 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Audio-guided Album Cover Art Generation with Genetic Algorithms
Jul 14, 2022


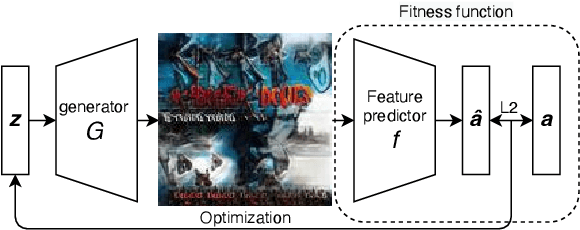
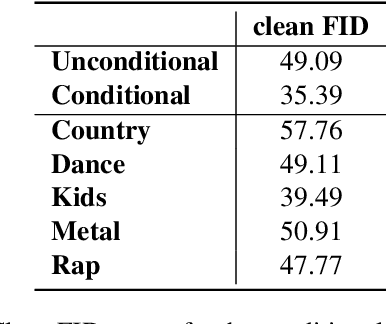
Over 60,000 songs are released on Spotify every day, and the competition for the listener's attention is immense. In that regard, the importance of captivating and inviting cover art cannot be underestimated, because it is deeply entangled with a song's character and the artist's identity, and remains one of the most important gateways to lead people to discover music. However, designing cover art is a highly creative, lengthy and sometimes expensive process that can be daunting, especially for non-professional artists. For this reason, we propose a novel deep-learning framework to generate cover art guided by audio features. Inspired by VQGAN-CLIP, our approach is highly flexible because individual components can easily be replaced without the need for any retraining. This paper outlines the architectural details of our models and discusses the optimization challenges that emerge from them. More specifically, we will exploit genetic algorithms to overcome bad local minima and adversarial examples. We find that our framework can generate suitable cover art for most genres, and that the visual features adapt themselves to audio feature changes. Given these results, we believe that our framework paves the road for extensions and more advanced applications in audio-guided visual generation tasks.
The impact of the additional features on the performance of regression analysis: a case study on regression analysis of music signal
May 11, 2021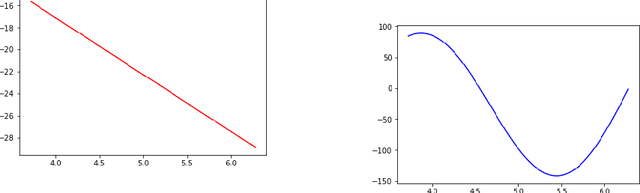
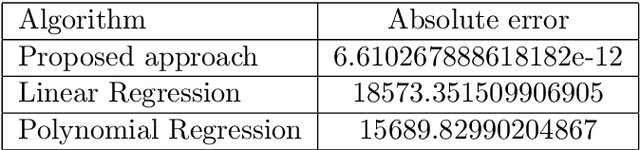
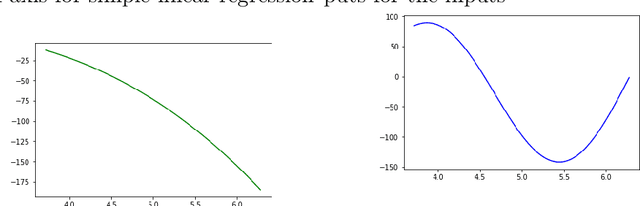
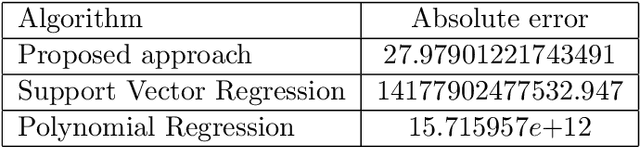
Machine learning techniques nowadays play a vital role in many burning issues of real-world problems when it involves data. In addition, when the task is complex, people are in dilemma in choosing deep learning techniques or going without them. This paper is about whether we should always rely on deep learning techniques or it is really possible to overcome the performance of deep learning algorithms by simple statistical machine learning algorithms by understanding the application and processing the data so that it can help in increasing the performance of the algorithm by a notable amount. The paper mentions the importance of data preprocessing than that of the selection of the algorithm. It discusses the functions involving trigonometric, logarithmic, and exponential terms and also talks about functions that are purely trigonometric. Finally, we discuss regression analysis on music signals to justify our claim.
Evaluation of Latent Space Disentanglement in the Presence of Interdependent Attributes
Oct 11, 2021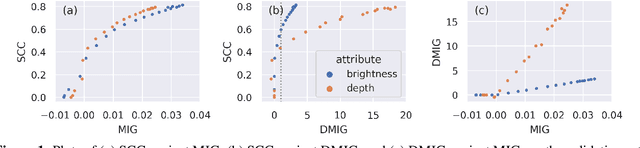
Controllable music generation with deep generative models has become increasingly reliant on disentanglement learning techniques. However, current disentanglement metrics, such as mutual information gap (MIG), are often inadequate and misleading when used for evaluating latent representations in the presence of interdependent semantic attributes often encountered in real-world music datasets. In this work, we propose a dependency-aware information metric as a drop-in replacement for MIG that accounts for the inherent relationship between semantic attributes.
A Deep Multimodal Approach for Cold-start Music Recommendation
Jul 24, 2017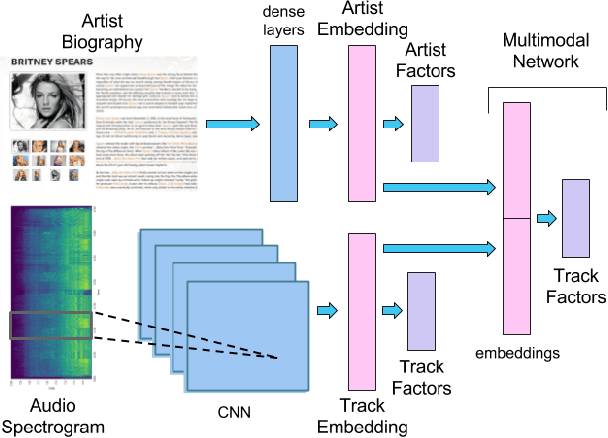
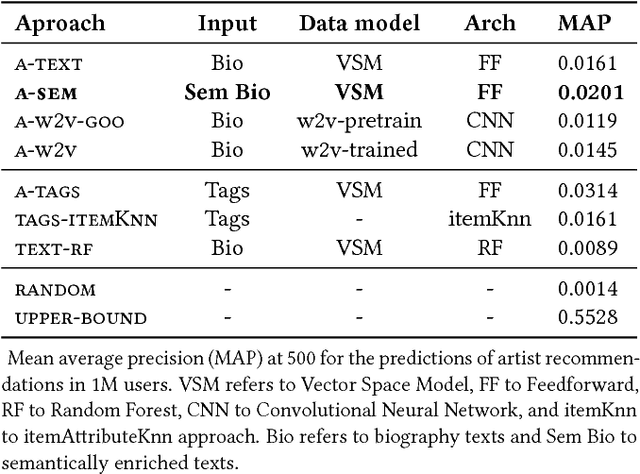

An increasing amount of digital music is being published daily. Music streaming services often ingest all available music, but this poses a challenge: how to recommend new artists for which prior knowledge is scarce? In this work we aim to address this so-called cold-start problem by combining text and audio information with user feedback data using deep network architectures. Our method is divided into three steps. First, artist embeddings are learned from biographies by combining semantics, text features, and aggregated usage data. Second, track embeddings are learned from the audio signal and available feedback data. Finally, artist and track embeddings are combined in a multimodal network. Results suggest that both splitting the recommendation problem between feature levels (i.e., artist metadata and audio track), and merging feature embeddings in a multimodal approach improve the accuracy of the recommendations.
Modeling Music Modality with a Key-Class Invariant Pitch Chroma CNN
Jun 17, 2019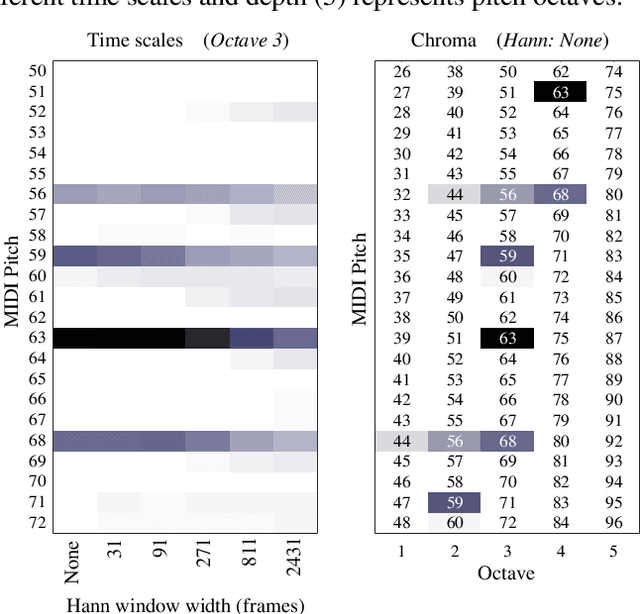
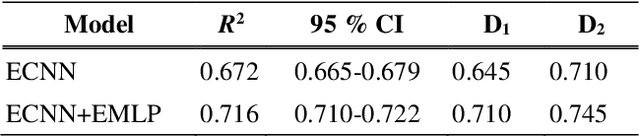
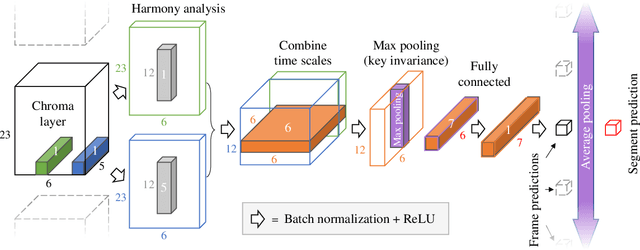
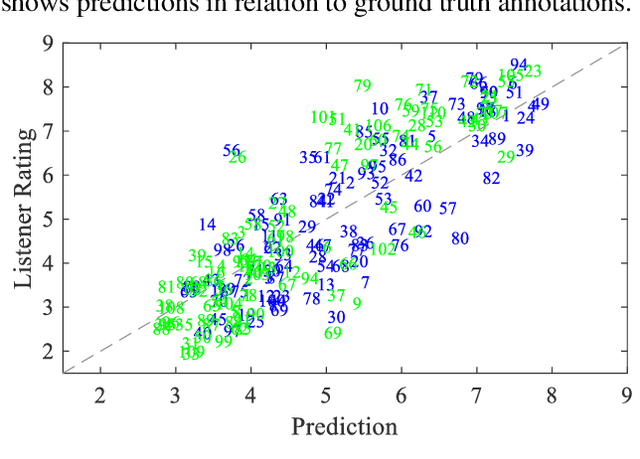
This paper presents a convolutional neural network (CNN) that uses input from a polyphonic pitch estimation system to predict perceived minor/major modality in music audio. The pitch activation input is structured to allow the first CNN layer to compute two pitch chromas focused on different octaves. The following layers perform harmony analysis across chroma and time scales. Through max pooling across pitch, the CNN becomes invariant with regards to the key class (i.e., key disregarding mode) of the music. A multilayer perceptron combines the modality activation output with spectral features for the final prediction. The study uses a dataset of 203 excerpts rated by around 20 listeners each, a small challenging data size requiring a carefully designed parameter sharing. With an R2 of about 0.71, the system clearly outperforms previous systems as well as individual human listeners. A final ablation study highlights the importance of using pitch activations processed across longer time scales, and using pooling to facilitate invariance with regards to the key class.
Application of Grover's Algorithm on the ibmqx4 Quantum Computer to Rule-based Algorithmic Music Composition
Feb 02, 2019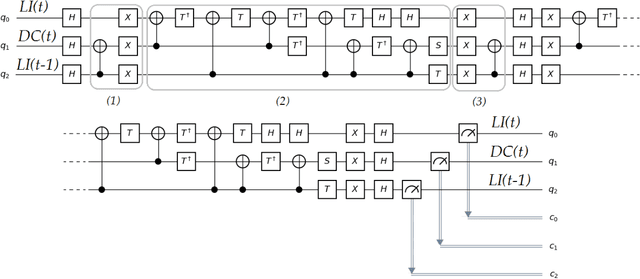


Previous research on quantum computing/mechanics and the arts has usually been in simulation. The small amount of work done in hardware or with actual physical systems has not utilized any of the advantages of quantum computation: the main advantage being the potential speed increase of quantum algorithms. This paper introduces a way of utilizing Grover's algorithm - which has been shown to provide a quadratic speed-up over its classical equivalent - in algorithmic rule-based music composition. The system introduced - qgMuse - is simple but scalable. It lays some groundwork for new ways of addressing a significant problem in computer music research: unstructured random search for desired music features. Example melodies are composed using qgMuse using the ibmqx4 quantum hardware, and the paper concludes with discussion on how such an approach can grow with the improvement of quantum computer hardware and software.
AccoMontage: Accompaniment Arrangement via Phrase Selection and Style Transfer
Aug 25, 2021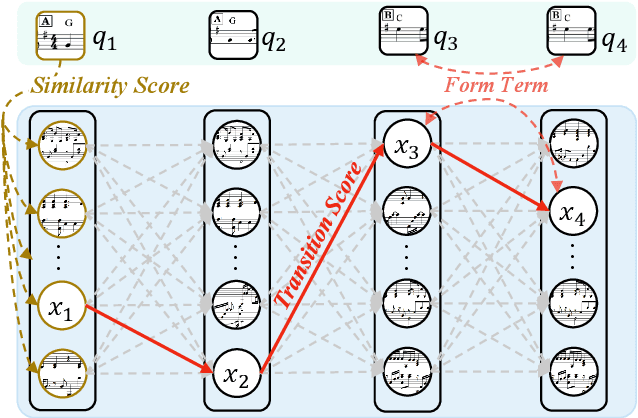



Accompaniment arrangement is a difficult music generation task involving intertwined constraints of melody, harmony, texture, and music structure. Existing models are not yet able to capture all these constraints effectively, especially for long-term music generation. To address this problem, we propose AccoMontage, an accompaniment arrangement system for whole pieces of music through unifying phrase selection and neural style transfer. We focus on generating piano accompaniments for folk/pop songs based on a lead sheet (i.e., melody with chord progression). Specifically, AccoMontage first retrieves phrase montages from a database while recombining them structurally using dynamic programming. Second, chords of the retrieved phrases are manipulated to match the lead sheet via style transfer. Lastly, the system offers controls over the generation process. In contrast to pure learning-based approaches, AccoMontage introduces a novel hybrid pathway, in which rule-based optimization and deep learning are both leveraged to complement each other for high-quality generation. Experiments show that our model generates well-structured accompaniment with delicate texture, significantly outperforming the baselines.
Knowledge-aware Neural Collective Matrix Factorization for Cross-domain Recommendation
Jun 27, 2022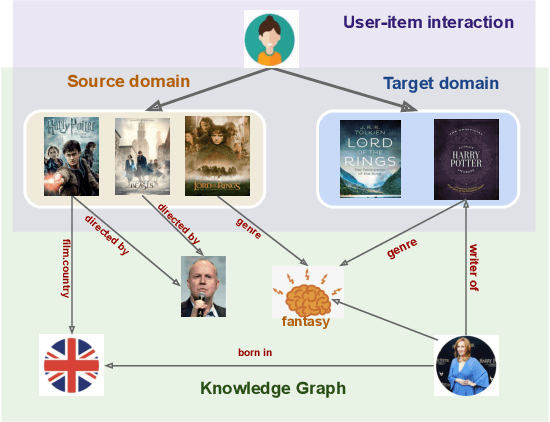
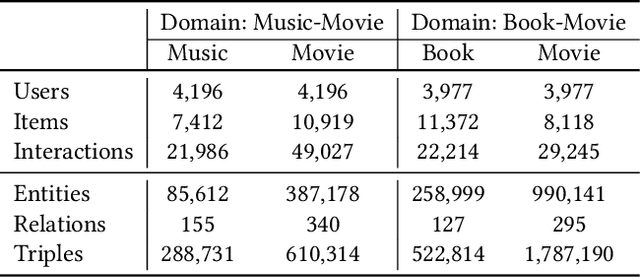
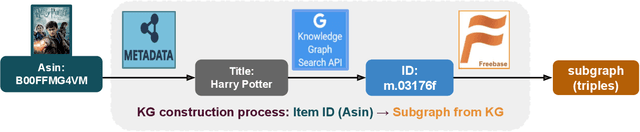
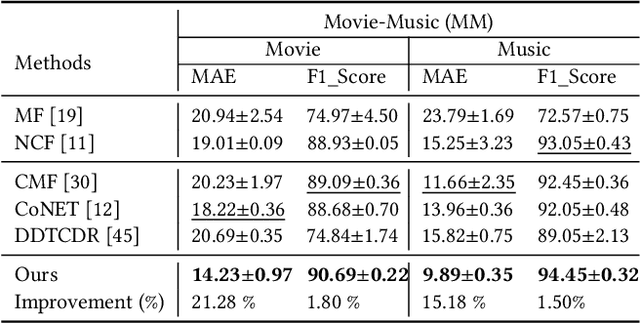
Cross-domain recommendation (CDR) can help customers find more satisfying items in different domains. Existing CDR models mainly use common users or mapping functions as bridges between domains but have very limited exploration in fully utilizing extra knowledge across domains. In this paper, we propose to incorporate the knowledge graph (KG) for CDR, which enables items in different domains to share knowledge. To this end, we first construct a new dataset AmazonKG4CDR from the Freebase KG and a subset (two domain pairs: movies-music, movie-book) of Amazon Review Data. This new dataset facilitates linking knowledge to bridge within- and cross-domain items for CDR. Then we propose a new framework, KG-aware Neural Collective Matrix Factorization (KG-NeuCMF), leveraging KG to enrich item representations. It first learns item embeddings by graph convolutional autoencoder to capture both domain-specific and domain-general knowledge from adjacent and higher-order neighbours in the KG. Then, we maximize the mutual information between item embeddings learned from the KG and user-item matrix to establish cross-domain relationships for better CDR. Finally, we conduct extensive experiments on the newly constructed dataset and demonstrate that our model significantly outperforms the best-performing baselines.
MusicMood: Predicting the mood of music from song lyrics using machine learning
Nov 01, 2016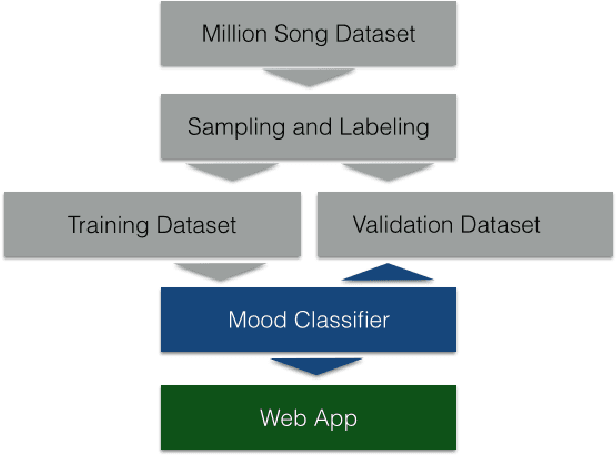
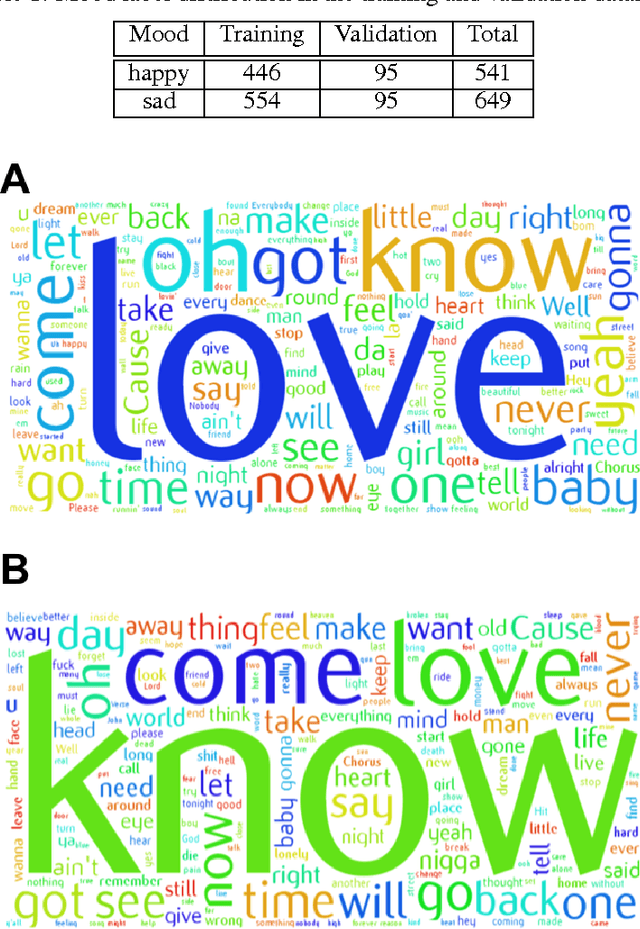
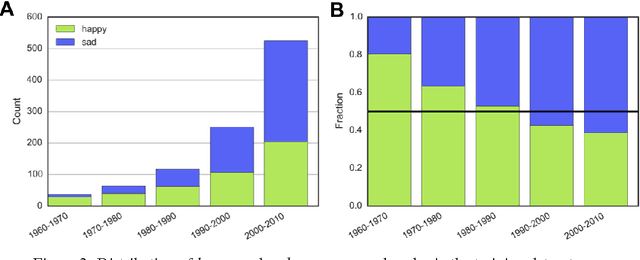
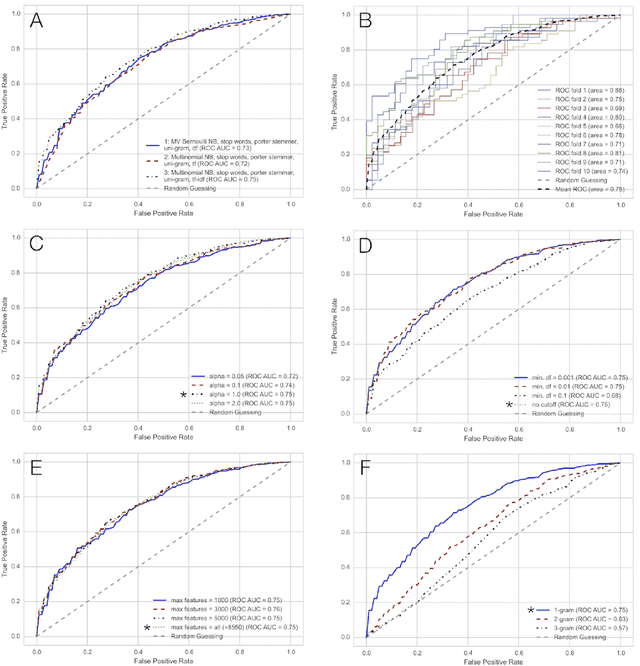
Sentiment prediction of contemporary music can have a wide-range of applications in modern society, for instance, selecting music for public institutions such as hospitals or restaurants to potentially improve the emotional well-being of personnel, patients, and customers, respectively. In this project, music recommendation system built upon on a naive Bayes classifier, trained to predict the sentiment of songs based on song lyrics alone. The experimental results show that music corresponding to a happy mood can be detected with high precision based on text features obtained from song lyrics.
Cross-cultural Mood Perception in Pop Songs and its Alignment with Mood Detection Algorithms
Aug 02, 2021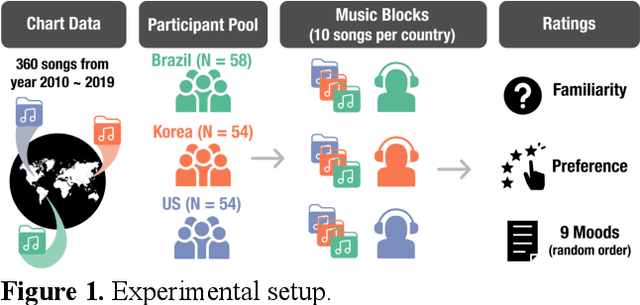
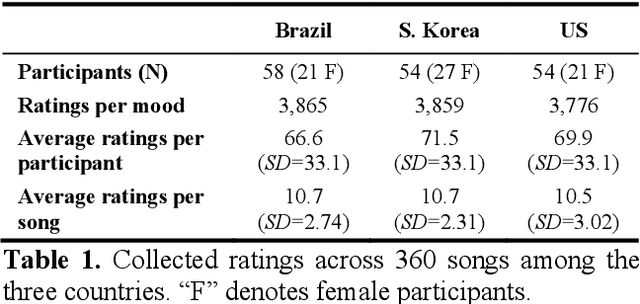

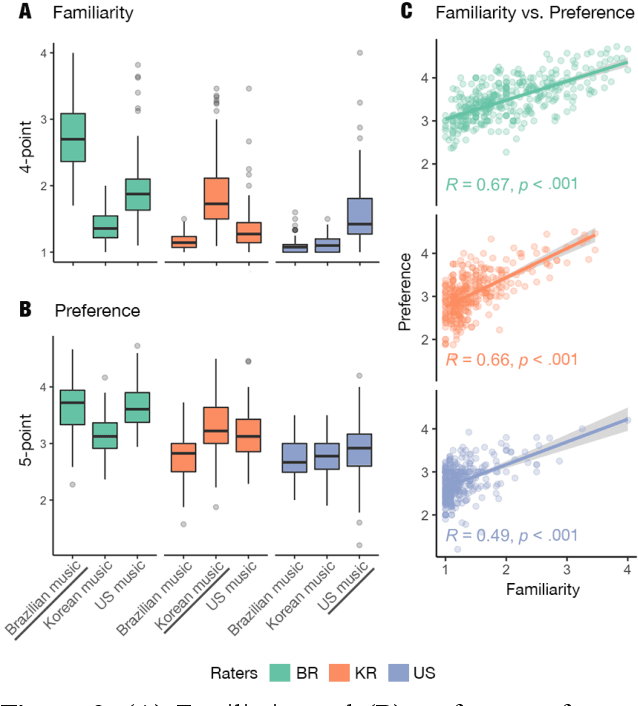
Do people from different cultural backgrounds perceive the mood in music the same way? How closely do human ratings across different cultures approximate automatic mood detection algorithms that are often trained on corpora of predominantly Western popular music? Analyzing 166 participants responses from Brazil, South Korea, and the US, we examined the similarity between the ratings of nine categories of perceived moods in music and estimated their alignment with four popular mood detection algorithms. We created a dataset of 360 recent pop songs drawn from major music charts of the countries and constructed semantically identical mood descriptors across English, Korean, and Portuguese languages. Multiple participants from the three countries rated their familiarity, preference, and perceived moods for a given song. Ratings were highly similar within and across cultures for basic mood attributes such as sad, cheerful, and energetic. However, we found significant cross-cultural differences for more complex characteristics such as dreamy and love. To our surprise, the results of mood detection algorithms were uniformly correlated across human ratings from all three countries and did not show a detectable bias towards any particular culture. Our study thus suggests that the mood detection algorithms can be considered as an objective measure at least within the popular music context.