 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Are we describing the same sound? An analysis of word embedding spaces of expressive piano performance
Dec 31, 2023
Semantic embeddings play a crucial role in natural language-based information retrieval. Embedding models represent words and contexts as vectors whose spatial configuration is derived from the distribution of words in large text corpora. While such representations are generally very powerful, they might fail to account for fine-grained domain-specific nuances. In this article, we investigate this uncertainty for the domain of characterizations of expressive piano performance. Using a music research dataset of free text performance characterizations and a follow-up study sorting the annotations into clusters, we derive a ground truth for a domain-specific semantic similarity structure. We test five embedding models and their similarity structure for correspondence with the ground truth. We further assess the effects of contextualizing prompts, hubness reduction, cross-modal similarity, and k-means clustering. The quality of embedding models shows great variability with respect to this task; more general models perform better than domain-adapted ones and the best model configurations reach human-level agreement.
Predicting performance difficulty from piano sheet music images
Sep 28, 2023Estimating the performance difficulty of a musical score is crucial in music education for adequately designing the learning curriculum of the students. Although the Music Information Retrieval community has recently shown interest in this task, existing approaches mainly use machine-readable scores, leaving the broader case of sheet music images unaddressed. Based on previous works involving sheet music images, we use a mid-level representation, bootleg score, describing notehead positions relative to staff lines coupled with a transformer model. This architecture is adapted to our task by introducing an encoding scheme that reduces the encoded sequence length to one-eighth of the original size. In terms of evaluation, we consider five datasets -- more than 7500 scores with up to 9 difficulty levels -- , two of them particularly compiled for this work. The results obtained when pretraining the scheme on the IMSLP corpus and fine-tuning it on the considered datasets prove the proposal's validity, achieving the best-performing model with a balanced accuracy of 40.34\% and a mean square error of 1.33. Finally, we provide access to our code, data, and models for transparency and reproducibility.
Performance Conditioning for Diffusion-Based Multi-Instrument Music Synthesis
Sep 21, 2023Generating multi-instrument music from symbolic music representations is an important task in Music Information Retrieval (MIR). A central but still largely unsolved problem in this context is musically and acoustically informed control in the generation process. As the main contribution of this work, we propose enhancing control of multi-instrument synthesis by conditioning a generative model on a specific performance and recording environment, thus allowing for better guidance of timbre and style. Building on state-of-the-art diffusion-based music generative models, we introduce performance conditioning - a simple tool indicating the generative model to synthesize music with style and timbre of specific instruments taken from specific performances. Our prototype is evaluated using uncurated performances with diverse instrumentation and achieves state-of-the-art FAD realism scores while allowing novel timbre and style control. Our project page, including samples and demonstrations, is available at benadar293.github.io/midipm
Music Understanding LLaMA: Advancing Text-to-Music Generation with Question Answering and Captioning
Aug 22, 2023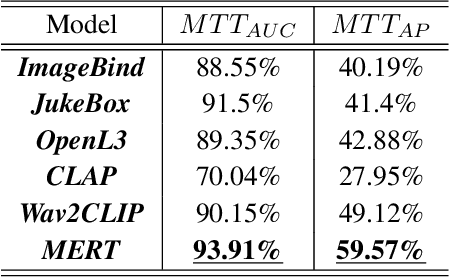
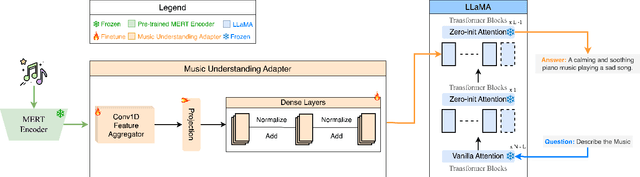
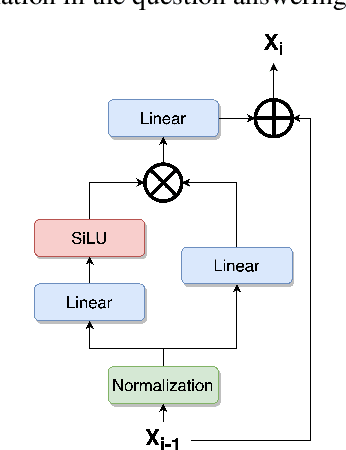
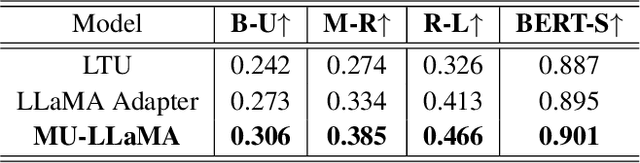
Text-to-music generation (T2M-Gen) faces a major obstacle due to the scarcity of large-scale publicly available music datasets with natural language captions. To address this, we propose the Music Understanding LLaMA (MU-LLaMA), capable of answering music-related questions and generating captions for music files. Our model utilizes audio representations from a pretrained MERT model to extract music features. However, obtaining a suitable dataset for training the MU-LLaMA model remains challenging, as existing publicly accessible audio question answering datasets lack the necessary depth for open-ended music question answering. To fill this gap, we present a methodology for generating question-answer pairs from existing audio captioning datasets and introduce the MusicQA Dataset designed for answering open-ended music-related questions. The experiments demonstrate that the proposed MU-LLaMA model, trained on our designed MusicQA dataset, achieves outstanding performance in both music question answering and music caption generation across various metrics, outperforming current state-of-the-art (SOTA) models in both fields and offering a promising advancement in the T2M-Gen research field.
Passage Summarization with Recurrent Models for Audio-Sheet Music Retrieval
Sep 21, 2023Many applications of cross-modal music retrieval are related to connecting sheet music images to audio recordings. A typical and recent approach to this is to learn, via deep neural networks, a joint embedding space that correlates short fixed-size snippets of audio and sheet music by means of an appropriate similarity structure. However, two challenges that arise out of this strategy are the requirement of strongly aligned data to train the networks, and the inherent discrepancies of musical content between audio and sheet music snippets caused by local and global tempo differences. In this paper, we address these two shortcomings by designing a cross-modal recurrent network that learns joint embeddings that can summarize longer passages of corresponding audio and sheet music. The benefits of our method are that it only requires weakly aligned audio-sheet music pairs, as well as that the recurrent network handles the non-linearities caused by tempo variations between audio and sheet music. We conduct a number of experiments on synthetic and real piano data and scores, showing that our proposed recurrent method leads to more accurate retrieval in all possible configurations.
Investigating Personalization Methods in Text to Music Generation
Sep 20, 2023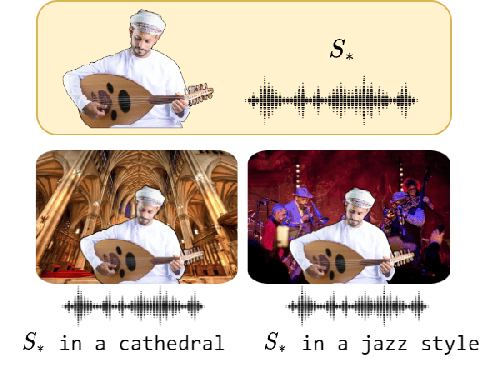
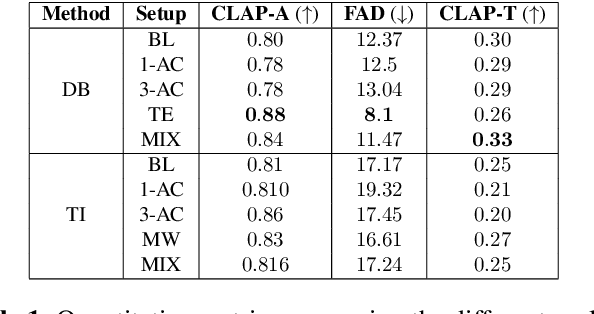
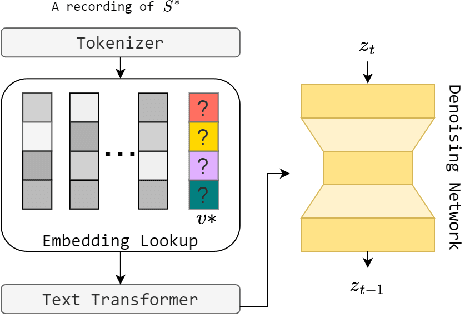
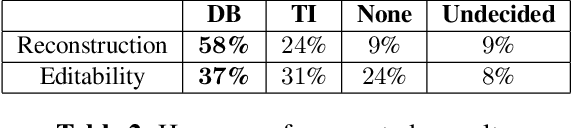
In this work, we investigate the personalization of text-to-music diffusion models in a few-shot setting. Motivated by recent advances in the computer vision domain, we are the first to explore the combination of pre-trained text-to-audio diffusers with two established personalization methods. We experiment with the effect of audio-specific data augmentation on the overall system performance and assess different training strategies. For evaluation, we construct a novel dataset with prompts and music clips. We consider both embedding-based and music-specific metrics for quantitative evaluation, as well as a user study for qualitative evaluation. Our analysis shows that similarity metrics are in accordance with user preferences and that current personalization approaches tend to learn rhythmic music constructs more easily than melody. The code, dataset, and example material of this study are open to the research community.
Exploring Music Genre Classification: Algorithm Analysis and Deployment Architecture
Sep 09, 2023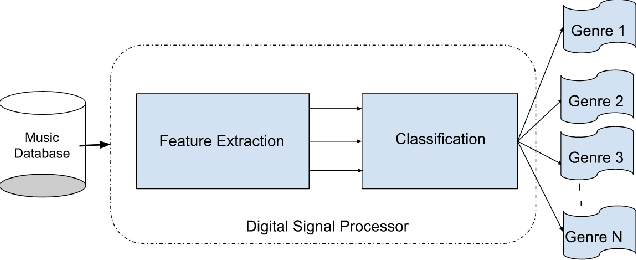
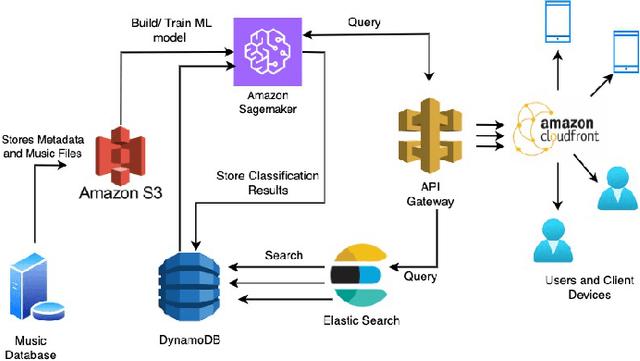
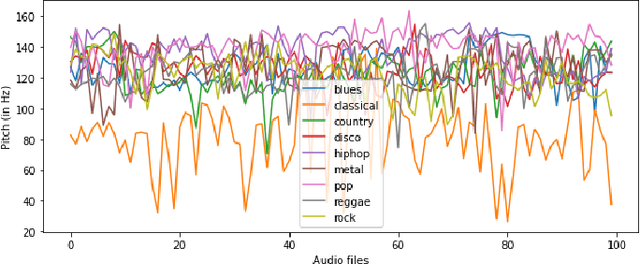

Music genre classification has become increasingly critical with the advent of various streaming applications. Nowadays, we find it impossible to imagine using the artist's name and song title to search for music in a sophisticated music app. It is always difficult to classify music correctly because the information linked to music, such as region, artist, album, or non-album, is so variable. This paper presents a study on music genre classification using a combination of Digital Signal Processing (DSP) and Deep Learning (DL) techniques. A novel algorithm is proposed that utilizes both DSP and DL methods to extract relevant features from audio signals and classify them into various genres. The algorithm was tested on the GTZAN dataset and achieved high accuracy. An end-to-end deployment architecture is also proposed for integration into music-related applications. The performance of the algorithm is analyzed and future directions for improvement are discussed. The proposed DSP and DL-based music genre classification algorithm and deployment architecture demonstrate a promising approach for music genre classification.
Dual-space Hierarchical Learning for Goal-guided Conversational Recommendation
Dec 30, 2023
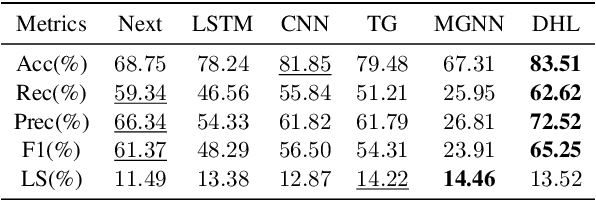
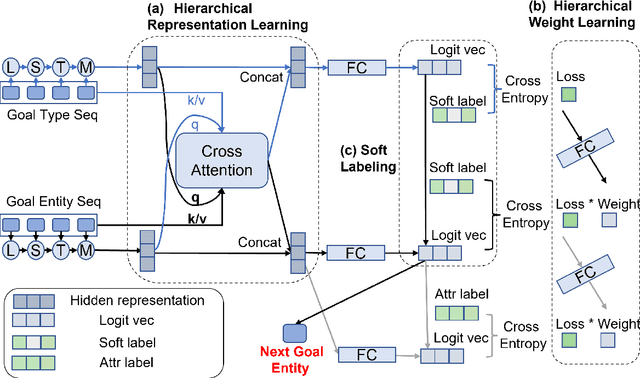
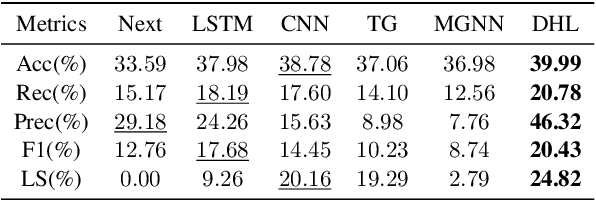
Proactively and naturally guiding the dialog from the non-recommendation context (e.g., Chit-chat) to the recommendation scenario (e.g., Music) is crucial for the Conversational Recommender System (CRS). Prior studies mainly focus on planning the next dialog goal~(e.g., chat on a movie star) conditioned on the previous dialog. However, we find the dialog goals can be simultaneously observed at different levels, which can be utilized to improve CRS. In this paper, we propose Dual-space Hierarchical Learning (DHL) to leverage multi-level goal sequences and their hierarchical relationships for conversational recommendation. Specifically, we exploit multi-level goal sequences from both the representation space and the optimization space. In the representation space, we propose the hierarchical representation learning where a cross attention module derives mutually enhanced multi-level goal representations. In the optimization space, we devise the hierarchical weight learning to reweight lower-level goal sequences, and introduce bi-level optimization for stable update. Additionally, we propose a soft labeling strategy to guide optimization gradually. Experiments on two real-world datasets verify the effectiveness of our approach. Code and data are available here.
BEAST: Online Joint Beat and Downbeat Tracking Based on Streaming Transformer
Dec 28, 2023Many deep learning models have achieved dominant performance on the offline beat tracking task. However, online beat tracking, in which only the past and present input features are available, still remains challenging. In this paper, we propose BEAt tracking Streaming Transformer (BEAST), an online joint beat and downbeat tracking system based on the streaming Transformer. To deal with online scenarios, BEAST applies contextual block processing in the Transformer encoder. Moreover, we adopt relative positional encoding in the attention layer of the streaming Transformer encoder to capture relative timing position which is critically important information in music. Carrying out beat and downbeat experiments on benchmark datasets for a low latency scenario with maximum latency under 50 ms, BEAST achieves an F1-measure of 80.04% in beat and 52.73% in downbeat, which is a substantial improvement of about 5 and 13 percentage points over the state-of-the-art online beat and downbeat tracking model.
Towards Robust and Truly Large-Scale Audio-Sheet Music Retrieval
Sep 21, 2023A range of applications of multi-modal music information retrieval is centred around the problem of connecting large collections of sheet music (images) to corresponding audio recordings, that is, identifying pairs of audio and score excerpts that refer to the same musical content. One of the typical and most recent approaches to this task employs cross-modal deep learning architectures to learn joint embedding spaces that link the two distinct modalities - audio and sheet music images. While there has been steady improvement on this front over the past years, a number of open problems still prevent large-scale employment of this methodology. In this article we attempt to provide an insightful examination of the current developments on audio-sheet music retrieval via deep learning methods. We first identify a set of main challenges on the road towards robust and large-scale cross-modal music retrieval in real scenarios. We then highlight the steps we have taken so far to address some of these challenges, documenting step-by-step improvement along several dimensions. We conclude by analysing the remaining challenges and present ideas for solving these, in order to pave the way to a unified and robust methodology for cross-modal music retrieval.