 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension
Feb 12, 2024
Recently, instruction-following audio-language models have received broad attention for human-audio interaction. However, the absence of benchmarks capable of evaluating audio-centric interaction capabilities has impeded advancements in this field. Previous models primarily focus on assessing different fundamental tasks, such as Automatic Speech Recognition (ASR), and lack an assessment of the open-ended generative capabilities centered around audio. Thus, it is challenging to track the progression in the Large Audio-Language Models (LALMs) domain and to provide guidance for future improvement. In this paper, we introduce AIR-Bench (\textbf{A}udio \textbf{I}nst\textbf{R}uction \textbf{Bench}mark), the first benchmark designed to evaluate the ability of LALMs to understand various types of audio signals (including human speech, natural sounds, and music), and furthermore, to interact with humans in the textual format. AIR-Bench encompasses two dimensions: \textit{foundation} and \textit{chat} benchmarks. The former consists of 19 tasks with approximately 19k single-choice questions, intending to inspect the basic single-task ability of LALMs. The latter one contains 2k instances of open-ended question-and-answer data, directly assessing the comprehension of the model on complex audio and its capacity to follow instructions. Both benchmarks require the model to generate hypotheses directly. We design a unified framework that leverages advanced language models, such as GPT-4, to evaluate the scores of generated hypotheses given the meta-information of the audio. Experimental results demonstrate a high level of consistency between GPT-4-based evaluation and human evaluation. By revealing the limitations of existing LALMs through evaluation results, AIR-Bench can provide insights into the direction of future research.
mir_ref: A Representation Evaluation Framework for Music Information Retrieval Tasks
Dec 12, 2023Music Information Retrieval (MIR) research is increasingly leveraging representation learning to obtain more compact, powerful music audio representations for various downstream MIR tasks. However, current representation evaluation methods are fragmented due to discrepancies in audio and label preprocessing, downstream model and metric implementations, data availability, and computational resources, often leading to inconsistent and limited results. In this work, we introduce mir_ref, an MIR Representation Evaluation Framework focused on seamless, transparent, local-first experiment orchestration to support representation development. It features implementations of a variety of components such as MIR datasets, tasks, embedding models, and tools for result analysis and visualization, while facilitating the implementation of custom components. To demonstrate its utility, we use it to conduct an extensive evaluation of several embedding models across various tasks and datasets, including evaluating their robustness to various audio perturbations and the ease of extracting relevant information from them.
Pre-training Music Classification Models via Music Source Separation
Oct 24, 2023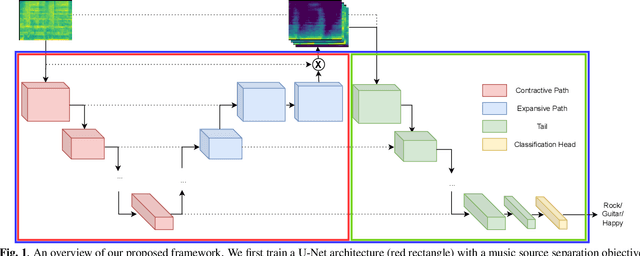
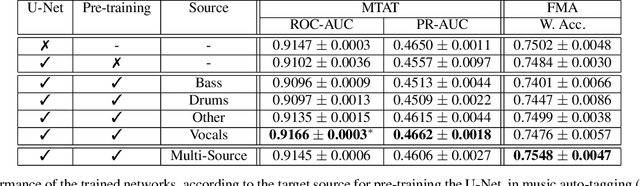
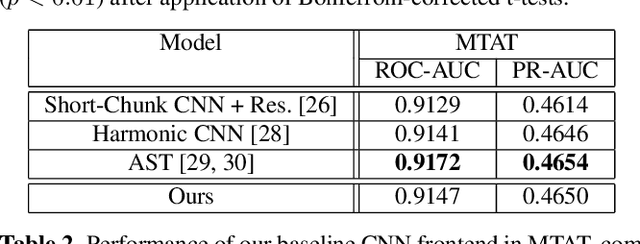
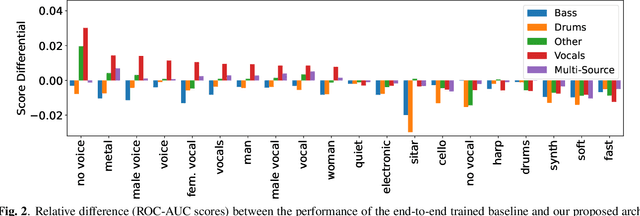
In this paper, we study whether music source separation can be used as a pre-training strategy for music representation learning, targeted at music classification tasks. To this end, we first pre-train U-Net networks under various music source separation objectives, such as the isolation of vocal or instrumental sources from a musical piece; afterwards, we attach a convolutional tail network to the pre-trained U-Net and jointly finetune the whole network. The features learned by the separation network are also propagated to the tail network through skip connections. Experimental results in two widely used and publicly available datasets indicate that pre-training the U-Nets with a music source separation objective can improve performance compared to both training the whole network from scratch and using the tail network as a standalone in two music classification tasks: music auto-tagging, when vocal separation is used, and music genre classification for the case of multi-source separation.
Annotation-Free Automatic Music Transcription with Scalable Synthetic Data and Adversarial Domain Confusion
Dec 16, 2023Automatic Music Transcription (AMT) is a crucial technology in music information processing. Despite recent improvements in performance through machine learning approaches, existing methods often achieve high accuracy in domains with abundant annotation data, primarily due to the difficulty of creating annotation data. A practical transcription model requires an architecture that does not require an annotation data. In this paper, we propose an annotation-free transcription model achieved through the utilization of scalable synthetic audio for pre-training and adversarial domain confusion using unannotated real audio. Through evaluation experiments, we confirm that our proposed method can achieve higher accuracy under annotation-free conditions compared to when learning with mixture of annotated real audio data. Additionally, through ablation studies, we gain insights into the scalability of this approach and the challenges that lie ahead in the field of AMT research.
The Music Meta Ontology: a flexible semantic model for the interoperability of music metadata
Nov 07, 2023The semantic description of music metadata is a key requirement for the creation of music datasets that can be aligned, integrated, and accessed for information retrieval and knowledge discovery. It is nonetheless an open challenge due to the complexity of musical concepts arising from different genres, styles, and periods -- standing to benefit from a lingua franca to accommodate various stakeholders (musicologists, librarians, data engineers, etc.). To initiate this transition, we introduce the Music Meta ontology, a rich and flexible semantic model to describe music metadata related to artists, compositions, performances, recordings, and links. We follow eXtreme Design methodologies and best practices for data engineering, to reflect the perspectives and the requirements of various stakeholders into the design of the model, while leveraging ontology design patterns and accounting for provenance at different levels (claims, links). After presenting the main features of Music Meta, we provide a first evaluation of the model, alignments to other schema (Music Ontology, DOREMUS, Wikidata), and support for data transformation.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 22, 2023We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
Machine Intelligence in Africa: a survey
Feb 03, 2024In the last 5 years, the availability of large audio datasets in African countries has opened unlimited opportunities to build machine intelligence (MI) technologies that are closer to the people and speak, learn, understand, and do businesses in local languages, including for those who cannot read and write. Unfortunately, these audio datasets are not fully exploited by current MI tools, leaving several Africans out of MI business opportunities. Additionally, many state-of-the-art MI models are not culture-aware, and the ethics of their adoption indexes are questionable. The lack thereof is a major drawback in many applications in Africa. This paper summarizes recent developments in machine intelligence in Africa from a multi-layer multiscale and culture-aware ethics perspective, showcasing MI use cases in 54 African countries through 400 articles on MI research, industry, government actions, as well as uses in art, music, the informal economy, and small businesses in Africa. The survey also opens discussions on the reliability of MI rankings and indexes in the African continent as well as algorithmic definitions of unclear terms used in MI.
Proceedings of the 5th International Workshop on Reading Music Systems
Nov 07, 2023The International Workshop on Reading Music Systems (WoRMS) is a workshop that tries to connect researchers who develop systems for reading music, such as in the field of Optical Music Recognition, with other researchers and practitioners that could benefit from such systems, like librarians or musicologists. The relevant topics of interest for the workshop include, but are not limited to: Music reading systems; Optical music recognition; Datasets and performance evaluation; Image processing on music scores; Writer identification; Authoring, editing, storing and presentation systems for music scores; Multi-modal systems; Novel input-methods for music to produce written music; Web-based Music Information Retrieval services; Applications and projects; Use-cases related to written music. These are the proceedings of the 5th International Workshop on Reading Music Systems, held in Milan, Italy on Nov. 4th 2023.
Equipping Pretrained Unconditional Music Transformers with Instrument and Genre Controls
Nov 21, 2023The ''pretraining-and-finetuning'' paradigm has become a norm for training domain-specific models in natural language processing and computer vision. In this work, we aim to examine this paradigm for symbolic music generation through leveraging the largest ever symbolic music dataset sourced from the MuseScore forum. We first pretrain a large unconditional transformer model using 1.5 million songs. We then propose a simple technique to equip this pretrained unconditional music transformer model with instrument and genre controls by finetuning the model with additional control tokens. Our proposed representation offers improved high-level controllability and expressiveness against two existing representations. The experimental results show that the proposed model can successfully generate music with user-specified instruments and genre. In a subjective listening test, the proposed model outperforms the pretrained baseline model in terms of coherence, harmony, arrangement and overall quality.
A fully differentiable model for unsupervised singing voice separation
Jan 30, 2024A novel model was recently proposed by Schulze-Forster et al. in [1] for unsupervised music source separation. This model allows to tackle some of the major shortcomings of existing source separation frameworks. Specifically, it eliminates the need for isolated sources during training, performs efficiently with limited data, and can handle homogeneous sources (such as singing voice). But, this model relies on an external multipitch estimator and incorporates an Ad hoc voice assignment procedure. In this paper, we propose to extend this framework and to build a fully differentiable model by integrating a multipitch estimator and a novel differentiable assignment module within the core model. We show the merits of our approach through a set of experiments, and we highlight in particular its potential for processing diverse and unseen data.