 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Musical Score Following and Audio Alignment
May 06, 2022

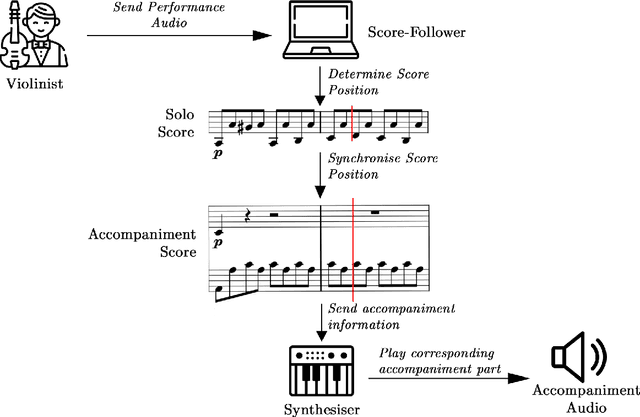
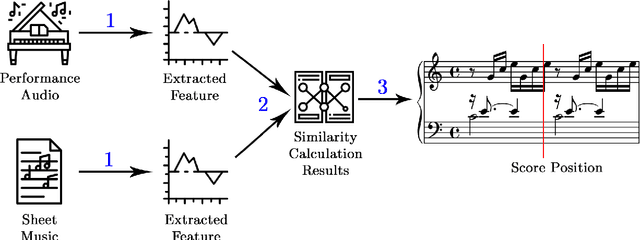
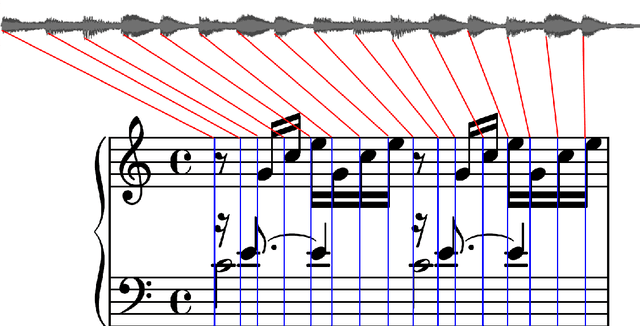
Real-time tracking of the position of a musical performance on a musical score, i.e. score following, can be useful in music practice, performance and production. Example applications of such technology include computer-aided accompaniment and automatic page turning. Score following is a challenging task, especially when considering deviations in performance data from the score stemming from mistakes or expressive choices. In this project, the extensive research present in the field is first explored before two open-source evaluation testbenches for score following--one quantitative and the other qualitative--are introduced. A new way of obtaining quantitative testbench data is proposed, and the QualScofo dataset for qualitative benchmarking is introduced. Subsequently, three different score followers, each of a different class, are implemented. First, a beat-based follower for an interactive conductor application--the TuneApp Conductor--is created to demonstrate an entertaining application of score following. Then, an Approximate String Matching (ASM) non-real-time follower is implemented to complement the quantitative testbench and provide more technical background details of score following. Finally, a Constant Q-Transform (CQT) Dynamic Time Warping (DTW) score follower robust against major challenges in score following (such as polyphonic music and performance deviations) is outlined and implemented; it is shown that this CQT-based approach consistently and significantly outperforms a commonly used FFT-based approach in extracting audio features for score following.
DrumGAN VST: A Plugin for Drum Sound Analysis/Synthesis With Autoencoding Generative Adversarial Networks
Jun 29, 2022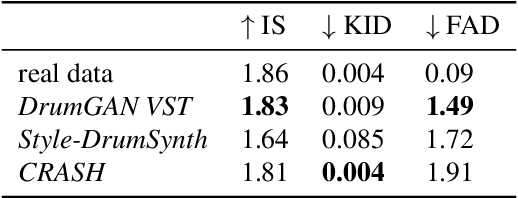
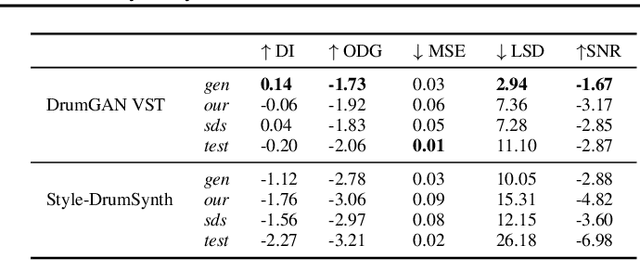
In contemporary popular music production, drum sound design is commonly performed by cumbersome browsing and processing of pre-recorded samples in sound libraries. One can also use specialized synthesis hardware, typically controlled through low-level, musically meaningless parameters. Today, the field of Deep Learning offers methods to control the synthesis process via learned high-level features and allows generating a wide variety of sounds. In this paper, we present DrumGAN VST, a plugin for synthesizing drum sounds using a Generative Adversarial Network. DrumGAN VST operates on 44.1 kHz sample-rate audio, offers independent and continuous instrument class controls, and features an encoding neural network that maps sounds into the GAN's latent space, enabling resynthesis and manipulation of pre-existing drum sounds. We provide numerous sound examples and a demo of the proposed VST plugin.
QAC: Quantum-computing Aided Composition
Feb 09, 2022
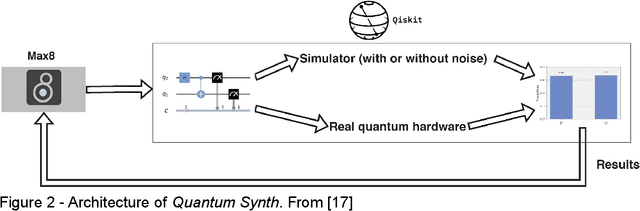
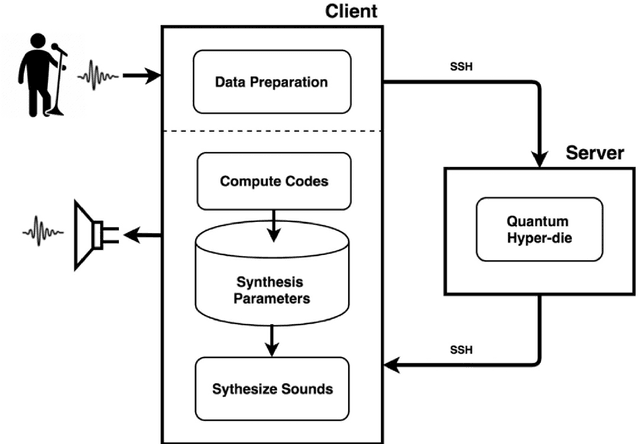
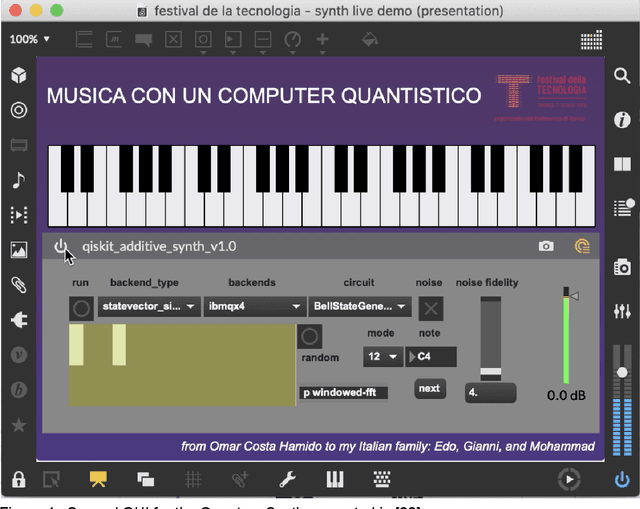
In this chapter I will discuss the role of quantum computing in computer music and how it can be integrated to better serve the creative artists. I will start by considering different approaches in current computer music and quantum computing tools, as well as reviewing some previous attempts to integrate them. Then, I will reflect on the meaning of this integration and present what I coined as QAC (Quantum-computing Aided Composition) as well as an early attempt at realizing it. This chapter will also introduce The QAC Toolkit Max package, analyze its performance, and explore some examples of what it can offer to realtime creative practice. Lastly, I will present a real case scenario of QAC in the creative work Disklavier Prelude #3.
Uncertainty Calibration for Deep Audio Classifiers
Jun 27, 2022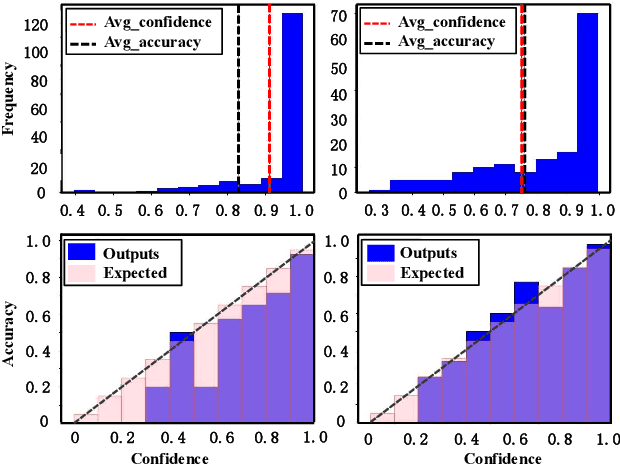
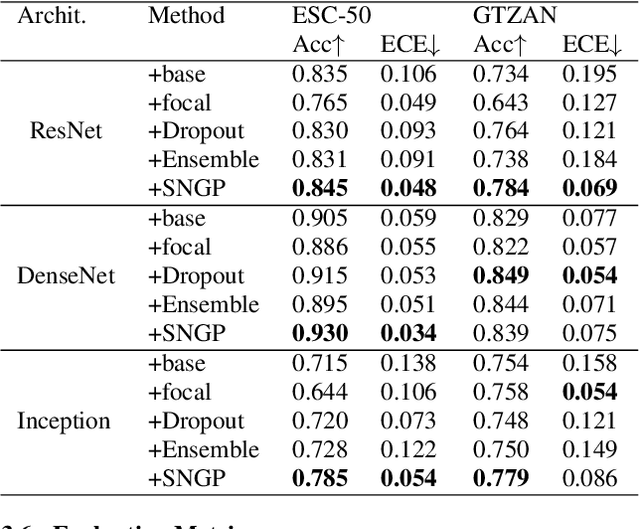
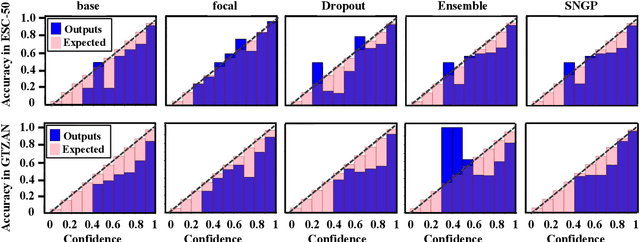
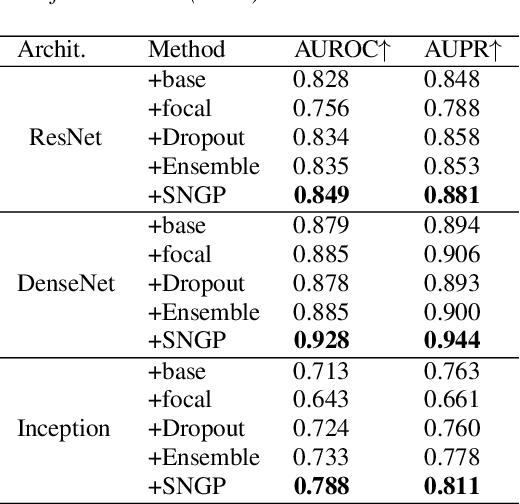
Although deep Neural Networks (DNNs) have achieved tremendous success in audio classification tasks, their uncertainty calibration are still under-explored. A well-calibrated model should be accurate when it is certain about its prediction and indicate high uncertainty when it is likely to be inaccurate. In this work, we investigate the uncertainty calibration for deep audio classifiers. In particular, we empirically study the performance of popular calibration methods: (i) Monte Carlo Dropout, (ii) ensemble, (iii) focal loss, and (iv) spectral-normalized Gaussian process (SNGP), on audio classification datasets. To this end, we evaluate (i-iv) for the tasks of environment sound and music genre classification. Results indicate that uncalibrated deep audio classifiers may be over-confident, and SNGP performs the best and is very efficient on the two datasets of this paper.
Mind the beat: detecting audio onsets from EEG recordings of music listening
Feb 12, 2021
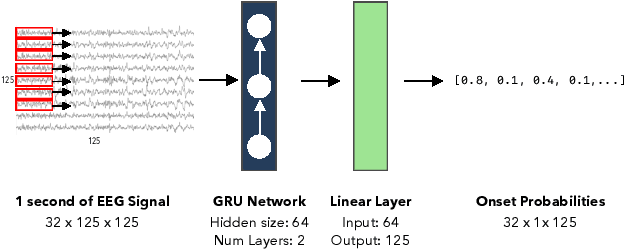
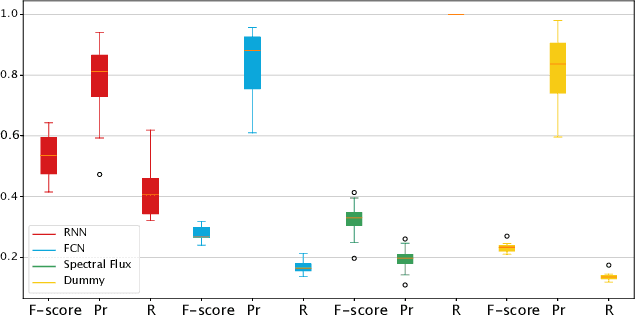
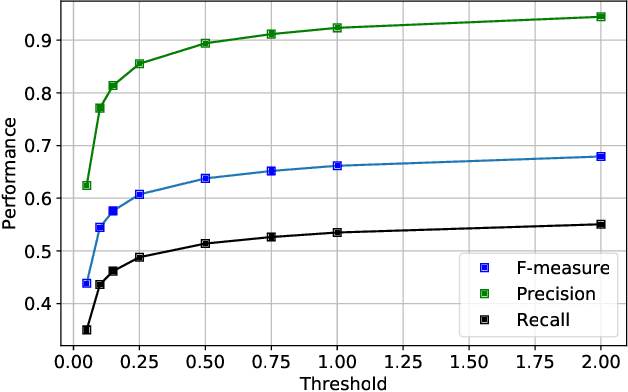
We propose a deep learning approach to predicting audio event onsets in electroencephalogram (EEG) recorded from users as they listen to music. We use a publicly available dataset containing ten contemporary songs and concurrently recorded EEG. We generate a sequence of onset labels for the songs in our dataset and trained neural networks (a fully connected network (FCN) and a recurrent neural network (RNN)) to parse one second windows of input EEG to predict one second windows of onsets in the audio. We compare our RNN network to both the standard spectral-flux based novelty function and the FCN. We find that our RNN was able to produce results that reflected its ability to generalize better than the other methods. Since there are no pre-existing works on this topic, the numbers presented in this paper may serve as useful benchmarks for future approaches to this research problem.
Convolutional Recurrent Neural Networks for Music Classification
Dec 21, 2016
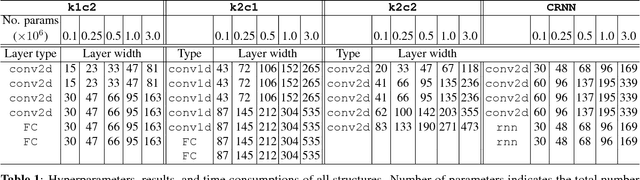
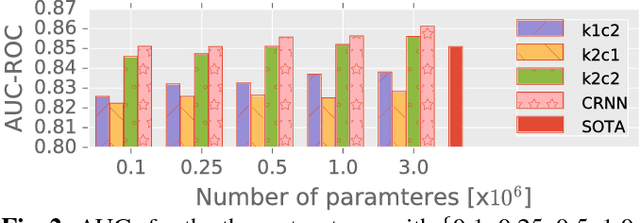
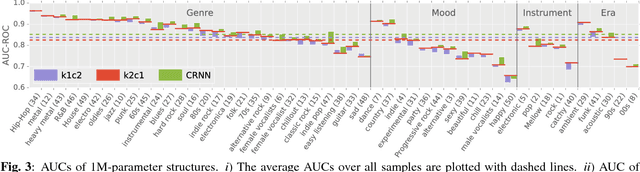
We introduce a convolutional recurrent neural network (CRNN) for music tagging. CRNNs take advantage of convolutional neural networks (CNNs) for local feature extraction and recurrent neural networks for temporal summarisation of the extracted features. We compare CRNN with three CNN structures that have been used for music tagging while controlling the number of parameters with respect to their performance and training time per sample. Overall, we found that CRNNs show a strong performance with respect to the number of parameter and training time, indicating the effectiveness of its hybrid structure in music feature extraction and feature summarisation.
Score difficulty analysis for piano performance education based on fingering
Mar 24, 2022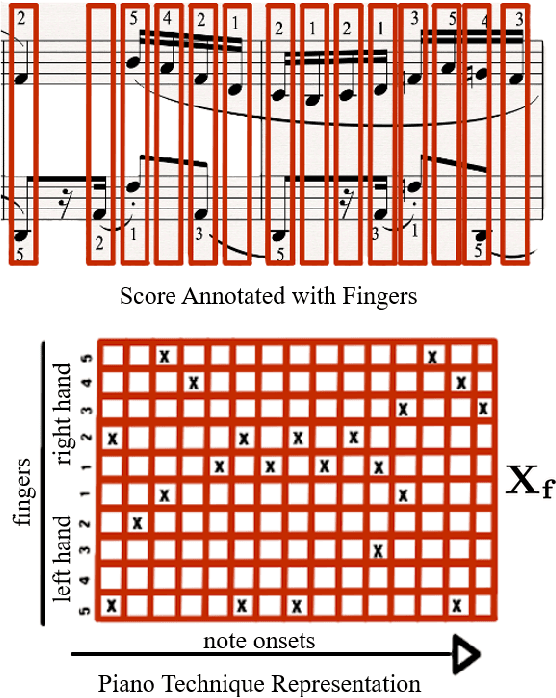

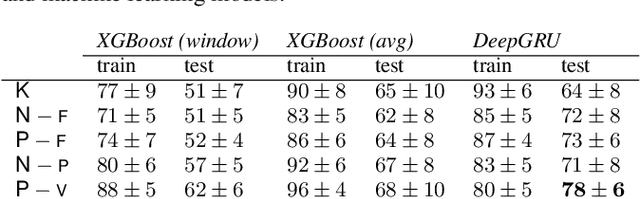
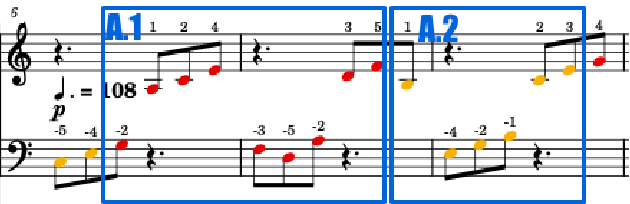
In this paper, we introduce score difficulty classification as a sub-task of music information retrieval (MIR), which may be used in music education technologies, for personalised curriculum generation, and score retrieval. We introduce a novel dataset for our task, Mikrokosmos-difficulty, containing 147 piano pieces in symbolic representation and the corresponding difficulty labels derived by its composer B\'ela Bart\'ok and the publishers. As part of our methodology, we propose piano technique feature representations based on different piano fingering algorithms. We use these features as input for two classifiers: a Gated Recurrent Unit neural network (GRU) with attention mechanism and gradient-boosted trees trained on score segments. We show that for our dataset fingering based features perform better than a simple baseline considering solely the notes in the score. Furthermore, the GRU with attention mechanism classifier surpasses the gradient-boosted trees. Our proposed models are interpretable and are capable of generating difficulty feedback both locally, on short term segments, and globally, for whole pieces. Code, datasets, models, and an online demo are made available for reproducibility
MIDI-Sandwich: Multi-model Multi-task Hierarchical Conditional VAE-GAN networks for Symbolic Single-track Music Generation
Jul 04, 2019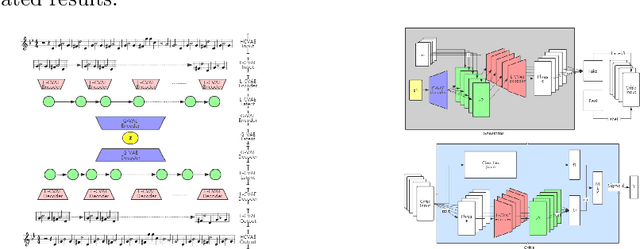
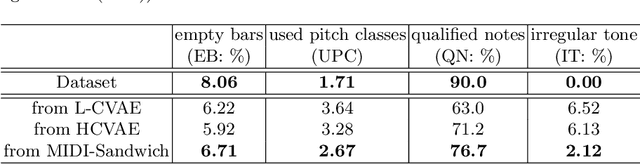
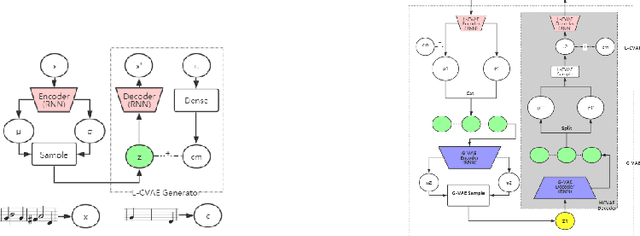
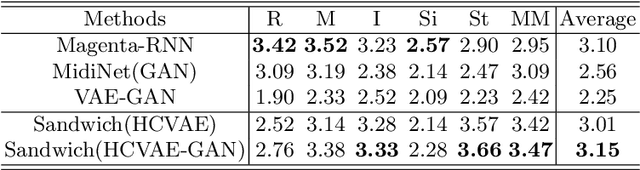
Most existing neural network models for music generation explore how to generate music bars, then directly splice the music bars into a song. However, these methods do not explore the relationship between the bars, and the connected song as a whole has no musical form structure and sense of musical direction. To address this issue, we propose a Multi-model Multi-task Hierarchical Conditional VAE-GAN (Variational Autoencoder-Generative adversarial networks) networks, named MIDI-Sandwich, which combines musical knowledge, such as musical form, tonic, and melodic motion. The MIDI-Sandwich has two submodels: Hierarchical Conditional Variational Autoencoder (HCVAE) and Hierarchical Conditional Generative Adversarial Network (HCGAN). The HCVAE uses hierarchical structure. The underlying layer of HCVAE uses Local Conditional Variational Autoencoder (L-CVAE) to generate a music bar which is pre-specified by the First and Last Notes (FLN). The upper layer of HCVAE uses Global Variational Autoencoder(G-VAE) to analyze the latent vector sequence generated by the L-CVAE encoder, to explore the musical relationship between the bars, and to produce the song pieced together by multiple music bars generated by the L-CVAE decoder, which makes the song both have musical structure and sense of direction. At the same time, the HCVAE shares a part of itself with the HCGAN to further improve the performance of the generated music. The MIDI-Sandwich is validated on the Nottingham dataset and is able to generate a single-track melody sequence (17x8 beats), which is superior to the length of most of the generated models (8 to 32 beats). Meanwhile, by referring to the experimental methods of many classical kinds of literature, the quality evaluation of the generated music is performed. The above experiments prove the validity of the model.
Fast online ranking with fairness of exposure
Sep 13, 2022
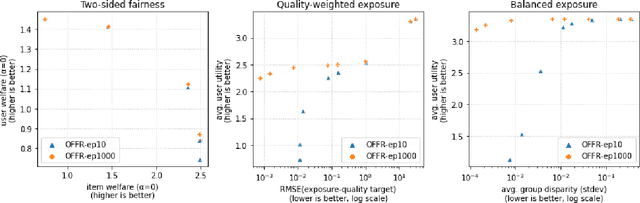
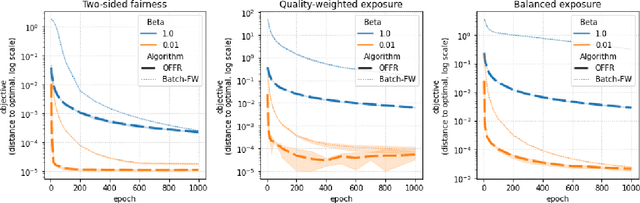
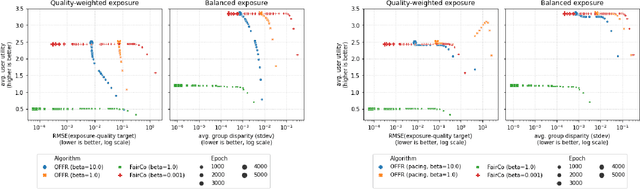
As recommender systems become increasingly central for sorting and prioritizing the content available online, they have a growing impact on the opportunities or revenue of their items producers. For instance, they influence which recruiter a resume is recommended to, or to whom and how much a music track, video or news article is being exposed. This calls for recommendation approaches that not only maximize (a proxy of) user satisfaction, but also consider some notion of fairness in the exposure of items or groups of items. Formally, such recommendations are usually obtained by maximizing a concave objective function in the space of randomized rankings. When the total exposure of an item is defined as the sum of its exposure over users, the optimal rankings of every users become coupled, which makes the optimization process challenging. Existing approaches to find these rankings either solve the global optimization problem in a batch setting, i.e., for all users at once, which makes them inapplicable at scale, or are based on heuristics that have weak theoretical guarantees. In this paper, we propose the first efficient online algorithm to optimize concave objective functions in the space of rankings which applies to every concave and smooth objective function, such as the ones found for fairness of exposure. Based on online variants of the Frank-Wolfe algorithm, we show that our algorithm is computationally fast, generating rankings on-the-fly with computation cost dominated by the sort operation, memory efficient, and has strong theoretical guarantees. Compared to baseline policies that only maximize user-side performance, our algorithm allows to incorporate complex fairness of exposure criteria in the recommendations with negligible computational overhead.