 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
A Two-stage U-Net for high-fidelity denoising of historical recordings
Feb 17, 2022
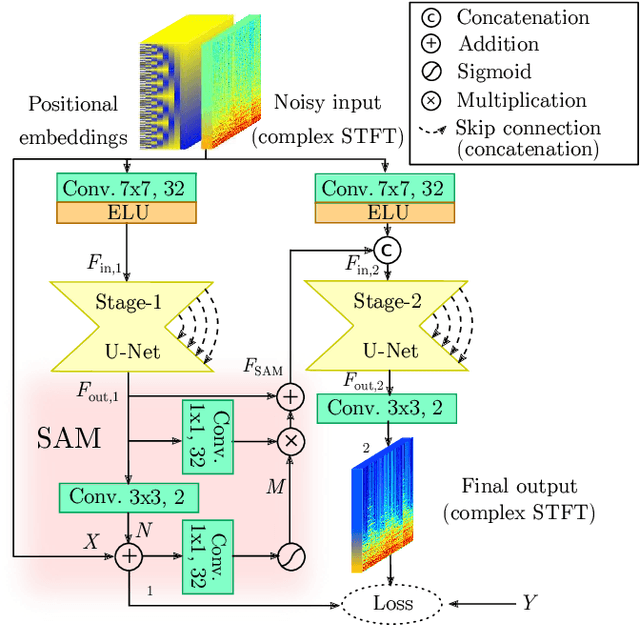
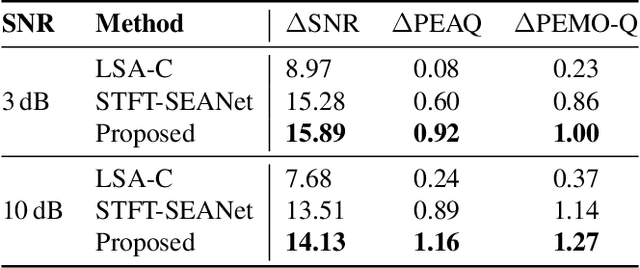
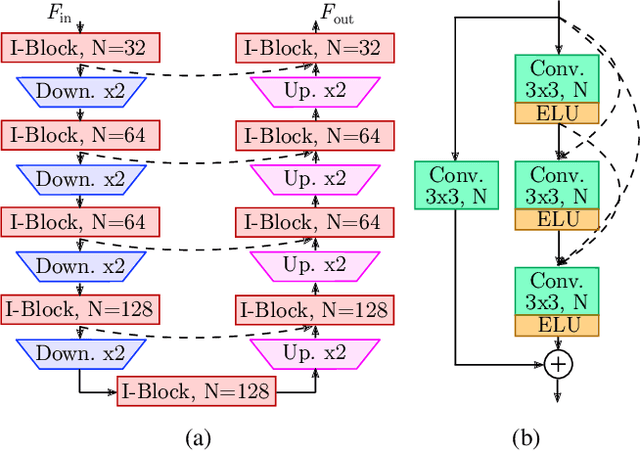
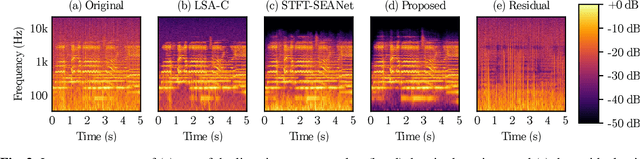
Enhancing the sound quality of historical music recordings is a long-standing problem. This paper presents a novel denoising method based on a fully-convolutional deep neural network. A two-stage U-Net model architecture is designed to model and suppress the degradations with high fidelity. The method processes the time-frequency representation of audio, and is trained using realistic noisy data to jointly remove hiss, clicks, thumps, and other common additive disturbances from old analog discs. The proposed model outperforms previous methods in both objective and subjective metrics. The results of a formal blind listening test show that real gramophone recordings denoised with this method have significantly better quality than the baseline methods. This study shows the importance of realistic training data and the power of deep learning in audio restoration.
Evaluating Music Recommender Systems for Groups
Jul 31, 2017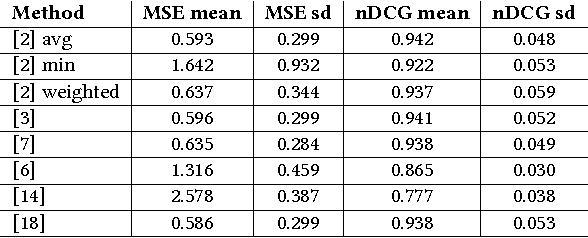
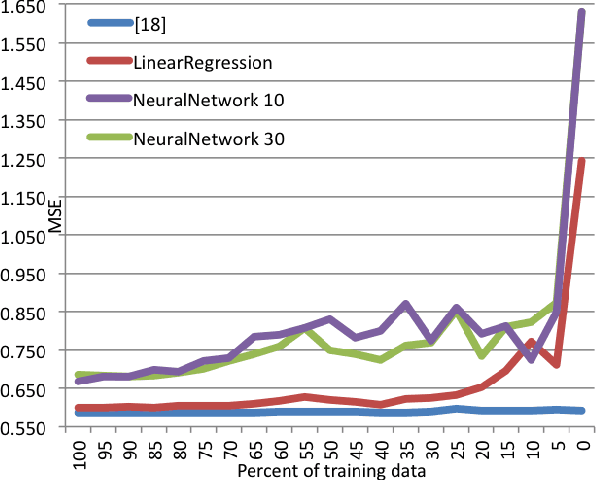
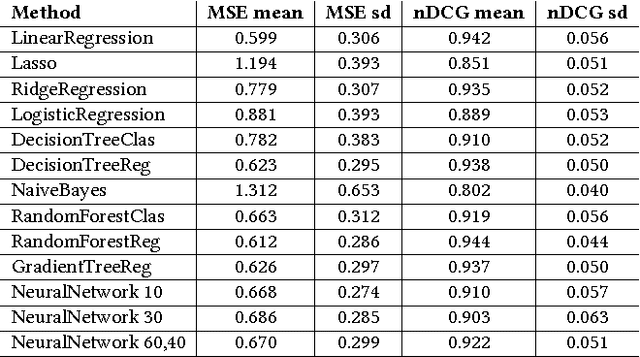
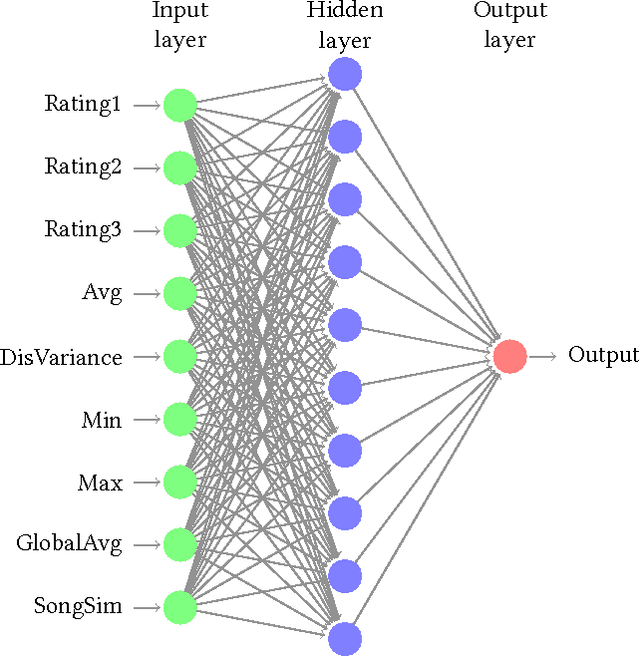
Recommendation to groups of users is a challenging and currently only passingly studied task. Especially the evaluation aspect often appears ad-hoc and instead of truly evaluating on groups of users, synthesizes groups by merging individual preferences. In this paper, we present a user study, recording the individual and shared preferences of actual groups of participants, resulting in a robust, standardized evaluation benchmark. Using this benchmarking dataset, that we share with the research community, we compare the respective performance of a wide range of music group recommendation techniques proposed in the
The artificial synesthete: Image-melody translations with variational autoencoders
Dec 06, 2021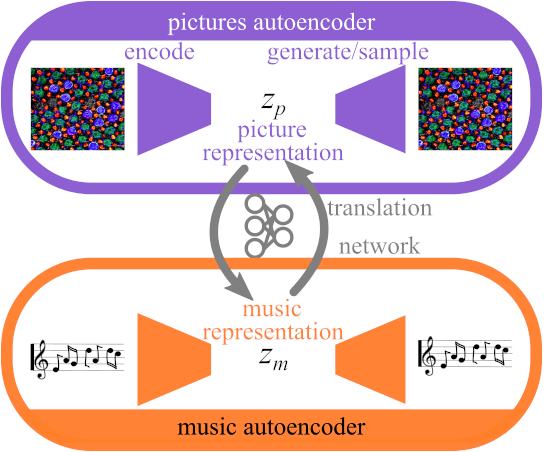
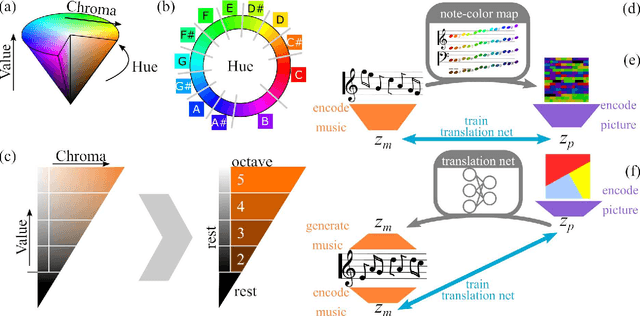
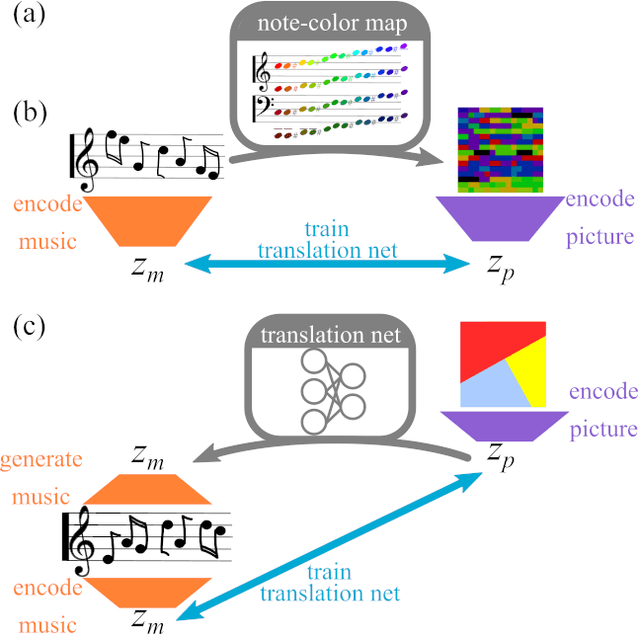
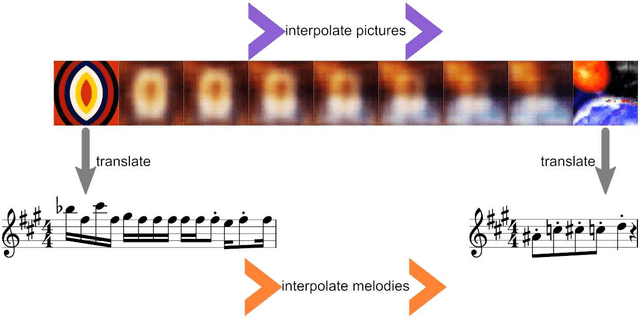
Abstract This project presents a system of neural networks to translate between images and melodies. Autoencoders compress the information in samples to abstract representation. A translation network learns a set of correspondences between musical and visual concepts from repeated joint exposure. The resulting "artificial synesthete" generates simple melodies inspired by images, and images from music. These are novel interpretation (not transposed data), expressing the machine' perception and understanding. Observing the work, one explores the machine's perception and thus, by contrast, one's own.
Style Imitation and Chord Invention in Polyphonic Music with Exponential Families
Sep 16, 2016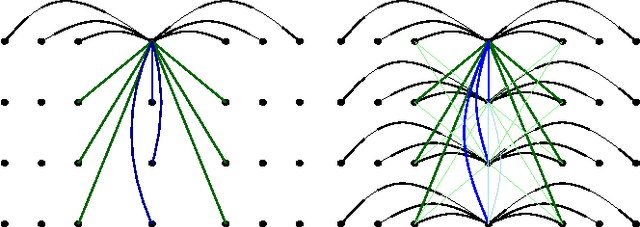
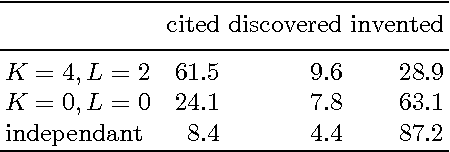

Modeling polyphonic music is a particularly challenging task because of the intricate interplay between melody and harmony. A good model should satisfy three requirements: statistical accuracy (capturing faithfully the statistics of correlations at various ranges, horizontally and vertically), flexibility (coping with arbitrary user constraints), and generalization capacity (inventing new material, while staying in the style of the training corpus). Models proposed so far fail on at least one of these requirements. We propose a statistical model of polyphonic music, based on the maximum entropy principle. This model is able to learn and reproduce pairwise statistics between neighboring note events in a given corpus. The model is also able to invent new chords and to harmonize unknown melodies. We evaluate the invention capacity of the model by assessing the amount of cited, re-discovered, and invented chords on a corpus of Bach chorales. We discuss how the model enables the user to specify and enforce user-defined constraints, which makes it useful for style-based, interactive music generation.
Polyphonic pitch detection with convolutional recurrent neural networks
Feb 04, 2022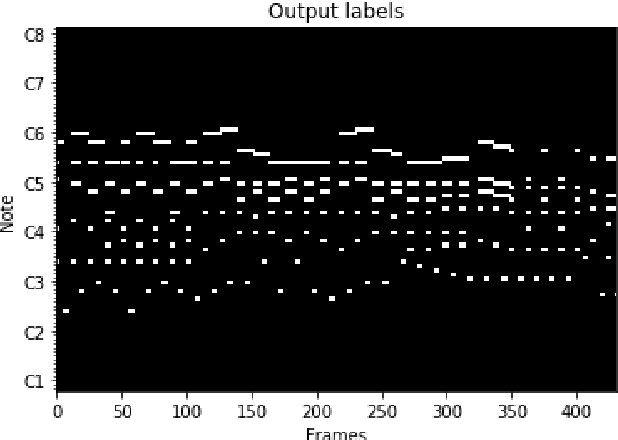
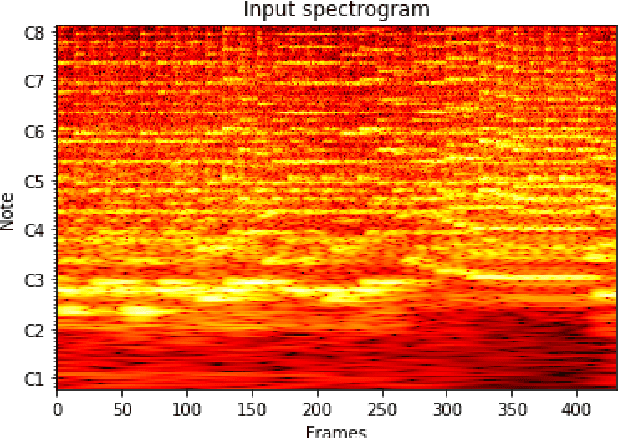
Recent directions in automatic speech recognition (ASR) research have shown that applying deep learning models from image recognition challenges in computer vision is beneficial. As automatic music transcription (AMT) is superficially similar to ASR, in the sense that methods often rely on transforming spectrograms to symbolic sequences of events (e.g. words or notes), deep learning should benefit AMT as well. In this work, we outline an online polyphonic pitch detection system that streams audio to MIDI by ConvLSTMs. Our system achieves state-of-the-art results on the 2007 MIREX multi-F0 development set, with an F-measure of 83\% on the bassoon, clarinet, flute, horn and oboe ensemble recording without requiring any musical language modelling or assumptions of instrument timbre.
An Audio Synthesis Framework Derived from Industrial Process Control
Sep 21, 2021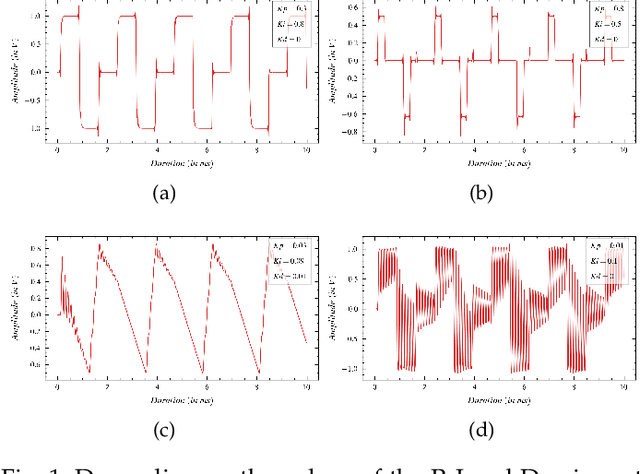
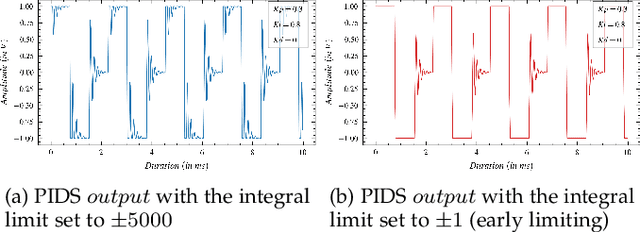
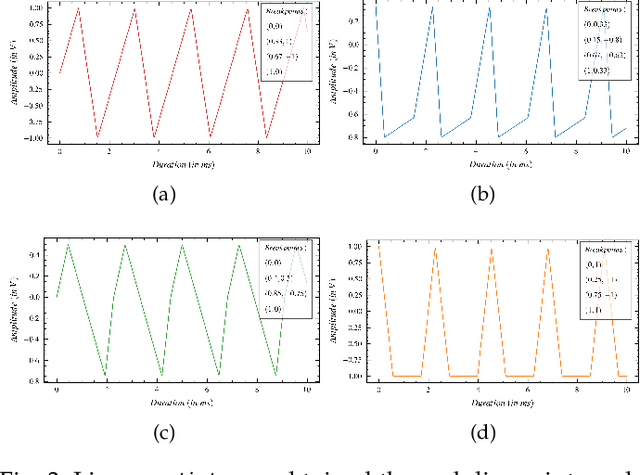
Since its conception, digital synthesis has significantly influenced the advancement of music, leading to new genres and production styles. Through existing synthesis techniques, one can recreate naturally occurring sounds as well as generate innovative artificial timbres. However, research in audio technology continues to pursue new methods of synthesizing sounds, keeping the transformation of music constant. This research attempts to formulate the framework of a new synthesis technique by redefining the popular Proportional-Integral-Derivative (PID) algorithm used in feedback-based process control. The framework is then implemented as a Python application to study the available control parameters and their effect on the synthesized output. Further, applications of this technique as an audio signal and LFO generator, including its potentiality as an alternative to FM and Wavetable synthesis techniques, are studied in detail. The research concludes by highlighting some of the imperfections in the current framework and the possible research directions to be considered to address them.
Basic Filters for Convolutional Neural Networks Applied to Music: Training or Design?
Sep 19, 2018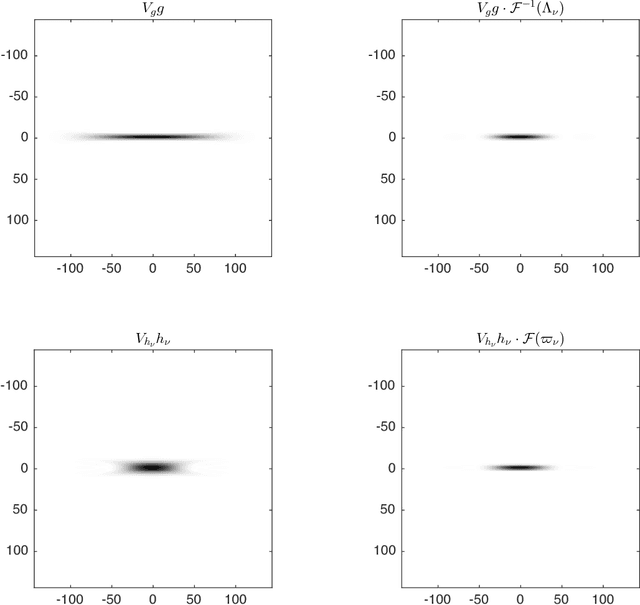
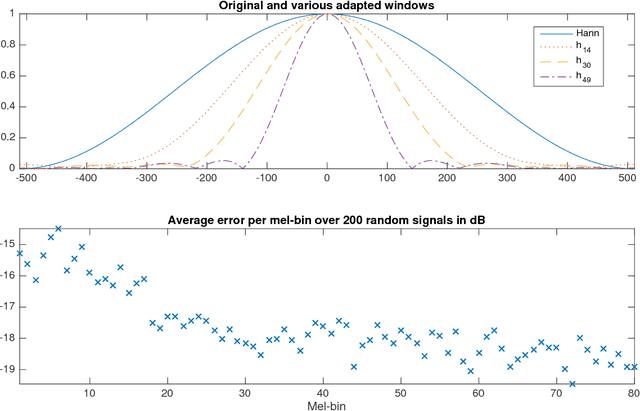
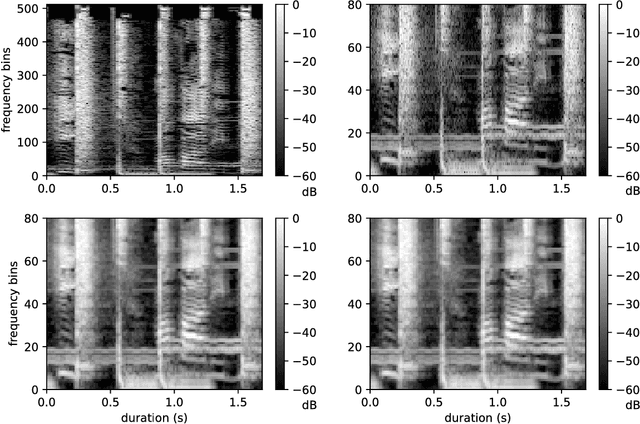
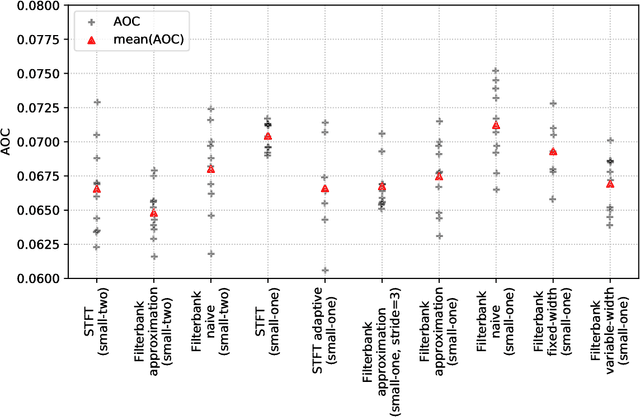
When convolutional neural networks are used to tackle learning problems based on music or, more generally, time series data, raw one-dimensional data are commonly pre-processed to obtain spectrogram or mel-spectrogram coefficients, which are then used as input to the actual neural network. In this contribution, we investigate, both theoretically and experimentally, the influence of this pre-processing step on the network's performance and pose the question, whether replacing it by applying adaptive or learned filters directly to the raw data, can improve learning success. The theoretical results show that approximately reproducing mel-spectrogram coefficients by applying adaptive filters and subsequent time-averaging is in principle possible. We also conducted extensive experimental work on the task of singing voice detection in music. The results of these experiments show that for classification based on Convolutional Neural Networks the features obtained from adaptive filter banks followed by time-averaging perform better than the canonical Fourier-transform-based mel-spectrogram coefficients. Alternative adaptive approaches with center frequencies or time-averaging lengths learned from training data perform equally well.
On Negative Sampling for Audio-Visual Contrastive Learning from Movies
Apr 29, 2022
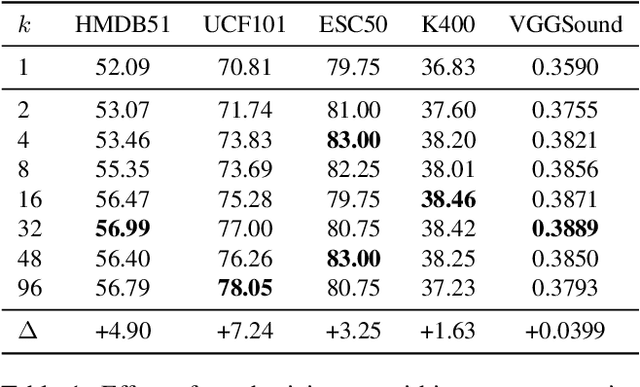
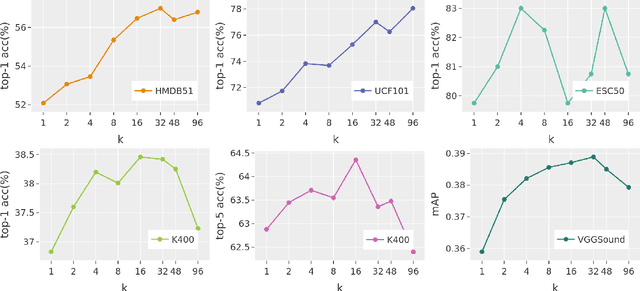
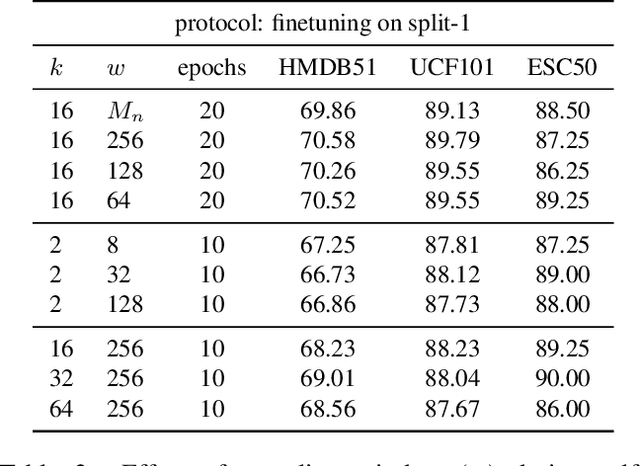
The abundance and ease of utilizing sound, along with the fact that auditory clues reveal a plethora of information about what happens in a scene, make the audio-visual space an intuitive choice for representation learning. In this paper, we explore the efficacy of audio-visual self-supervised learning from uncurated long-form content i.e movies. Studying its differences with conventional short-form content, we identify a non-i.i.d distribution of data, driven by the nature of movies. Specifically, we find long-form content to naturally contain a diverse set of semantic concepts (semantic diversity), where a large portion of them, such as main characters and environments often reappear frequently throughout the movie (reoccurring semantic concepts). In addition, movies often contain content-exclusive artistic artifacts, such as color palettes or thematic music, which are strong signals for uniquely distinguishing a movie (non-semantic consistency). Capitalizing on these observations, we comprehensively study the effect of emphasizing within-movie negative sampling in a contrastive learning setup. Our view is different from those of prior works who consider within-video positive sampling, inspired by the notion of semantic persistency over time, and operate in a short-video regime. Our empirical findings suggest that, with certain modifications, training on uncurated long-form videos yields representations which transfer competitively with the state-of-the-art to a variety of action recognition and audio classification tasks.
Multitask Learning for Fundamental Frequency Estimation in Music
Sep 02, 2018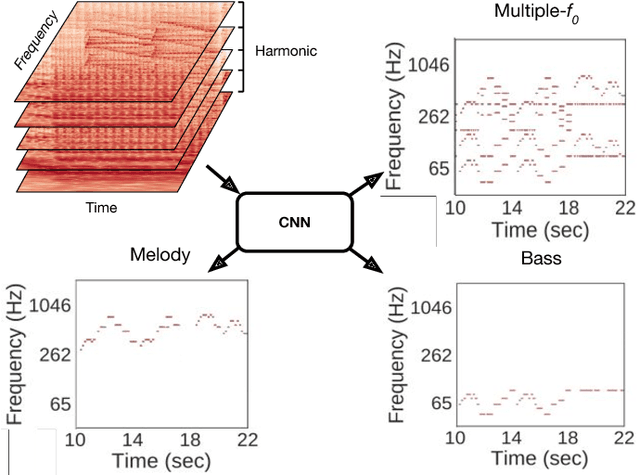
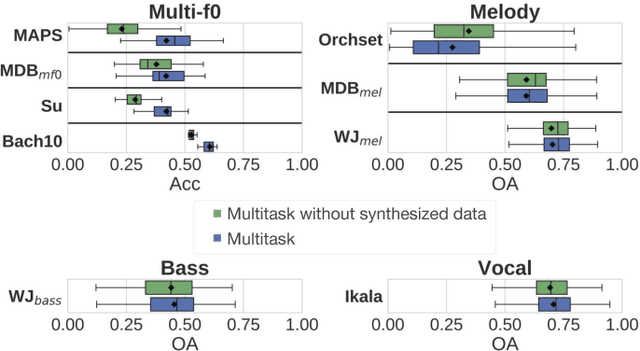
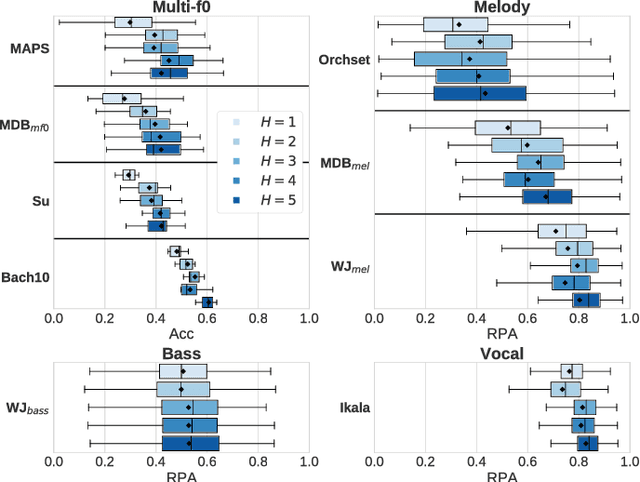
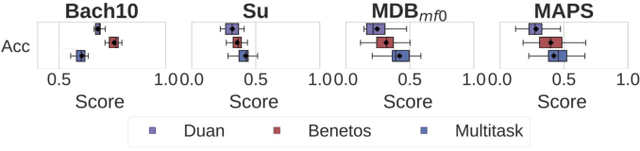
Fundamental frequency (f0) estimation from polyphonic music includes the tasks of multiple-f0, melody, vocal, and bass line estimation. Historically these problems have been approached separately, and only recently, using learning-based approaches. We present a multitask deep learning architecture that jointly estimates outputs for various tasks including multiple-f0, melody, vocal and bass line estimation, and is trained using a large, semi-automatically annotated dataset. We show that the multitask model outperforms its single-task counterparts, and explore the effect of various design decisions in our approach, and show that it performs better or at least competitively when compared against strong baseline methods.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 06, 2022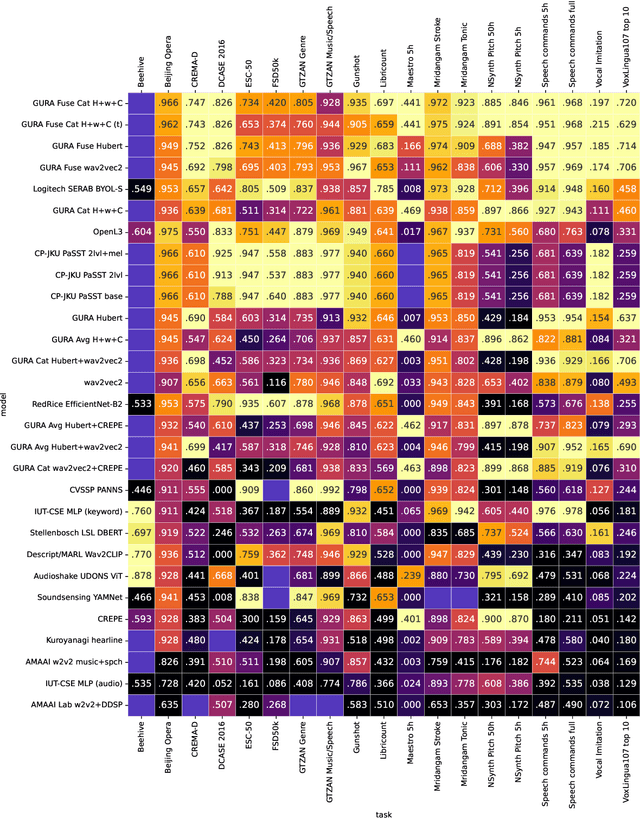
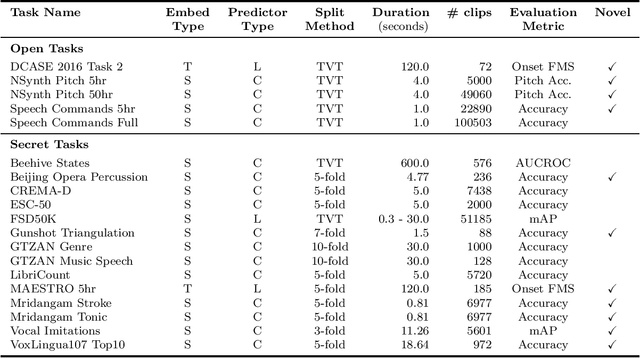

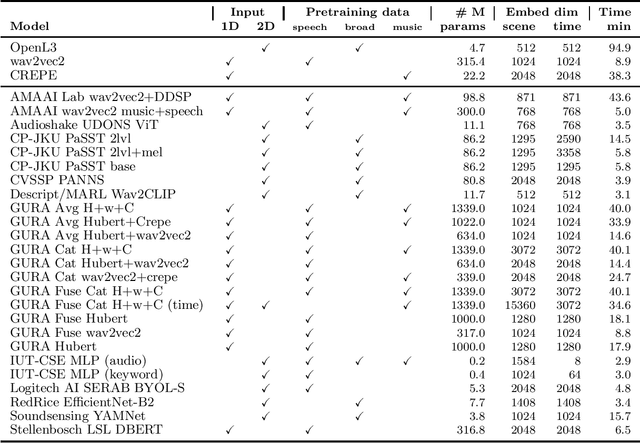
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.