 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Target Sensing with Intelligent Reflecting Surface: Architecture and Performance
Jan 22, 2022
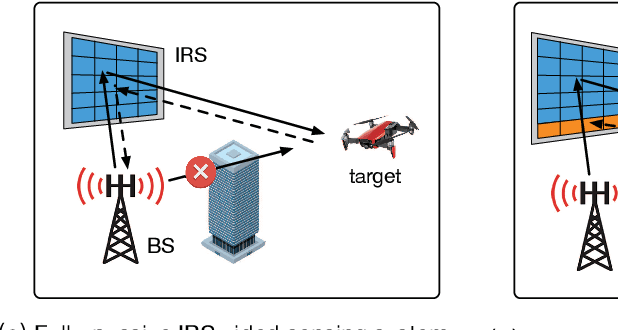
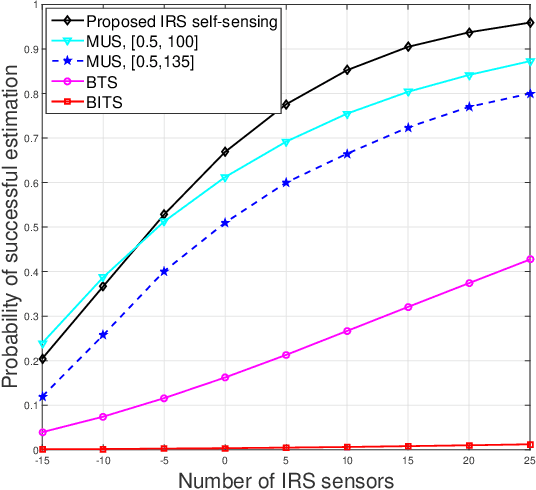
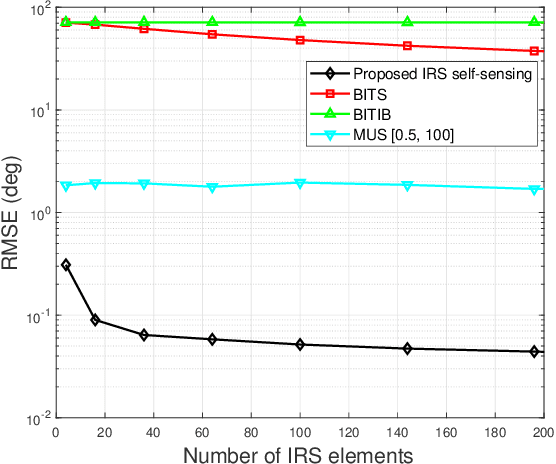
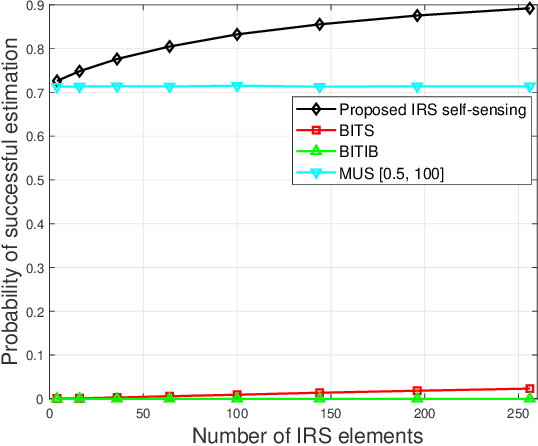
Intelligent reflecting surface (IRS) has emerged as a promising technology to reconfigure the radio propagation environment by dynamically controlling wireless signal's amplitude and/or phase via a large number of reflecting elements. In contrast to the vast literature on studying IRS's performance gains in wireless communications, we study in this paper a new application of IRS for sensing/localizing targets in wireless networks. Specifically, we propose a new self-sensing IRS architecture where the IRS controller is capable of transmitting probing signals that are not only directly reflected by the target (referred to as the direct echo link), but also consecutively reflected by the IRS and then the target (referred to as the IRS-reflected echo link). Moreover, dedicated sensors are installed at the IRS for receiving both the direct and IRS-reflected echo signals from the target, such that the IRS can sense the direction of its nearby target by applying a customized multiple signal classification (MUSIC) algorithm. However, since the angle estimation mean square error (MSE) by the MUSIC algorithm is intractable, we propose to optimize the IRS passive reflection for maximizing the average echo signals' total power at the IRS sensors and derive the resultant Cramer-Rao bound (CRB) of the angle estimation MSE. Last, numerical results are presented to show the effectiveness of the proposed new IRS sensing architecture and algorithm, as compared to other benchmark sensing systems/algorithms.
BacHMMachine: An Interpretable and Scalable Model for Algorithmic Harmonization for Four-part Baroque Chorales
Sep 15, 2021

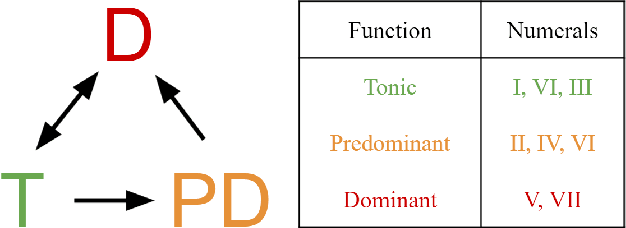

Algorithmic harmonization - the automated harmonization of a musical piece given its melodic line - is a challenging problem that has garnered much interest from both music theorists and computer scientists. One genre of particular interest is the four-part Baroque chorales of J.S. Bach. Methods for algorithmic chorale harmonization typically adopt a black-box, "data-driven" approach: they do not explicitly integrate principles from music theory but rely on a complex learning model trained with a large amount of chorale data. We propose instead a new harmonization model, called BacHMMachine, which employs a "theory-driven" framework guided by music composition principles, along with a "data-driven" model for learning compositional features within this framework. As its name suggests, BacHMMachine uses a novel Hidden Markov Model based on key and chord transitions, providing a probabilistic framework for learning key modulations and chordal progressions from a given melodic line. This allows for the generation of creative, yet musically coherent chorale harmonizations; integrating compositional principles allows for a much simpler model that results in vast decreases in computational burden and greater interpretability compared to state-of-the-art algorithmic harmonization methods, at no penalty to quality of harmonization or musicality. We demonstrate this improvement via comprehensive experiments and Turing tests comparing BacHMMachine to existing methods.
Karaoker: Alignment-free singing voice synthesis with speech training data
Apr 08, 2022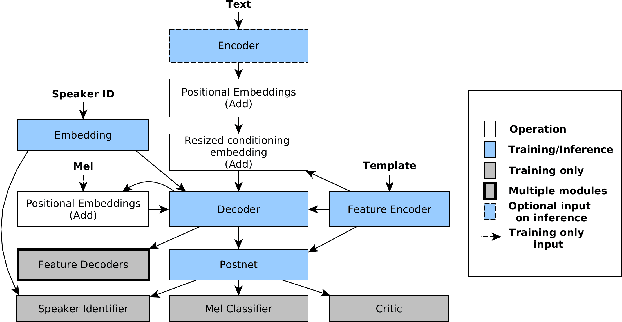
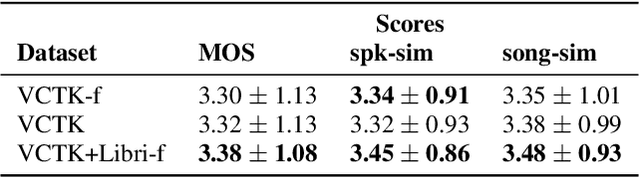
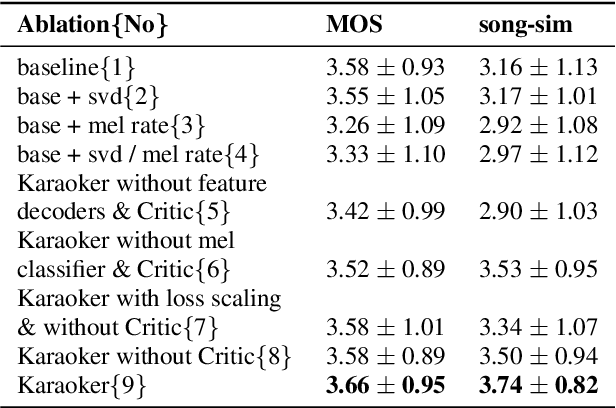
Existing singing voice synthesis models (SVS) are usually trained on singing data and depend on either error-prone time-alignment and duration features or explicit music score information. In this paper, we propose Karaoker, a multispeaker Tacotron-based model conditioned on voice characteristic features that is trained exclusively on spoken data without requiring time-alignments. Karaoker synthesizes singing voice following a multi-dimensional template extracted from a source waveform of an unseen speaker/singer. The model is jointly conditioned with a single deep convolutional encoder on continuous data including pitch, intensity, harmonicity, formants, cepstral peak prominence and octaves. We extend the text-to-speech training objective with feature reconstruction, classification and speaker identification tasks that guide the model to an accurate result. Except for multi-tasking, we also employ a Wasserstein GAN training scheme as well as new losses on the acoustic model's output to further refine the quality of the model.
Text-based LSTM networks for Automatic Music Composition
Apr 18, 2016

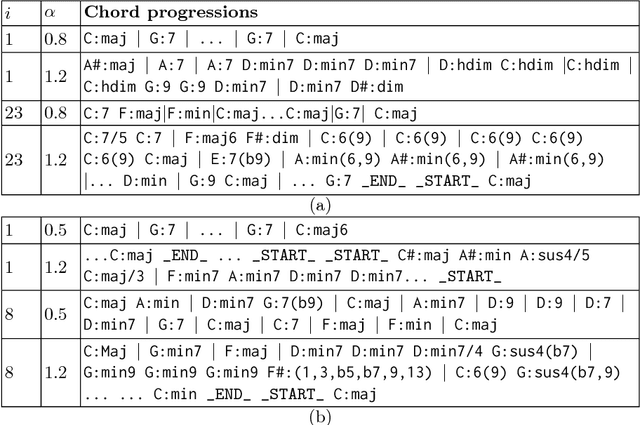
In this paper, we introduce new methods and discuss results of text-based LSTM (Long Short-Term Memory) networks for automatic music composition. The proposed network is designed to learn relationships within text documents that represent chord progressions and drum tracks in two case studies. In the experiments, word-RNNs (Recurrent Neural Networks) show good results for both cases, while character-based RNNs (char-RNNs) only succeed to learn chord progressions. The proposed system can be used for fully automatic composition or as semi-automatic systems that help humans to compose music by controlling a diversity parameter of the model.
Algorithmic Clustering of Music
Mar 24, 2003
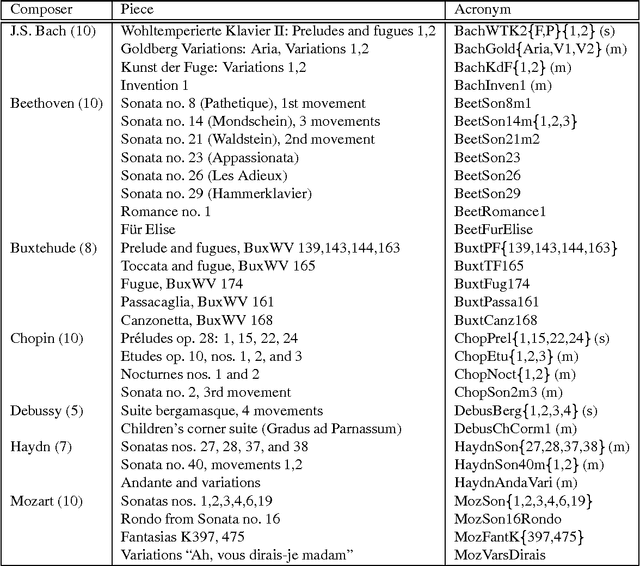

We present a fully automatic method for music classification, based only on compression of strings that represent the music pieces. The method uses no background knowledge about music whatsoever: it is completely general and can, without change, be used in different areas like linguistic classification and genomics. It is based on an ideal theory of the information content in individual objects (Kolmogorov complexity), information distance, and a universal similarity metric. Experiments show that the method distinguishes reasonably well between various musical genres and can even cluster pieces by composer.
A Statistical Model for Melody Reduction
May 12, 2021


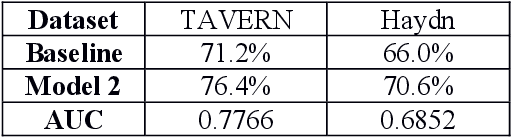
A commonly-cited reason for the poor performance of automatic chord estimation (ACE) systems within music information retrieval (MIR) is that non-chord tones (i.e., notes outside the supporting harmony) contribute to error during the labeling process. Despite the prevalence of machine learning approaches in MIR, there are cases where alternative approaches provide a simpler alternative while allowing for insights into musicological practices. In this project, we present a statistical model for predicting chord tones based on music theory rules. Our model is currently focused on predicting chord tones in classical music, since composition in this style is highly constrained, theoretically making the placement of chord tones highly predictable. Indeed, music theorists have labeling systems for every variety of non-chord tone, primarily classified by the note's metric position and intervals of approach and departure. Using metric position, duration, and melodic intervals as predictors, we build a statistical model for predicting chord tones using the TAVERN dataset. While our probabilistic approach is similar to other efforts in the domain of automatic harmonic analysis, our focus is on melodic reduction rather than predicting harmony. However, we hope to pursue applications for ACE in the future. Finally, we implement our melody reduction model using an existing symbolic visualization tool, to assist with melody reduction and non-chord tone identification for computational musicology researchers and music theorists.
Dance Generation with Style Embedding: Learning and Transferring Latent Representations of Dance Styles
Apr 30, 2021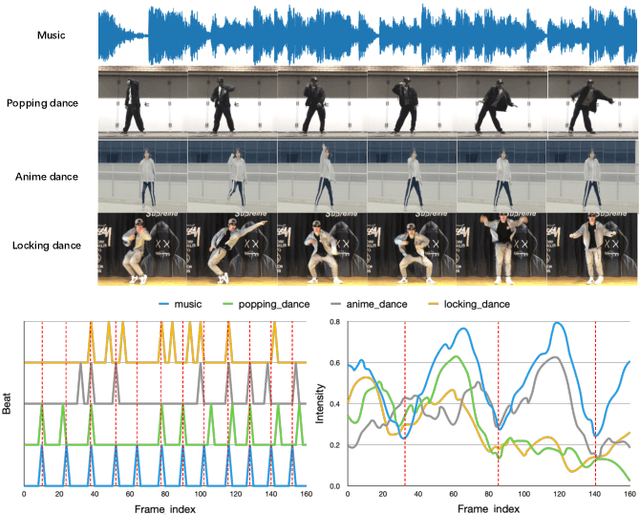
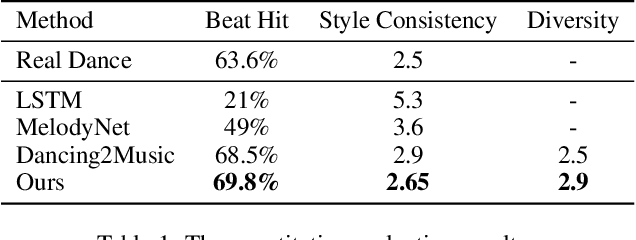
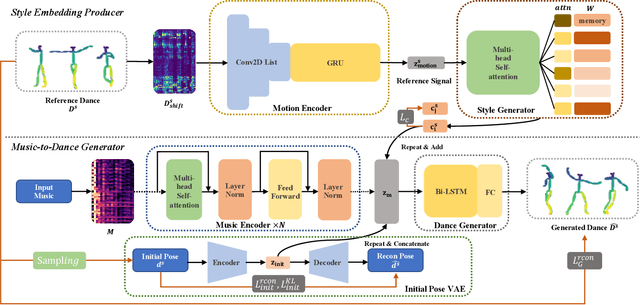
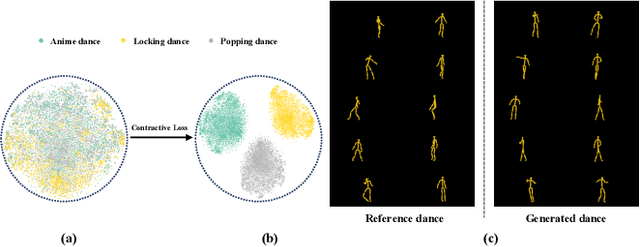
Choreography refers to creation of dance steps and motions for dances according to the latent knowledge in human mind, where the created dance motions are in general style-specific and consistent. So far, such latent style-specific knowledge about dance styles cannot be represented explicitly in human language and has not yet been learned in previous works on music-to-dance generation tasks. In this paper, we propose a novel music-to-dance synthesis framework with controllable style embeddings. These embeddings are learned representations of style-consistent kinematic abstraction of reference dance clips, which act as controllable factors to impose style constraints on dance generation in a latent manner. Thus, the dance styles can be transferred to dance motions by merely modifying the style embeddings. To support this study, we build a large music-to-dance dataset. The qualitative and quantitative evaluations demonstrate the advantage of our proposed framework, as well as the ability of synthesizing diverse styles of dances from identical music via style embeddings.
CycleDRUMS: Automatic Drum Arrangement For Bass Lines Using CycleGAN
Apr 09, 2021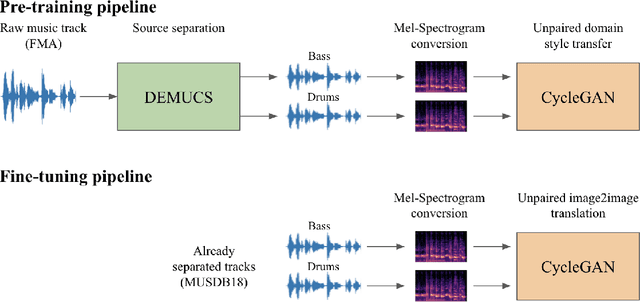
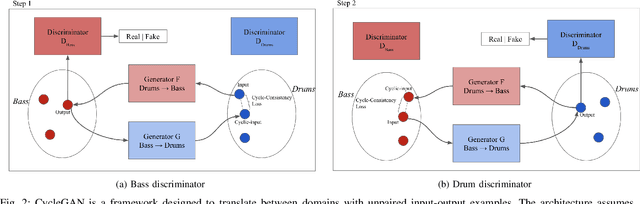
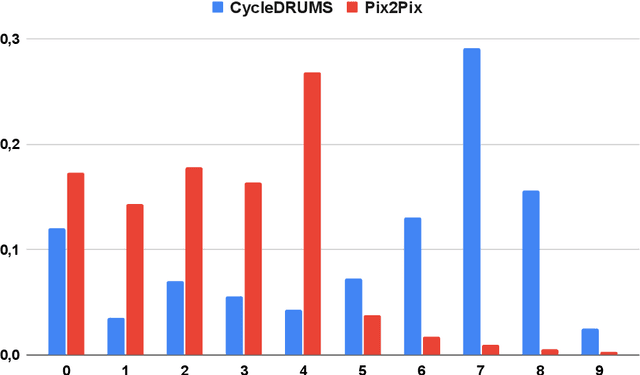
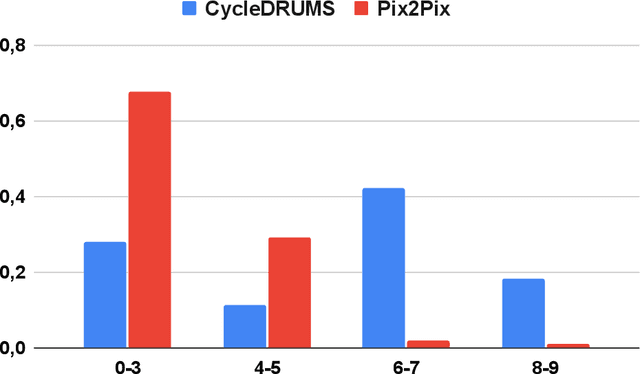
The two main research threads in computer-based music generation are: the construction of autonomous music-making systems, and the design of computer-based environments to assist musicians. In the symbolic domain, the key problem of automatically arranging a piece music was extensively studied, while relatively fewer systems tackled this challenge in the audio domain. In this contribution, we propose CycleDRUMS, a novel method for generating drums given a bass line. After converting the waveform of the bass into a mel-spectrogram, we are able to automatically generate original drums that follow the beat, sound credible and can be directly mixed with the input bass. We formulated this task as an unpaired image-to-image translation problem, and we addressed it with CycleGAN, a well-established unsupervised style transfer framework, originally designed for treating images. The choice to deploy raw audio and mel-spectrograms enabled us to better represent how humans perceive music, and to potentially draw sounds for new arrangements from the vast collection of music recordings accumulated in the last century. In absence of an objective way of evaluating the output of both generative adversarial networks and music generative systems, we further defined a possible metric for the proposed task, partially based on human (and expert) judgement. Finally, as a comparison, we replicated our results with Pix2Pix, a paired image-to-image translation network, and we showed that our approach outperforms it.
Music, Complexity, Information
Jul 03, 2008These are the preparatory notes for a Science & Music essay, "Playing by numbers", appeared in Nature 453 (2008) 988-989.
Nearly optimal resolution estimate for the two-dimensional super-resolution and a new algorithm for direction of arrival estimation with uniform rectangular array
May 14, 2022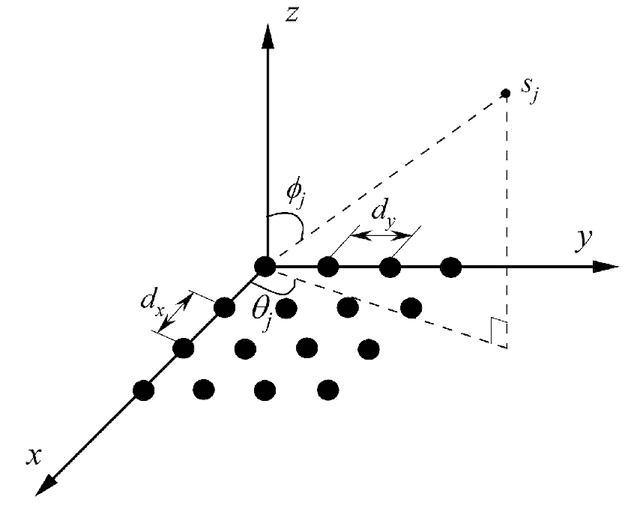
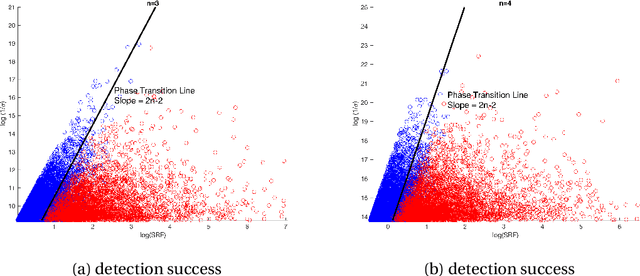
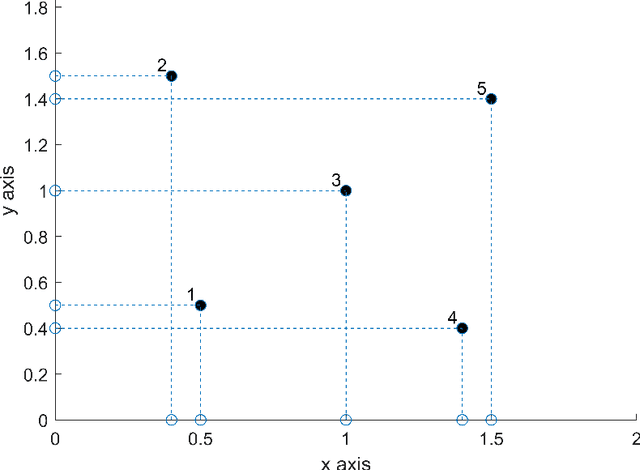
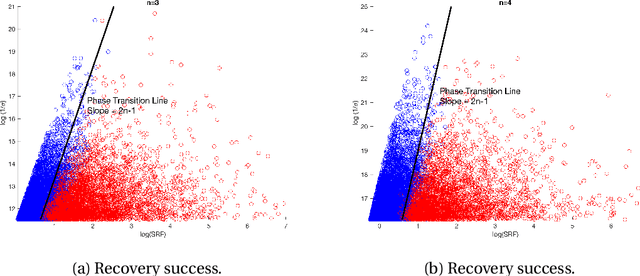
In this paper, we develop a new technique to obtain nearly optimal estimates of the computational resolution limits introduced in Appl. Comput. Harmon. Anal. 56 (2022) 402-446; IEEE Trans. Inf. Theory 67(7) (2021) 4812-4827; Inverse Probl. 37(10) (2021) 104001 for two-dimensional super-resolution problems. Our main contributions are fivefold: (i) Our work improves the resolution estimate for number detection and location recovery in two-dimensional super-resolution problems to nearly optimal; (ii) As a consequence, we derive a stability result for a sparsity-promoting algorithm in two-dimensional super-resolution problems (or Direction of Arrival problems (DOA)). The stability result exhibits the optimal performance of sparsity promoting in solving such problems; (iii) Our techniques pave the way for improving the estimate for resolution limits in higher-dimensional super-resolutions to nearly optimal; (iv) Inspired by these new techniques, we propose a new coordinate-combination-based model order detection algorithm for two-dimensional DOA estimation and theoretically demonstrate its optimal performance, and (v) we also propose a new coordinate-combination-based MUSIC algorithm for super-resolving sources in two-dimensional DOA estimation. It has excellent performance and enjoys many advantages compared to the conventional DOA algorithms. The coordinate-combination idea seems to be a promising way for multi-dimensional DOA estimation.