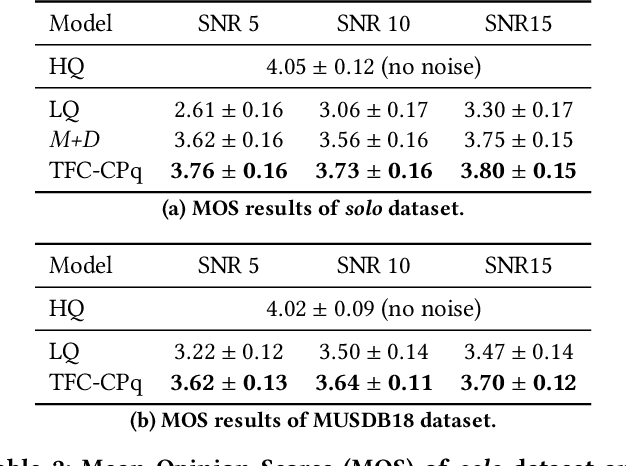
With the proliferation of video platforms on the internet, recording musical performances by mobile devices has become commonplace. However, these recordings often suffer from degradation such as noise and reverberation, which negatively impact the listening experience. Consequently, the necessity for music audio enhancement (referred to as music enhancement from this point onward), involving the transformation of degraded audio recordings into pristine high-quality music, has surged to augment the auditory experience. To address this issue, we propose a music enhancement system based on the Conformer architecture that has demonstrated outstanding performance in speech enhancement tasks. Our approach explores the attention mechanisms of the Conformer and examines their performance to discover the best approach for the music enhancement task. Our experimental results show that our proposed model achieves state-of-the-art performance on single-stem music enhancement. Furthermore, our system can perform general music enhancement with multi-track mixtures, which has not been examined in previous work.
TrOMR:Transformer-Based Polyphonic Optical Music Recognition
Aug 18, 2023Optical Music Recognition (OMR) is an important technology in music and has been researched for a long time. Previous approaches for OMR are usually based on CNN for image understanding and RNN for music symbol classification. In this paper, we propose a transformer-based approach with excellent global perceptual capability for end-to-end polyphonic OMR, called TrOMR. We also introduce a novel consistency loss function and a reasonable approach for data annotation to improve recognition accuracy for complex music scores. Extensive experiments demonstrate that TrOMR outperforms current OMR methods, especially in real-world scenarios. We also develop a TrOMR system and build a camera scene dataset for full-page music scores in real-world. The code and datasets will be made available for reproducibility.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
Improving Emotional Expression and Cohesion in Image-Based Playlist Description and Music Topics: A Continuous Parameterization Approach
Oct 12, 2023Text generation in image-based platforms, particularly for music-related content, requires precise control over text styles and the incorporation of emotional expression. However, existing approaches often need help to control the proportion of external factors in generated text and rely on discrete inputs, lacking continuous control conditions for desired text generation. This study proposes Continuous Parameterization for Controlled Text Generation (CPCTG) to overcome these limitations. Our approach leverages a Language Model (LM) as a style learner, integrating Semantic Cohesion (SC) and Emotional Expression Proportion (EEP) considerations. By enhancing the reward method and manipulating the CPCTG level, our experiments on playlist description and music topic generation tasks demonstrate significant improvements in ROUGE scores, indicating enhanced relevance and coherence in the generated text.
Comparative Assessment of Markov Models and Recurrent Neural Networks for Jazz Music Generation
Sep 14, 2023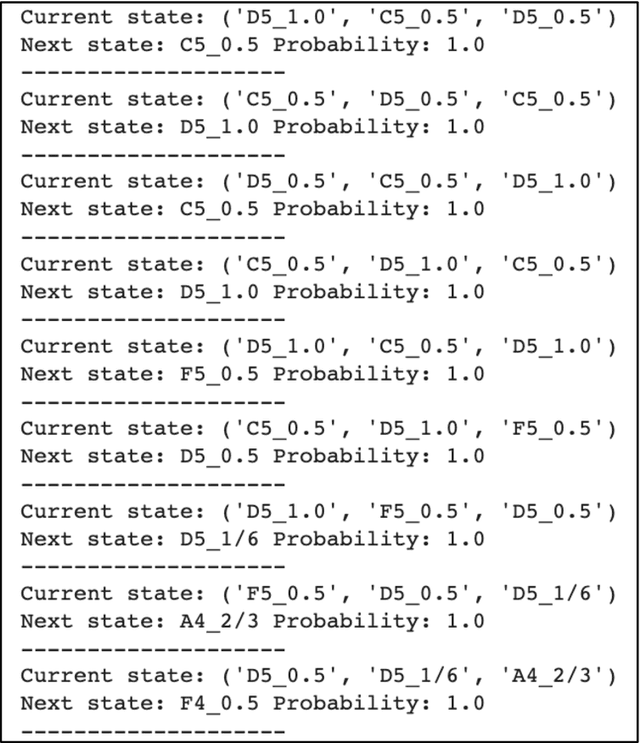
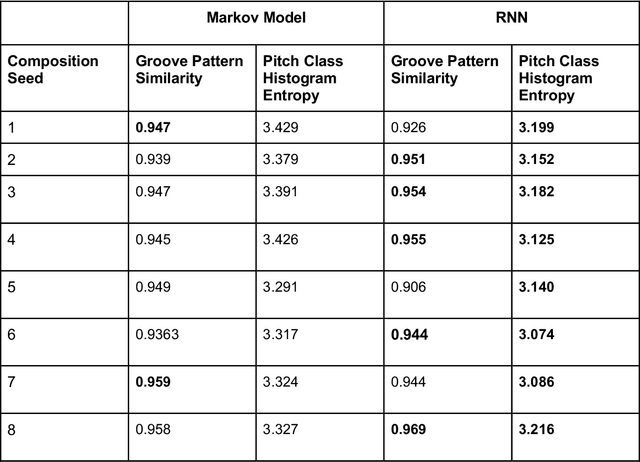
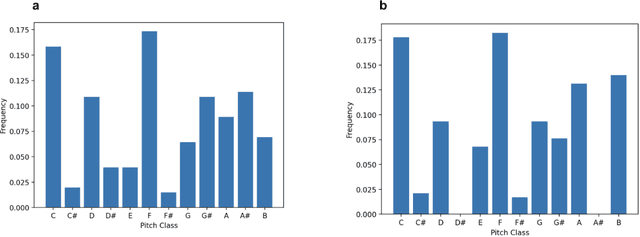
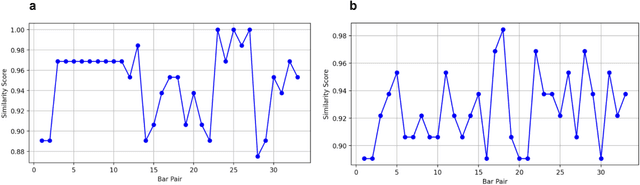
As generative models have risen in popularity, a domain that has risen alongside is generative models for music. Our study aims to compare the performance of a simple Markov chain model and a recurrent neural network (RNN) model, two popular models for sequence generating tasks, in jazz music improvisation. While music, especially jazz, remains subjective in telling whether a composition is "good" or "bad", we aim to quantify our results using metrics of groove pattern similarity and pitch class histogram entropy. We trained both models using transcriptions of jazz blues choruses from professional jazz players, and also fed musical jazz seeds to help give our model some context in beginning the generation. Our results show that the RNN outperforms the Markov model on both of our metrics, indicating better rhythmic consistency and tonal stability in the generated music. Through the use of music21 library, we tokenized our jazz dataset into pitches and durations that our model could interpret and train on. Our findings contribute to the growing field of AI-generated music, highlighting the important use of metrics to assess generation quality. Future work includes expanding the dataset of MIDI files to a larger scale, conducting human surveys for subjective evaluations, and incorporating additional metrics to address the challenge of subjectivity in music evaluation. Our study provides valuable insight into the use of recurrent neural networks for sequential based tasks like generating music.
Towards Contrastive Learning in Music Video Domain
Sep 01, 2023Contrastive learning is a powerful way of learning multimodal representations across various domains such as image-caption retrieval and audio-visual representation learning. In this work, we investigate if these findings generalize to the domain of music videos. Specifically, we create a dual en-coder for the audio and video modalities and train it using a bidirectional contrastive loss. For the experiments, we use an industry dataset containing 550 000 music videos as well as the public Million Song Dataset, and evaluate the quality of learned representations on the downstream tasks of music tagging and genre classification. Our results indicate that pre-trained networks without contrastive fine-tuning outperform our contrastive learning approach when evaluated on both tasks. To gain a better understanding of the reasons contrastive learning was not successful for music videos, we perform a qualitative analysis of the learned representations, revealing why contrastive learning might have difficulties uniting embeddings from two modalities. Based on these findings, we outline possible directions for future work. To facilitate the reproducibility of our results, we share our code and the pre-trained model.