 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Self-Supervised VQ-VAE For One-Shot Music Style Transfer
Feb 10, 2021
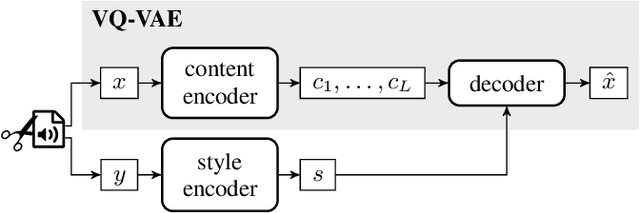
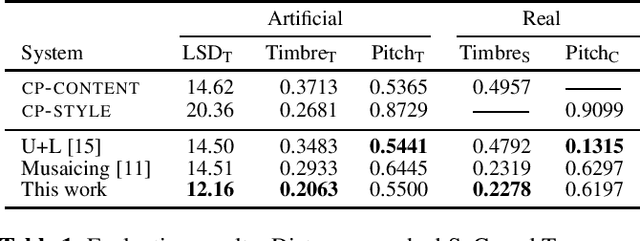
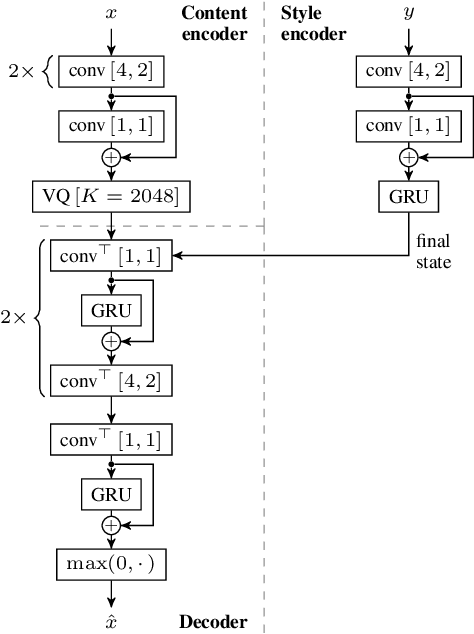
Neural style transfer, allowing to apply the artistic style of one image to another, has become one of the most widely showcased computer vision applications shortly after its introduction. In contrast, related tasks in the music audio domain remained, until recently, largely untackled. While several style conversion methods tailored to musical signals have been proposed, most lack the 'one-shot' capability of classical image style transfer algorithms. On the other hand, the results of existing one-shot audio style transfer methods on musical inputs are not as compelling. In this work, we are specifically interested in the problem of one-shot timbre transfer. We present a novel method for this task, based on an extension of the vector-quantized variational autoencoder (VQ-VAE), along with a simple self-supervised learning strategy designed to obtain disentangled representations of timbre and pitch. We evaluate the method using a set of objective metrics and show that it is able to outperform selected baselines.
Conformity bias in the cultural transmission of music sampling traditions
Jun 27, 2019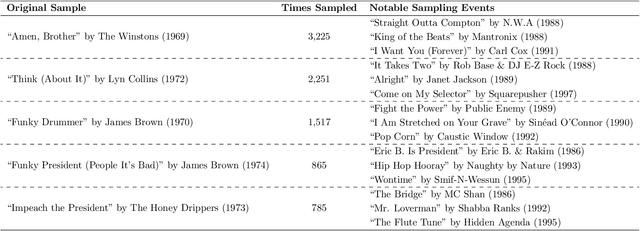
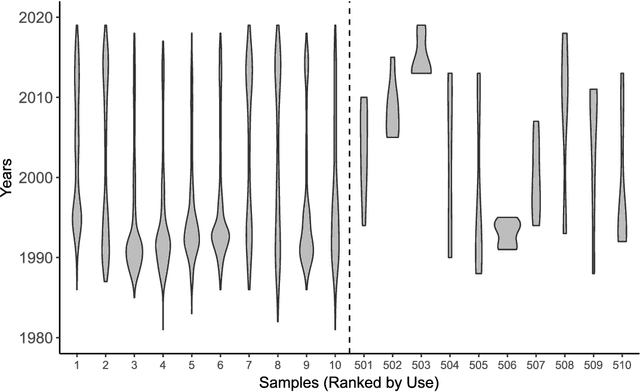
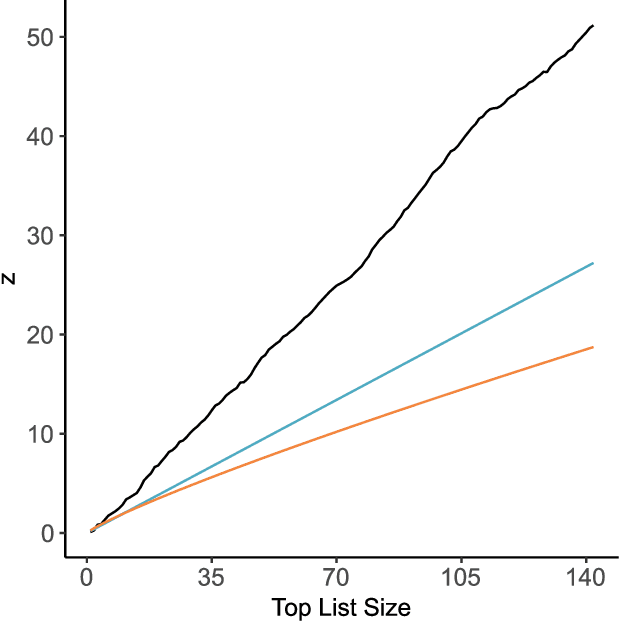

One of the fundamental questions of cultural evolutionary research is how individual-level processes scale up to generate population-level patterns. Previous studies in music have revealed that frequency-based bias (e.g. conformity and novelty) drives large-scale cultural diversity in different ways across domains and levels of analysis. Music sampling is an ideal research model for this process because samples are known to be culturally transmitted between collaborating artists, and sampling events are reliably documented in online databases. The aim of the current study was to determine whether frequency-based bias has played a role in the cultural transmission of music sampling traditions, using a longitudinal dataset of sampling events across three decades. Firstly, we assessed whether turn-over rates of popular samples differ from those expected under neutral evolution. Next, we used agent-based simulations in an approximate Bayesian computation framework to infer what level of frequency-based bias likely generated the observed data. Despite anecdotal evidence of novelty bias, we found that sampling patterns at the population-level are most consistent with conformity bias.
The emotions that we perceive in music: the influence of language and lyrics comprehension on agreement
Sep 12, 2019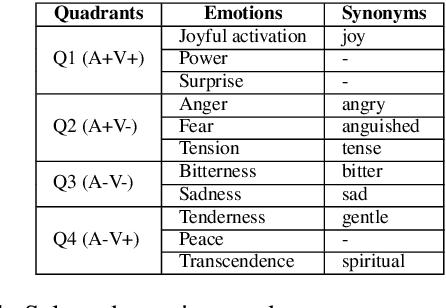
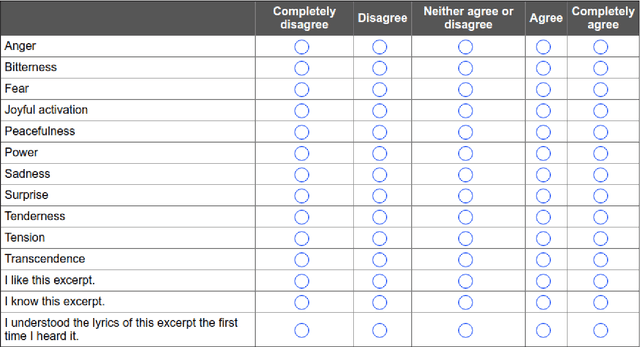
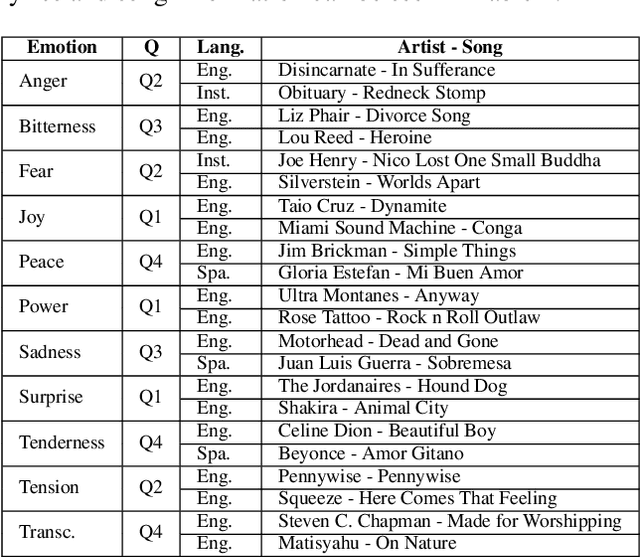

In the present study, we address the relationship between the emotions perceived in pop and rock music (mainly in Euro-American styles with English lyrics) and the language spoken by the listener. Our goal is to understand the influence of lyrics comprehension on the perception of emotions and use this information to improve Music Emotion Recognition (MER) models. Two main research questions are addressed: 1. Are there differences and similarities between the emotions perceived in pop/rock music by listeners raised with different mother tongues? 2. Do personal characteristics have an influence on the perceived emotions for listeners of a given language? Personal characteristics include the listeners' general demographics, familiarity and preference for the fragments, and music sophistication. Our hypothesis is that inter-rater agreement (as defined by Krippendorff's alpha coefficient) from subjects is directly influenced by the comprehension of lyrics.
Exploiting Synchronized Lyrics And Vocal Features For Music Emotion Detection
Jan 15, 2019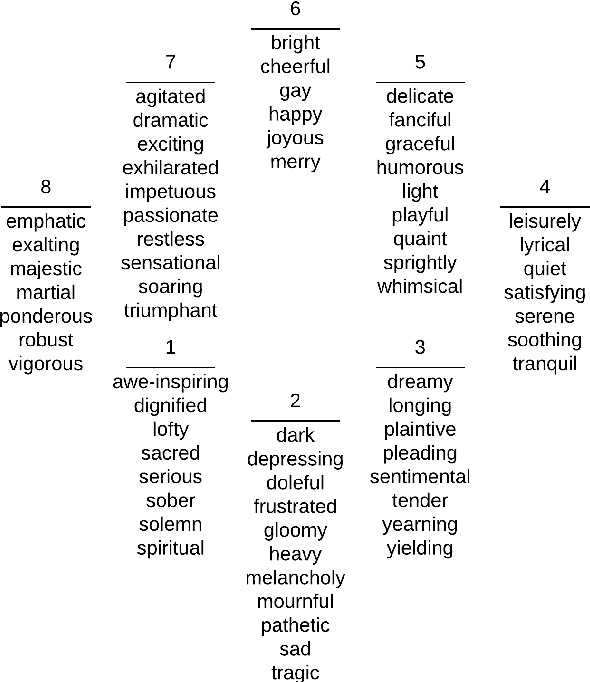

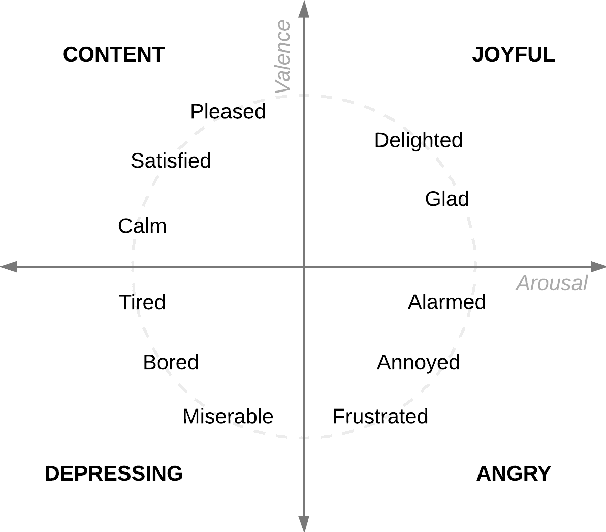
One of the key points in music recommendation is authoring engaging playlists according to sentiment and emotions. While previous works were mostly based on audio for music discovery and playlists generation, we take advantage of our synchronized lyrics dataset to combine text representations and music features in a novel way; we therefore introduce the Synchronized Lyrics Emotion Dataset. Unlike other approaches that randomly exploited the audio samples and the whole text, our data is split according to the temporal information provided by the synchronization between lyrics and audio. This work shows a comparison between text-based and audio-based deep learning classification models using different techniques from Natural Language Processing and Music Information Retrieval domains. From the experiments on audio we conclude that using vocals only, instead of the whole audio data improves the overall performances of the audio classifier. In the lyrics experiments we exploit the state-of-the-art word representations applied to the main Deep Learning architectures available in literature. In our benchmarks the results show how the Bilinear LSTM classifier with Attention based on fastText word embedding performs better than the CNN applied on audio.
A Quantum Natural Language Processing Approach to Musical Intelligence
Nov 10, 2021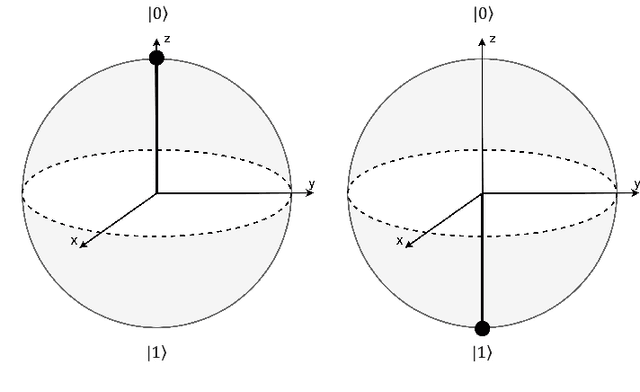
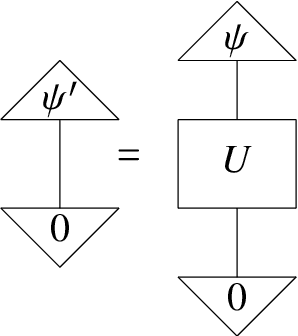
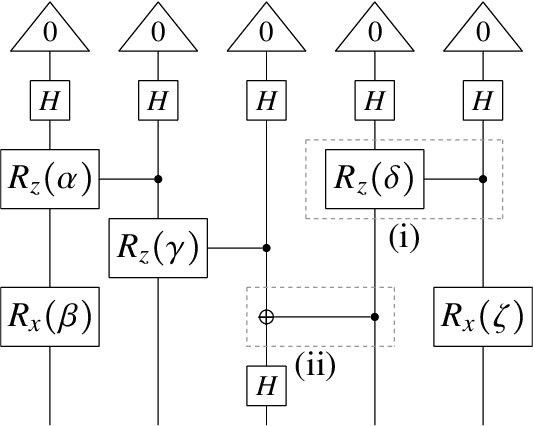
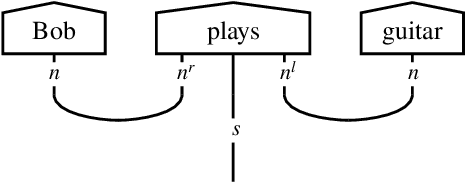
There has been tremendous progress in Artificial Intelligence (AI) for music, in particular for musical composition and access to large databases for commercialisation through the Internet. We are interested in further advancing this field, focusing on composition. In contrast to current black-box AI methods, we are championing an interpretable compositional outlook on generative music systems. In particular, we are importing methods from the Distributional Compositional Categorical (DisCoCat) modelling framework for Natural Language Processing (NLP), motivated by musical grammars. Quantum computing is a nascent technology, which is very likely to impact the music industry in time to come. Thus, we are pioneering a Quantum Natural Language Processing (QNLP) approach to develop a new generation of intelligent musical systems. This work follows from previous experimental implementations of DisCoCat linguistic models on quantum hardware. In this chapter, we present Quanthoven, the first proof-of-concept ever built, which (a) demonstrates that it is possible to program a quantum computer to learn to classify music that conveys different meanings and (b) illustrates how such a capability might be leveraged to develop a system to compose meaningful pieces of music. After a discussion about our current understanding of music as a communication medium and its relationship to natural language, the chapter focuses on the techniques developed to (a) encode musical compositions as quantum circuits, and (b) design a quantum classifier. The chapter ends with demonstrations of compositions created with the system.
Towards End-to-End Audio-Sheet-Music Retrieval
Dec 15, 2016
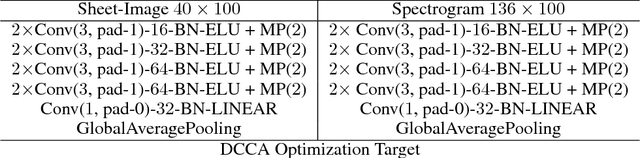
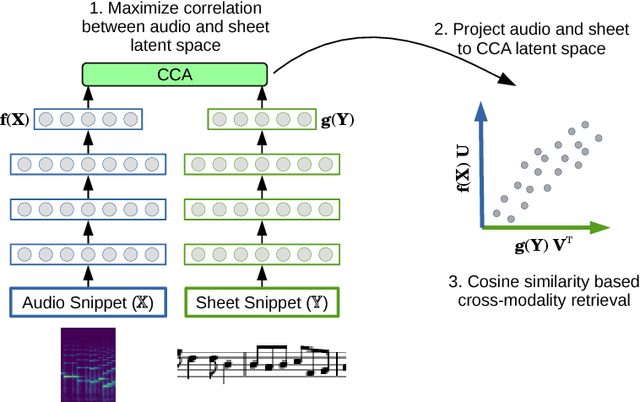
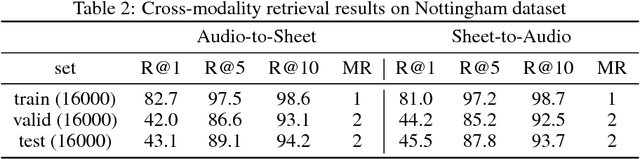
This paper demonstrates the feasibility of learning to retrieve short snippets of sheet music (images) when given a short query excerpt of music (audio) -- and vice versa --, without any symbolic representation of music or scores. This would be highly useful in many content-based musical retrieval scenarios. Our approach is based on Deep Canonical Correlation Analysis (DCCA) and learns correlated latent spaces allowing for cross-modality retrieval in both directions. Initial experiments with relatively simple monophonic music show promising results.
Rapid Phase Ambiguity Elimination Methods for DOA Estimator via Hybrid Massive MIMO Receive Array
Apr 27, 2022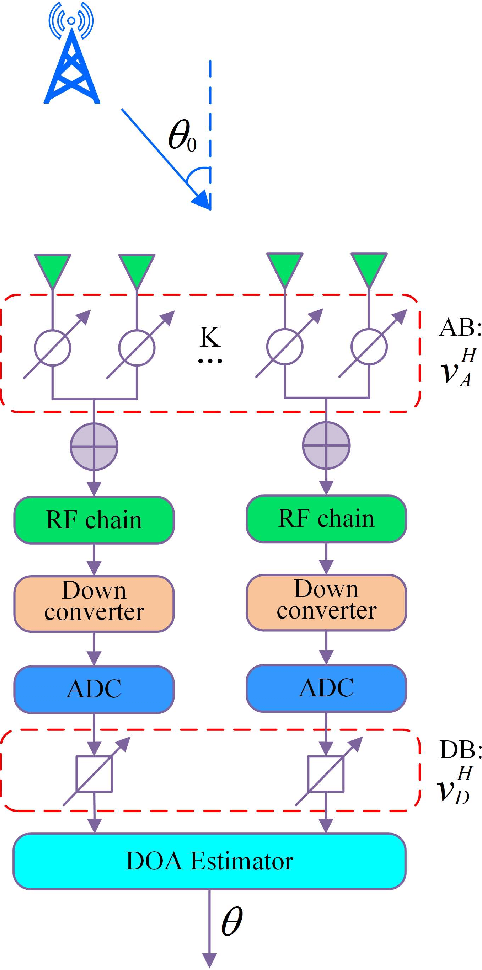
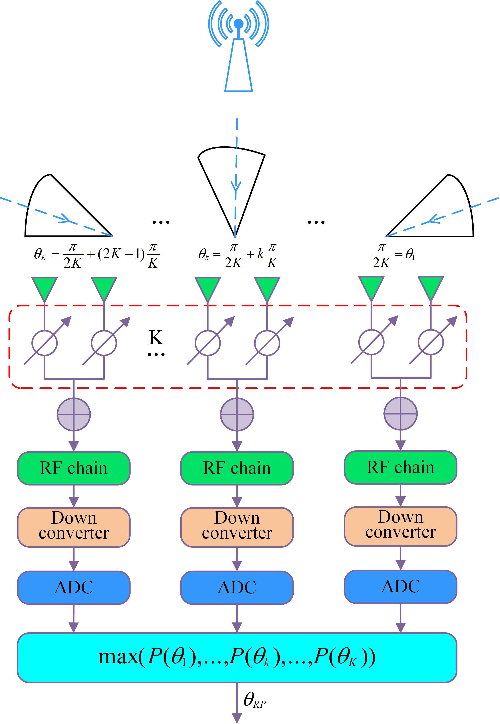
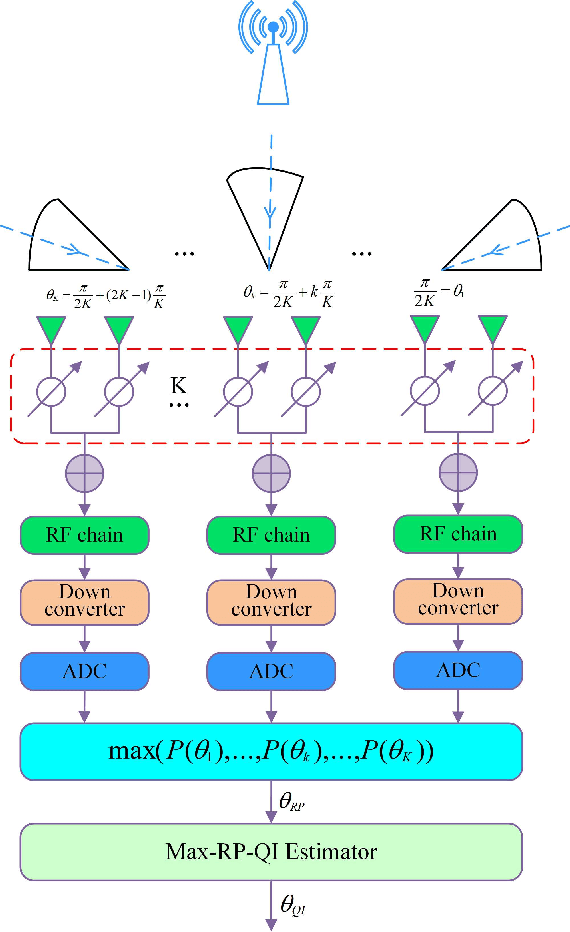
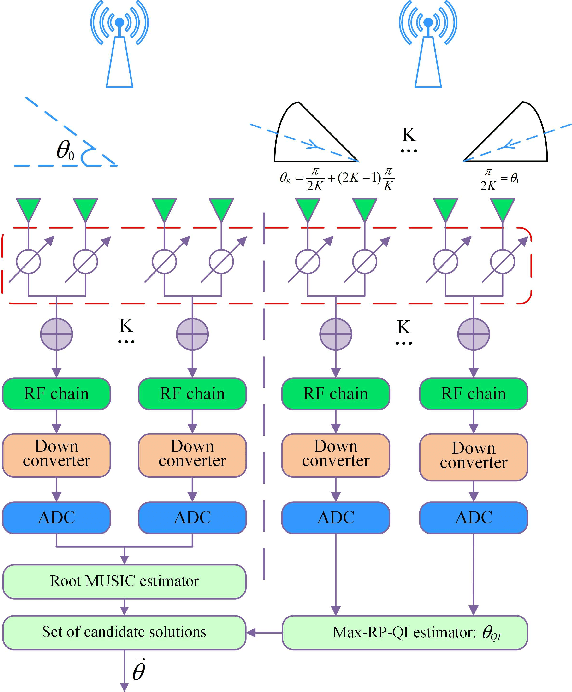
For a sub-connected hybrid multiple-input multiple-output (MIMO) receiver with $K$ subarrays and $N$ antennas, there exists a challenging problem of how to rapidly remove phase ambiguity in only single time-slot. First, a DOA estimator of maximizing received power (Max-RP) is proposed to find the maximum value of $K$-subarray output powers, where each subarray is in charge of one sector, and the center angle of the sector corresponding to the maximum output is the estimated true DOA. To make an enhancement on precision, Max-RP plus quadratic interpolation (Max-RP-QI) method is designed. In the proposed Max-RP-QI, a quadratic interpolation scheme is adopted to interpolate the three DOA values corresponding to the largest three receive powers of Max-RP. Finally, to achieve the CRLB, a Root-MUSIC plus Max-RP-QI scheme is developed. Simulation results show that the proposed three methods eliminate the phase ambiguity during one time-slot and also show low-computational-complexities. In particular, the proposed Root-MUSIC plus Max-RP-QI scheme can reach the CRLB, and the proposed Max-RP and Max-RP-QI are still some performance losses $2dB\thicksim4dB$ compared to the CRLB.
Spectrogram Feature Losses for Music Source Separation
Jan 18, 2019



In this paper we study deep learning-based music source separation, and explore using an alternative loss to the standard spectrogram pixel-level L2 loss for model training. Our main contribution is in demonstrating that adding a high-level feature loss term, extracted from the spectrograms using a VGG net, can improve separation quality vis-a-vis a pure pixel-level loss. We show this improvement in the context of the MMDenseNet, a State-of-the-Art deep learning model for this task, for the extraction of drums and vocal sounds from songs in the musdb18 database, covering a broad range of western music genres. We believe that this finding can be generalized and applied to broader machine learning-based systems in the audio domain.
Generating Nontrivial Melodies for Music as a Service
Oct 06, 2017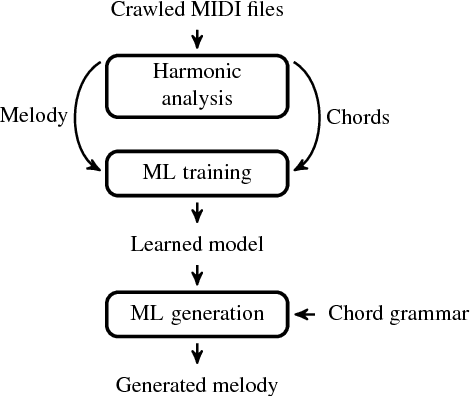
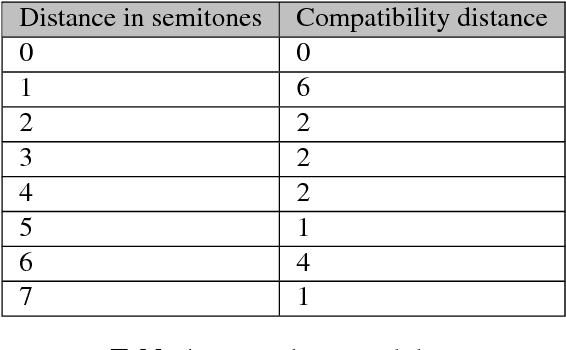

We present a hybrid neural network and rule-based system that generates pop music. Music produced by pure rule-based systems often sounds mechanical. Music produced by machine learning sounds better, but still lacks hierarchical temporal structure. We restore temporal hierarchy by augmenting machine learning with a temporal production grammar, which generates the music's overall structure and chord progressions. A compatible melody is then generated by a conditional variational recurrent autoencoder. The autoencoder is trained with eight-measure segments from a corpus of 10,000 MIDI files, each of which has had its melody track and chord progressions identified heuristically. The autoencoder maps melody into a multi-dimensional feature space, conditioned by the underlying chord progression. A melody is then generated by feeding a random sample from that space to the autoencoder's decoder, along with the chord progression generated by the grammar. The autoencoder can make musically plausible variations on an existing melody, suitable for recurring motifs. It can also reharmonize a melody to a new chord progression, keeping the rhythm and contour. The generated music compares favorably with that generated by other academic and commercial software designed for the music-as-a-service industry.
Score Transformer: Generating Musical Score from Note-level Representation
Dec 01, 2021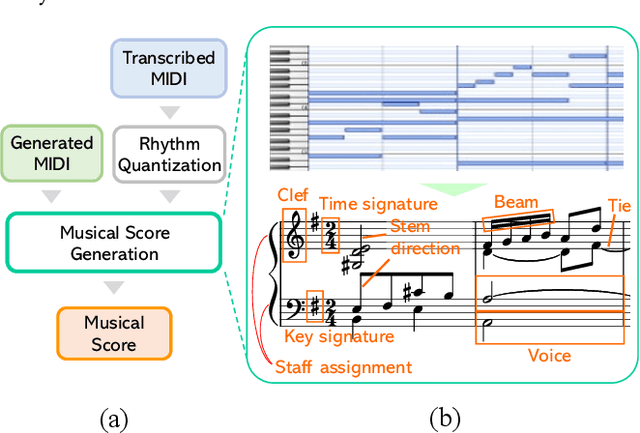
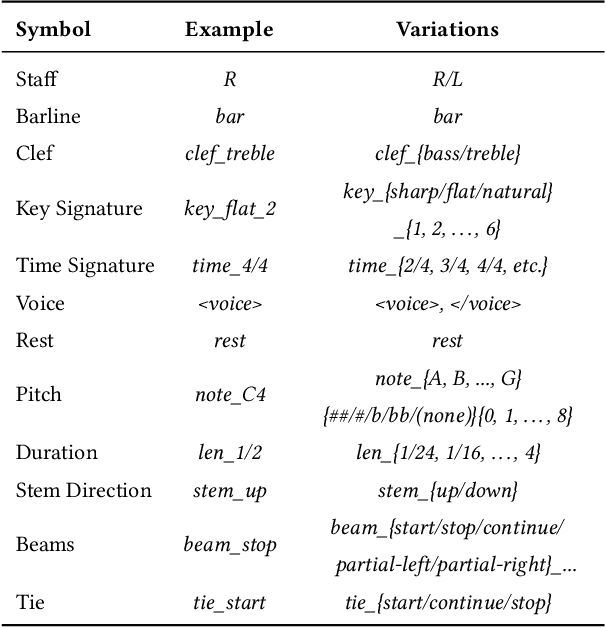

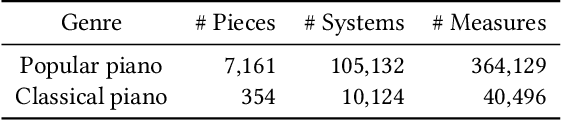
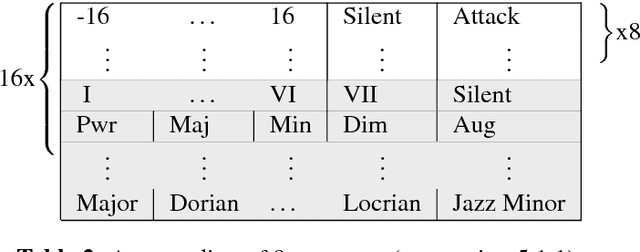
In this paper, we explore the tokenized representation of musical scores using the Transformer model to automatically generate musical scores. Thus far, sequence models have yielded fruitful results with note-level (MIDI-equivalent) symbolic representations of music. Although the note-level representations can comprise sufficient information to reproduce music aurally, they cannot contain adequate information to represent music visually in terms of notation. Musical scores contain various musical symbols (e.g., clef, key signature, and notes) and attributes (e.g., stem direction, beam, and tie) that enable us to visually comprehend musical content. However, automated estimation of these elements has yet to be comprehensively addressed. In this paper, we first design score token representation corresponding to the various musical elements. We then train the Transformer model to transcribe note-level representation into appropriate music notation. Evaluations of popular piano scores show that the proposed method significantly outperforms existing methods on all 12 musical aspects that were investigated. We also explore an effective notation-level token representation to work with the model and determine that our proposed representation produces the steadiest results.