 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Equipping Pretrained Unconditional Music Transformers with Instrument and Genre Controls
Nov 21, 2023
The ''pretraining-and-finetuning'' paradigm has become a norm for training domain-specific models in natural language processing and computer vision. In this work, we aim to examine this paradigm for symbolic music generation through leveraging the largest ever symbolic music dataset sourced from the MuseScore forum. We first pretrain a large unconditional transformer model using 1.5 million songs. We then propose a simple technique to equip this pretrained unconditional music transformer model with instrument and genre controls by finetuning the model with additional control tokens. Our proposed representation offers improved high-level controllability and expressiveness against two existing representations. The experimental results show that the proposed model can successfully generate music with user-specified instruments and genre. In a subjective listening test, the proposed model outperforms the pretrained baseline model in terms of coherence, harmony, arrangement and overall quality.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 28, 2023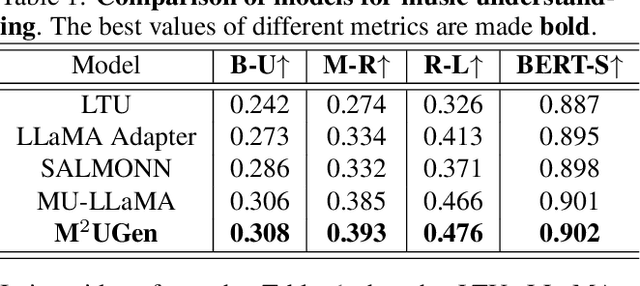
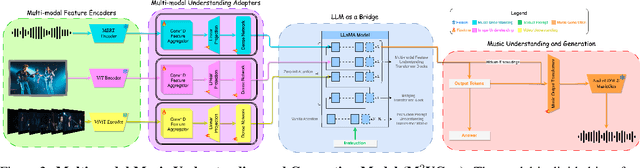
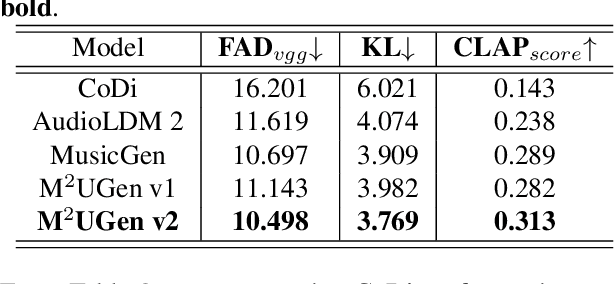
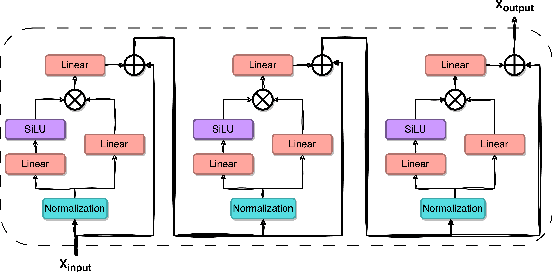
The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
Retrieval Augmented Generation of Symbolic Music with LLMs
Nov 17, 2023We explore the use of large language models (LLMs) for music generation using a retrieval system to select relevant examples. We find promising initial results for music generation in a dialogue with the user, especially considering the ease with which such a system can be implemented. The code is available online.
"All of Me": Mining Users' Attributes from their Public Spotify Playlists
Jan 25, 2024In the age of digital music streaming, playlists on platforms like Spotify have become an integral part of individuals' musical experiences. People create and publicly share their own playlists to express their musical tastes, promote the discovery of their favorite artists, and foster social connections. These publicly accessible playlists transcend the boundaries of mere musical preferences: they serve as sources of rich insights into users' attributes and identities. For example, the musical preferences of elderly individuals may lean more towards Frank Sinatra, while Billie Eilish remains a favored choice among teenagers. These playlists thus become windows into the diverse and evolving facets of one's musical identity. In this work, we investigate the relationship between Spotify users' attributes and their public playlists. In particular, we focus on identifying recurring musical characteristics associated with users' individual attributes, such as demographics, habits, or personality traits. To this end, we conducted an online survey involving 739 Spotify users, yielding a dataset of 10,286 publicly shared playlists encompassing over 200,000 unique songs and 55,000 artists. Through extensive statistical analyses, we first assess a deep connection between a user's Spotify playlists and their real-life attributes. For instance, we found individuals high in openness often create playlists featuring a diverse array of artists, while female users prefer Pop and K-pop music genres. Building upon these observed associations, we create accurate predictive models for users' attributes, presenting a novel DeepSet application that outperforms baselines in most of these users' attributes.
Parametric Near-Field Channel Estimation for Extremely Large Aperture Arrays
Jan 31, 2024Accurate channel estimation is critical to fully exploit the beamforming gains when communicating with extremely large aperture arrays. The propagation distances between the user and receiver, which potentially has thousands of antennas/elements, are such that they are located in the radiative near-field region of each other when considering the Fraunhofer distance of the entire array. Therefore, it is imperative to consider near-field effects to achieve proper channel estimation. This paper proposes a parametric multi-user near-field channel estimation algorithm based on MUltiple SIgnal Classification (MUSIC) method to obtain the essential parameters describing the users' locations. We derive the estimated channel by incorporating the estimated parameters into the near-field channel model. Additionally, we implement a least-squares-based estimation corrector, resulting in a precise near-field channel estimation. Simulation results demonstrate that our proposed scheme outperforms classical least-squares and minimum mean-square error channel estimation methods in terms of normalized beamforming gain and normalized mean-square error.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 18, 2023We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
Revisiting proximity effect using broadband signals
Jan 11, 2024Experiments studying mainly proximity effect are presented. Pink noise and music were used as stimuli and a combo guitar amplifier as source to test several microphones: omnidirectional and directional. We plot in-axis levels and spectral balances as functions of x, the distance to the source. Proximity effect was found for omnidirectional microphones. In-axis level curves show that 1/x law seems poorly valid. Spectral balance evolutions depend on microphones and moreover on stimuli: bigger decreases of low frequencies with pink noise; larger increases of other frequencies with music. For a naked loudspeaker, we found similar in-axis level curves under and above the cut-off frequency and propose an explanation. Listening equalized music recordings will help to demonstrate proximity effect for tested microphones.Paper 7106 presented at the 122th Convention of the Audio Engineering Society, Wien, 2007
An Exploratory Study of Multimodal Physiological Data in Jazz Improvisation Using Basic Machine Learning Techniques
Jan 22, 2024Our study delves into the "Embodied Musicking Dataset," exploring the intertwined relationships and correlations between physiological and psychological dimensions during improvisational music performances. The primary objective is to ascertain the presence of a definitive causal or correlational relationship between these states and comprehend their manifestation in musical compositions. This rich dataset provides a perspective on how musicians coordinate their physicality with sonic events in real-time improvisational scenarios, emphasizing the concept of "Embodied Musicking."
EVA-GAN: Enhanced Various Audio Generation via Scalable Generative Adversarial Networks
Jan 31, 2024The advent of Large Models marks a new era in machine learning, significantly outperforming smaller models by leveraging vast datasets to capture and synthesize complex patterns. Despite these advancements, the exploration into scaling, especially in the audio generation domain, remains limited, with previous efforts didn't extend into the high-fidelity (HiFi) 44.1kHz domain and suffering from both spectral discontinuities and blurriness in the high-frequency domain, alongside a lack of robustness against out-of-domain data. These limitations restrict the applicability of models to diverse use cases, including music and singing generation. Our work introduces Enhanced Various Audio Generation via Scalable Generative Adversarial Networks (EVA-GAN), yields significant improvements over previous state-of-the-art in spectral and high-frequency reconstruction and robustness in out-of-domain data performance, enabling the generation of HiFi audios by employing an extensive dataset of 36,000 hours of 44.1kHz audio, a context-aware module, a Human-In-The-Loop artifact measurement toolkit, and expands the model to approximately 200 million parameters. Demonstrations of our work are available at https://double-blind-eva-gan.cc.
mmID: High-Resolution mmWave Imaging for Human Identification
Feb 01, 2024Achieving accurate human identification through RF imaging has been a persistent challenge, primarily attributed to the limited aperture size and its consequent impact on imaging resolution. The existing imaging solution enables tasks such as pose estimation, activity recognition, and human tracking based on deep neural networks by estimating skeleton joints. In contrast to estimating joints, this paper proposes to improve imaging resolution by estimating the human figure as a whole using conditional generative adversarial networks (cGAN). In order to reduce training complexity, we use an estimated spatial spectrum using the MUltiple SIgnal Classification (MUSIC) algorithm as input to the cGAN. Our system generates environmentally independent, high-resolution images that can extract unique physical features useful for human identification. We use a simple convolution layers-based classification network to obtain the final identification result. From the experimental results, we show that resolution of the image produced by our trained generator is high enough to enable human identification. Our finding indicates high-resolution accuracy with 5% mean silhouette difference to the Kinect device. Extensive experiments in different environments on multiple testers demonstrate that our system can achieve 93% overall test accuracy in unseen environments for static human target identification.