 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Self-Supervised Music Source Separation Using Vector-Quantized Source Category Estimates
Nov 21, 2023
Music source separation is focused on extracting distinct sonic elements from composite tracks. Historically, many methods have been grounded in supervised learning, necessitating labeled data, which is occasionally constrained in its diversity. More recent methods have delved into N-shot techniques that utilize one or more audio samples to aid in the separation. However, a challenge with some of these methods is the necessity for an audio query during inference, making them less suited for genres with varied timbres and effects. This paper offers a proof-of-concept for a self-supervised music source separation system that eliminates the need for audio queries at inference time. In the training phase, while it adopts a query-based approach, we introduce a modification by substituting the continuous embedding of query audios with Vector Quantized (VQ) representations. Trained end-to-end with up to N classes as determined by the VQ's codebook size, the model seeks to effectively categorise instrument classes. During inference, the input is partitioned into N sources, with some potentially left unutilized based on the mix's instrument makeup. This methodology suggests an alternative avenue for considering source separation across diverse music genres. We provide examples and additional results online.
Prompt Smells: An Omen for Undesirable Generative AI Outputs
Jan 23, 2024Recent Generative Artificial Intelligence (GenAI) trends focus on various applications, including creating stories, illustrations, poems, articles, computer code, music compositions, and videos. Extrinsic hallucinations are a critical limitation of such GenAI, which can lead to significant challenges in achieving and maintaining the trustworthiness of GenAI. In this paper, we propose two new concepts that we believe will aid the research community in addressing limitations associated with the application of GenAI models. First, we propose a definition for the "desirability" of GenAI outputs and three factors which are observed to influence it. Second, drawing inspiration from Martin Fowler's code smells, we propose the concept of "prompt smells" and the adverse effects they are observed to have on the desirability of GenAI outputs. We expect our work will contribute to the ongoing conversation about the desirability of GenAI outputs and help advance the field in a meaningful way.
Video2Music: Suitable Music Generation from Videos using an Affective Multimodal Transformer model
Nov 02, 2023Numerous studies in the field of music generation have demonstrated impressive performance, yet virtually no models are able to directly generate music to match accompanying videos. In this work, we develop a generative music AI framework, Video2Music, that can match a provided video. We first curated a unique collection of music videos. Then, we analysed the music videos to obtain semantic, scene offset, motion, and emotion features. These distinct features are then employed as guiding input to our music generation model. We transcribe the audio files into MIDI and chords, and extract features such as note density and loudness. This results in a rich multimodal dataset, called MuVi-Sync, on which we train a novel Affective Multimodal Transformer (AMT) model to generate music given a video. This model includes a novel mechanism to enforce affective similarity between video and music. Finally, post-processing is performed based on a biGRU-based regression model to estimate note density and loudness based on the video features. This ensures a dynamic rendering of the generated chords with varying rhythm and volume. In a thorough experiment, we show that our proposed framework can generate music that matches the video content in terms of emotion. The musical quality, along with the quality of music-video matching is confirmed in a user study. The proposed AMT model, along with the new MuVi-Sync dataset, presents a promising step for the new task of music generation for videos.
MotionMix: Weakly-Supervised Diffusion for Controllable Motion Generation
Jan 24, 2024Controllable generation of 3D human motions becomes an important topic as the world embraces digital transformation. Existing works, though making promising progress with the advent of diffusion models, heavily rely on meticulously captured and annotated (e.g., text) high-quality motion corpus, a resource-intensive endeavor in the real world. This motivates our proposed MotionMix, a simple yet effective weakly-supervised diffusion model that leverages both noisy and unannotated motion sequences. Specifically, we separate the denoising objectives of a diffusion model into two stages: obtaining conditional rough motion approximations in the initial $T-T^*$ steps by learning the noisy annotated motions, followed by the unconditional refinement of these preliminary motions during the last $T^*$ steps using unannotated motions. Notably, though learning from two sources of imperfect data, our model does not compromise motion generation quality compared to fully supervised approaches that access gold data. Extensive experiments on several benchmarks demonstrate that our MotionMix, as a versatile framework, consistently achieves state-of-the-art performances on text-to-motion, action-to-motion, and music-to-dance tasks. Project page: https://nhathoang2002.github.io/MotionMix-page/
Resource-constrained stereo singing voice cancellation
Jan 22, 2024We study the problem of stereo singing voice cancellation, a subtask of music source separation, whose goal is to estimate an instrumental background from a stereo mix. We explore how to achieve performance similar to large state-of-the-art source separation networks starting from a small, efficient model for real-time speech separation. Such a model is useful when memory and compute are limited and singing voice processing has to run with limited look-ahead. In practice, this is realised by adapting an existing mono model to handle stereo input. Improvements in quality are obtained by tuning model parameters and expanding the training set. Moreover, we highlight the benefits a stereo model brings by introducing a new metric which detects attenuation inconsistencies between channels. Our approach is evaluated using objective offline metrics and a large-scale MUSHRA trial, confirming the effectiveness of our techniques in stringent listening tests.
Within-basket Recommendation via Neural Pattern Associator
Jan 25, 2024Within-basket recommendation (WBR) refers to the task of recommending items to the end of completing a non-empty shopping basket during a shopping session. While the latest innovations in this space demonstrate remarkable performance improvement on benchmark datasets, they often overlook the complexity of user behaviors in practice, such as 1) co-existence of multiple shopping intentions, 2) multi-granularity of such intentions, and 3) interleaving behavior (switching intentions) in a shopping session. This paper presents Neural Pattern Associator (NPA), a deep item-association-mining model that explicitly models the aforementioned factors. Specifically, inspired by vector quantization, the NPA model learns to encode common user intentions (or item-combination patterns) as quantized representations (a.k.a. codebook), which permits identification of users's shopping intentions via attention-driven lookup during the reasoning phase. This yields coherent and self-interpretable recommendations. We evaluated the proposed NPA model across multiple extensive datasets, encompassing the domains of grocery e-commerce (shopping basket completion) and music (playlist extension), where our quantitative evaluations show that the NPA model significantly outperforms a wide range of existing WBR solutions, reflecting the benefit of explicitly modeling complex user intentions.
Emotion-Aware Music Recommendation System: Enhancing User Experience Through Real-Time Emotional Context
Nov 17, 2023
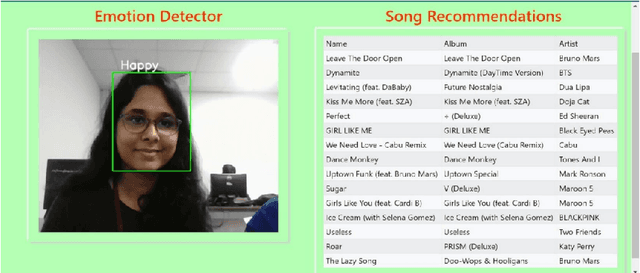

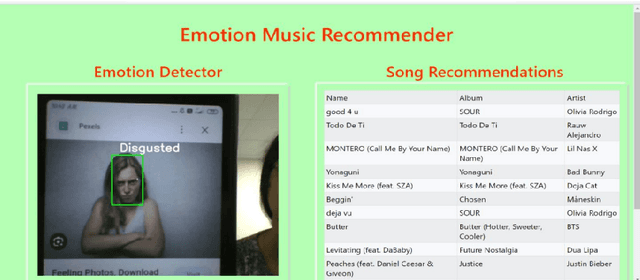
This study addresses the deficiency in conventional music recommendation systems by focusing on the vital role of emotions in shaping users music choices. These systems often disregard the emotional context, relying predominantly on past listening behavior and failing to consider the dynamic and evolving nature of users emotional preferences. This gap leads to several limitations. Users may receive recommendations that do not match their current mood, which diminishes the quality of their music experience. Furthermore, without accounting for emotions, the systems might overlook undiscovered or lesser-known songs that have a profound emotional impact on users. To combat these limitations, this research introduces an AI model that incorporates emotional context into the song recommendation process. By accurately detecting users real-time emotions, the model can generate personalized song recommendations that align with the users emotional state. This approach aims to enhance the user experience by offering music that resonates with their current mood, elicits the desired emotions, and creates a more immersive and meaningful listening experience. By considering emotional context in the song recommendation process, the proposed model offers an opportunity for a more personalized and emotionally resonant musical journey.
Exploring the Emotional Landscape of Music: An Analysis of Valence Trends and Genre Variations in Spotify Music Data
Oct 29, 2023This paper conducts an intricate analysis of musical emotions and trends using Spotify music data, encompassing audio features and valence scores extracted through the Spotipi API. Employing regression modeling, temporal analysis, mood transitions, and genre investigation, the study uncovers patterns within music-emotion relationships. Regression models linear, support vector, random forest, and ridge, are employed to predict valence scores. Temporal analysis reveals shifts in valence distribution over time, while mood transition exploration illuminates emotional dynamics within playlists. The research contributes to nuanced insights into music's emotional fabric, enhancing comprehension of the interplay between music and emotions through years.
JEN-1 Composer: A Unified Framework for High-Fidelity Multi-Track Music Generation
Nov 03, 2023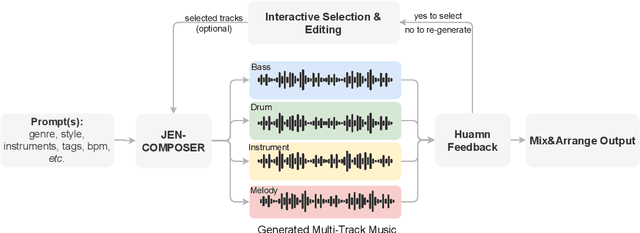
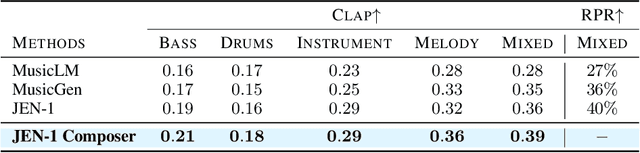
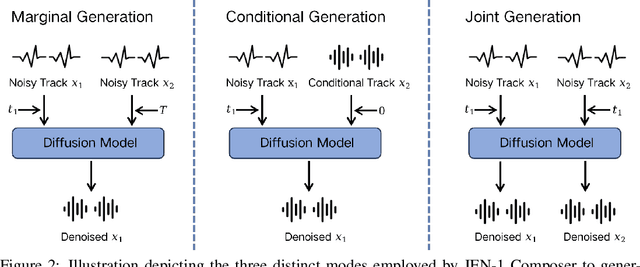
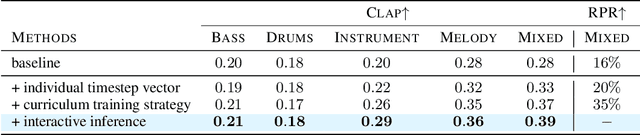
With rapid advances in generative artificial intelligence, the text-to-music synthesis task has emerged as a promising direction for music generation from scratch. However, finer-grained control over multi-track generation remains an open challenge. Existing models exhibit strong raw generation capability but lack the flexibility to compose separate tracks and combine them in a controllable manner, differing from typical workflows of human composers. To address this issue, we propose JEN-1 Composer, a unified framework to efficiently model marginal, conditional, and joint distributions over multi-track music via a single model. JEN-1 Composer framework exhibits the capacity to seamlessly incorporate any diffusion-based music generation system, \textit{e.g.} Jen-1, enhancing its capacity for versatile multi-track music generation. We introduce a curriculum training strategy aimed at incrementally instructing the model in the transition from single-track generation to the flexible generation of multi-track combinations. During the inference, users have the ability to iteratively produce and choose music tracks that meet their preferences, subsequently creating an entire musical composition incrementally following the proposed Human-AI co-composition workflow. Quantitative and qualitative assessments demonstrate state-of-the-art performance in controllable and high-fidelity multi-track music synthesis. The proposed JEN-1 Composer represents a significant advance toward interactive AI-facilitated music creation and composition. Demos will be available at https://www.jenmusic.ai/audio-demos.
Siamese Residual Neural Network for Musical Shape Evaluation in Piano Performance Assessment
Jan 04, 2024Understanding and identifying musical shape plays an important role in music education and performance assessment. To simplify the otherwise time- and cost-intensive musical shape evaluation, in this paper we explore how artificial intelligence (AI) driven models can be applied. Considering musical shape evaluation as a classification problem, a light-weight Siamese residual neural network (S-ResNN) is proposed to automatically identify musical shapes. To assess the proposed approach in the context of piano musical shape evaluation, we have generated a new dataset, containing 4116 music pieces derived by 147 piano preparatory exercises and performed in 28 categories of musical shapes. The experimental results show that the S-ResNN significantly outperforms a number of benchmark methods in terms of the precision, recall and F1 score.