 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Style Transfer of Audio Effects with Differentiable Signal Processing
Jul 18, 2022
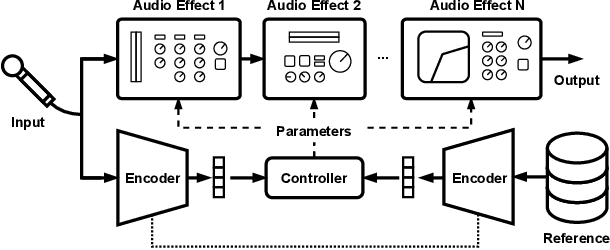
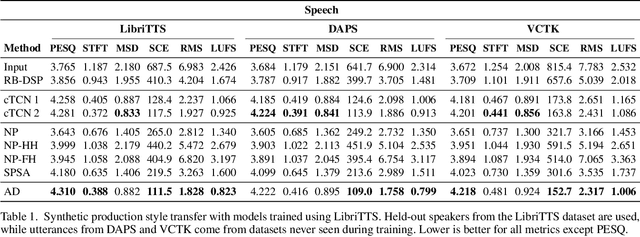
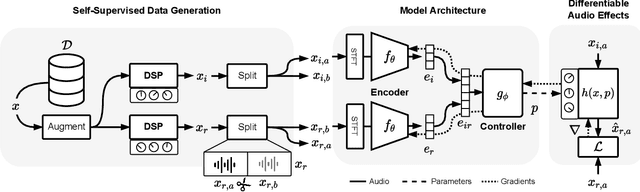
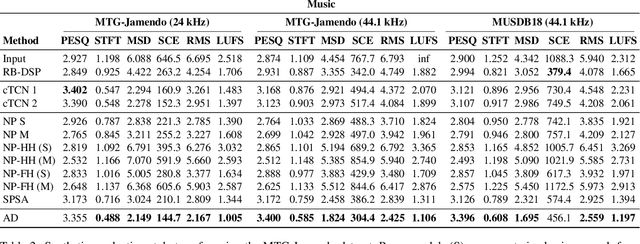
We present a framework that can impose the audio effects and production style from one recording to another by example with the goal of simplifying the audio production process. We train a deep neural network to analyze an input recording and a style reference recording, and predict the control parameters of audio effects used to render the output. In contrast to past work, we integrate audio effects as differentiable operators in our framework, perform backpropagation through audio effects, and optimize end-to-end using an audio-domain loss. We use a self-supervised training strategy enabling automatic control of audio effects without the use of any labeled or paired training data. We survey a range of existing and new approaches for differentiable signal processing, showing how each can be integrated into our framework while discussing their trade-offs. We evaluate our approach on both speech and music tasks, demonstrating that our approach generalizes both to unseen recordings and even to sample rates different than those seen during training. Our approach produces convincing production style transfer results with the ability to transform input recordings to produced recordings, yielding audio effect control parameters that enable interpretability and user interaction.
MELONS: generating melody with long-term structure using transformers and structure graph
Oct 12, 2021

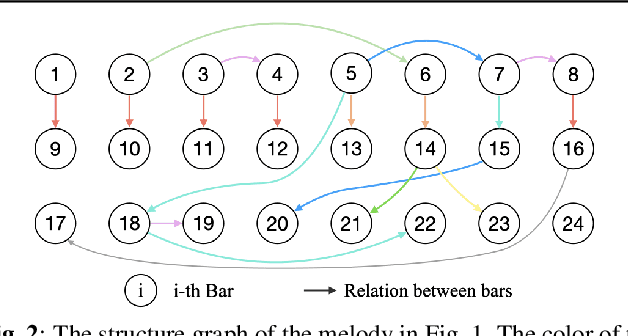
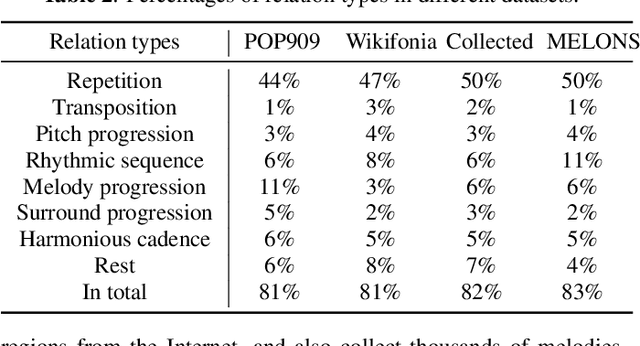
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
GenéLive! Generating Rhythm Actions in Love Live!
Feb 25, 2022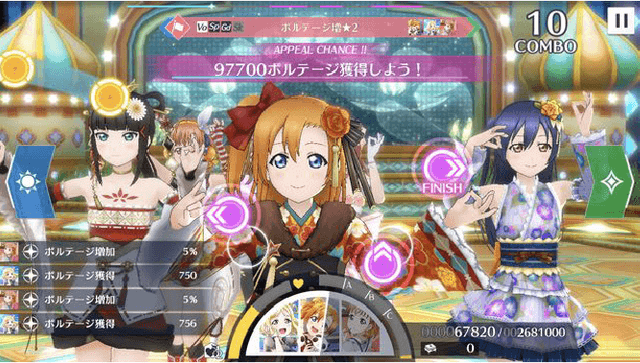
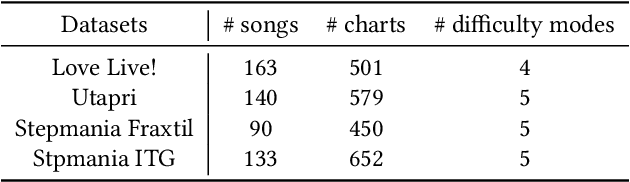
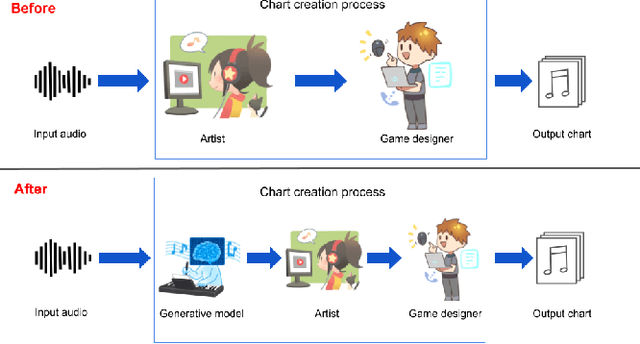
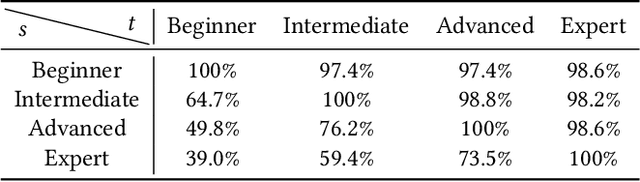
A rhythm action game is a music-based video game in which the player is challenged to issue commands at the right timings during a music session. The timings are rendered in the chart, which consists of visual symbols, called notes, flying through the screen. KLab Inc., a Japan-based video game developer, has operated rhythm action games including a title for the "Love Live!" franchise, which became a hit across Asia and beyond. Before this work, the company generated the charts manually, which resulted in a costly business operation. This paper presents how KLab applied a deep generative model for synthesizing charts, and shows how it has improved the chart production process, reducing the business cost by half. Existing generative models generated poor quality charts for easier difficulty modes. We report how we overcame this challenge through a multi-scaling model dedicated to rhythm actions, by considering beats among other things. Our model, named Gen\'eLive!, is evaluated using production datasets at KLab as well as open datasets.
A Deep Learning Approach for Low-Latency Packet Loss Concealment of Audio Signals in Networked Music Performance Applications
Jul 14, 2020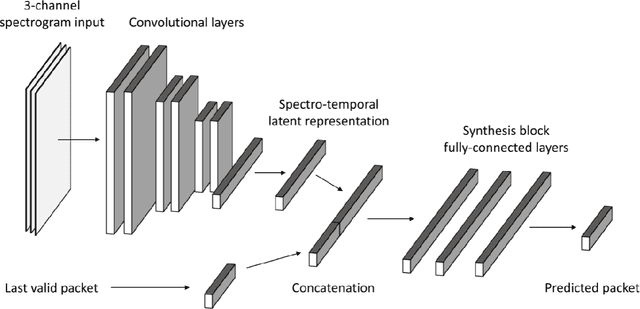
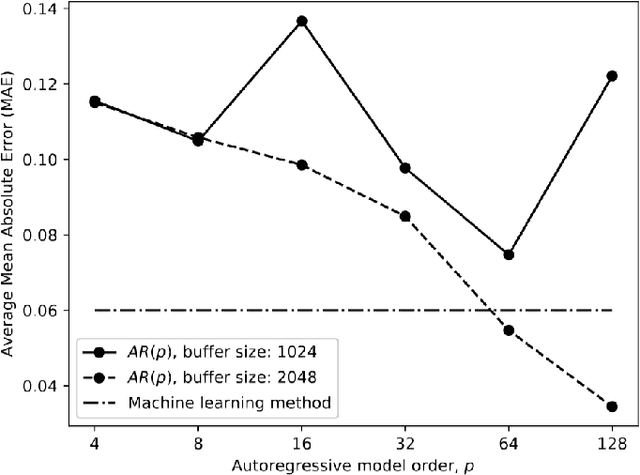
Networked Music Performance (NMP) is envisioned as a potential game changer among Internet applications: it aims at revolutionizing the traditional concept of musical interaction by enabling remote musicians to interact and perform together through a telecommunication network. Ensuring realistic conditions for music performance, however, constitutes a significant engineering challenge due to extremely strict requirements in terms of audio quality and, most importantly, network delay. To minimize the end-to-end delay experienced by the musicians, typical implementations of NMP applications use un-compressed, bidirectional audio streams and leverage UDP as transport protocol. Being connection less and unreliable,audio packets transmitted via UDP which become lost in transit are not re-transmitted and thus cause glitches in the receiver audio playout. This article describes a technique for predicting lost packet content in real-time using a deep learning approach. The ability of concealing errors in real time can help mitigate audio impairments caused by packet losses, thus improving the quality of audio playout in real-world scenarios.
Modeling the Compatibility of Stem Tracks to Generate Music Mashups
Mar 26, 2021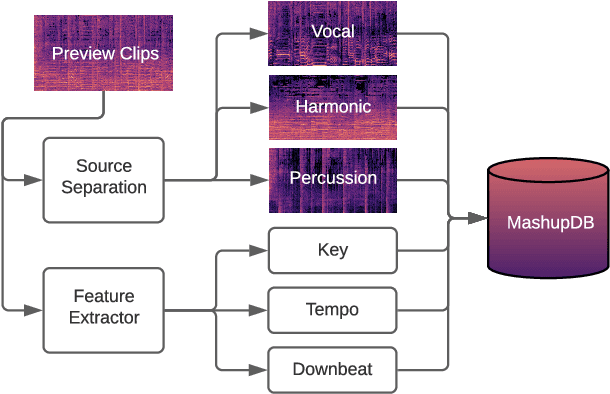
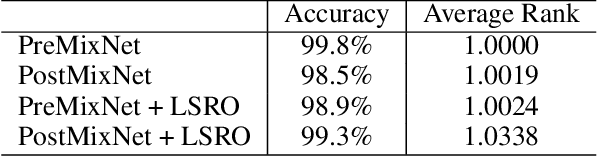
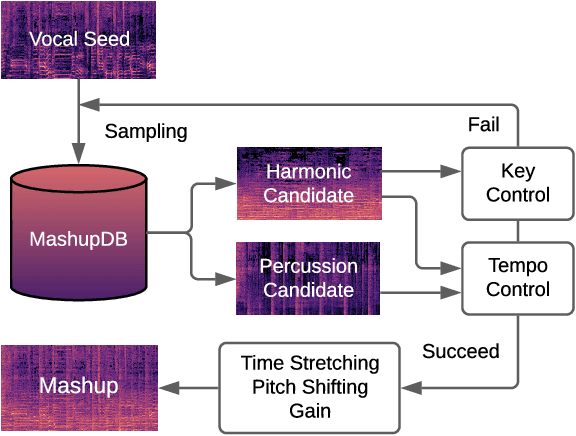
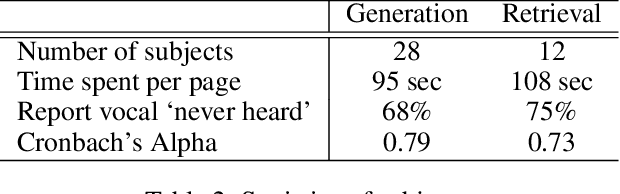
A music mashup combines audio elements from two or more songs to create a new work. To reduce the time and effort required to make them, researchers have developed algorithms that predict the compatibility of audio elements. Prior work has focused on mixing unaltered excerpts, but advances in source separation enable the creation of mashups from isolated stems (e.g., vocals, drums, bass, etc.). In this work, we take advantage of separated stems not just for creating mashups, but for training a model that predicts the mutual compatibility of groups of excerpts, using self-supervised and semi-supervised methods. Specifically, we first produce a random mashup creation pipeline that combines stem tracks obtained via source separation, with key and tempo automatically adjusted to match, since these are prerequisites for high-quality mashups. To train a model to predict compatibility, we use stem tracks obtained from the same song as positive examples, and random combinations of stems with key and/or tempo unadjusted as negative examples. To improve the model and use more data, we also train on "average" examples: random combinations with matching key and tempo, where we treat them as unlabeled data as their true compatibility is unknown. To determine whether the combined signal or the set of stem signals is more indicative of the quality of the result, we experiment on two model architectures and train them using semi-supervised learning technique. Finally, we conduct objective and subjective evaluations of the system, comparing them to a standard rule-based system.
A practical framework for multi-domain speech recognition and an instance sampling method to neural language modeling
Mar 09, 2022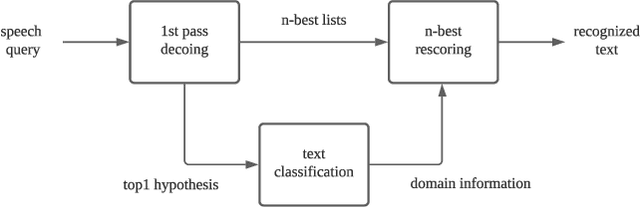

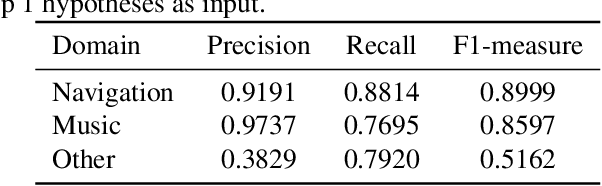
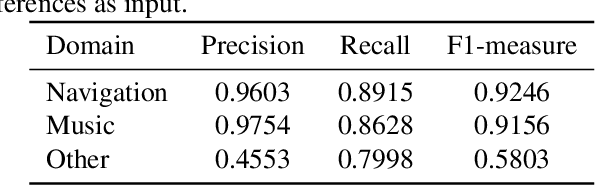
Automatic speech recognition (ASR) systems used on smart phones or vehicles are usually required to process speech queries from very different domains. In such situations, a vanilla ASR system usually fails to perform well on every domain. This paper proposes a multi-domain ASR framework for Tencent Map, a navigation app used on smart phones and in-vehicle infotainment systems. The proposed framework consists of three core parts: a basic ASR module to generate n-best lists of a speech query, a text classification module to determine which domain the speech query belongs to, and a reranking module to rescore n-best lists using domain-specific language models. In addition, an instance sampling based method to training neural network language models (NNLMs) is proposed to address the data imbalance problem in multi-domain ASR. In experiments, the proposed framework was evaluated on navigation domain and music domain, since navigating and playing music are two main features of Tencent Map. Compared to a general ASR system, the proposed framework achieves a relative 13% $\sim$ 22% character error rate reduction on several test sets collected from Tencent Map and our in-car voice assistant.
Gaussian Processes for Music Audio Modelling and Content Analysis
Jun 10, 2016
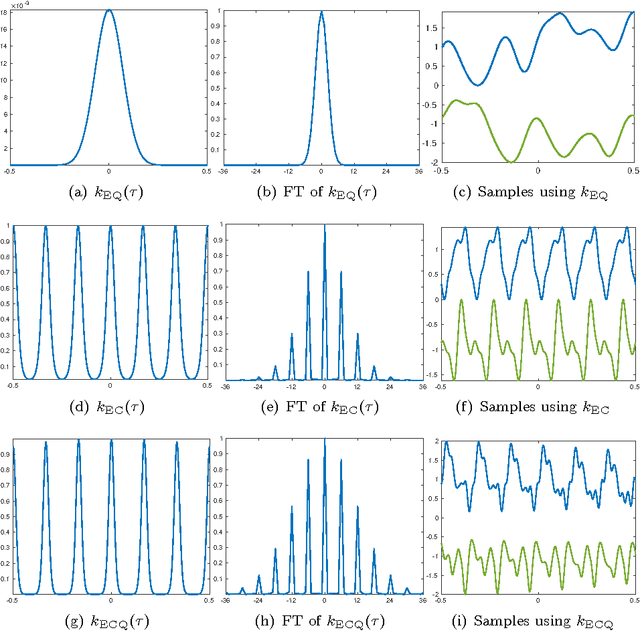
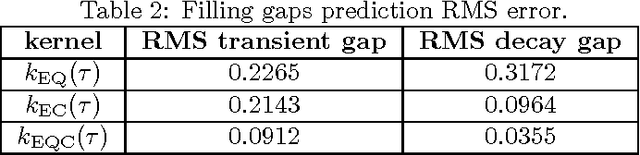
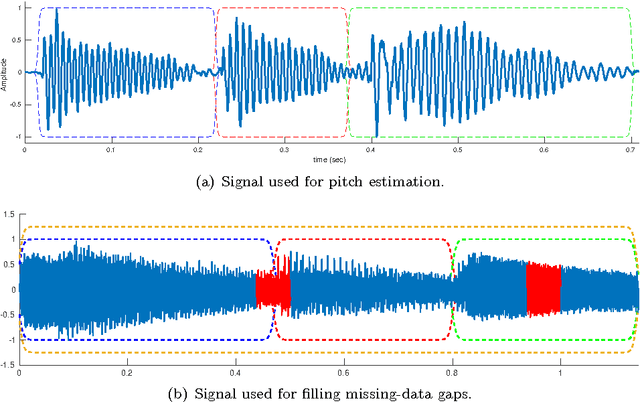
Real music signals are highly variable, yet they have strong statistical structure. Prior information about the underlying physical mechanisms by which sounds are generated and rules by which complex sound structure is constructed (notes, chords, a complete musical score), can be naturally unified using Bayesian modelling techniques. Typically algorithms for Automatic Music Transcription independently carry out individual tasks such as multiple-F0 detection and beat tracking. The challenge remains to perform joint estimation of all parameters. We present a Bayesian approach for modelling music audio, and content analysis. The proposed methodology based on Gaussian processes seeks joint estimation of multiple music concepts by incorporating into the kernel prior information about non-stationary behaviour, dynamics, and rich spectral content present in the modelled music signal. We illustrate the benefits of this approach via two tasks: pitch estimation, and inferring missing segments in a polyphonic audio recording.
Sound2Synth: Interpreting Sound via FM Synthesizer Parameters Estimation
May 06, 2022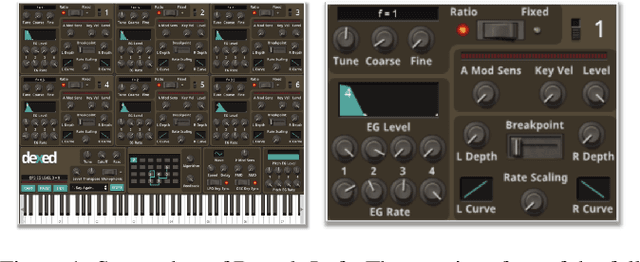
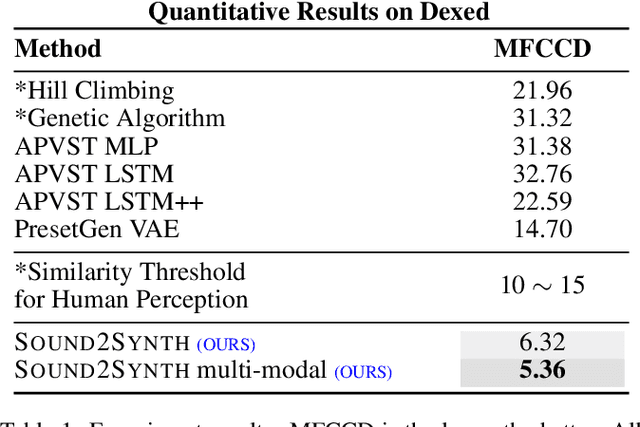
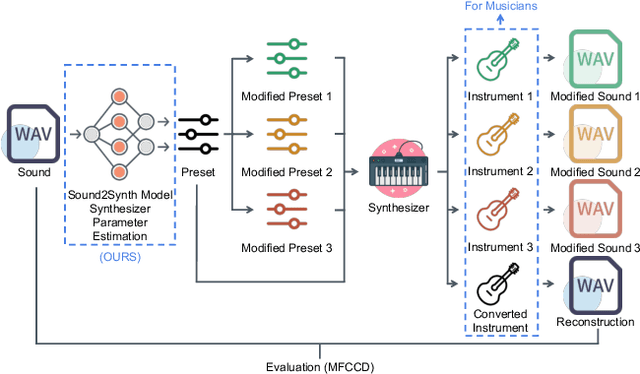
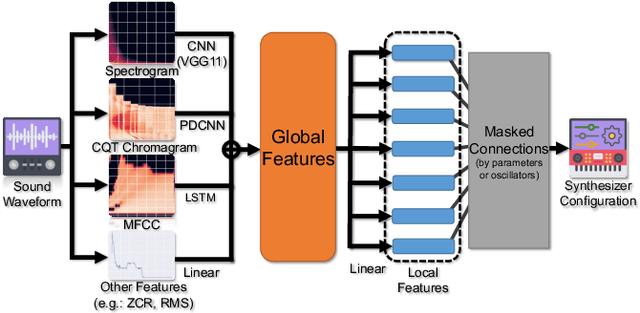
Synthesizer is a type of electronic musical instrument that is now widely used in modern music production and sound design. Each parameters configuration of a synthesizer produces a unique timbre and can be viewed as a unique instrument. The problem of estimating a set of parameters configuration that best restore a sound timbre is an important yet complicated problem, i.e.: the synthesizer parameters estimation problem. We proposed a multi-modal deep-learning-based pipeline Sound2Synth, together with a network structure Prime-Dilated Convolution (PDC) specially designed to solve this problem. Our method achieved not only SOTA but also the first real-world applicable results on Dexed synthesizer, a popular FM synthesizer.
Towards Deep Modeling of Music Semantics using EEG Regularizers
Dec 15, 2017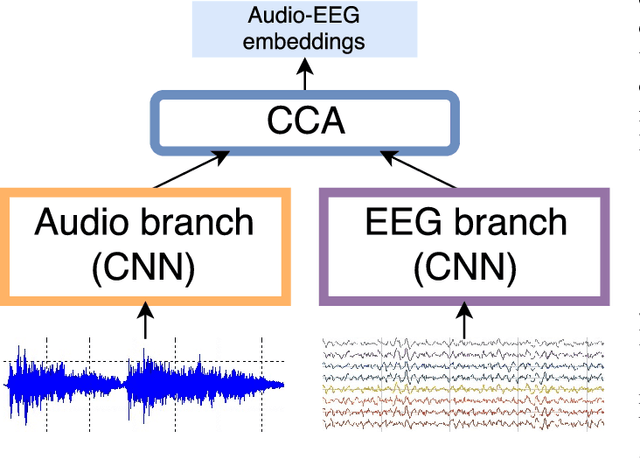
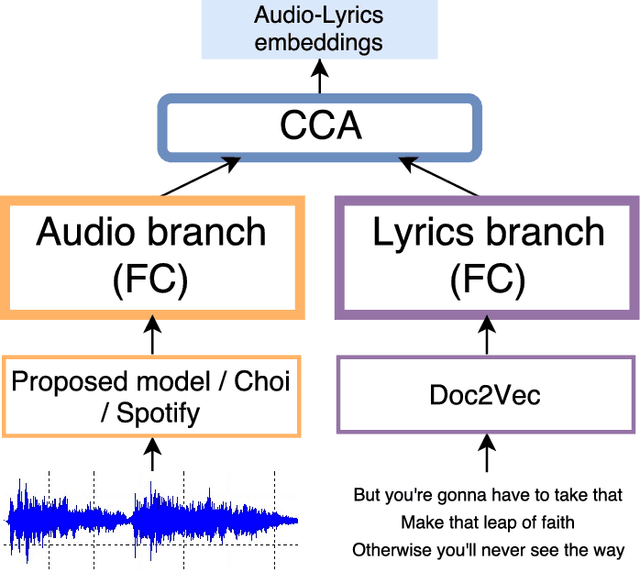

Modeling of music audio semantics has been previously tackled through learning of mappings from audio data to high-level tags or latent unsupervised spaces. The resulting semantic spaces are theoretically limited, either because the chosen high-level tags do not cover all of music semantics or because audio data itself is not enough to determine music semantics. In this paper, we propose a generic framework for semantics modeling that focuses on the perception of the listener, through EEG data, in addition to audio data. We implement this framework using a novel end-to-end 2-view Neural Network (NN) architecture and a Deep Canonical Correlation Analysis (DCCA) loss function that forces the semantic embedding spaces of both views to be maximally correlated. We also detail how the EEG dataset was collected and use it to train our proposed model. We evaluate the learned semantic space in a transfer learning context, by using it as an audio feature extractor in an independent dataset and proxy task: music audio-lyrics cross-modal retrieval. We show that our embedding model outperforms Spotify features and performs comparably to a state-of-the-art embedding model that was trained on 700 times more data. We further discuss improvements to the model that are likely to improve its performance.
Coupled Recurrent Models for Polyphonic Music Composition
Nov 20, 2018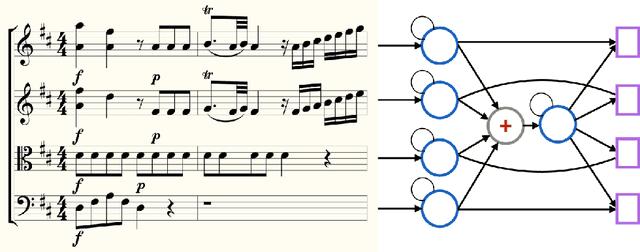



This work describes a novel recurrent model for music composition, which accounts for the rich statistical structure of polyphonic music. There are many ways to factor the probability distribution over musical scores; we consider the merits of various approaches and propose a new factorization that decomposes a score into a collection of concurrent, coupled time series: 'parts.' The model we propose borrows ideas from both convolutional neural models and recurrent neural models; we argue that these ideas are natural for capturing music's pitch invariances, temporal structure, and polyphony. We train generative models for homophonic and polyphonic composition on the KernScores dataset (Sapp, 2005) a collection of 2,300 musical scores comprised of around 2.8 million notes spanning time from the Renaissance to the early 20th century. While evaluation of generative models is known to be hard (Theis et al., 2016), we present careful quantitative results using a unit-adjusted cross entropy metric that is independent of how we factor the distribution over scores. We also present qualitative results using a blind discrimination test.