 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Bottom-up Broadcast Neural Network For Music Genre Classification
Jan 24, 2019
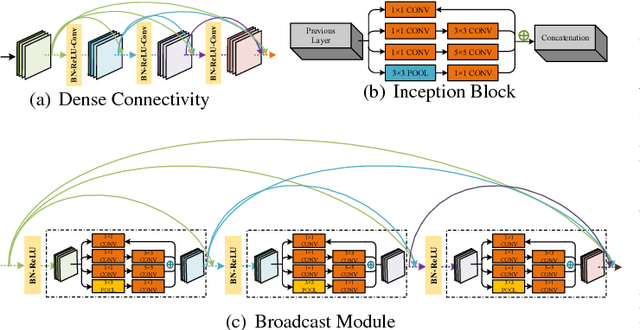

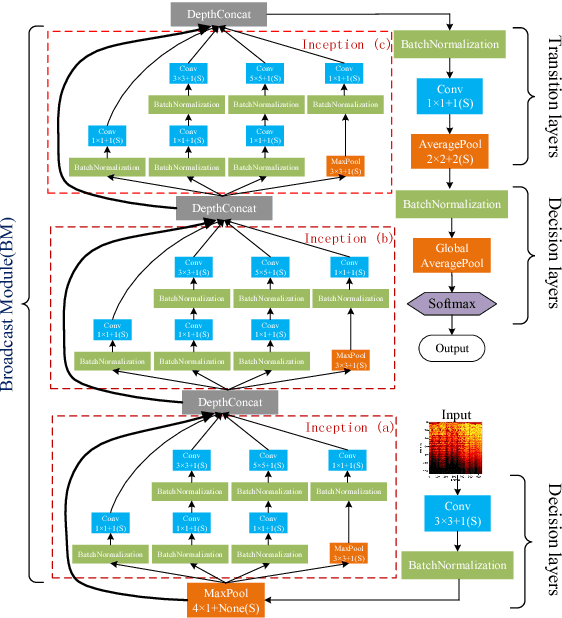
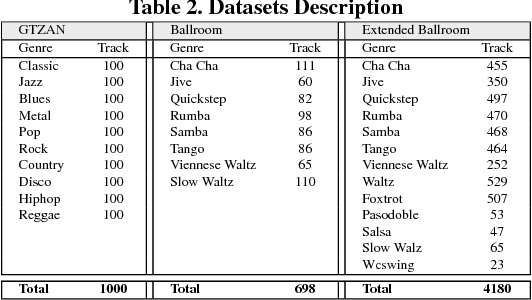
Music genre recognition based on visual representation has been successfully explored over the last years. Recently, there has been increasing interest in attempting convolutional neural networks (CNNs) to achieve the task. However, most of existing methods employ the mature CNN structures proposed in image recognition without any modification, which results in the learning features that are not adequate for music genre classification. Faced with the challenge of this issue, we fully exploit the low-level information from spectrograms of audios and develop a novel CNN architecture in this paper. The proposed CNN architecture takes the long contextual information into considerations, which transfers more suitable information for the decision-making layer. Various experiments on several benchmark datasets, including GTZAN, Ballroom, and Extended Ballroom, have verified the excellent performances of the proposed neural network. Codes and model will be available at "ttps://github.com/CaifengLiu/music-genre-classification".
Bootstrapping deep music separation from primitive auditory grouping principles
Oct 23, 2019
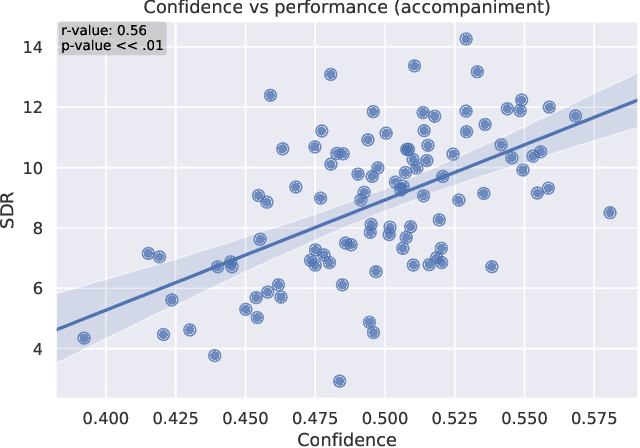
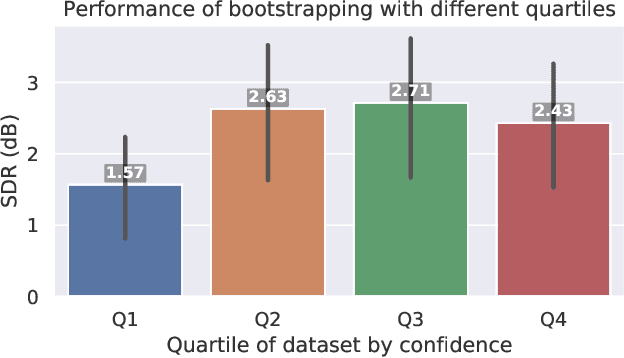
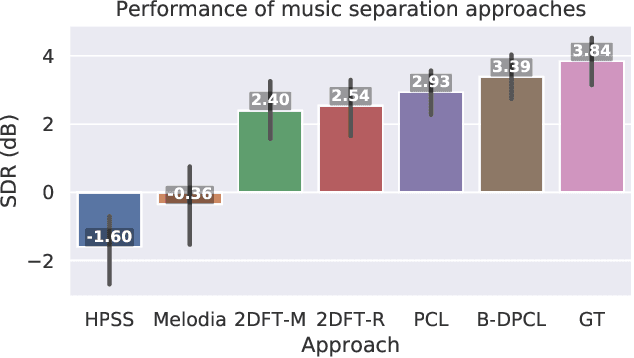
Separating an audio scene such as a cocktail party into constituent, meaningful components is a core task in computer audition. Deep networks are the state-of-the-art approach. They are trained on synthetic mixtures of audio made from isolated sound source recordings so that ground truth for the separation is known. However, the vast majority of available audio is not isolated. The brain uses primitive cues that are independent of the characteristics of any particular sound source to perform an initial segmentation of the audio scene. We present a method for bootstrapping a deep model for music source separation without ground truth by using multiple primitive cues. We apply our method to train a network on a large set of unlabeled music recordings from YouTube to separate vocals from accompaniment without the need for ground truth isolated sources or artificial training mixtures.
Deep Content-User Embedding Model for Music Recommendation
Jul 18, 2018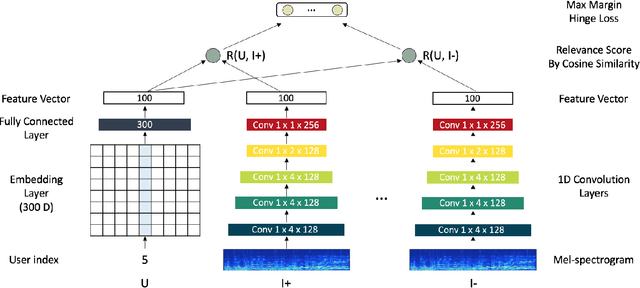


Recently deep learning based recommendation systems have been actively explored to solve the cold-start problem using a hybrid approach. However, the majority of previous studies proposed a hybrid model where collaborative filtering and content-based filtering modules are independently trained. The end-to-end approach that takes different modality data as input and jointly trains the model can provide better optimization but it has not been fully explored yet. In this work, we propose deep content-user embedding model, a simple and intuitive architecture that combines the user-item interaction and music audio content. We evaluate the model on music recommendation and music auto-tagging tasks. The results show that the proposed model significantly outperforms the previous work. We also discuss various directions to improve the proposed model further.
Towards End-to-End Audio-Sheet-Music Retrieval
Dec 15, 2016
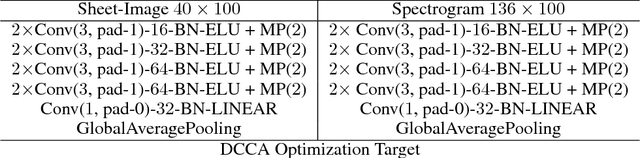
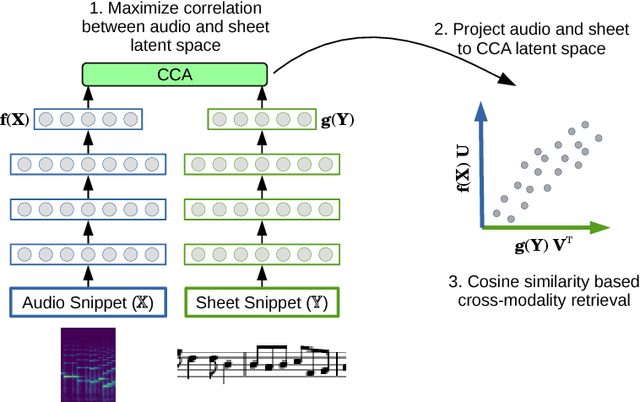
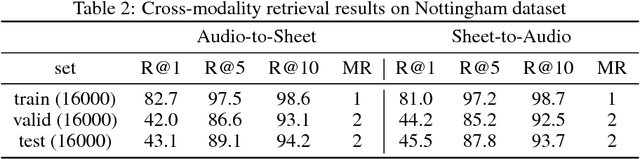
This paper demonstrates the feasibility of learning to retrieve short snippets of sheet music (images) when given a short query excerpt of music (audio) -- and vice versa --, without any symbolic representation of music or scores. This would be highly useful in many content-based musical retrieval scenarios. Our approach is based on Deep Canonical Correlation Analysis (DCCA) and learns correlated latent spaces allowing for cross-modality retrieval in both directions. Initial experiments with relatively simple monophonic music show promising results.
Conformity bias in the cultural transmission of music sampling traditions
Jun 27, 2019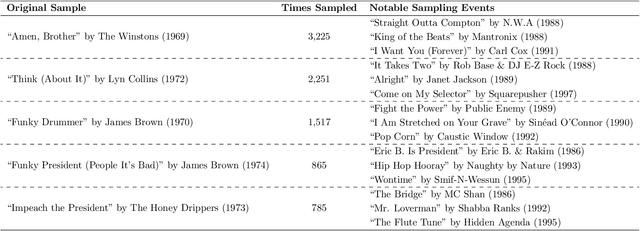
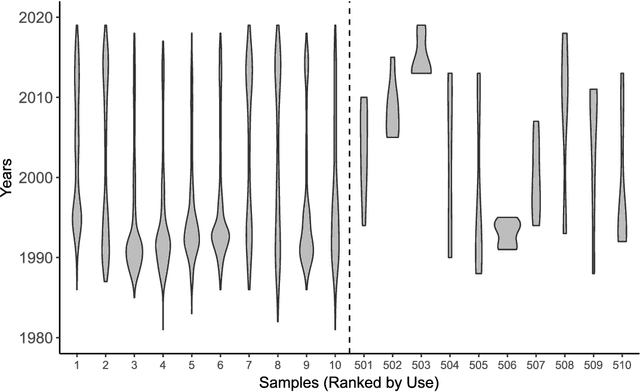
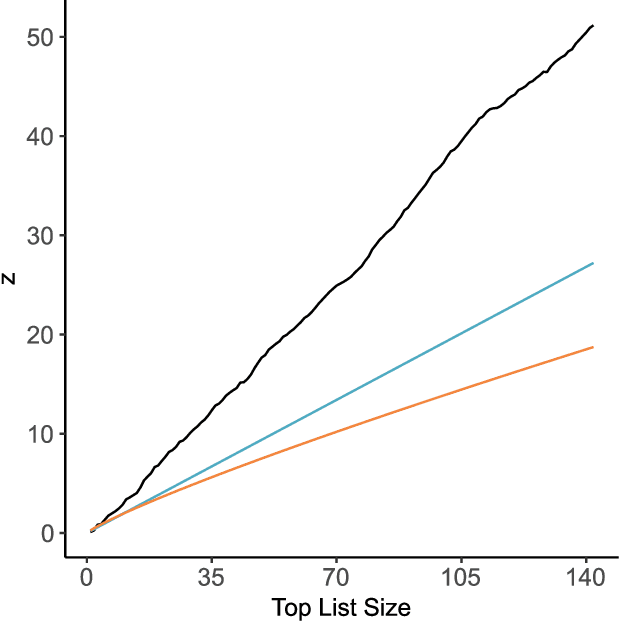

One of the fundamental questions of cultural evolutionary research is how individual-level processes scale up to generate population-level patterns. Previous studies in music have revealed that frequency-based bias (e.g. conformity and novelty) drives large-scale cultural diversity in different ways across domains and levels of analysis. Music sampling is an ideal research model for this process because samples are known to be culturally transmitted between collaborating artists, and sampling events are reliably documented in online databases. The aim of the current study was to determine whether frequency-based bias has played a role in the cultural transmission of music sampling traditions, using a longitudinal dataset of sampling events across three decades. Firstly, we assessed whether turn-over rates of popular samples differ from those expected under neutral evolution. Next, we used agent-based simulations in an approximate Bayesian computation framework to infer what level of frequency-based bias likely generated the observed data. Despite anecdotal evidence of novelty bias, we found that sampling patterns at the population-level are most consistent with conformity bias.
Exploiting Synchronized Lyrics And Vocal Features For Music Emotion Detection
Jan 15, 2019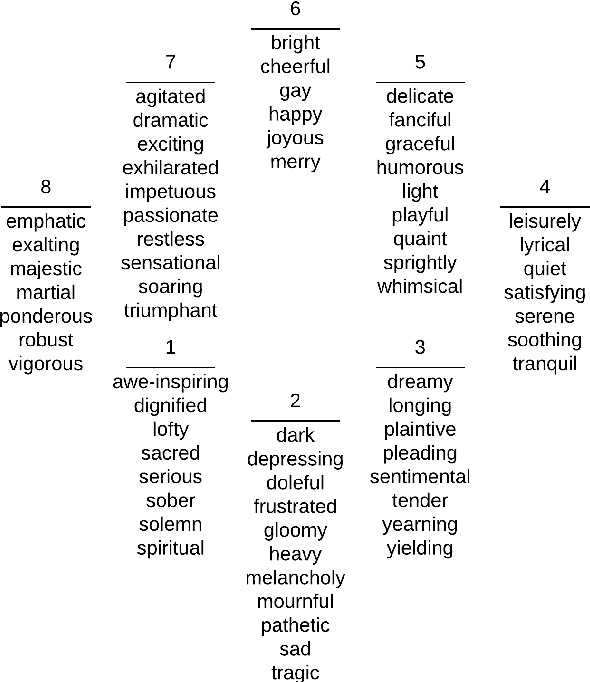

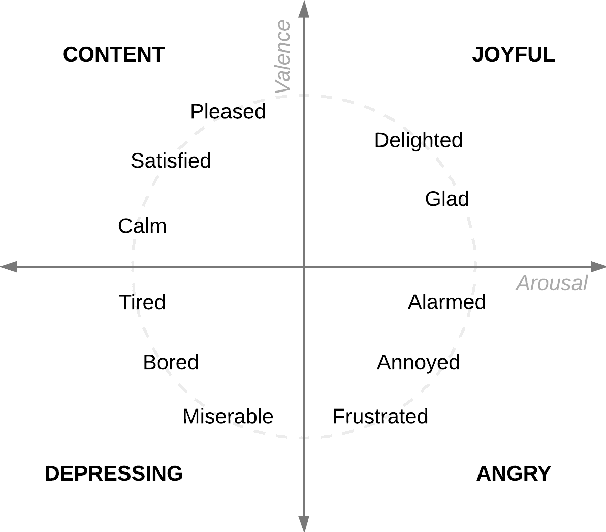
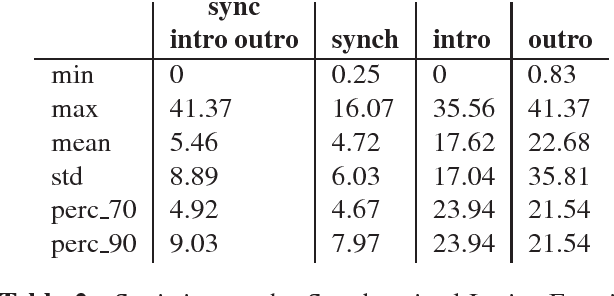
One of the key points in music recommendation is authoring engaging playlists according to sentiment and emotions. While previous works were mostly based on audio for music discovery and playlists generation, we take advantage of our synchronized lyrics dataset to combine text representations and music features in a novel way; we therefore introduce the Synchronized Lyrics Emotion Dataset. Unlike other approaches that randomly exploited the audio samples and the whole text, our data is split according to the temporal information provided by the synchronization between lyrics and audio. This work shows a comparison between text-based and audio-based deep learning classification models using different techniques from Natural Language Processing and Music Information Retrieval domains. From the experiments on audio we conclude that using vocals only, instead of the whole audio data improves the overall performances of the audio classifier. In the lyrics experiments we exploit the state-of-the-art word representations applied to the main Deep Learning architectures available in literature. In our benchmarks the results show how the Bilinear LSTM classifier with Attention based on fastText word embedding performs better than the CNN applied on audio.
The emotions that we perceive in music: the influence of language and lyrics comprehension on agreement
Sep 12, 2019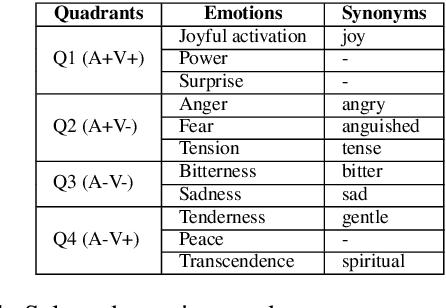
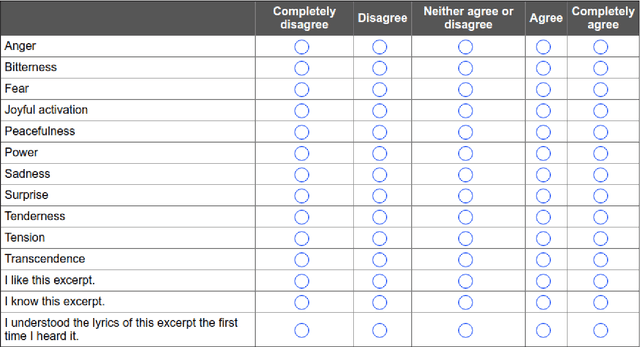
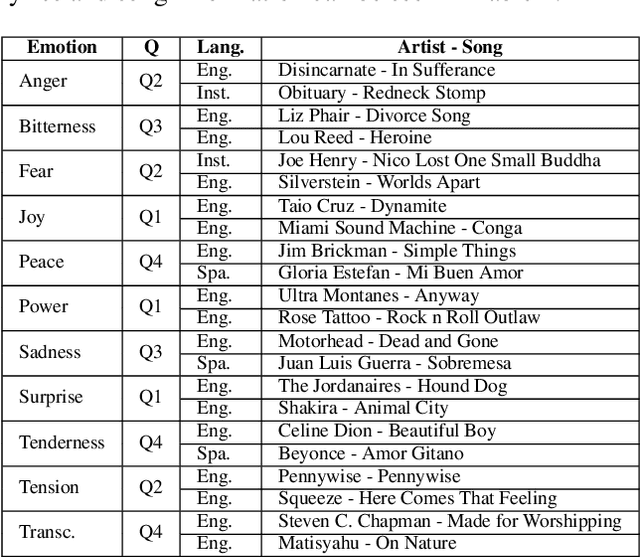

In the present study, we address the relationship between the emotions perceived in pop and rock music (mainly in Euro-American styles with English lyrics) and the language spoken by the listener. Our goal is to understand the influence of lyrics comprehension on the perception of emotions and use this information to improve Music Emotion Recognition (MER) models. Two main research questions are addressed: 1. Are there differences and similarities between the emotions perceived in pop/rock music by listeners raised with different mother tongues? 2. Do personal characteristics have an influence on the perceived emotions for listeners of a given language? Personal characteristics include the listeners' general demographics, familiarity and preference for the fragments, and music sophistication. Our hypothesis is that inter-rater agreement (as defined by Krippendorff's alpha coefficient) from subjects is directly influenced by the comprehension of lyrics.
Self-Supervised VQ-VAE For One-Shot Music Style Transfer
Feb 10, 2021
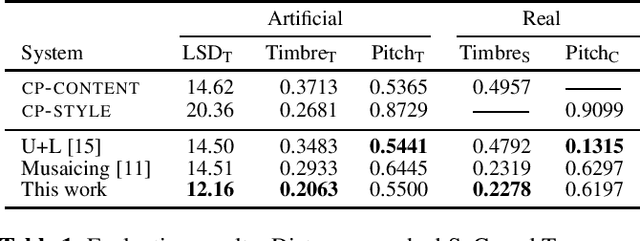
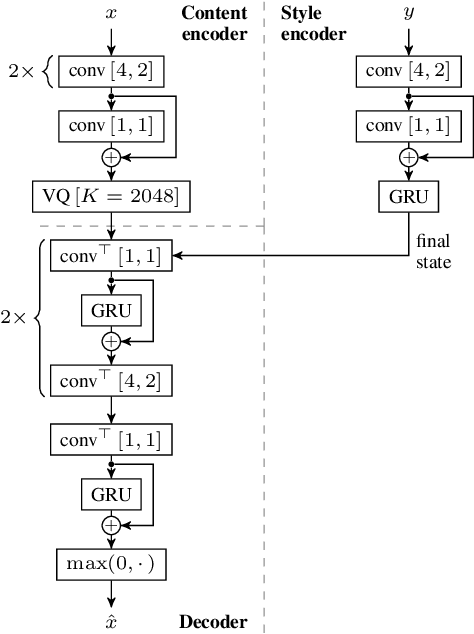
Neural style transfer, allowing to apply the artistic style of one image to another, has become one of the most widely showcased computer vision applications shortly after its introduction. In contrast, related tasks in the music audio domain remained, until recently, largely untackled. While several style conversion methods tailored to musical signals have been proposed, most lack the 'one-shot' capability of classical image style transfer algorithms. On the other hand, the results of existing one-shot audio style transfer methods on musical inputs are not as compelling. In this work, we are specifically interested in the problem of one-shot timbre transfer. We present a novel method for this task, based on an extension of the vector-quantized variational autoencoder (VQ-VAE), along with a simple self-supervised learning strategy designed to obtain disentangled representations of timbre and pitch. We evaluate the method using a set of objective metrics and show that it is able to outperform selected baselines.
Spectrogram Feature Losses for Music Source Separation
Jan 18, 2019



In this paper we study deep learning-based music source separation, and explore using an alternative loss to the standard spectrogram pixel-level L2 loss for model training. Our main contribution is in demonstrating that adding a high-level feature loss term, extracted from the spectrograms using a VGG net, can improve separation quality vis-a-vis a pure pixel-level loss. We show this improvement in the context of the MMDenseNet, a State-of-the-Art deep learning model for this task, for the extraction of drums and vocal sounds from songs in the musdb18 database, covering a broad range of western music genres. We believe that this finding can be generalized and applied to broader machine learning-based systems in the audio domain.
A Quantum Natural Language Processing Approach to Musical Intelligence
Nov 10, 2021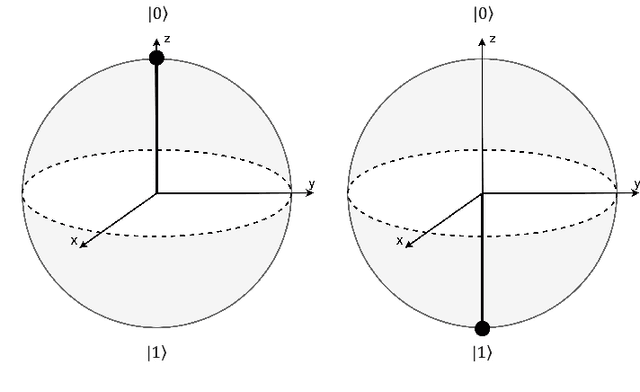
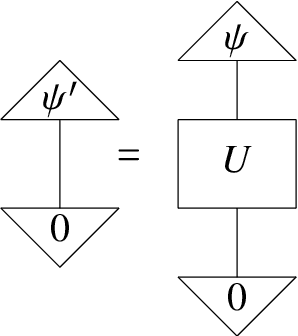
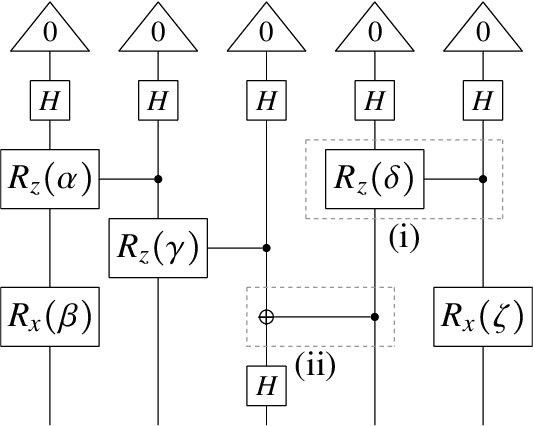
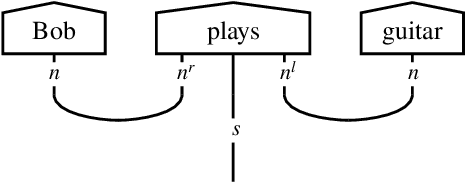
There has been tremendous progress in Artificial Intelligence (AI) for music, in particular for musical composition and access to large databases for commercialisation through the Internet. We are interested in further advancing this field, focusing on composition. In contrast to current black-box AI methods, we are championing an interpretable compositional outlook on generative music systems. In particular, we are importing methods from the Distributional Compositional Categorical (DisCoCat) modelling framework for Natural Language Processing (NLP), motivated by musical grammars. Quantum computing is a nascent technology, which is very likely to impact the music industry in time to come. Thus, we are pioneering a Quantum Natural Language Processing (QNLP) approach to develop a new generation of intelligent musical systems. This work follows from previous experimental implementations of DisCoCat linguistic models on quantum hardware. In this chapter, we present Quanthoven, the first proof-of-concept ever built, which (a) demonstrates that it is possible to program a quantum computer to learn to classify music that conveys different meanings and (b) illustrates how such a capability might be leveraged to develop a system to compose meaningful pieces of music. After a discussion about our current understanding of music as a communication medium and its relationship to natural language, the chapter focuses on the techniques developed to (a) encode musical compositions as quantum circuits, and (b) design a quantum classifier. The chapter ends with demonstrations of compositions created with the system.