 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
MIDI-Sandwich: Multi-model Multi-task Hierarchical Conditional VAE-GAN networks for Symbolic Single-track Music Generation
Jul 04, 2019
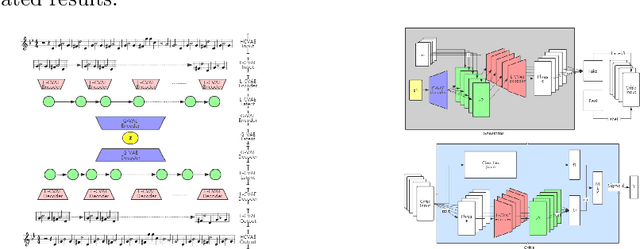
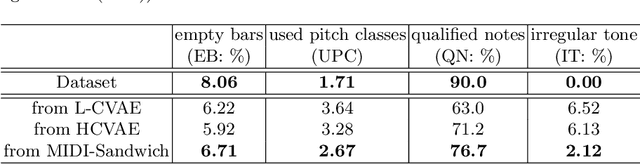
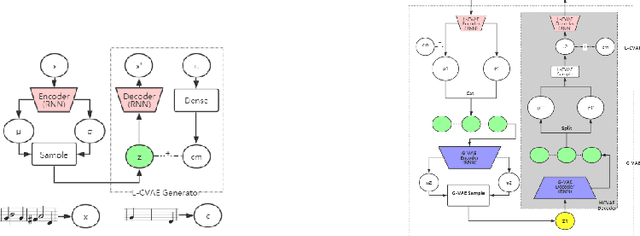
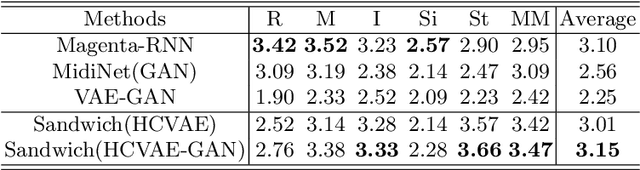
Most existing neural network models for music generation explore how to generate music bars, then directly splice the music bars into a song. However, these methods do not explore the relationship between the bars, and the connected song as a whole has no musical form structure and sense of musical direction. To address this issue, we propose a Multi-model Multi-task Hierarchical Conditional VAE-GAN (Variational Autoencoder-Generative adversarial networks) networks, named MIDI-Sandwich, which combines musical knowledge, such as musical form, tonic, and melodic motion. The MIDI-Sandwich has two submodels: Hierarchical Conditional Variational Autoencoder (HCVAE) and Hierarchical Conditional Generative Adversarial Network (HCGAN). The HCVAE uses hierarchical structure. The underlying layer of HCVAE uses Local Conditional Variational Autoencoder (L-CVAE) to generate a music bar which is pre-specified by the First and Last Notes (FLN). The upper layer of HCVAE uses Global Variational Autoencoder(G-VAE) to analyze the latent vector sequence generated by the L-CVAE encoder, to explore the musical relationship between the bars, and to produce the song pieced together by multiple music bars generated by the L-CVAE decoder, which makes the song both have musical structure and sense of direction. At the same time, the HCVAE shares a part of itself with the HCGAN to further improve the performance of the generated music. The MIDI-Sandwich is validated on the Nottingham dataset and is able to generate a single-track melody sequence (17x8 beats), which is superior to the length of most of the generated models (8 to 32 beats). Meanwhile, by referring to the experimental methods of many classical kinds of literature, the quality evaluation of the generated music is performed. The above experiments prove the validity of the model.
DEEPF0: End-To-End Fundamental Frequency Estimation for Music and Speech Signals
Feb 11, 2021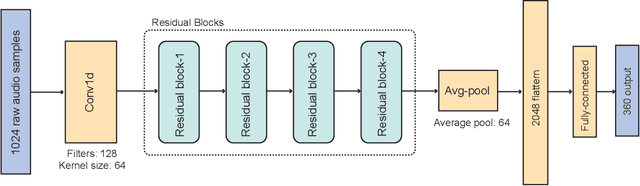
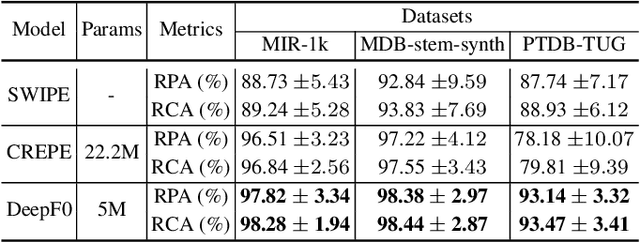
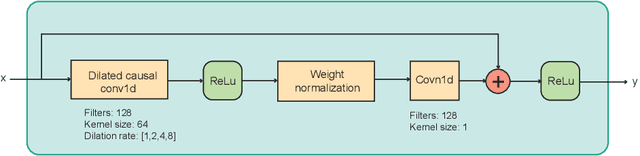
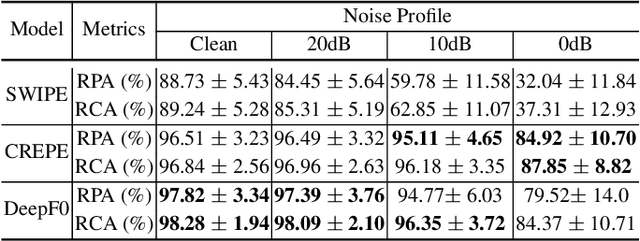
We propose a novel pitch estimation technique called DeepF0, which leverages the available annotated data to directly learns from the raw audio in a data-driven manner. F0 estimation is important in various speech processing and music information retrieval applications. Existing deep learning models for pitch estimations have relatively limited learning capabilities due to their shallow receptive field. The proposed model addresses this issue by extending the receptive field of a network by introducing the dilated convolutional blocks into the network. The dilation factor increases the network receptive field exponentially without increasing the parameters of the model exponentially. To make the training process more efficient and faster, DeepF0 is augmented with residual blocks with residual connections. Our empirical evaluation demonstrates that the proposed model outperforms the baselines in terms of raw pitch accuracy and raw chroma accuracy even using 77.4% fewer network parameters. We also show that our model can capture reasonably well pitch estimation even under the various levels of accompaniment noise.
A dataset and classification model for Malay, Hindi, Tamil and Chinese music
Sep 15, 2020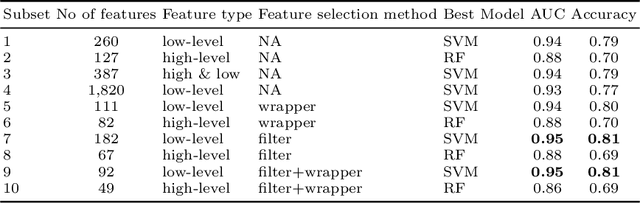
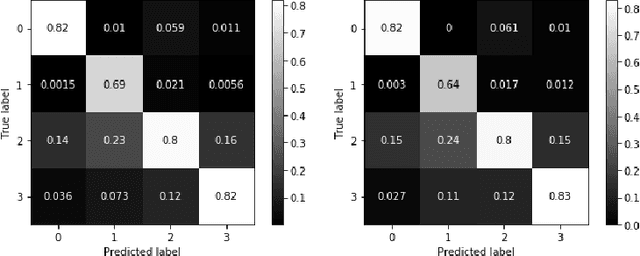
In this paper we present a new dataset, with musical excepts from the three main ethnic groups in Singapore: Chinese, Malay and Indian (both Hindi and Tamil). We use this new dataset to train different classification models to distinguish the origin of the music in terms of these ethnic groups. The classification models were optimized by exploring the use of different musical features as the input. Both high level features, i.e., musically meaningful features, as well as low level features, i.e., spectrogram based features, were extracted from the audio files so as to optimize the performance of the different classification models.
D3Net: Densely connected multidilated DenseNet for music source separation
Oct 15, 2020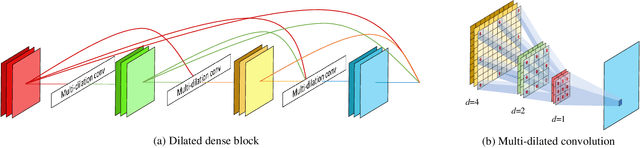
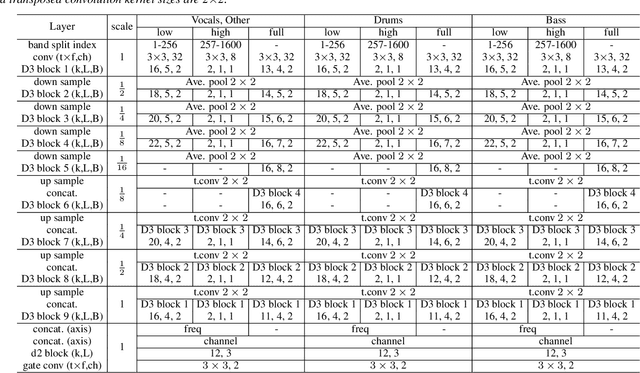
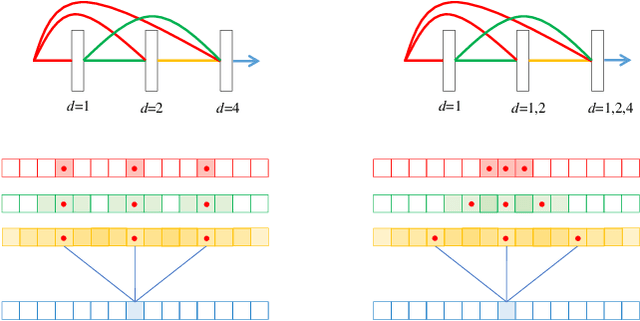
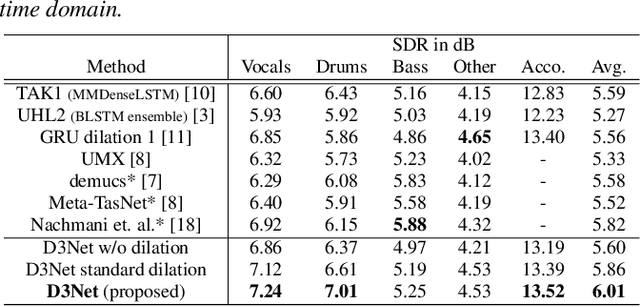
Music source separation involves a large input field to model a long-term dependence of an audio signal. Previous convolutional neural network (CNN) -based approaches address the large input field modeling using sequentially down- and up-sampling feature maps or dilated convolution. In this paper, we claim the importance of a rapid growth of a receptive field and a simultaneous modeling of multi-resolution data in a single convolution layer, and propose a novel CNN architecture called densely connected dilated DenseNet (D3Net). D3Net involves a novel multi-dilated convolution that has different dilation factors in a single layer to model different resolutions simultaneously. By combining the multi-dilated convolution with DenseNet architecture, D3Net avoids the aliasing problem that exists when we naively incorporate the dilated convolution in DenseNet. Experimental results on MUSDB18 dataset show that D3Net achieves state-of-the-art performance with an average signal to distortion ratio (SDR) of 6.01 dB.
Music Source Separation in the Waveform Domain
Nov 27, 2019



Source separation for music is the task of isolating contributions, or stems, from different instruments recorded individually and arranged together to form a song. Such components include voice, bass, drums and any other accompaniments. Contrarily to many audio synthesis tasks where the best performances are achieved by models that directly generate the waveform, the state-of-the-art in source separation for music is to compute masks on the magnitude spectrum. In this paper, we first show that an adaptation of Conv-Tasnet (Luo \& Mesgarani, 2019), a waveform-to-waveform model for source separation for speech, significantly beats the state-of-the-art on the MusDB dataset, the standard benchmark of multi-instrument source separation. Second, we observe that Conv-Tasnet follows a masking approach on the input signal, which has the potential drawback of removing parts of the relevant source without the capacity to reconstruct it. We propose Demucs, a new waveform-to-waveform model, which has an architecture closer to models for audio generation with more capacity on the decoder. Experiments on the MusDB dataset show that Demucs beats previously reported results in terms of signal to distortion ratio (SDR), but lower than Conv-Tasnet. Human evaluations show that Demucs has significantly higher quality (as assessed by mean opinion score) than Conv-Tasnet, but slightly more contamination from other sources, which explains the difference in SDR. Additional experiments with a larger dataset suggest that the gap in SDR between Demucs and Conv-Tasnet shrinks, showing that our approach is promising.
MELONS: generating melody with long-term structure using transformers and structure graph
Nov 03, 2021

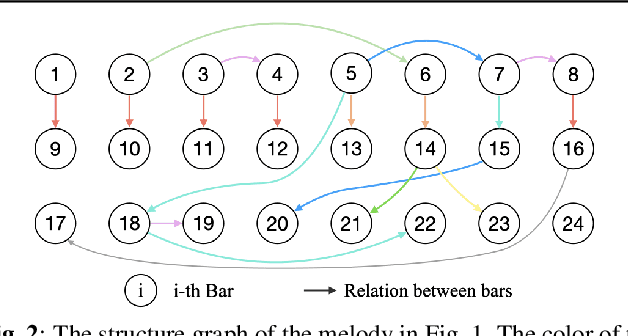
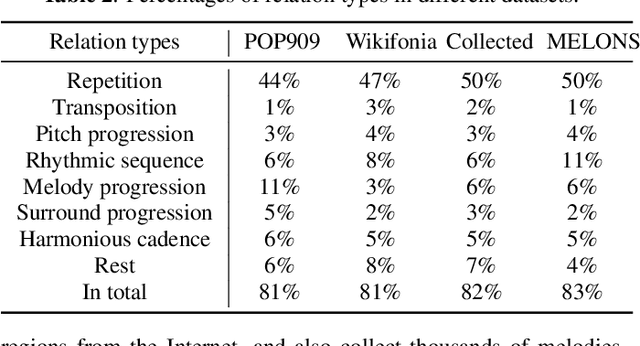
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
The Bach Doodle: Approachable music composition with machine learning at scale
Jul 14, 2019
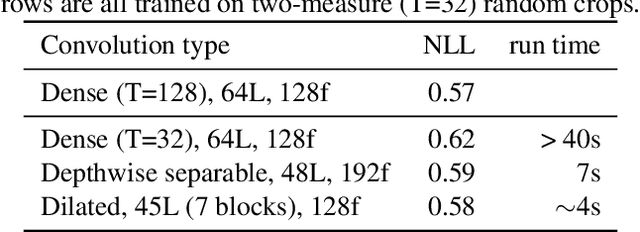

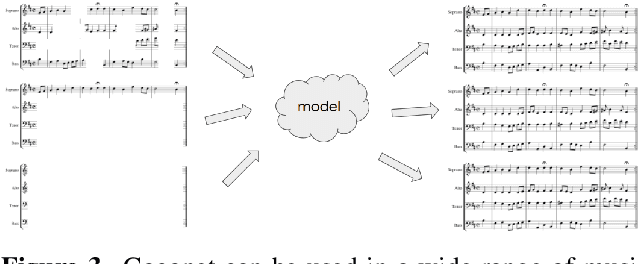
To make music composition more approachable, we designed the first AI-powered Google Doodle, the Bach Doodle, where users can create their own melody and have it harmonized by a machine learning model Coconet (Huang et al., 2017) in the style of Bach. For users to input melodies, we designed a simplified sheet-music based interface. To support an interactive experience at scale, we re-implemented Coconet in TensorFlow.js (Smilkov et al., 2019) to run in the browser and reduced its runtime from 40s to 2s by adopting dilated depth-wise separable convolutions and fusing operations. We also reduced the model download size to approximately 400KB through post-training weight quantization. We calibrated a speed test based on partial model evaluation time to determine if the harmonization request should be performed locally or sent to remote TPU servers. In three days, people spent 350 years worth of time playing with the Bach Doodle, and Coconet received more than 55 million queries. Users could choose to rate their compositions and contribute them to a public dataset, which we are releasing with this paper. We hope that the community finds this dataset useful for applications ranging from ethnomusicological studies, to music education, to improving machine learning models.
Cutting Music Source Separation Some Slakh: A Dataset to Study the Impact of Training Data Quality and Quantity
Sep 18, 2019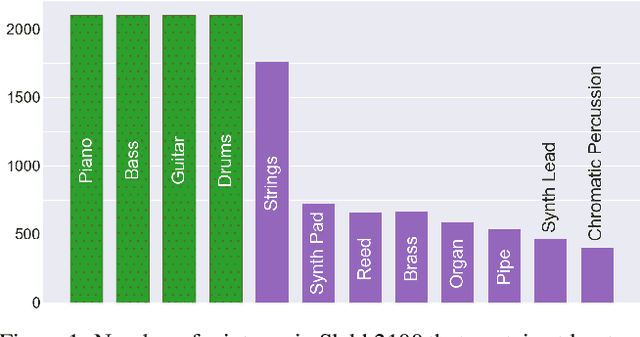
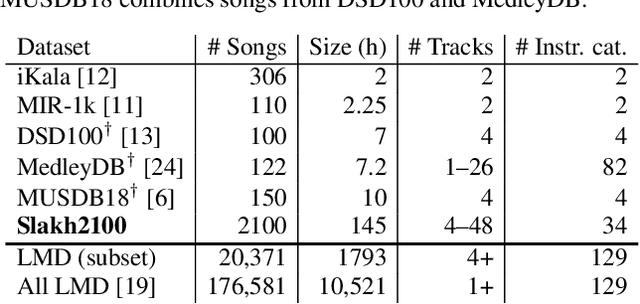
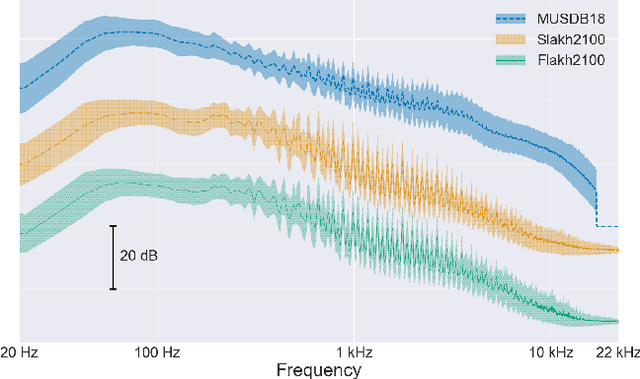
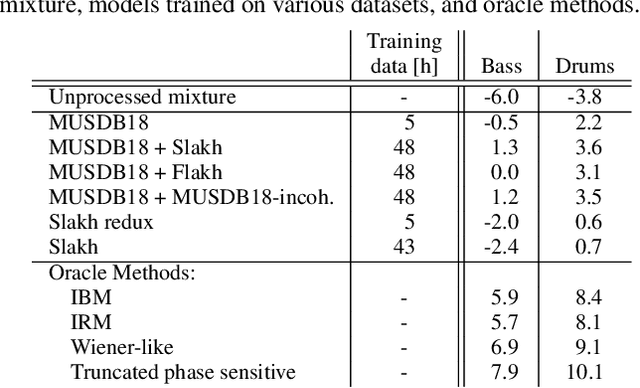
Music source separation performance has greatly improved in recent years with the advent of approaches based on deep learning. Such methods typically require large amounts of labelled training data, which in the case of music consist of mixtures and corresponding instrument stems. However, stems are unavailable for most commercial music, and only limited datasets have so far been released to the public. It can thus be difficult to draw conclusions when comparing various source separation methods, as the difference in performance may stem as much from better data augmentation techniques or training tricks to alleviate the limited availability of training data, as from intrinsically better model architectures and objective functions. In this paper, we present the synthesized Lakh dataset (Slakh) as a new tool for music source separation research. Slakh consists of high-quality renderings of instrumental mixtures and corresponding stems generated from the Lakh MIDI dataset (LMD) using professional-grade sample-based virtual instruments. A first version, Slakh2100, focuses on 2100 songs, resulting in 145 hours of mixtures. While not fully comparable because it is purely instrumental, this dataset contains an order of magnitude more data than MUSDB18, the {\it de facto} standard dataset in the field. We show that Slakh can be used to effectively augment existing datasets for musical instrument separation, while opening the door to a wide array of data-intensive music signal analysis tasks.