 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Exploring the Emotional Landscape of Music: An Analysis of Valence Trends and Genre Variations in Spotify Music Data
Oct 29, 2023
This paper conducts an intricate analysis of musical emotions and trends using Spotify music data, encompassing audio features and valence scores extracted through the Spotipi API. Employing regression modeling, temporal analysis, mood transitions, and genre investigation, the study uncovers patterns within music-emotion relationships. Regression models linear, support vector, random forest, and ridge, are employed to predict valence scores. Temporal analysis reveals shifts in valence distribution over time, while mood transition exploration illuminates emotional dynamics within playlists. The research contributes to nuanced insights into music's emotional fabric, enhancing comprehension of the interplay between music and emotions through years.
JEN-1 Composer: A Unified Framework for High-Fidelity Multi-Track Music Generation
Nov 03, 2023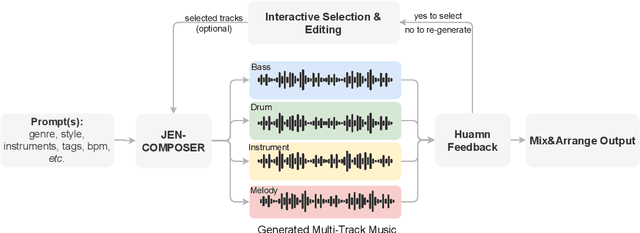
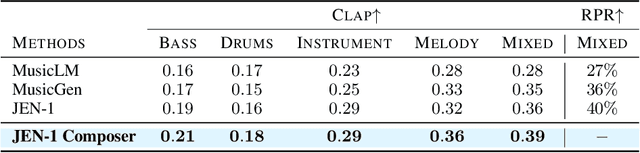
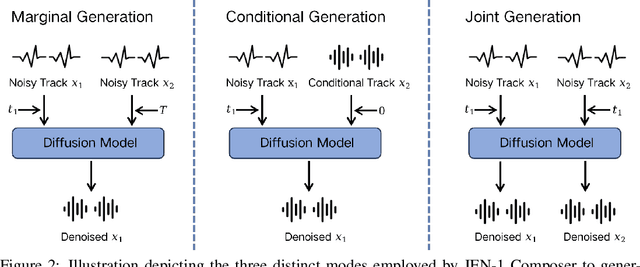
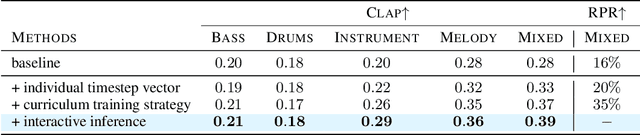
With rapid advances in generative artificial intelligence, the text-to-music synthesis task has emerged as a promising direction for music generation from scratch. However, finer-grained control over multi-track generation remains an open challenge. Existing models exhibit strong raw generation capability but lack the flexibility to compose separate tracks and combine them in a controllable manner, differing from typical workflows of human composers. To address this issue, we propose JEN-1 Composer, a unified framework to efficiently model marginal, conditional, and joint distributions over multi-track music via a single model. JEN-1 Composer framework exhibits the capacity to seamlessly incorporate any diffusion-based music generation system, \textit{e.g.} Jen-1, enhancing its capacity for versatile multi-track music generation. We introduce a curriculum training strategy aimed at incrementally instructing the model in the transition from single-track generation to the flexible generation of multi-track combinations. During the inference, users have the ability to iteratively produce and choose music tracks that meet their preferences, subsequently creating an entire musical composition incrementally following the proposed Human-AI co-composition workflow. Quantitative and qualitative assessments demonstrate state-of-the-art performance in controllable and high-fidelity multi-track music synthesis. The proposed JEN-1 Composer represents a significant advance toward interactive AI-facilitated music creation and composition. Demos will be available at https://www.jenmusic.ai/audio-demos.
Siamese Residual Neural Network for Musical Shape Evaluation in Piano Performance Assessment
Jan 04, 2024Understanding and identifying musical shape plays an important role in music education and performance assessment. To simplify the otherwise time- and cost-intensive musical shape evaluation, in this paper we explore how artificial intelligence (AI) driven models can be applied. Considering musical shape evaluation as a classification problem, a light-weight Siamese residual neural network (S-ResNN) is proposed to automatically identify musical shapes. To assess the proposed approach in the context of piano musical shape evaluation, we have generated a new dataset, containing 4116 music pieces derived by 147 piano preparatory exercises and performed in 28 categories of musical shapes. The experimental results show that the S-ResNN significantly outperforms a number of benchmark methods in terms of the precision, recall and F1 score.
An Explainable Proxy Model for Multiabel Audio Segmentation
Jan 17, 2024Audio signal segmentation is a key task for automatic audio indexing. It consists of detecting the boundaries of class-homogeneous segments in the signal. In many applications, explainable AI is a vital process for transparency of decision-making with machine learning. In this paper, we propose an explainable multilabel segmentation model that solves speech activity (SAD), music (MD), noise (ND), and overlapped speech detection (OSD) simultaneously. This proxy uses the non-negative matrix factorization (NMF) to map the embedding used for the segmentation to the frequency domain. Experiments conducted on two datasets show similar performances as the pre-trained black box model while showing strong explainability features. Specifically, the frequency bins used for the decision can be easily identified at both the segment level (local explanations) and global level (class prototypes).
Encoding Performance Data in MEI with the Automatic Music Performance Analysis and Comparison Toolkit (AMPACT)
Nov 19, 2023This paper presents a new method of encoding performance data in MEI using the recently added \texttt{<extData>} element. Performance data was extracted using the Automatic Music Performance Analysis and Comparison Toolkit (AMPACT) and encoded as a JSON object within an \texttt{<extData>} element linked to a specific musical note. A set of pop music vocals has was encoded to demonstrate both the range of descriptors that can be encoded in <extData> and how AMPACT can be used for extracting performance data in the absence of a fully specified musical score.
* 3 pages, 2 figures
Sounding Out Reconstruction Error-Based Evaluation of Generative Models of Expressive Performance
Dec 31, 2023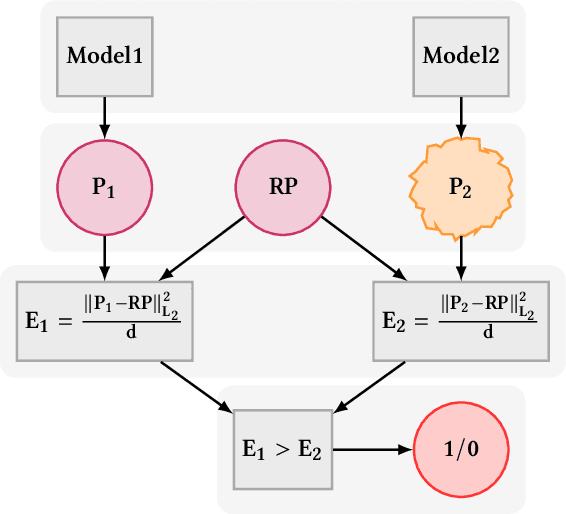
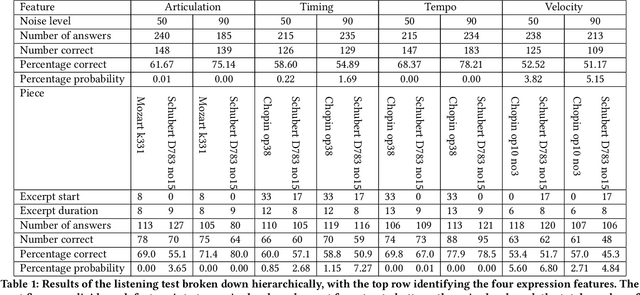
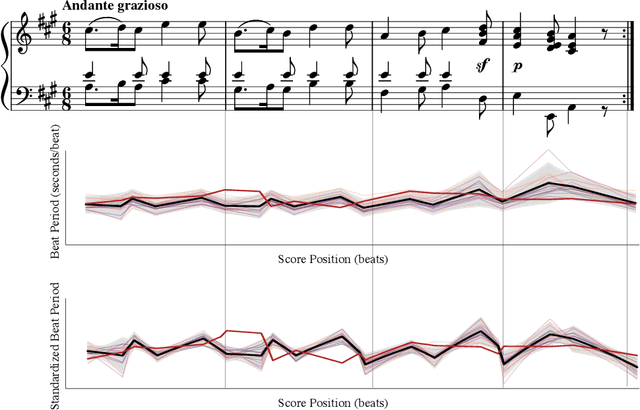
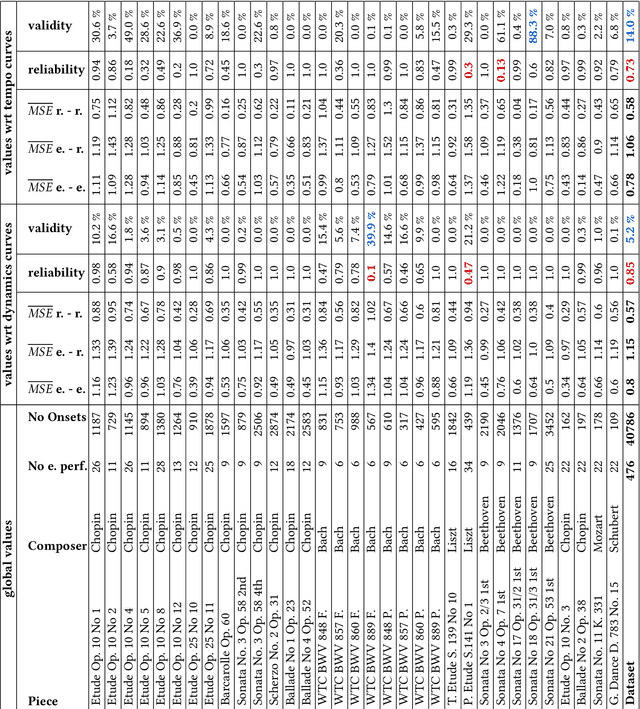
Generative models of expressive piano performance are usually assessed by comparing their predictions to a reference human performance. A generative algorithm is taken to be better than competing ones if it produces performances that are closer to a human reference performance. However, expert human performers can (and do) interpret music in different ways, making for different possible references, and quantitative closeness is not necessarily aligned with perceptual similarity, raising concerns about the validity of this evaluation approach. In this work, we present a number of experiments that shed light on this problem. Using precisely measured high-quality performances of classical piano music, we carry out a listening test indicating that listeners can sometimes perceive subtle performance difference that go unnoticed under quantitative evaluation. We further present tests that indicate that such evaluation frameworks show a lot of variability in reliability and validity across different reference performances and pieces. We discuss these results and their implications for quantitative evaluation, and hope to foster a critical appreciation of the uncertainties involved in quantitative assessments of such performances within the wider music information retrieval (MIR) community.
CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark
Jan 22, 2024As the capabilities of large multimodal models (LMMs) continue to advance, evaluating the performance of LMMs emerges as an increasing need. Additionally, there is an even larger gap in evaluating the advanced knowledge and reasoning abilities of LMMs in non-English contexts such as Chinese. We introduce CMMMU, a new Chinese Massive Multi-discipline Multimodal Understanding benchmark designed to evaluate LMMs on tasks demanding college-level subject knowledge and deliberate reasoning in a Chinese context. CMMMU is inspired by and strictly follows the annotation and analysis pattern of MMMU. CMMMU includes 12k manually collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering, like its companion, MMMU. These questions span 30 subjects and comprise 39 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. CMMMU focuses on complex perception and reasoning with domain-specific knowledge in the Chinese context. We evaluate 11 open-source LLMs and one proprietary GPT-4V(ision). Even GPT-4V only achieves accuracies of 42%, indicating a large space for improvement. CMMMU will boost the community to build the next-generation LMMs towards expert artificial intelligence and promote the democratization of LMMs by providing diverse language contexts.
MuseChat: A Conversational Music Recommendation System for Videos
Oct 11, 2023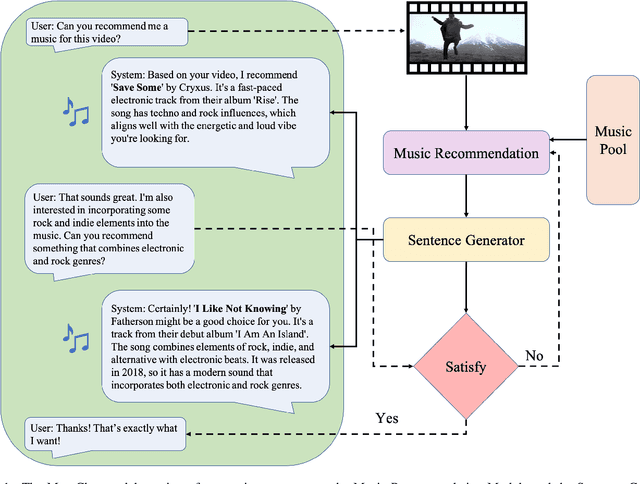

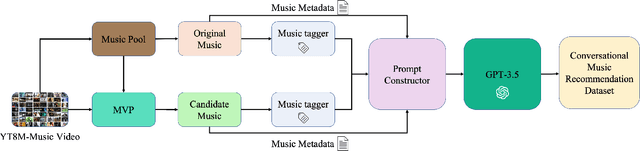

We introduce MuseChat, an innovative dialog-based music recommendation system. This unique platform not only offers interactive user engagement but also suggests music tailored for input videos, so that users can refine and personalize their music selections. In contrast, previous systems predominantly emphasized content compatibility, often overlooking the nuances of users' individual preferences. For example, all the datasets only provide basic music-video pairings or such pairings with textual music descriptions. To address this gap, our research offers three contributions. First, we devise a conversation-synthesis method that simulates a two-turn interaction between a user and a recommendation system, which leverages pre-trained music tags and artist information. In this interaction, users submit a video to the system, which then suggests a suitable music piece with a rationale. Afterwards, users communicate their musical preferences, and the system presents a refined music recommendation with reasoning. Second, we introduce a multi-modal recommendation engine that matches music either by aligning it with visual cues from the video or by harmonizing visual information, feedback from previously recommended music, and the user's textual input. Third, we bridge music representations and textual data with a Large Language Model(Vicuna-7B). This alignment equips MuseChat to deliver music recommendations and their underlying reasoning in a manner resembling human communication. Our evaluations show that MuseChat surpasses existing state-of-the-art models in music retrieval tasks and pioneers the integration of the recommendation process within a natural language framework.
EXPLORE -- Explainable Song Recommendation
Dec 30, 2023This study explores the development of an explainable music recommendation system with enhanced user control. Leveraging a hybrid of collaborative filtering and content-based filtering, we address the challenges of opaque recommendation logic and lack of user influence on results. We present a novel approach combining advanced algorithms and an interactive user interface. Our methodology integrates Spotify data with user preference analytics to tailor music suggestions. Evaluation through RMSE and user studies underscores the efficacy and user satisfaction with our system. The paper concludes with potential directions for future enhancements in group recommendations and dynamic feedback integration.