 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Understanding and Compressing Music with Maximal Transformable Patterns
Jan 28, 2022
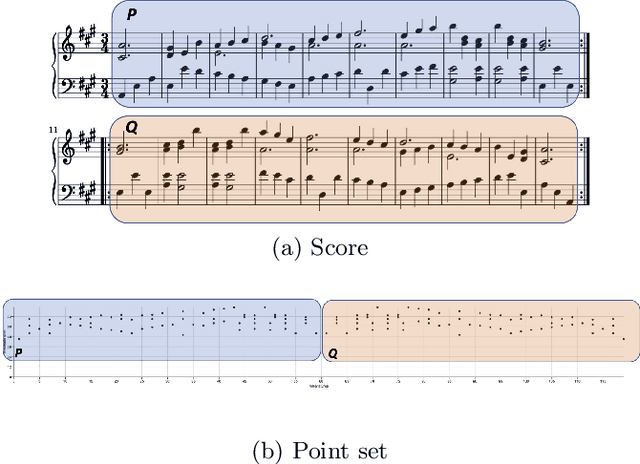
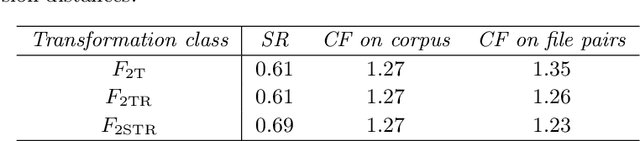

We present a polynomial-time algorithm that discovers all maximal patterns in a point set, $D\subset\mathbb{R}^k$, that are related by transformations in a user-specified class, $F$, of bijections over $\mathbb{R}^k$. We also present a second algorithm that discovers the set of occurrences for each of these maximal patterns and then uses compact encodings of these occurrence sets to compute a losslessly compressed encoding of the input point set. This encoding takes the form of a set of pairs, $E=\left\lbrace\left\langle P_1, T_1\right\rangle,\left\langle P_2, T_2\right\rangle,\ldots\left\langle P_{\ell}, T_{\ell}\right\rangle\right\rbrace$, where each $\langle P_i,T_i\rangle$ consists of a maximal pattern, $P_i\subseteq D$, and a set, $T_i\subset F$, of transformations that map $P_i$ onto other subsets of $D$. Each transformation is encoded by a vector of real values that uniquely identifies it within $F$ and the length of this vector is used as a measure of the complexity of $F$. We evaluate the new compression algorithm with three transformation classes of differing complexity, on the task of classifying folk-song melodies into tune families. The most complex of the classes tested includes all combinations of the musical transformations of transposition, inversion, retrograde, augmentation and diminution. We found that broadening the transformation class improved performance on this task. However, it did not, on average, improve compression factor, which may be due to the datasets (in this case, folk-song melodies) being too short and simple to benefit from the potentially greater number of pattern relationships that are discoverable with larger transformation classes.
Social influence leads to the formation of diverse local trends
Aug 17, 2021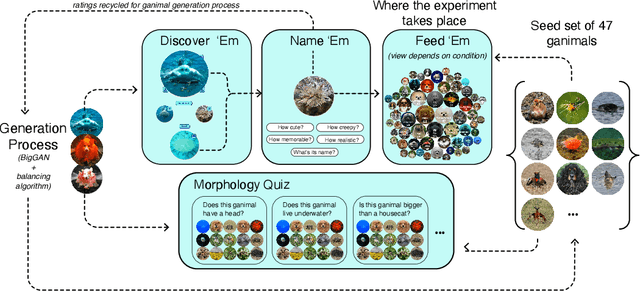

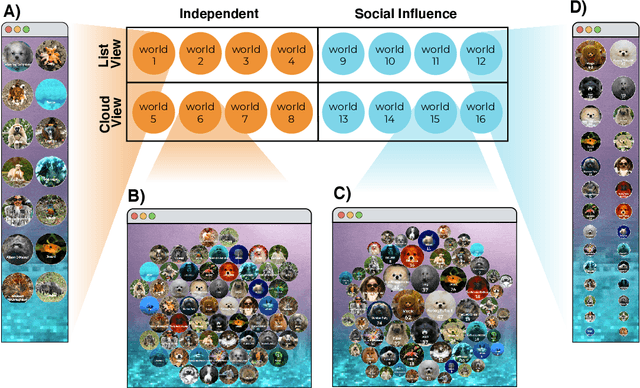
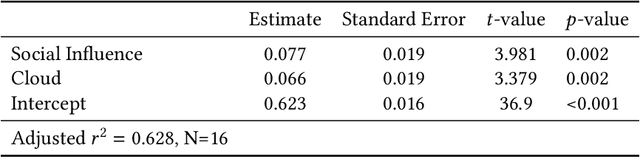
How does the visual design of digital platforms impact user behavior and the resulting environment? A body of work suggests that introducing social signals to content can increase both the inequality and unpredictability of its success, but has only been shown in the context of music listening. To further examine the effect of social influence on media popularity, we extend this research to the context of algorithmically-generated images by re-adapting Salganik et al's Music Lab experiment. On a digital platform where participants discover and curate AI-generated hybrid animals, we randomly assign both the knowledge of other participants' behavior and the visual presentation of the information. We successfully replicate the Music Lab's findings in the context of images, whereby social influence leads to an unpredictable winner-take-all market. However, we also find that social influence can lead to the emergence of local cultural trends that diverge from the status quo and are ultimately more diverse. We discuss the implications of these results for platform designers and animal conservation efforts.
A Hybrid Recurrent Neural Network For Music Transcription
Nov 06, 2014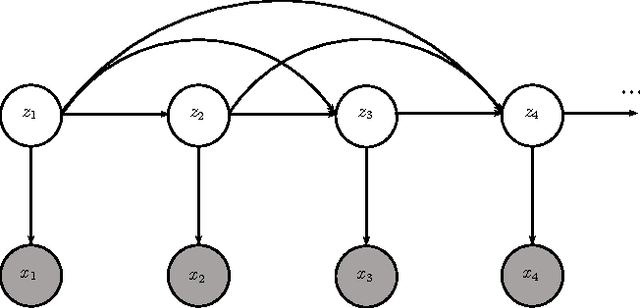

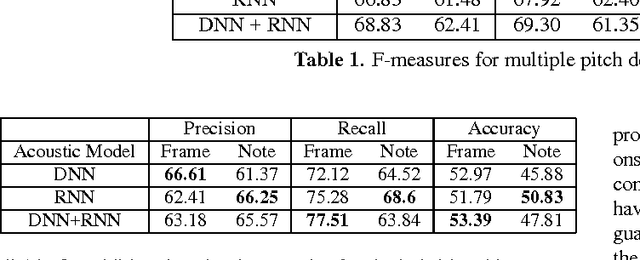
We investigate the problem of incorporating higher-level symbolic score-like information into Automatic Music Transcription (AMT) systems to improve their performance. We use recurrent neural networks (RNNs) and their variants as music language models (MLMs) and present a generative architecture for combining these models with predictions from a frame level acoustic classifier. We also compare different neural network architectures for acoustic modeling. The proposed model computes a distribution over possible output sequences given the acoustic input signal and we present an algorithm for performing a global search for good candidate transcriptions. The performance of the proposed model is evaluated on piano music from the MAPS dataset and we observe that the proposed model consistently outperforms existing transcription methods.
Expressive Singing Synthesis Using Local Style Token and Dual-path Pitch Encoder
Apr 07, 2022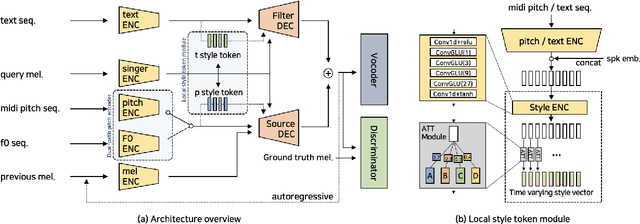
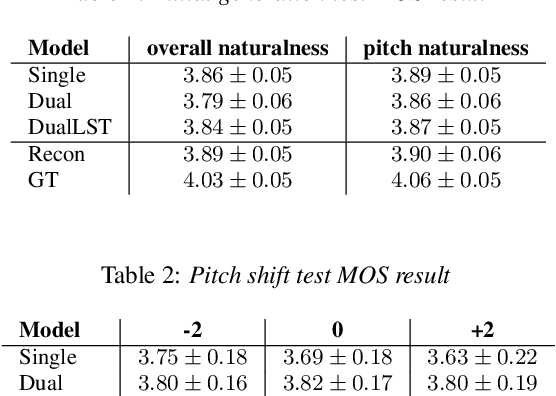
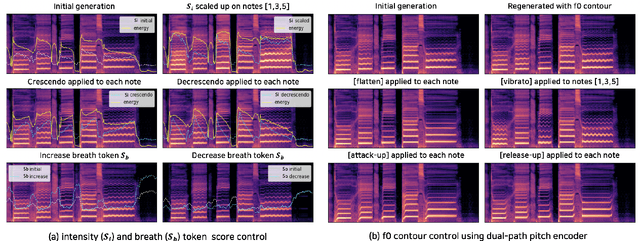
This paper proposes a controllable singing voice synthesis system capable of generating expressive singing voice with two novel methodologies. First, a local style token module, which predicts frame-level style tokens from an input pitch and text sequence, is proposed to allow the singing voice system to control musical expression often unspecified in sheet music (e.g., breathing and intensity). Second, we propose a dual-path pitch encoder with a choice of two different pitch inputs: MIDI pitch sequence or f0 contour. Because the initial generation of a singing voice is usually executed by taking a MIDI pitch sequence, one can later extract an f0 contour from the generated singing voice and modify the f0 contour to a finer level as desired. Through quantitative and qualitative evaluations, we confirmed that the proposed model could control various musical expressions while not sacrificing the sound quality of the singing voice synthesis system.
Superconducting qubits as musical synthesizers for live performance
Mar 11, 2022

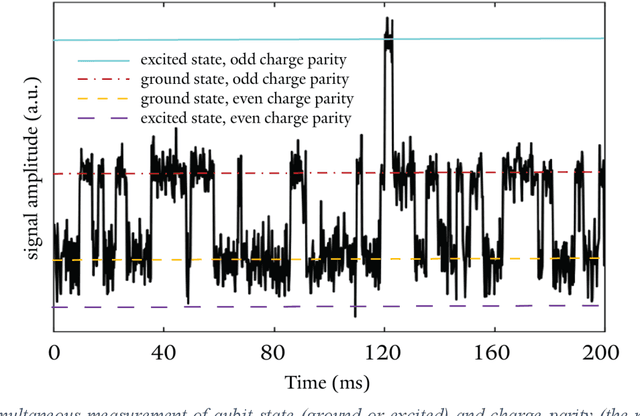
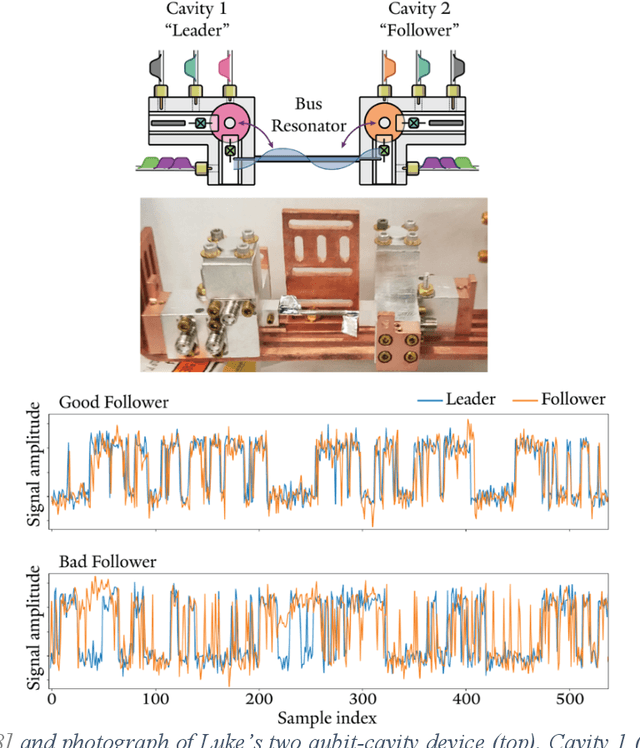
In the frame of a year-long artistic residency at the Yale Quantum Institute in 2019, artist and technologist Spencer Topel and quantum physicists Kyle Serniak and Luke Burkhart collaborated to create Quantum Sound, the first-ever music created and performed directly from measurements of superconducting quantum devices. Using analog- and digital-signal-processing sonification techniques, the team transformed GHz-frequency signals from experiments inside dilution refrigerators into audible sounds. The project was performed live at the International Festival of Arts and Ideas in New Haven, Connecticut on June 14, 2019 as a structured improvisation using the synthesis methods described in this chapter. At the interface between research and art, Quantum Sound represents an earnest attempt to produce a sonic reflection of the quantum realm.
Towards a Deep Improviser: a prototype deep learning post-tonal free music generator
Dec 21, 2017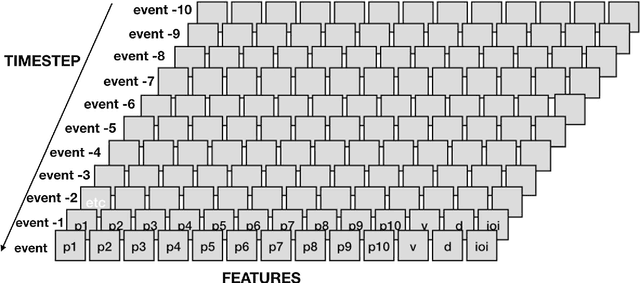
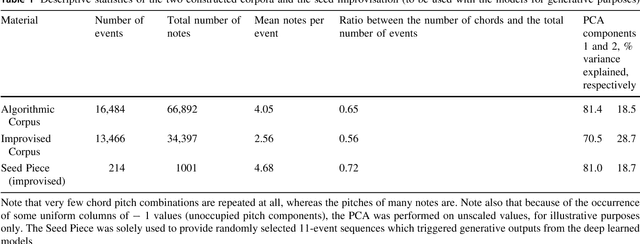

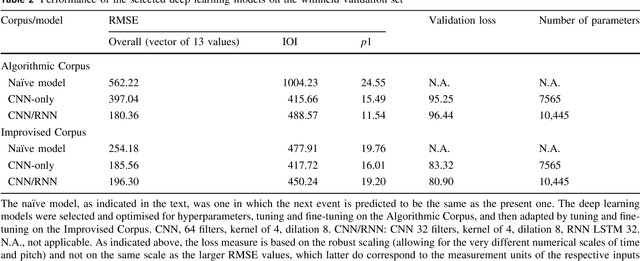
Two modest-sized symbolic corpora of post-tonal and post-metric keyboard music have been constructed, one algorithmic, the other improvised. Deep learning models of each have been trained and largely optimised. Our purpose is to obtain a model with sufficient generalisation capacity that in response to a small quantity of separate fresh input seed material, it can generate outputs that are distinctive, rather than recreative of the learned corpora or the seed material. This objective has been first assessed statistically, and as judged by k-sample Anderson-Darling and Cramer tests, has been achieved. Music has been generated using the approach, and informal judgements place it roughly on a par with algorithmic and composed music in related forms. Future work will aim to enhance the model such that it can be evaluated in relation to expression, meaning and utility in real-time performance.
PDAugment: Data Augmentation by Pitch and Duration Adjustments for Automatic Lyrics Transcription
Sep 17, 2021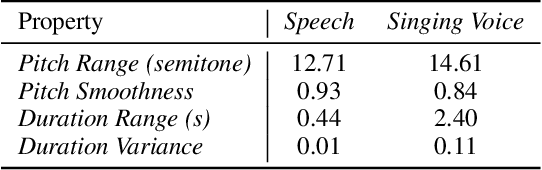
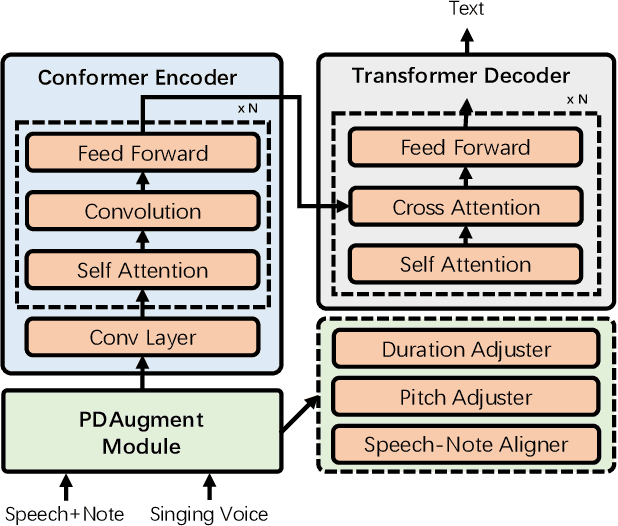
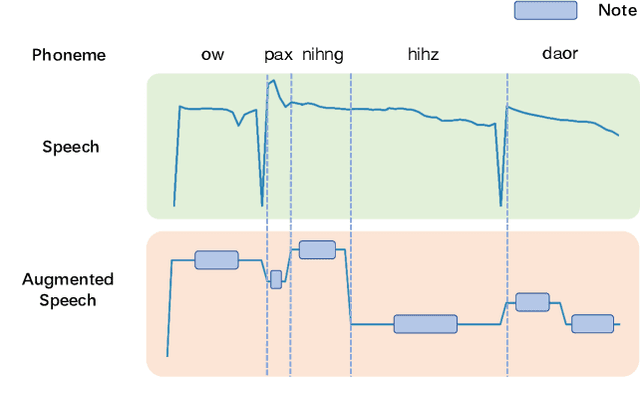

Automatic lyrics transcription (ALT), which can be regarded as automatic speech recognition (ASR) on singing voice, is an interesting and practical topic in academia and industry. ALT has not been well developed mainly due to the dearth of paired singing voice and lyrics datasets for model training. Considering that there is a large amount of ASR training data, a straightforward method is to leverage ASR data to enhance ALT training. However, the improvement is marginal when training the ALT system directly with ASR data, because of the gap between the singing voice and standard speech data which is rooted in music-specific acoustic characteristics in singing voice. In this paper, we propose PDAugment, a data augmentation method that adjusts pitch and duration of speech at syllable level under the guidance of music scores to help ALT training. Specifically, we adjust the pitch and duration of each syllable in natural speech to those of the corresponding note extracted from music scores, so as to narrow the gap between natural speech and singing voice. Experiments on DSing30 and Dali corpus show that the ALT system equipped with our PDAugment outperforms previous state-of-the-art systems by 5.9% and 18.1% WERs respectively, demonstrating the effectiveness of PDAugment for ALT.
Multi-task U-Net for Music Source Separation
Mar 23, 2020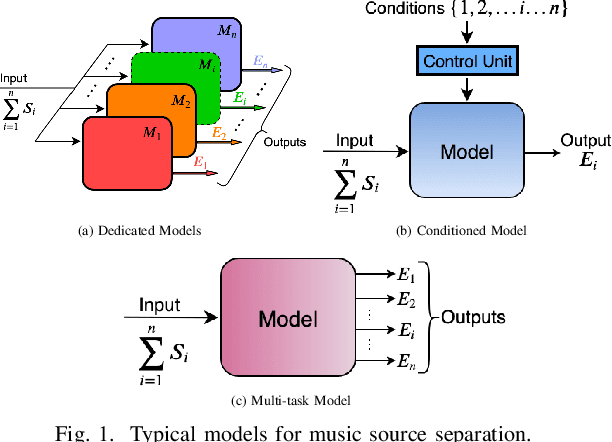
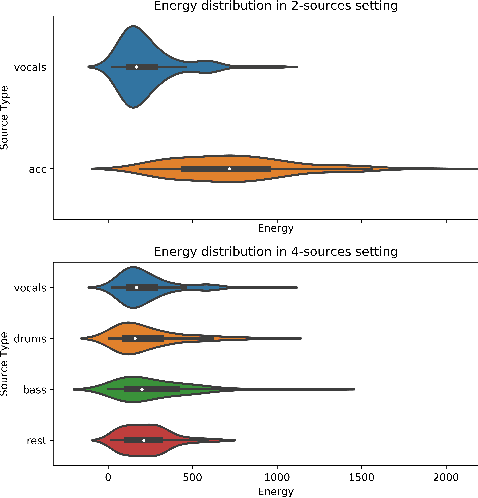
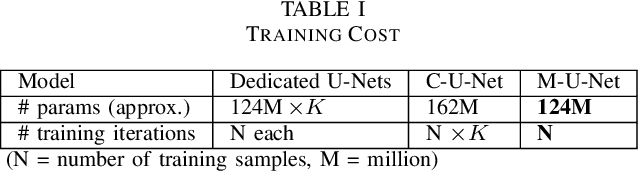
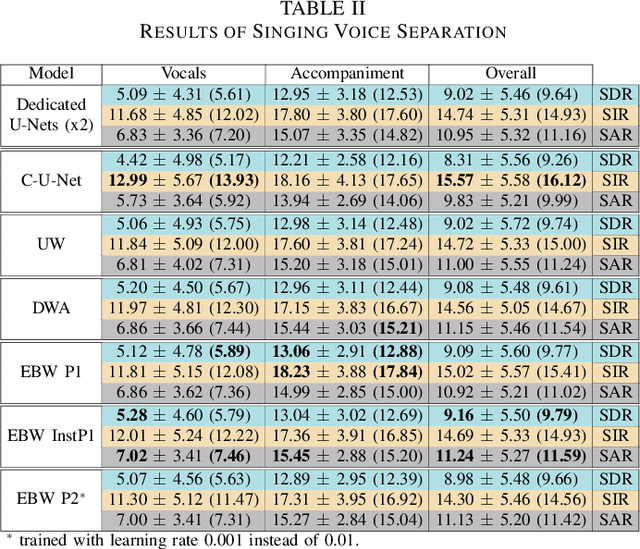
A fairly straightforward approach for music source separation is to train independent models, wherein each model is dedicated for estimating only a specific source. Training a single model to estimate multiple sources generally does not perform as well as the independent dedicated models. However, Conditioned U-Net (C-U-Net) uses a control mechanism to train a single model for multi-source separation and attempts to achieve a performance comparable to that of the dedicated models. We propose a multi-task U-Net (M-U-Net) trained using a weighted multi-task loss as an alternative to the C-U-Net. We investigate two weighting strategies for our multi-task loss: 1) Dynamic Weighted Average (DWA), and 2) Energy Based Weighting (EBW). DWA determines the weights by tracking the rate of change of loss of each task during training. EBW aims to neutralize the effect of the training bias arising from the difference in energy levels of each of the sources in a mixture. Our methods provide two-fold advantages compared to the C-U-Net: 1) Fewer effective training iterations with no conditioning, and 2) Fewer trainable network parameters (no control parameters). Our methods achieve performance comparable to that of C-U-Net and the dedicated U-Nets at a much lower training cost.
Using Generic Summarization to Improve Music Information Retrieval Tasks
Mar 09, 2016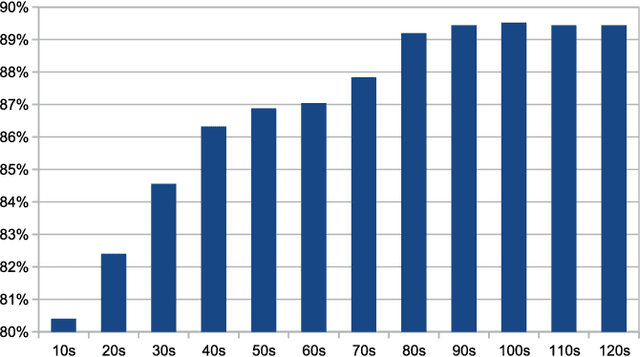
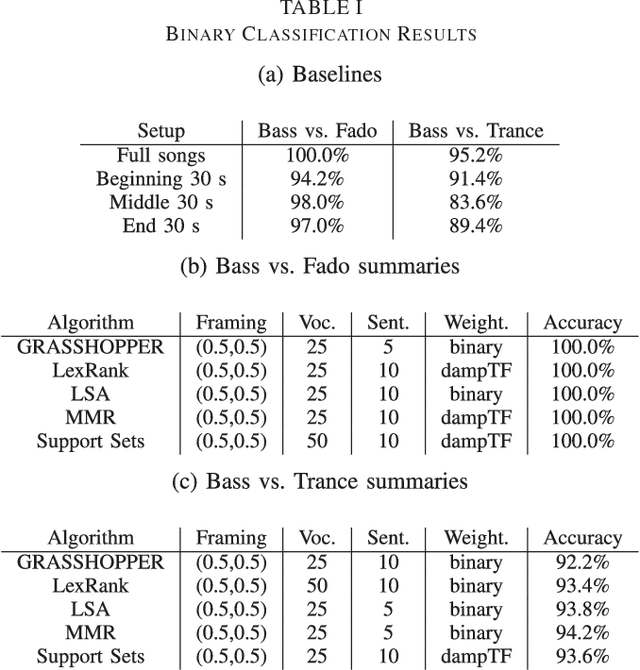
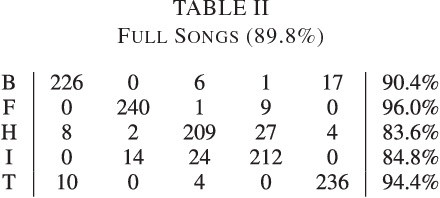
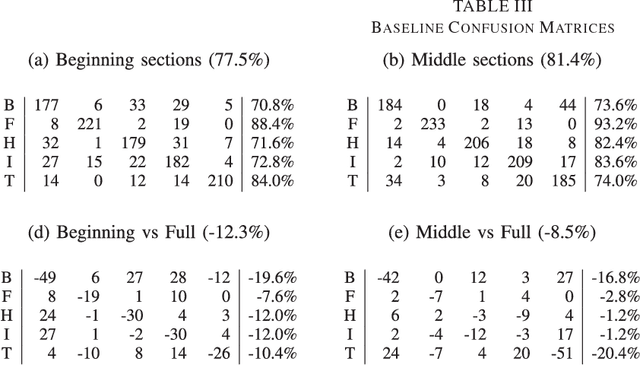
In order to satisfy processing time constraints, many MIR tasks process only a segment of the whole music signal. This practice may lead to decreasing performance, since the most important information for the tasks may not be in those processed segments. In this paper, we leverage generic summarization algorithms, previously applied to text and speech summarization, to summarize items in music datasets. These algorithms build summaries, that are both concise and diverse, by selecting appropriate segments from the input signal which makes them good candidates to summarize music as well. We evaluate the summarization process on binary and multiclass music genre classification tasks, by comparing the performance obtained using summarized datasets against the performances obtained using continuous segments (which is the traditional method used for addressing the previously mentioned time constraints) and full songs of the same original dataset. We show that GRASSHOPPER, LexRank, LSA, MMR, and a Support Sets-based Centrality model improve classification performance when compared to selected 30-second baselines. We also show that summarized datasets lead to a classification performance whose difference is not statistically significant from using full songs. Furthermore, we make an argument stating the advantages of sharing summarized datasets for future MIR research.
* 24 pages, 10 tables; Submitted to IEEE/ACM Transactions on Audio, Speech and Language Processing