 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
LLark: A Multimodal Foundation Model for Music
Oct 11, 2023
Music has a unique and complex structure which is challenging for both expert humans and existing AI systems to understand, and presents unique challenges relative to other forms of audio. We present LLark, an instruction-tuned multimodal model for music understanding. We detail our process for dataset creation, which involves augmenting the annotations of diverse open-source music datasets and converting them to a unified instruction-tuning format. We propose a multimodal architecture for LLark, integrating a pretrained generative model for music with a pretrained language model. In evaluations on three types of tasks (music understanding, captioning, and reasoning), we show that our model matches or outperforms existing baselines in zero-shot generalization for music understanding, and that humans show a high degree of agreement with the model's responses in captioning and reasoning tasks. LLark is trained entirely from open-source music data and models, and we make our training code available along with the release of this paper. Additional results and audio examples are at https://bit.ly/llark, and our source code is available at https://github.com/spotify-research/llark .
Let's Get It Started: Fostering the Discoverability of New Releases on Deezer
Jan 05, 2024This paper presents our recent initiatives to foster the discoverability of new releases on the music streaming service Deezer. After introducing our search and recommendation features dedicated to new releases, we outline our shift from editorial to personalized release suggestions using cold start embeddings and contextual bandits. Backed by online experiments, we discuss the advantages of this shift in terms of recommendation quality and exposure of new releases on the service.
MusicAgent: An AI Agent for Music Understanding and Generation with Large Language Models
Oct 25, 2023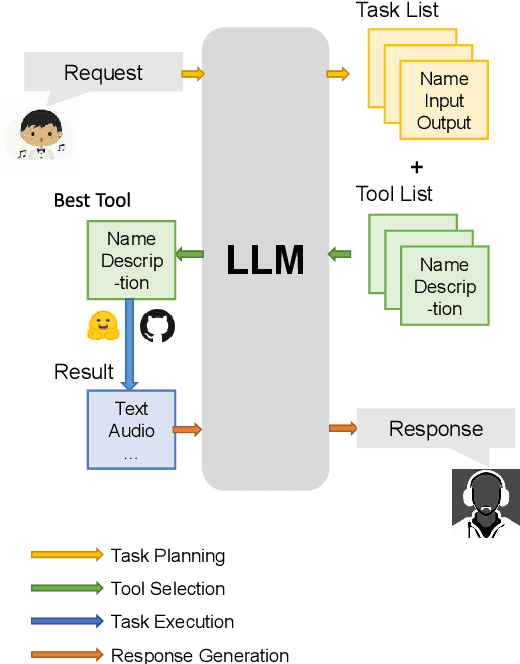
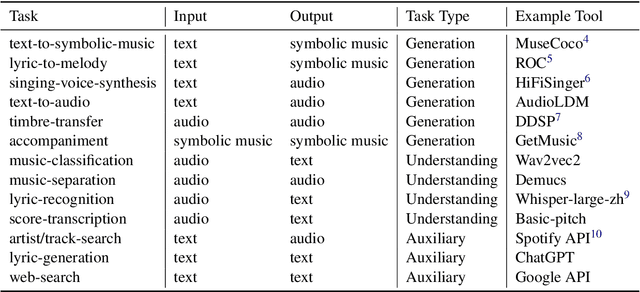
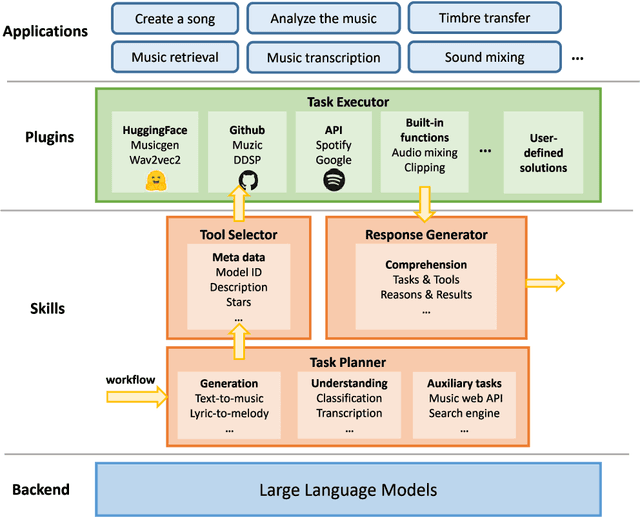
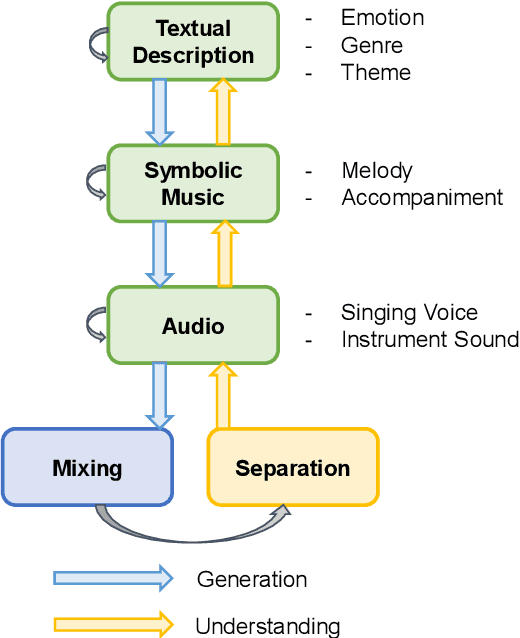
AI-empowered music processing is a diverse field that encompasses dozens of tasks, ranging from generation tasks (e.g., timbre synthesis) to comprehension tasks (e.g., music classification). For developers and amateurs, it is very difficult to grasp all of these task to satisfy their requirements in music processing, especially considering the huge differences in the representations of music data and the model applicability across platforms among various tasks. Consequently, it is necessary to build a system to organize and integrate these tasks, and thus help practitioners to automatically analyze their demand and call suitable tools as solutions to fulfill their requirements. Inspired by the recent success of large language models (LLMs) in task automation, we develop a system, named MusicAgent, which integrates numerous music-related tools and an autonomous workflow to address user requirements. More specifically, we build 1) toolset that collects tools from diverse sources, including Hugging Face, GitHub, and Web API, etc. 2) an autonomous workflow empowered by LLMs (e.g., ChatGPT) to organize these tools and automatically decompose user requests into multiple sub-tasks and invoke corresponding music tools. The primary goal of this system is to free users from the intricacies of AI-music tools, enabling them to concentrate on the creative aspect. By granting users the freedom to effortlessly combine tools, the system offers a seamless and enriching music experience.
CoCoFormer: A controllable feature-rich polyphonic music generation method
Oct 15, 2023This paper explores the modeling method of polyphonic music sequence. Due to the great potential of Transformer models in music generation, controllable music generation is receiving more attention. In the task of polyphonic music, current controllable generation research focuses on controlling the generation of chords, but lacks precise adjustment for the controllable generation of choral music textures. This paper proposed Condition Choir Transformer (CoCoFormer) which controls the output of the model by controlling the chord and rhythm inputs at a fine-grained level. In this paper, the self-supervised method improves the loss function and performs joint training through conditional control input and unconditional input training. In order to alleviate the lack of diversity on generated samples caused by the teacher forcing training, this paper added an adversarial training method. CoCoFormer enhances model performance with explicit and implicit inputs to chords and rhythms. In this paper, the experiments proves that CoCoFormer has reached the current better level than current models. On the premise of specifying the polyphonic music texture, the same melody can also be generated in a variety of ways.
GATSY: Graph Attention Network for Music Artist Similarity
Nov 01, 2023The artist similarity quest has become a crucial subject in social and scientific contexts. Modern research solutions facilitate music discovery according to user tastes. However, defining similarity among artists may involve several aspects, even related to a subjective perspective, and it often affects a recommendation. This paper presents GATSY, a recommendation system built upon graph attention networks and driven by a clusterized embedding of artists. The proposed framework takes advantage of a graph topology of the input data to achieve outstanding performance results without relying heavily on hand-crafted features. This flexibility allows us to introduce fictitious artists in a music dataset, create bridges to previously unrelated artists, and get recommendations conditioned by possibly heterogeneous sources. Experimental results prove the effectiveness of the proposed method with respect to state-of-the-art solutions.
Composer Style-specific Symbolic Music Generation Using Vector Quantized Discrete Diffusion Models
Oct 21, 2023Emerging Denoising Diffusion Probabilistic Models (DDPM) have become increasingly utilised because of promising results they have achieved in diverse generative tasks with continuous data, such as image and sound synthesis. Nonetheless, the success of diffusion models has not been fully extended to discrete symbolic music. We propose to combine a vector quantized variational autoencoder (VQ-VAE) and discrete diffusion models for the generation of symbolic music with desired composer styles. The trained VQ-VAE can represent symbolic music as a sequence of indexes that correspond to specific entries in a learned codebook. Subsequently, a discrete diffusion model is used to model the VQ-VAE's discrete latent space. The diffusion model is trained to generate intermediate music sequences consisting of codebook indexes, which are then decoded to symbolic music using the VQ-VAE's decoder. The results demonstrate our model can generate symbolic music with target composer styles that meet the given conditions with a high accuracy of 72.36%.
Similar but Faster: Manipulation of Tempo in Music Audio Embeddings for Tempo Prediction and Search
Jan 17, 2024Audio embeddings enable large scale comparisons of the similarity of audio files for applications such as search and recommendation. Due to the subjectivity of audio similarity, it can be desirable to design systems that answer not only whether audio is similar, but similar in what way (e.g., wrt. tempo, mood or genre). Previous works have proposed disentangled embedding spaces where subspaces representing specific, yet possibly correlated, attributes can be weighted to emphasize those attributes in downstream tasks. However, no research has been conducted into the independence of these subspaces, nor their manipulation, in order to retrieve tracks that are similar but different in a specific way. Here, we explore the manipulation of tempo in embedding spaces as a case-study towards this goal. We propose tempo translation functions that allow for efficient manipulation of tempo within a pre-existing embedding space whilst maintaining other properties such as genre. As this translation is specific to tempo it enables retrieval of tracks that are similar but have specifically different tempi. We show that such a function can be used as an efficient data augmentation strategy for both training of downstream tempo predictors, and improved nearest neighbor retrieval of properties largely independent of tempo.
Fast Diffusion GAN Model for Symbolic Music Generation Controlled by Emotions
Oct 21, 2023Diffusion models have shown promising results for a wide range of generative tasks with continuous data, such as image and audio synthesis. However, little progress has been made on using diffusion models to generate discrete symbolic music because this new class of generative models are not well suited for discrete data while its iterative sampling process is computationally expensive. In this work, we propose a diffusion model combined with a Generative Adversarial Network, aiming to (i) alleviate one of the remaining challenges in algorithmic music generation which is the control of generation towards a target emotion, and (ii) mitigate the slow sampling drawback of diffusion models applied to symbolic music generation. We first used a trained Variational Autoencoder to obtain embeddings of a symbolic music dataset with emotion labels and then used those to train a diffusion model. Our results demonstrate the successful control of our diffusion model to generate symbolic music with a desired emotion. Our model achieves several orders of magnitude improvement in computational cost, requiring merely four time steps to denoise while the steps required by current state-of-the-art diffusion models for symbolic music generation is in the order of thousands.
Controllable Music Production with Diffusion Models and Guidance Gradients
Nov 01, 2023We demonstrate how conditional generation from diffusion models can be used to tackle a variety of realistic tasks in the production of music in 44.1kHz stereo audio with sampling-time guidance. The scenarios we consider include continuation, inpainting and regeneration of musical audio, the creation of smooth transitions between two different music tracks, and the transfer of desired stylistic characteristics to existing audio clips. We achieve this by applying guidance at sampling time in a simple framework that supports both reconstruction and classification losses, or any combination of the two. This approach ensures that generated audio can match its surrounding context, or conform to a class distribution or latent representation specified relative to any suitable pre-trained classifier or embedding model.
BeatDance: A Beat-Based Model-Agnostic Contrastive Learning Framework for Music-Dance Retrieval
Oct 16, 2023Dance and music are closely related forms of expression, with mutual retrieval between dance videos and music being a fundamental task in various fields like education, art, and sports. However, existing methods often suffer from unnatural generation effects or fail to fully explore the correlation between music and dance. To overcome these challenges, we propose BeatDance, a novel beat-based model-agnostic contrastive learning framework. BeatDance incorporates a Beat-Aware Music-Dance InfoExtractor, a Trans-Temporal Beat Blender, and a Beat-Enhanced Hubness Reducer to improve dance-music retrieval performance by utilizing the alignment between music beats and dance movements. We also introduce the Music-Dance (MD) dataset, a large-scale collection of over 10,000 music-dance video pairs for training and testing. Experimental results on the MD dataset demonstrate the superiority of our method over existing baselines, achieving state-of-the-art performance. The code and dataset will be made public available upon acceptance.