 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
SMITIN: Self-Monitored Inference-Time INtervention for Generative Music Transformers
Apr 02, 2024
We introduce Self-Monitored Inference-Time INtervention (SMITIN), an approach for controlling an autoregressive generative music transformer using classifier probes. These simple logistic regression probes are trained on the output of each attention head in the transformer using a small dataset of audio examples both exhibiting and missing a specific musical trait (e.g., the presence/absence of drums, or real/synthetic music). We then steer the attention heads in the probe direction, ensuring the generative model output captures the desired musical trait. Additionally, we monitor the probe output to avoid adding an excessive amount of intervention into the autoregressive generation, which could lead to temporally incoherent music. We validate our results objectively and subjectively for both audio continuation and text-to-music applications, demonstrating the ability to add controls to large generative models for which retraining or even fine-tuning is impractical for most musicians. Audio samples of the proposed intervention approach are available on our demo page http://tinyurl.com/smitin .
Audio Dialogues: Dialogues dataset for audio and music understanding
Apr 11, 2024Existing datasets for audio understanding primarily focus on single-turn interactions (i.e. audio captioning, audio question answering) for describing audio in natural language, thus limiting understanding audio via interactive dialogue. To address this gap, we introduce Audio Dialogues: a multi-turn dialogue dataset containing 163.8k samples for general audio sounds and music. In addition to dialogues, Audio Dialogues also has question-answer pairs to understand and compare multiple input audios together. Audio Dialogues leverages a prompting-based approach and caption annotations from existing datasets to generate multi-turn dialogues using a Large Language Model (LLM). We evaluate existing audio-augmented large language models on our proposed dataset to demonstrate the complexity and applicability of Audio Dialogues. Our code for generating the dataset will be made publicly available. Detailed prompts and generated dialogues can be found on the demo website https://audiodialogues.github.io/.
A Novel Audio Representation for Music Genre Identification in MIR
Apr 01, 2024For Music Information Retrieval downstream tasks, the most common audio representation is time-frequency-based, such as Mel spectrograms. In order to identify musical genres, this study explores the possibilities of a new form of audio representation one of the most usual MIR downstream tasks. Therefore, to discretely encoding music using deep vector quantization; a novel audio representation was created for the innovative generative music model i.e. Jukebox. The effectiveness of Jukebox's audio representation is compared to Mel spectrograms using a dataset that is almost equivalent to State-of-the-Art (SOTA) and an almost same transformer design. The results of this study imply that, at least when the transformers are pretrained using a very modest dataset of 20k tracks, Jukebox's audio representation is not superior to Mel spectrograms. This could be explained by the fact that Jukebox's audio representation does not sufficiently take into account the peculiarities of human hearing perception. On the other hand, Mel spectrograms are specifically created with the human auditory sense in mind.
Practical End-to-End Optical Music Recognition for Pianoform Music
Mar 20, 2024
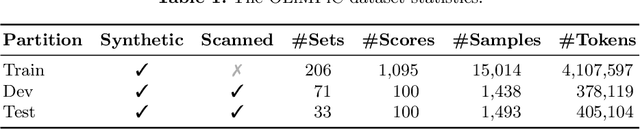
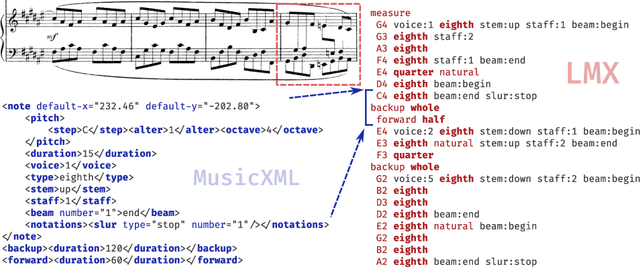

The majority of recent progress in Optical Music Recognition (OMR) has been achieved with Deep Learning methods, especially models following the end-to-end paradigm, reading input images and producing a linear sequence of tokens. Unfortunately, many music scores, especially piano music, cannot be easily converted to a linear sequence. This has led OMR researchers to use custom linearized encodings, instead of broadly accepted structured formats for music notation. Their diversity makes it difficult to compare the performance of OMR systems directly. To bring recent OMR model progress closer to useful results: (a) We define a sequential format called Linearized MusicXML, allowing to train an end-to-end model directly and maintaining close cohesion and compatibility with the industry-standard MusicXML format. (b) We create a dev and test set for benchmarking typeset OMR with MusicXML ground truth based on the OpenScore Lieder corpus. They contain 1,438 and 1,493 pianoform systems, each with an image from IMSLP. (c) We train and fine-tune an end-to-end model to serve as a baseline on the dataset and employ the TEDn metric to evaluate the model. We also test our model against the recently published synthetic pianoform dataset GrandStaff and surpass the state-of-the-art results.
Jointly Recognizing Speech and Singing Voices Based on Multi-Task Audio Source Separation
Apr 17, 2024In short video and live broadcasts, speech, singing voice, and background music often overlap and obscure each other. This complexity creates difficulties in structuring and recognizing the audio content, which may impair subsequent ASR and music understanding applications. This paper proposes a multi-task audio source separation (MTASS) based ASR model called JRSV, which Jointly Recognizes Speech and singing Voices. Specifically, the MTASS module separates the mixed audio into distinct speech and singing voice tracks while removing background music. The CTC/attention hybrid recognition module recognizes both tracks. Online distillation is proposed to improve the robustness of recognition further. To evaluate the proposed methods, a benchmark dataset is constructed and released. Experimental results demonstrate that JRSV can significantly improve recognition accuracy on each track of the mixed audio.
A Diffusion-Based Generative Equalizer for Music Restoration
Mar 27, 2024This paper presents a novel approach to audio restoration, focusing on the enhancement of low-quality music recordings, and in particular historical ones. Building upon a previous algorithm called BABE, or Blind Audio Bandwidth Extension, we introduce BABE-2, which presents a series of significant improvements. This research broadens the concept of bandwidth extension to \emph{generative equalization}, a novel task that, to the best of our knowledge, has not been explicitly addressed in previous studies. BABE-2 is built around an optimization algorithm utilizing priors from diffusion models, which are trained or fine-tuned using a curated set of high-quality music tracks. The algorithm simultaneously performs two critical tasks: estimation of the filter degradation magnitude response and hallucination of the restored audio. The proposed method is objectively evaluated on historical piano recordings, showing a marked enhancement over the prior version. The method yields similarly impressive results in rejuvenating the works of renowned vocalists Enrico Caruso and Nellie Melba. This research represents an advancement in the practical restoration of historical music.
Shotit: compute-efficient image-to-video search engine for the cloud
Apr 18, 2024With the rapid growth of information technology, users are exposed to a massive amount of data online, including image, music, and video. This has led to strong needs to provide effective corresponsive search services such as image, music, and video search services. Most of them are operated based on keywords, namely using keywords to find related image, music, and video. Additionally, there are image-to-image search services that enable users to find similar images using one input image. Given that videos are essentially composed of image frames, then similar videos can be searched by one input image or screenshot. We want to target this scenario and provide an efficient method and implementation in this paper. We present Shotit, a cloud-native image-to-video search engine that tailors this search scenario in a compute-efficient approach. One main limitation faced in this scenario is the scale of its dataset. A typical image-to-image search engine only handles one-to-one relationships, colloquially, one image corresponds to another single image. But image-to-video proliferates. Take a 24-min length video as an example, it will generate roughly 20,000 image frames. As the number of videos grows, the scale of the dataset explodes exponentially. In this case, a compute-efficient approach ought to be considered, and the system design should cater to the cloud-native trend. Choosing an emerging technology - vector database as its backbone, Shotit fits these two metrics performantly. Experiments for two different datasets, a 50 thousand-scale Blender Open Movie dataset, and a 50 million-scale proprietary TV genre dataset at a 4 Core 32GB RAM Intel Xeon Gold 6271C cloud machine with object storage reveal the effectiveness of Shotit. A demo regarding the Blender Open Movie dataset is illustrated within this paper.
Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
Apr 18, 2024Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, \textit{MUSIC-AVQA-R}, crafted in two steps: rephrasing questions within the test split of a public dataset (\textit{MUSIC-AVQA}) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on both datasets, especially obtaining a significant improvement of 9.68\% on the proposed dataset. Extensive ablation experiments are conducted on these two datasets to validate the effectiveness of the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset.
DanceCamera3D: 3D Camera Movement Synthesis with Music and Dance
Mar 20, 2024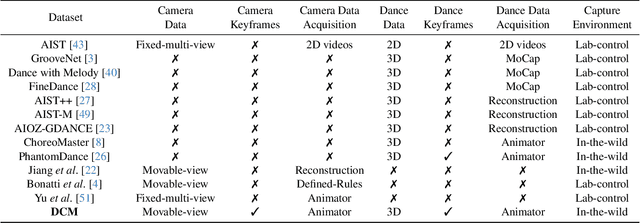
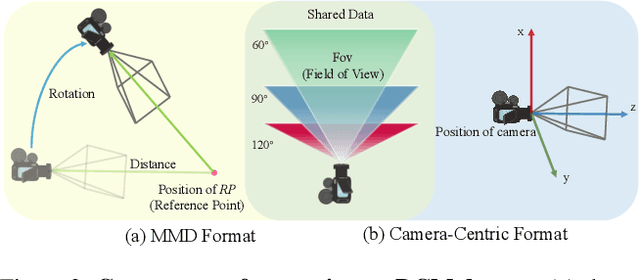
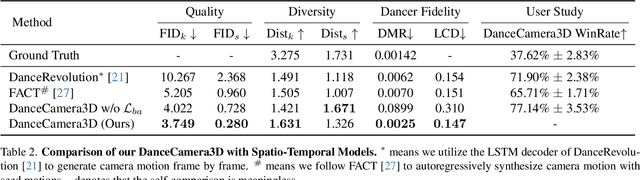
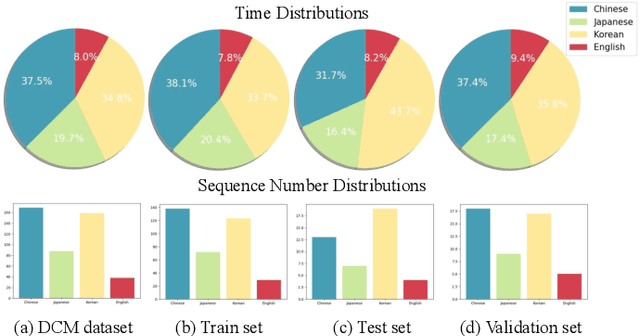
Choreographers determine what the dances look like, while cameramen determine the final presentation of dances. Recently, various methods and datasets have showcased the feasibility of dance synthesis. However, camera movement synthesis with music and dance remains an unsolved challenging problem due to the scarcity of paired data. Thus, we present DCM, a new multi-modal 3D dataset, which for the first time combines camera movement with dance motion and music audio. This dataset encompasses 108 dance sequences (3.2 hours) of paired dance-camera-music data from the anime community, covering 4 music genres. With this dataset, we uncover that dance camera movement is multifaceted and human-centric, and possesses multiple influencing factors, making dance camera synthesis a more challenging task compared to camera or dance synthesis alone. To overcome these difficulties, we propose DanceCamera3D, a transformer-based diffusion model that incorporates a novel body attention loss and a condition separation strategy. For evaluation, we devise new metrics measuring camera movement quality, diversity, and dancer fidelity. Utilizing these metrics, we conduct extensive experiments on our DCM dataset, providing both quantitative and qualitative evidence showcasing the effectiveness of our DanceCamera3D model. Code and video demos are available at https://github.com/Carmenw1203/DanceCamera3D-Official.
Music to Dance as Language Translation using Sequence Models
Mar 22, 2024Synthesising appropriate choreographies from music remains an open problem. We introduce MDLT, a novel approach that frames the choreography generation problem as a translation task. Our method leverages an existing data set to learn to translate sequences of audio into corresponding dance poses. We present two variants of MDLT: one utilising the Transformer architecture and the other employing the Mamba architecture. We train our method on AIST++ and PhantomDance data sets to teach a robotic arm to dance, but our method can be applied to a full humanoid robot. Evaluation metrics, including Average Joint Error and Frechet Inception Distance, consistently demonstrate that, when given a piece of music, MDLT excels at producing realistic and high-quality choreography. The code can be found at github.com/meowatthemoon/MDLT.