 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Supervised Chorus Detection for Popular Music Using Convolutional Neural Network and Multi-task Learning
Mar 26, 2021
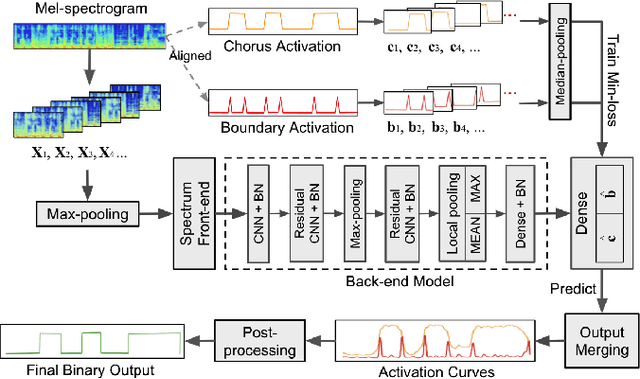
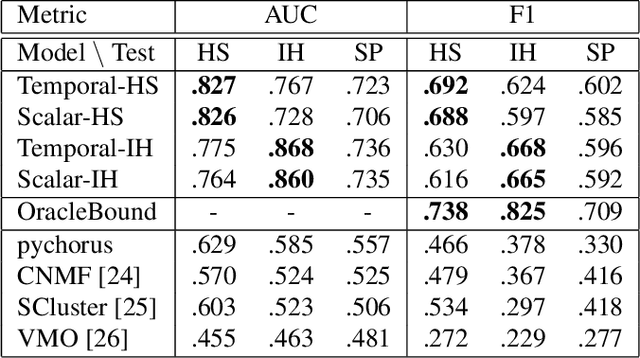
This paper presents a novel supervised approach to detecting the chorus segments in popular music. Traditional approaches to this task are mostly unsupervised, with pipelines designed to target some quality that is assumed to define "chorusness," which usually means seeking the loudest or most frequently repeated sections. We propose to use a convolutional neural network with a multi-task learning objective, which simultaneously fits two temporal activation curves: one indicating "chorusness" as a function of time, and the other the location of the boundaries. We also propose a post-processing method that jointly takes into account the chorus and boundary predictions to produce binary output. In experiments using three datasets, we compare our system to a set of public implementations of other segmentation and chorus-detection algorithms, and find our approach performs significantly better.
Natural Language Processing for Music Knowledge Discovery
Jul 06, 2018
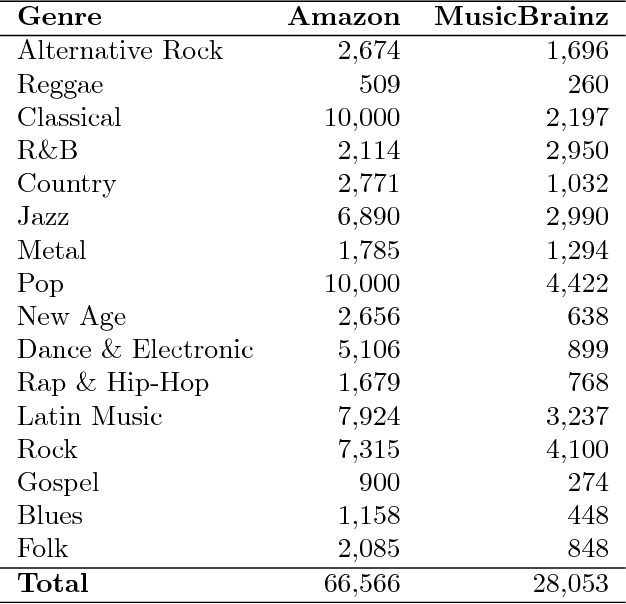

Today, a massive amount of musical knowledge is stored in written form, with testimonies dated as far back as several centuries ago. In this work, we present different Natural Language Processing (NLP) approaches to harness the potential of these text collections for automatic music knowledge discovery, covering different phases in a prototypical NLP pipeline, namely corpus compilation, text-mining, information extraction, knowledge graph generation and sentiment analysis. Each of these approaches is presented alongside different use cases (i.e., flamenco, Renaissance and popular music) where large collections of documents are processed, and conclusions stemming from data-driven analyses are presented and discussed.
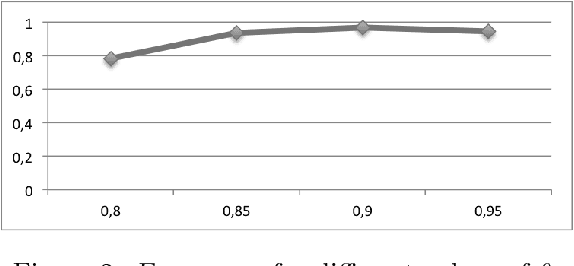
Convolutional Neural Network Achieves Human-level Accuracy in Music Genre Classification
Feb 27, 2018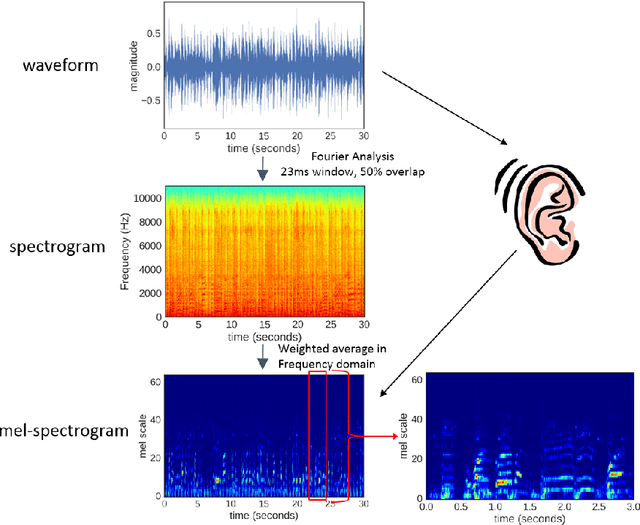
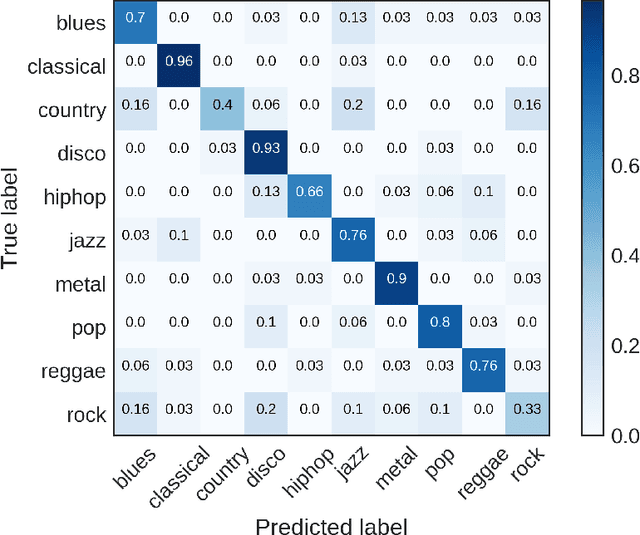
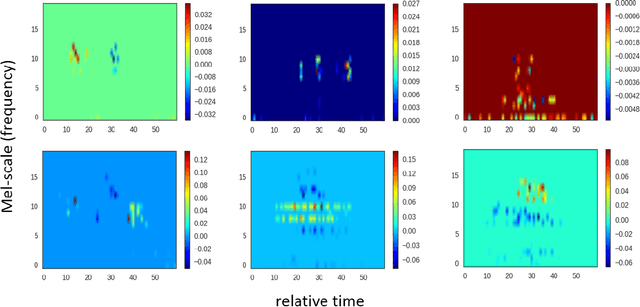
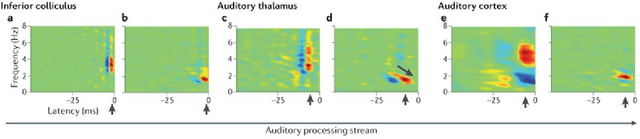
Music genre classification is one example of content-based analysis of music signals. Traditionally, human-engineered features were used to automatize this task and 61% accuracy has been achieved in the 10-genre classification. However, it's still below the 70% accuracy that humans could achieve in the same task. Here, we propose a new method that combines knowledge of human perception study in music genre classification and the neurophysiology of the auditory system. The method works by training a simple convolutional neural network (CNN) to classify a short segment of the music signal. Then, the genre of a music is determined by splitting it into short segments and then combining CNN's predictions from all short segments. After training, this method achieves human-level (70%) accuracy and the filters learned in the CNN resemble the spectrotemporal receptive field (STRF) in the auditory system.
Composing Music with Grammar Argumented Neural Networks and Note-Level Encoding
Dec 07, 2016
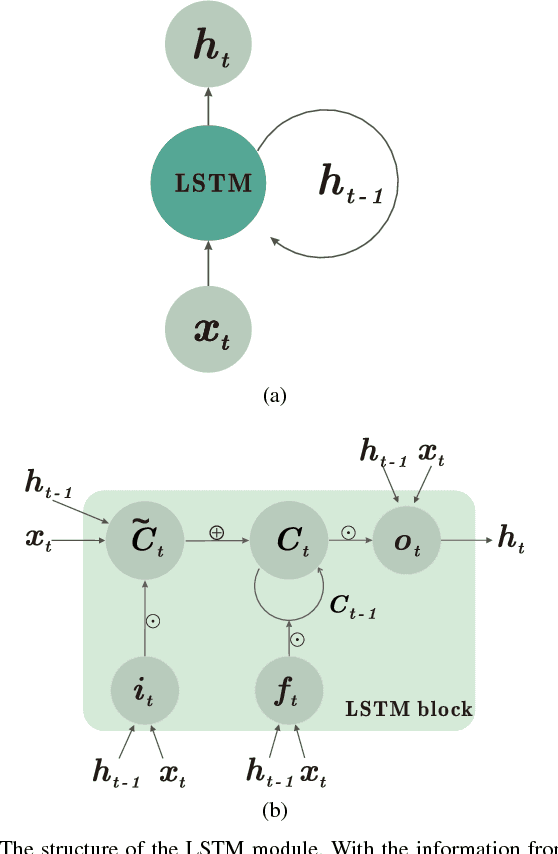
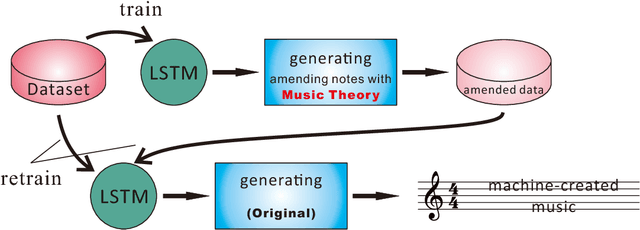

Creating aesthetically pleasing pieces of art, including music, has been a long-term goal for artificial intelligence research. Despite recent successes of long-short term memory (LSTM) recurrent neural networks (RNNs) in sequential learning, LSTM neural networks have not, by themselves, been able to generate natural-sounding music conforming to music theory. To transcend this inadequacy, we put forward a novel method for music composition that combines the LSTM with Grammars motivated by music theory. The main tenets of music theory are encoded as grammar argumented (GA) filters on the training data, such that the machine can be trained to generate music inheriting the naturalness of human-composed pieces from the original dataset while adhering to the rules of music theory. Unlike previous approaches, pitches and durations are encoded as one semantic entity, which we refer to as note-level encoding. This allows easy implementation of music theory grammars, as well as closer emulation of the thinking pattern of a musician. Although the GA rules are applied to the training data and never directly to the LSTM music generation, our machine still composes music that possess high incidences of diatonic scale notes, small pitch intervals and chords, in deference to music theory.
Exploring Graph Representation of Chorales
Jan 27, 2022

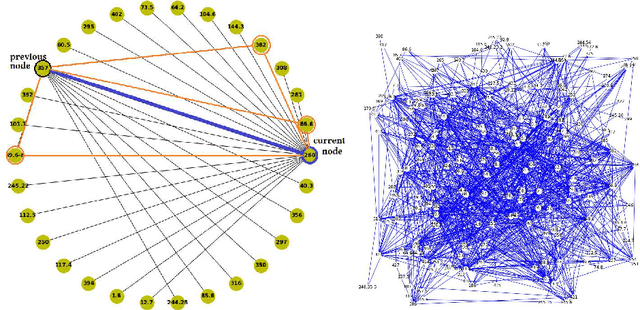

This work explores areas overlapping music, graph theory, and machine learning. An embedding representation of a node, in a weighted undirected graph $\mathcal{G}$, is a representation that captures the meaning of nodes in an embedding space. In this work, 383 Bach chorales were compiled and represented as a graph. Two application cases were investigated in this paper (i) learning node embedding representation using \emph{Continuous Bag of Words (CBOW), skip-gram}, and \emph{node2vec} algorithms, and (ii) learning node labels from neighboring nodes based on a collective classification approach. The results of this exploratory study ascertains many salient features of the graph-based representation approach applicable to music applications.
Towards the bio-personalization of music recommendation systems: A single-sensor EEG biomarker of subjective music preference
Sep 21, 2016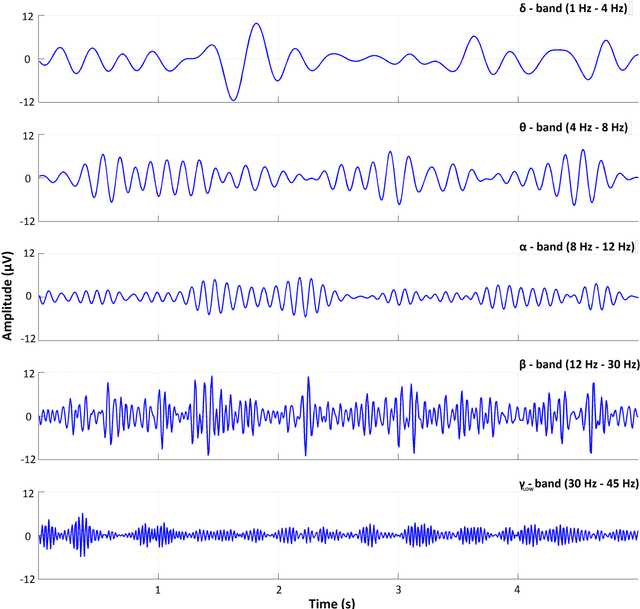
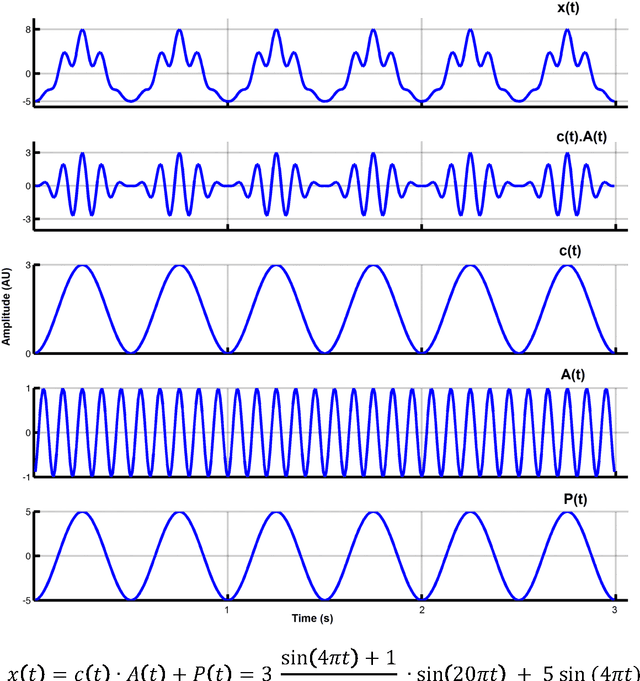
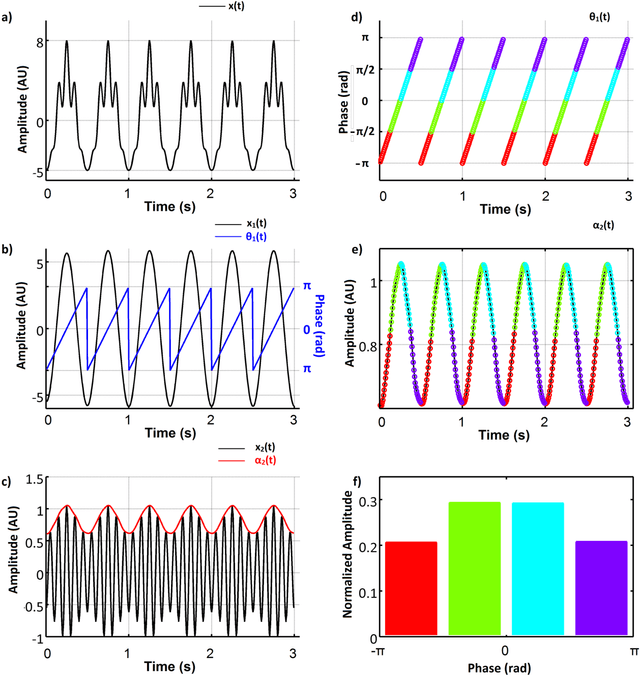
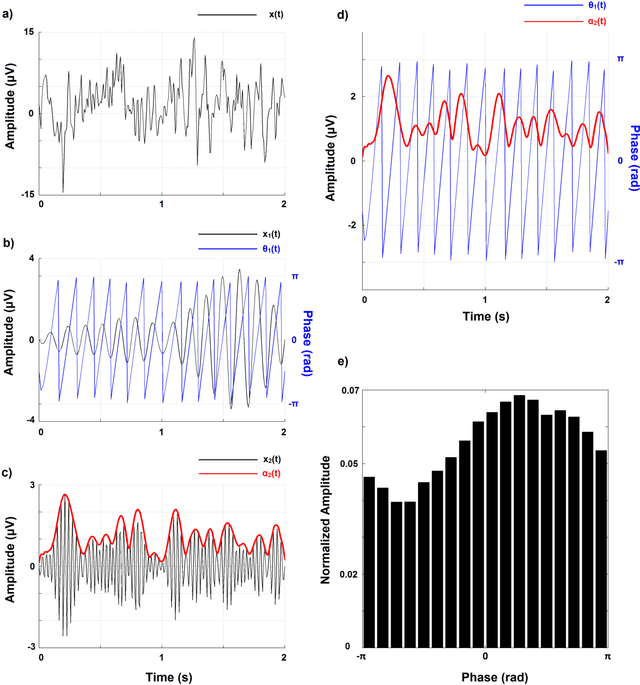
Recent advances in biosensors technology and mobile electroencephalographic (EEG) interfaces have opened new application fields for cognitive monitoring. A computable biomarker for the assessment of spontaneous aesthetic brain responses during music listening is introduced here. It derives from well-established measures of cross-frequency coupling (CFC) and quantifies the music-induced alterations in the dynamic relationships between brain rhythms. During a stage of exploratory analysis, and using the signals from a suitably designed experiment, we established the biomarker, which acts on brain activations recorded over the left prefrontal cortex and focuses on the functional coupling between high-beta and low-gamma oscillations. Based on data from an additional experimental paradigm, we validated the introduced biomarker and showed its relevance for expressing the subjective aesthetic appreciation of a piece of music. Our approach resulted in an affordable tool that can promote human-machine interaction and, by serving as a personalized music annotation strategy, can be potentially integrated into modern flexible music recommendation systems. Keywords: Cross-frequency coupling; Human-computer interaction; Brain-computer interface
DrumGAN VST: A Plugin for Drum Sound Analysis/Synthesis With Autoencoding Generative Adversarial Networks
Jun 29, 2022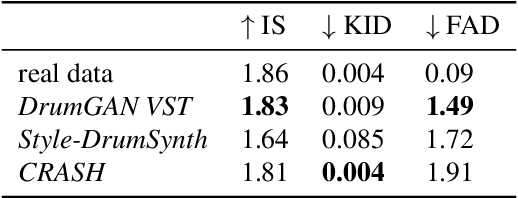
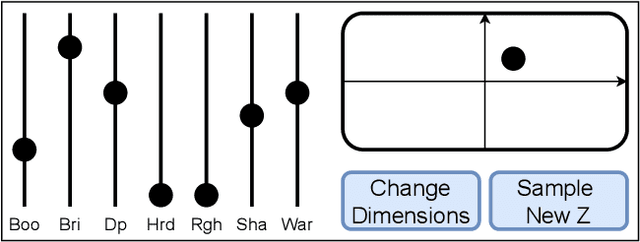
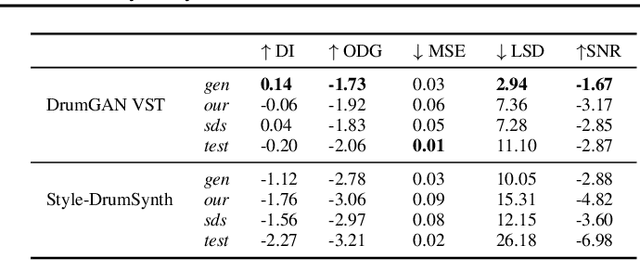
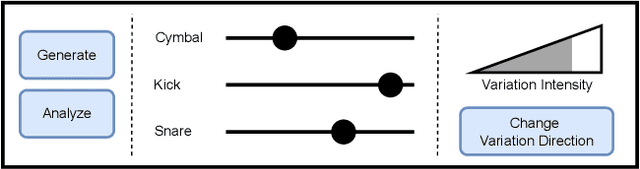
In contemporary popular music production, drum sound design is commonly performed by cumbersome browsing and processing of pre-recorded samples in sound libraries. One can also use specialized synthesis hardware, typically controlled through low-level, musically meaningless parameters. Today, the field of Deep Learning offers methods to control the synthesis process via learned high-level features and allows generating a wide variety of sounds. In this paper, we present DrumGAN VST, a plugin for synthesizing drum sounds using a Generative Adversarial Network. DrumGAN VST operates on 44.1 kHz sample-rate audio, offers independent and continuous instrument class controls, and features an encoding neural network that maps sounds into the GAN's latent space, enabling resynthesis and manipulation of pre-existing drum sounds. We provide numerous sound examples and a demo of the proposed VST plugin.
Musical Score Following and Audio Alignment
May 06, 2022
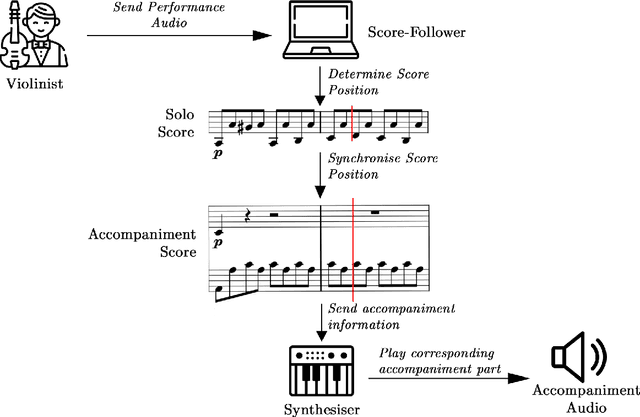
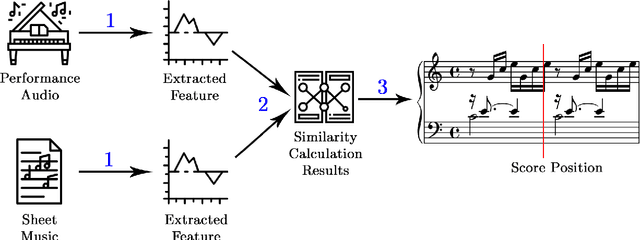
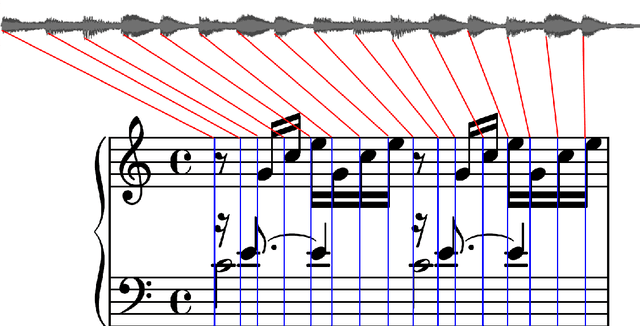
Real-time tracking of the position of a musical performance on a musical score, i.e. score following, can be useful in music practice, performance and production. Example applications of such technology include computer-aided accompaniment and automatic page turning. Score following is a challenging task, especially when considering deviations in performance data from the score stemming from mistakes or expressive choices. In this project, the extensive research present in the field is first explored before two open-source evaluation testbenches for score following--one quantitative and the other qualitative--are introduced. A new way of obtaining quantitative testbench data is proposed, and the QualScofo dataset for qualitative benchmarking is introduced. Subsequently, three different score followers, each of a different class, are implemented. First, a beat-based follower for an interactive conductor application--the TuneApp Conductor--is created to demonstrate an entertaining application of score following. Then, an Approximate String Matching (ASM) non-real-time follower is implemented to complement the quantitative testbench and provide more technical background details of score following. Finally, a Constant Q-Transform (CQT) Dynamic Time Warping (DTW) score follower robust against major challenges in score following (such as polyphonic music and performance deviations) is outlined and implemented; it is shown that this CQT-based approach consistently and significantly outperforms a commonly used FFT-based approach in extracting audio features for score following.
Music transcription modelling and composition using deep learning
Apr 29, 2016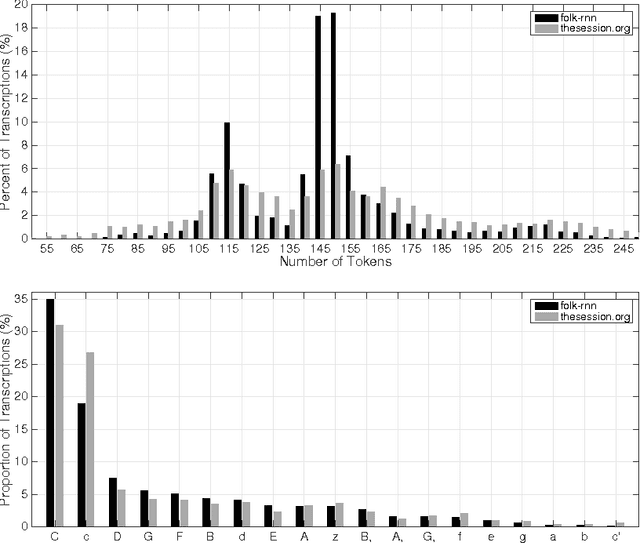



We apply deep learning methods, specifically long short-term memory (LSTM) networks, to music transcription modelling and composition. We build and train LSTM networks using approximately 23,000 music transcriptions expressed with a high-level vocabulary (ABC notation), and use them to generate new transcriptions. Our practical aim is to create music transcription models useful in particular contexts of music composition. We present results from three perspectives: 1) at the population level, comparing descriptive statistics of the set of training transcriptions and generated transcriptions; 2) at the individual level, examining how a generated transcription reflects the conventions of a music practice in the training transcriptions (Celtic folk); 3) at the application level, using the system for idea generation in music composition. We make our datasets, software and sound examples open and available: \url{https://github.com/IraKorshunova/folk-rnn}.
Time-Aware Music Recommender Systems: Modeling the Evolution of Implicit User Preferences and User Listening Habits in A Collaborative Filtering Approach
Aug 26, 2020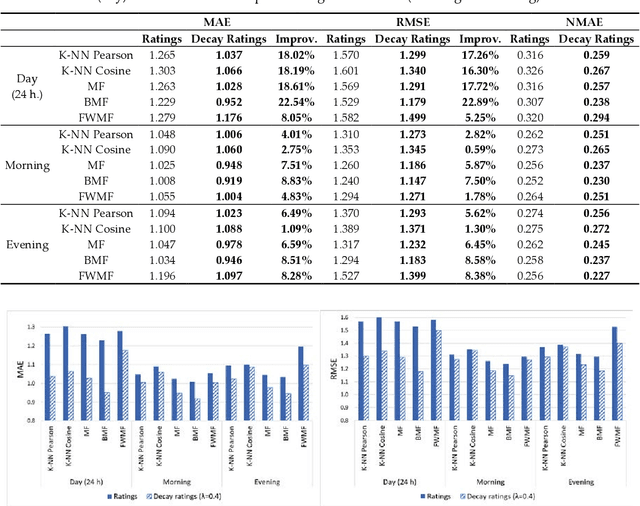
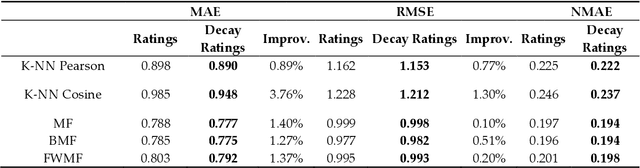
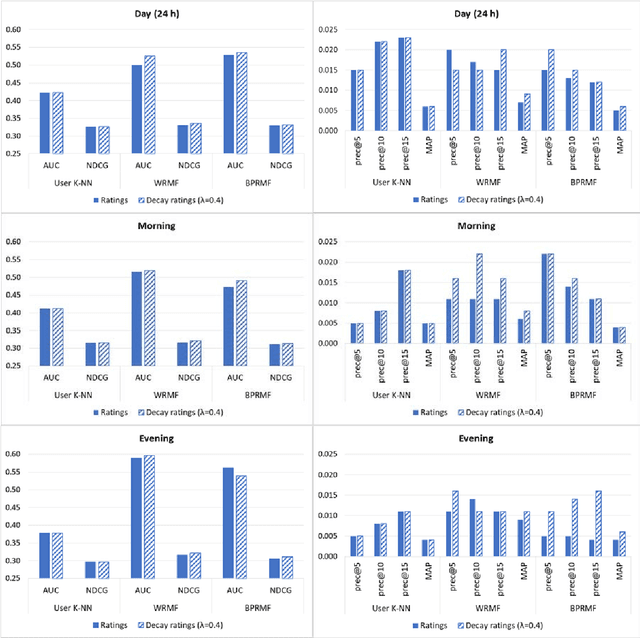
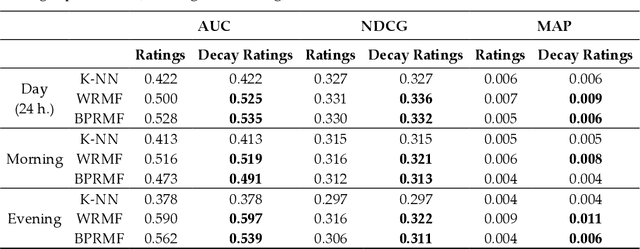
Online streaming services have become the most popular way of listening to music. The majority of these services are endowed with recommendation mechanisms that help users to discover songs and artists that may interest them from the vast amount of music available. However, many are not reliable as they may not take into account contextual aspects or the ever-evolving user behavior. Therefore, it is necessary to develop systems that consider these aspects. In the field of music, time is one of the most important factors influencing user preferences and managing its effects, and is the motivation behind the work presented in this paper. Here, the temporal information regarding when songs are played is examined. The purpose is to model both the evolution of user preferences in the form of evolving implicit ratings and user listening behavior. In the collaborative filtering method proposed in this work, daily listening habits are captured in order to characterize users and provide them with more reliable recommendations. The results of the validation prove that this approach outperforms other methods in generating both context-aware and context-free recommendations