 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
The Arrow of Time in Music -- Revisiting the Temporal Structure of Music with Distinguishability and Unique Orientability as the Anchor Point
Dec 28, 2023
Driven by the term "the arrow of time" as a general topic, the article develops a musical discussion by referring to the etymological origin of the term: philosophy (epistemology) and physics (thermodynamics). In particular, the article explores two specific conditions: distinguishability and unique orientability, from which the article derives respective musical propositions and case studies. For the distinguishability condition, the article focuses on the "recurrence" in music and tries to interpret Bach's Christmas Oratorio from the perspective of "birth/resurrection". For the unique orientability condition, the article discusses the process of delaying the climax, thereby proposing "AB-AAB left-replication" model, implying an organicist view by treating the temporal structure of music (e.g. form) as the product of a dynamic process: organic growth.
Zero-Shot Unsupervised and Text-Based Audio Editing Using DDPM Inversion
Feb 16, 2024Editing signals using large pre-trained models, in a zero-shot manner, has recently seen rapid advancements in the image domain. However, this wave has yet to reach the audio domain. In this paper, we explore two zero-shot editing techniques for audio signals, which use DDPM inversion on pre-trained diffusion models. The first, adopted from the image domain, allows text-based editing. The second, is a novel approach for discovering semantically meaningful editing directions without supervision. When applied to music signals, this method exposes a range of musically interesting modifications, from controlling the participation of specific instruments to improvisations on the melody. Samples and code can be found on our examples page in https://hilamanor.github.io/AudioEditing/ .
Recommender for Its Purpose: Repeat and Exploration in Food Delivery Recommendations
Feb 22, 2024Recommender systems have been widely used for various scenarios, such as e-commerce, news, and music, providing online contents to help and enrich users' daily life. Different scenarios hold distinct and unique characteristics, calling for domain-specific investigations and corresponding designed recommender systems. Therefore, in this paper, we focus on food delivery recommendations to unveil unique features in this domain, where users order food online and enjoy their meals shortly after delivery. We first conduct an in-depth analysis on food delivery datasets. The analysis shows that repeat orders are prevalent for both users and stores, and situations' differently influence repeat and exploration consumption in the food delivery recommender systems. Moreover, we revisit the ability of existing situation-aware methods for repeat and exploration recommendations respectively, and find them unable to effectively solve both tasks simultaneously. Based on the analysis and experiments, we have designed two separate recommendation models -- ReRec for repeat orders and ExpRec for exploration orders; both are simple in their design and computation. We conduct experiments on three real-world food delivery datasets, and our proposed models outperform various types of baselines on repeat, exploration, and combined recommendation tasks. This paper emphasizes the importance of dedicated analyses and methods for domain-specific characteristics for the recommender system studies.
N-Gram Unsupervised Compoundation and Feature Injection for Better Symbolic Music Understanding
Dec 15, 2023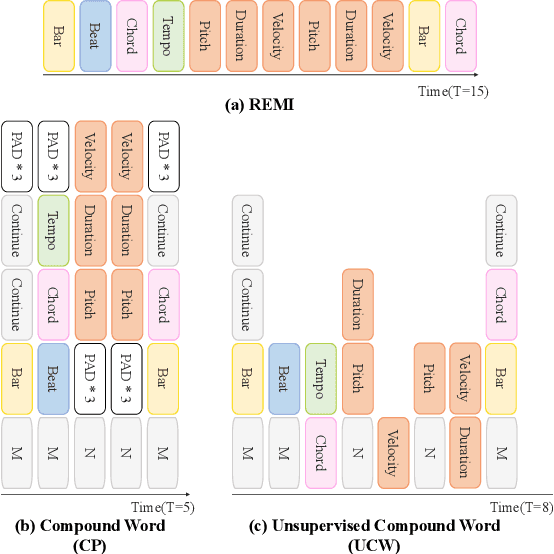
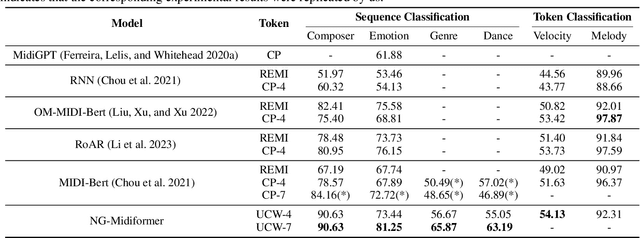
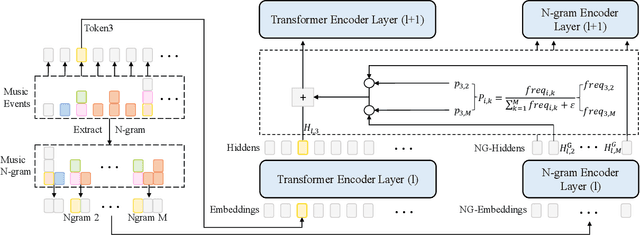
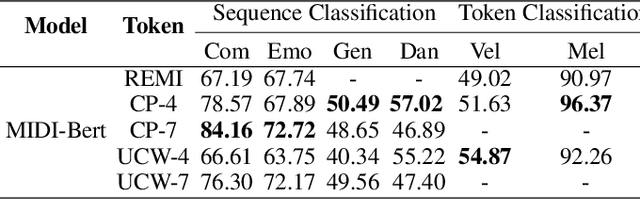
The first step to apply deep learning techniques for symbolic music understanding is to transform musical pieces (mainly in MIDI format) into sequences of predefined tokens like note pitch, note velocity, and chords. Subsequently, the sequences are fed into a neural sequence model to accomplish specific tasks. Music sequences exhibit strong correlations between adjacent elements, making them prime candidates for N-gram techniques from Natural Language Processing (NLP). Consider classical piano music: specific melodies might recur throughout a piece, with subtle variations each time. In this paper, we propose a novel method, NG-Midiformer, for understanding symbolic music sequences that leverages the N-gram approach. Our method involves first processing music pieces into word-like sequences with our proposed unsupervised compoundation, followed by using our N-gram Transformer encoder, which can effectively incorporate N-gram information to enhance the primary encoder part for better understanding of music sequences. The pre-training process on large-scale music datasets enables the model to thoroughly learn the N-gram information contained within music sequences, and subsequently apply this information for making inferences during the fine-tuning stage. Experiment on various datasets demonstrate the effectiveness of our method and achieved state-of-the-art performance on a series of music understanding downstream tasks. The code and model weights will be released at https://github.com/CinqueOrigin/NG-Midiformer.
StemGen: A music generation model that listens
Dec 14, 2023
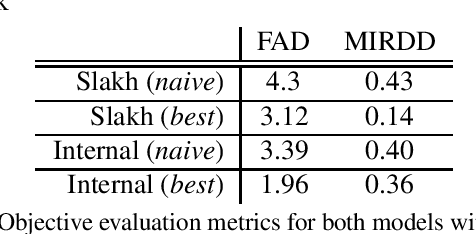
End-to-end generation of musical audio using deep learning techniques has seen an explosion of activity recently. However, most models concentrate on generating fully mixed music in response to abstract conditioning information. In this work, we present an alternative paradigm for producing music generation models that can listen and respond to musical context. We describe how such a model can be constructed using a non-autoregressive, transformer-based model architecture and present a number of novel architectural and sampling improvements. We train the described architecture on both an open-source and a proprietary dataset. We evaluate the produced models using standard quality metrics and a new approach based on music information retrieval descriptors. The resulting model reaches the audio quality of state-of-the-art text-conditioned models, as well as exhibiting strong musical coherence with its context.
WikiMuTe: A web-sourced dataset of semantic descriptions for music audio
Dec 14, 2023Multi-modal deep learning techniques for matching free-form text with music have shown promising results in the field of Music Information Retrieval (MIR). Prior work is often based on large proprietary data while publicly available datasets are few and small in size. In this study, we present WikiMuTe, a new and open dataset containing rich semantic descriptions of music. The data is sourced from Wikipedia's rich catalogue of articles covering musical works. Using a dedicated text-mining pipeline, we extract both long and short-form descriptions covering a wide range of topics related to music content such as genre, style, mood, instrumentation, and tempo. To show the use of this data, we train a model that jointly learns text and audio representations and performs cross-modal retrieval. The model is evaluated on two tasks: tag-based music retrieval and music auto-tagging. The results show that while our approach has state-of-the-art performance on multiple tasks, but still observe a difference in performance depending on the data used for training.
If Turing played piano with an artificial partner
Feb 09, 2024Music is an inherently social activity that allows people to share experiences and feel connected with one another. There has been little progress in designing artificial partners exhibiting a similar social experience as playing with another person. Neural network architectures that implement generative models, such as large language models, are suited for producing musical scores. Playing music socially, however, involves more than playing a score; it must complement the other musicians' ideas and keep time correctly. We addressed the question of whether a convincing social experience is made possible by a generative model trained to produce musical scores, not necessarily optimized for synchronization and continuation. The network, a variational autoencoder trained on a large corpus of digital scores, was adapted for a timed call-and-response task with a human partner. Participants played piano with a human or artificial partner-in various configurations-and rated the performance quality and first-person experience of self-other integration. Overall, the artificial partners held promise but were rated lower than human partners. The artificial partner with simplest design and highest similarity parameter was not rated differently from the human partners on some measures, suggesting that interactive rather than generative sophistication is important in enabling social AI.
Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models
Feb 20, 2024In recent years, large language models have achieved significant success in generative tasks (e.g., speech cloning and audio generation) related to speech, audio, music, and other signal domains. A crucial element of these models is the discrete acoustic codecs, which serves as an intermediate representation replacing the mel-spectrogram. However, there exist several gaps between discrete codecs and downstream speech language models. Specifically, 1) most codec models are trained on only 1,000 hours of data, whereas most speech language models are trained on 60,000 hours; 2) Achieving good reconstruction performance requires the utilization of numerous codebooks, which increases the burden on downstream speech language models; 3) The initial channel of the codebooks contains excessive information, making it challenging to directly generate acoustic tokens from weakly supervised signals such as text in downstream tasks. Consequently, leveraging the characteristics of speech language models, we propose Language-Codec. In the Language-Codec, we introduce a Mask Channel Residual Vector Quantization (MCRVQ) mechanism along with improved Fourier transform structures and larger training datasets to address the aforementioned gaps. We compare our method with competing audio compression algorithms and observe significant outperformance across extensive evaluations. Furthermore, we also validate the efficiency of the Language-Codec on downstream speech language models. The source code and pre-trained models can be accessed at https://github.com/jishengpeng/languagecodec .
MusER: Musical Element-Based Regularization for Generating Symbolic Music with Emotion
Dec 16, 2023Generating music with emotion is an important task in automatic music generation, in which emotion is evoked through a variety of musical elements (such as pitch and duration) that change over time and collaborate with each other. However, prior research on deep learning-based emotional music generation has rarely explored the contribution of different musical elements to emotions, let alone the deliberate manipulation of these elements to alter the emotion of music, which is not conducive to fine-grained element-level control over emotions. To address this gap, we present a novel approach employing musical element-based regularization in the latent space to disentangle distinct elements, investigate their roles in distinguishing emotions, and further manipulate elements to alter musical emotions. Specifically, we propose a novel VQ-VAE-based model named MusER. MusER incorporates a regularization loss to enforce the correspondence between the musical element sequences and the specific dimensions of latent variable sequences, providing a new solution for disentangling discrete sequences. Taking advantage of the disentangled latent vectors, a two-level decoding strategy that includes multiple decoders attending to latent vectors with different semantics is devised to better predict the elements. By visualizing latent space, we conclude that MusER yields a disentangled and interpretable latent space and gain insights into the contribution of distinct elements to the emotional dimensions (i.e., arousal and valence). Experimental results demonstrate that MusER outperforms the state-of-the-art models for generating emotional music in both objective and subjective evaluation. Besides, we rearrange music through element transfer and attempt to alter the emotion of music by transferring emotion-distinguishable elements.
Annotation-free Automatic Music Transcription with Scalable Synthetic Data and Adversarial Domain Confusion
Dec 31, 2023Automatic Music Transcription (AMT) is a vital technology in the field of music information processing. Despite recent enhancements in performance due to machine learning techniques, current methods typically attain high accuracy in domains where abundant annotated data is available. Addressing domains with low or no resources continues to be an unresolved challenge. To tackle this issue, we propose a transcription model that does not require any MIDI-audio paired data through the utilization of scalable synthetic audio for pre-training and adversarial domain confusion using unannotated real audio. In experiments, we evaluate methods under the real-world application scenario where training datasets do not include the MIDI annotation of audio in the target data domain. Our proposed method achieved competitive performance relative to established baseline methods, despite not utilizing any real datasets of paired MIDI-audio. Additionally, ablation studies have provided insights into the scalability of this approach and the forthcoming challenges in the field of AMT research.