 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Dual-space Hierarchical Learning for Goal-guided Conversational Recommendation
Dec 30, 2023

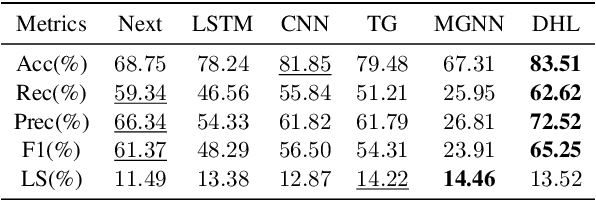
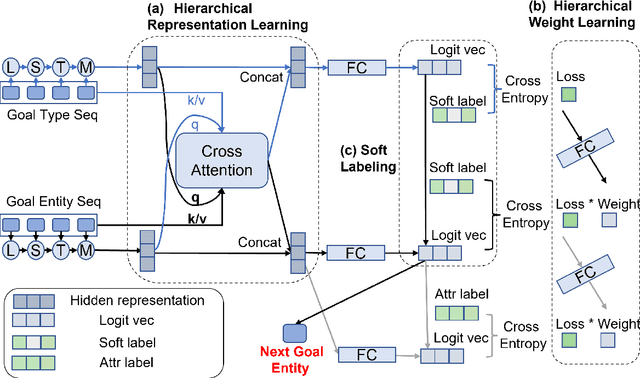
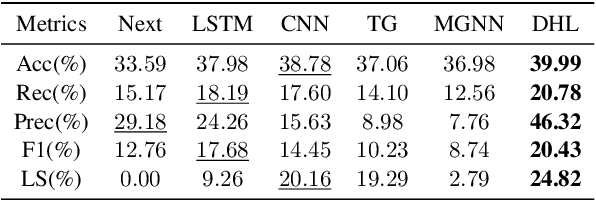
Proactively and naturally guiding the dialog from the non-recommendation context (e.g., Chit-chat) to the recommendation scenario (e.g., Music) is crucial for the Conversational Recommender System (CRS). Prior studies mainly focus on planning the next dialog goal~(e.g., chat on a movie star) conditioned on the previous dialog. However, we find the dialog goals can be simultaneously observed at different levels, which can be utilized to improve CRS. In this paper, we propose Dual-space Hierarchical Learning (DHL) to leverage multi-level goal sequences and their hierarchical relationships for conversational recommendation. Specifically, we exploit multi-level goal sequences from both the representation space and the optimization space. In the representation space, we propose the hierarchical representation learning where a cross attention module derives mutually enhanced multi-level goal representations. In the optimization space, we devise the hierarchical weight learning to reweight lower-level goal sequences, and introduce bi-level optimization for stable update. Additionally, we propose a soft labeling strategy to guide optimization gradually. Experiments on two real-world datasets verify the effectiveness of our approach. Code and data are available here.
Towards Robust and Truly Large-Scale Audio-Sheet Music Retrieval
Sep 21, 2023A range of applications of multi-modal music information retrieval is centred around the problem of connecting large collections of sheet music (images) to corresponding audio recordings, that is, identifying pairs of audio and score excerpts that refer to the same musical content. One of the typical and most recent approaches to this task employs cross-modal deep learning architectures to learn joint embedding spaces that link the two distinct modalities - audio and sheet music images. While there has been steady improvement on this front over the past years, a number of open problems still prevent large-scale employment of this methodology. In this article we attempt to provide an insightful examination of the current developments on audio-sheet music retrieval via deep learning methods. We first identify a set of main challenges on the road towards robust and large-scale cross-modal music retrieval in real scenarios. We then highlight the steps we have taken so far to address some of these challenges, documenting step-by-step improvement along several dimensions. We conclude by analysing the remaining challenges and present ideas for solving these, in order to pave the way to a unified and robust methodology for cross-modal music retrieval.
BEAST: Online Joint Beat and Downbeat Tracking Based on Streaming Transformer
Dec 28, 2023Many deep learning models have achieved dominant performance on the offline beat tracking task. However, online beat tracking, in which only the past and present input features are available, still remains challenging. In this paper, we propose BEAt tracking Streaming Transformer (BEAST), an online joint beat and downbeat tracking system based on the streaming Transformer. To deal with online scenarios, BEAST applies contextual block processing in the Transformer encoder. Moreover, we adopt relative positional encoding in the attention layer of the streaming Transformer encoder to capture relative timing position which is critically important information in music. Carrying out beat and downbeat experiments on benchmark datasets for a low latency scenario with maximum latency under 50 ms, BEAST achieves an F1-measure of 80.04% in beat and 52.73% in downbeat, which is a substantial improvement of about 5 and 13 percentage points over the state-of-the-art online beat and downbeat tracking model.
Music Augmentation and Denoising For Peak-Based Audio Fingerprinting
Oct 29, 2023Audio fingerprinting is a well-established solution for song identification from short recording excerpts. Popular methods rely on the extraction of sparse representations, generally spectral peaks, and have proven to be accurate, fast, and scalable to large collections. However, real-world applications of audio identification often happen in noisy environments, which can cause these systems to fail. In this work, we tackle this problem by introducing and releasing a new audio augmentation pipeline that adds noise to music snippets in a realistic way, by stochastically mimicking real-world scenarios. We then propose and release a deep learning model that removes noisy components from spectrograms in order to improve peak-based fingerprinting systems' accuracy. We show that the addition of our model improves the identification performance of commonly used audio fingerprinting systems, even under noisy conditions.
Self-Supervised Contrastive Learning for Robust Audio-Sheet Music Retrieval Systems
Sep 21, 2023Linking sheet music images to audio recordings remains a key problem for the development of efficient cross-modal music retrieval systems. One of the fundamental approaches toward this task is to learn a cross-modal embedding space via deep neural networks that is able to connect short snippets of audio and sheet music. However, the scarcity of annotated data from real musical content affects the capability of such methods to generalize to real retrieval scenarios. In this work, we investigate whether we can mitigate this limitation with self-supervised contrastive learning, by exposing a network to a large amount of real music data as a pre-training step, by contrasting randomly augmented views of snippets of both modalities, namely audio and sheet images. Through a number of experiments on synthetic and real piano data, we show that pre-trained models are able to retrieve snippets with better precision in all scenarios and pre-training configurations. Encouraged by these results, we employ the snippet embeddings in the higher-level task of cross-modal piece identification and conduct more experiments on several retrieval configurations. In this task, we observe that the retrieval quality improves from 30% up to 100% when real music data is present. We then conclude by arguing for the potential of self-supervised contrastive learning for alleviating the annotated data scarcity in multi-modal music retrieval models.
Undecidability Results and Their Relevance in Modern Music Making
Sep 14, 2023This paper delves into the intersection of computational theory and music, examining the concept of undecidability and its significant, yet overlooked, implications within the realm of modern music composition and production. It posits that undecidability, a principle traditionally associated with theoretical computer science, extends its relevance to the music industry. The study adopts a multidimensional approach, focusing on five key areas: (1) the Turing completeness of Ableton, a widely used digital audio workstation, (2) the undecidability of satisfiability in sound creation utilizing an array of effects, (3) the undecidability of constraints on polymeters in musical compositions, (4) the undecidability of satisfiability in just intonation harmony constraints, and (5) the undecidability of "new ordering systems". In addition to providing theoretical proof for these assertions, the paper elucidates the practical relevance of these concepts for practitioners outside the field of theoretical computer science. The ultimate aim is to foster a new understanding of undecidability in music, highlighting its broader applicability and potential to influence contemporary computer-assisted (and traditional) music making.
Positive and Risky Message Assessment for Music Products
Sep 18, 2023In this work, we propose a novel research problem: assessing positive and risky messages from music products. We first establish a benchmark for multi-angle multi-level music content assessment and then present an effective multi-task prediction model with ordinality-enforcement to solve this problem. Our result shows the proposed method not only significantly outperforms strong task-specific counterparts but can concurrently evaluate multiple aspects.
MDSC: Towards Evaluating the Style Consistency Between Music and
Sep 04, 2023We propose MDSC(Music-Dance-Style Consistency), the first evaluation metric which assesses to what degree the dance moves and music match. Existing metrics can only evaluate the fidelity and diversity of motion and the degree of rhythmic matching between music and motion. MDSC measures how stylistically correlated the generated dance motion sequences and the conditioning music sequences are. We found that directly measuring the embedding distance between motion and music is not an optimal solution. We instead tackle this through modelling it as a clustering problem. Specifically, 1) we pre-train a music encoder and a motion encoder, then 2) we learn to map and align the motion and music embedding in joint space by jointly minimizing the intra-cluster distance and maximizing the inter-cluster distance, and 3) for evaluation purpose, we encode the dance moves into embedding and measure the intra-cluster and inter-cluster distances, as well as the ratio between them. We evaluate our metric on the results of several music-conditioned motion generation methods, combined with user study, we found that our proposed metric is a robust evaluation metric in measuring the music-dance style correlation. The code is available at: https://github.com/zixiangzhou916/MDSC.
Can MusicGen Create Training Data for MIR Tasks?
Nov 15, 2023We are investigating the broader concept of using AI-based generative music systems to generate training data for Music Information Retrieval (MIR) tasks. To kick off this line of work, we ran an initial experiment in which we trained a genre classifier on a fully artificial music dataset created with MusicGen. We constructed over 50 000 genre- conditioned textual descriptions and generated a collection of music excerpts that covers five musical genres. Our preliminary results show that the proposed model can learn genre-specific characteristics from artificial music tracks that generalise well to real-world music recordings.
Emotion-Aligned Contrastive Learning Between Images and Music
Aug 24, 2023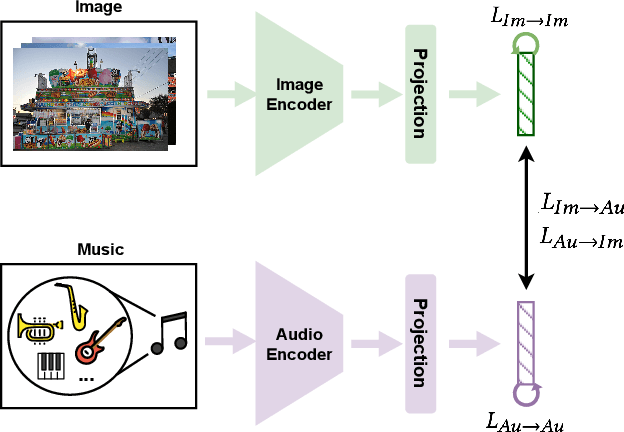



Traditional music search engines rely on retrieval methods that match natural language queries with music metadata. There have been increasing efforts to expand retrieval methods to consider the audio characteristics of music itself, using queries of various modalities including text, video, and speech. Most approaches aim to match general music semantics to the input queries, while only a few focus on affective qualities. We address the task of retrieving emotionally-relevant music from image queries by proposing a framework for learning an affective alignment between images and music audio. Our approach focuses on learning an emotion-aligned joint embedding space between images and music. This joint embedding space is learned via emotion-supervised contrastive learning, using an adapted cross-modal version of the SupCon loss. We directly evaluate the joint embeddings with cross-modal retrieval tasks (image-to-music and music-to-image) based on emotion labels. In addition, we investigate the generalizability of the learned music embeddings with automatic music tagging as a downstream task. Our experiments show that our approach successfully aligns images and music, and that the learned embedding space is effective for cross-modal retrieval applications.