 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
The challenge of realistic music generation: modelling raw audio at scale
Jun 26, 2018
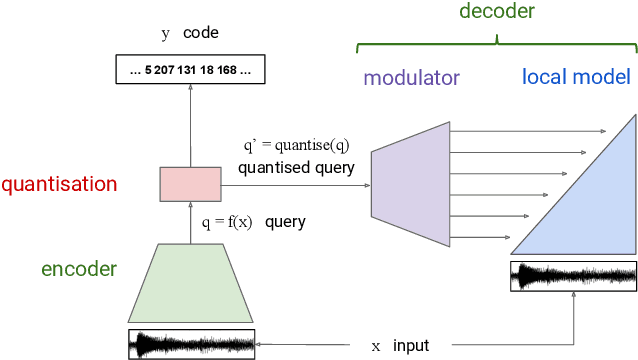
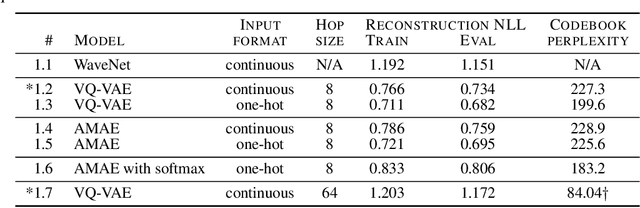
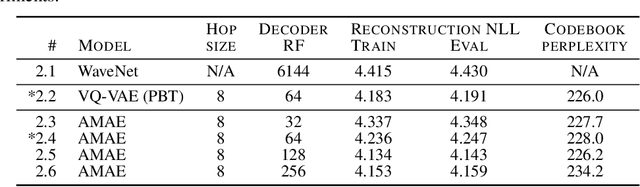
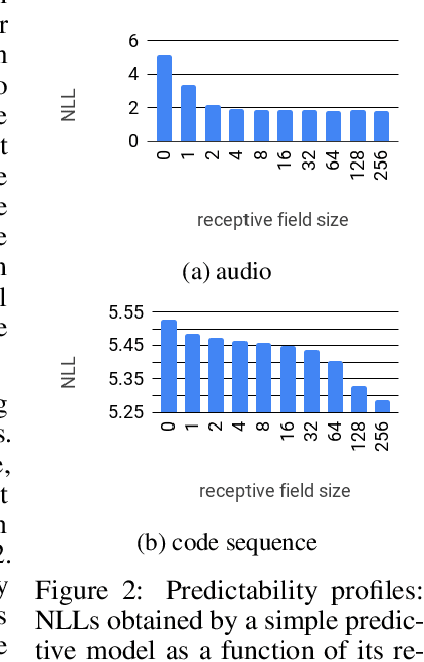
Realistic music generation is a challenging task. When building generative models of music that are learnt from data, typically high-level representations such as scores or MIDI are used that abstract away the idiosyncrasies of a particular performance. But these nuances are very important for our perception of musicality and realism, so in this work we embark on modelling music in the raw audio domain. It has been shown that autoregressive models excel at generating raw audio waveforms of speech, but when applied to music, we find them biased towards capturing local signal structure at the expense of modelling long-range correlations. This is problematic because music exhibits structure at many different timescales. In this work, we explore autoregressive discrete autoencoders (ADAs) as a means to enable autoregressive models to capture long-range correlations in waveforms. We find that they allow us to unconditionally generate piano music directly in the raw audio domain, which shows stylistic consistency across tens of seconds.
Learning Transposition-Invariant Interval Features from Symbolic Music and Audio
Jun 21, 2018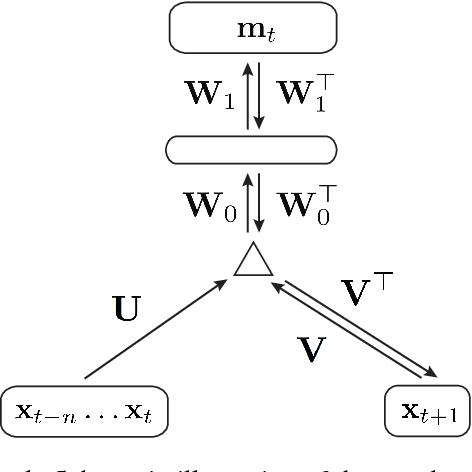
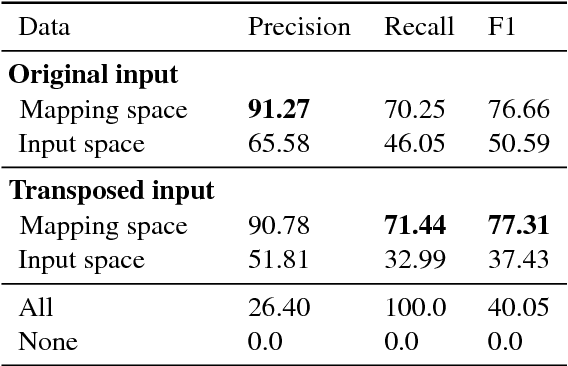

Many music theoretical constructs (such as scale types, modes, cadences, and chord types) are defined in terms of pitch intervals---relative distances between pitches. Therefore, when computer models are employed in music tasks, it can be useful to operate on interval representations rather than on the raw musical surface. Moreover, interval representations are transposition-invariant, valuable for tasks like audio alignment, cover song detection and music structure analysis. We employ a gated autoencoder to learn fixed-length, invertible and transposition-invariant interval representations from polyphonic music in the symbolic domain and in audio. An unsupervised training method is proposed yielding an organization of intervals in the representation space which is musically plausible. Based on the representations, a transposition-invariant self-similarity matrix is constructed and used to determine repeated sections in symbolic music and in audio, yielding competitive results in the MIREX task "Discovery of Repeated Themes and Sections".
An Annihilating Filter-Based DOA Estimation for Uniform Linear Array
Oct 12, 2021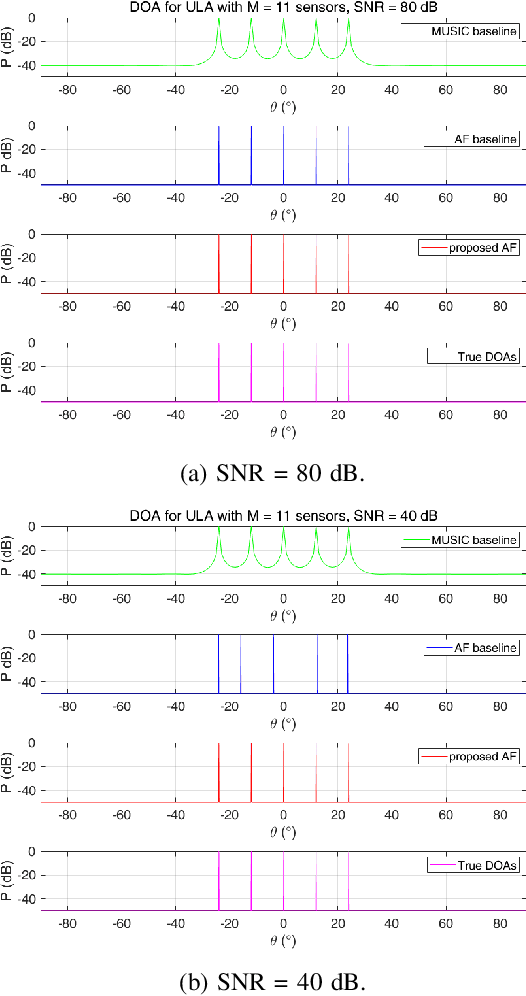
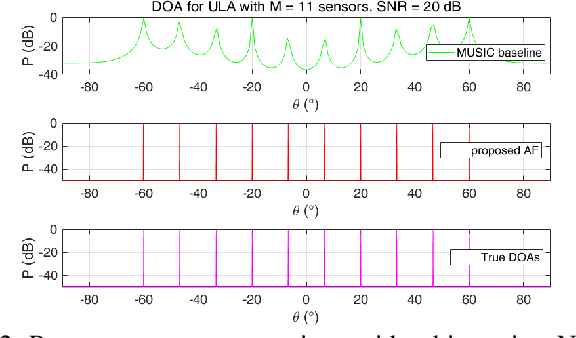
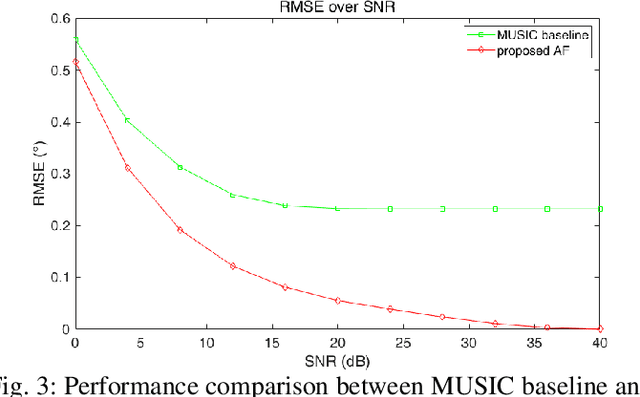
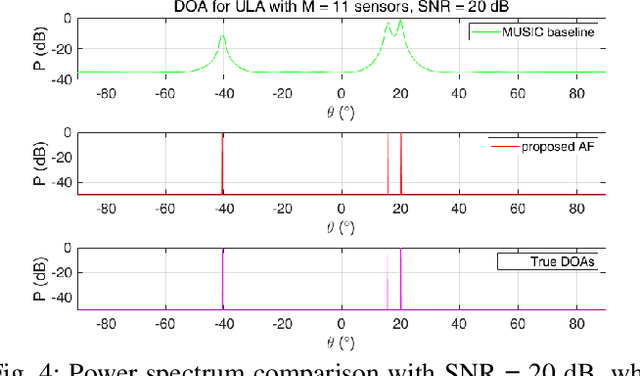
In this paper, we propose a new method to design an annihilating filter (AF) for direction-of-arrival (DOA) estimation of multiple snapshots within an uniform linear array. To evaluate the proposed method, we firstly design a DOA estimation using multiple signal classification (MUSIC) algorithm, referred to as the MUSIC baseline. We then compare the proposed method with the MUSIC baseline in two environmental noise conditions: Only white noise, or both white noise and diffusion. The experimental results highlight two main contributions; the first is to modify conventional MUSIC algorithm for adapting different noise conditions, and the second is to propose an AF-based method that shows competitive accuracy of arrival angles detected and low complexity compared with the MUSIC baseline.
A Functional Taxonomy of Music Generation Systems
Dec 11, 2018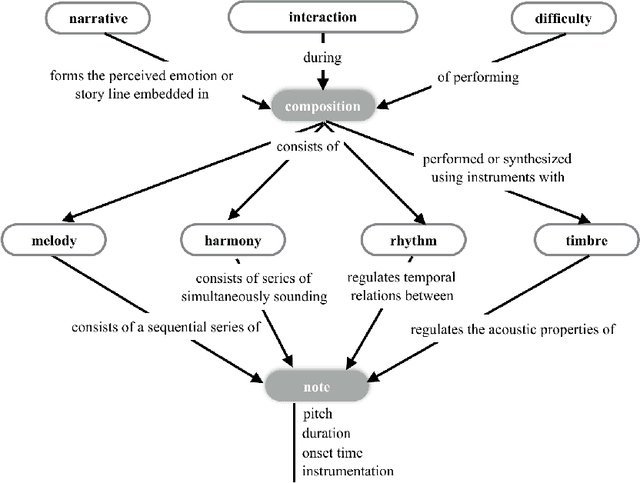

Digital advances have transformed the face of automatic music generation since its beginnings at the dawn of computing. Despite the many breakthroughs, issues such as the musical tasks targeted by different machines and the degree to which they succeed remain open questions. We present a functional taxonomy for music generation systems with reference to existing systems. The taxonomy organizes systems according to the purposes for which they were designed. It also reveals the inter-relatedness amongst the systems. This design-centered approach contrasts with predominant methods-based surveys and facilitates the identification of grand challenges to set the stage for new breakthroughs.
* survey, music generation, taxonomy, functional survey, survey, automatic composition, algorithmic composition
Modelling Sequential Music Track Skips using a Multi-RNN Approach
Mar 20, 2019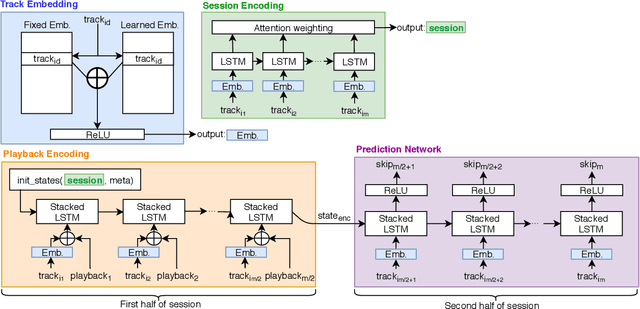
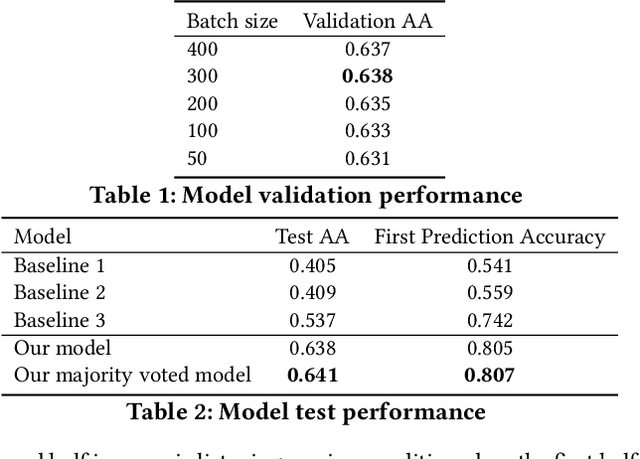
Modelling sequential music skips provides streaming companies the ability to better understand the needs of the user base, resulting in a better user experience by reducing the need to manually skip certain music tracks. This paper describes the solution of the University of Copenhagen DIKU-IR team in the 'Spotify Sequential Skip Prediction Challenge', where the task was to predict the skip behaviour of the second half in a music listening session conditioned on the first half. We model this task using a Multi-RNN approach consisting of two distinct stacked recurrent neural networks, where one network focuses on encoding the first half of the session and the other network focuses on utilizing the encoding to make sequential skip predictions. The encoder network is initialized by a learned session-wide music encoding, and both of them utilize a learned track embedding. Our final model consists of a majority voted ensemble of individually trained models, and ranked 2nd out of 45 participating teams in the competition with a mean average accuracy of 0.641 and an accuracy on the first skip prediction of 0.807. Our code is released at https://github.com/Varyn/WSDM-challenge-2019-spotify.
* 4 pages
Conditioning Deep Generative Raw Audio Models for Structured Automatic Music
Jun 26, 2018
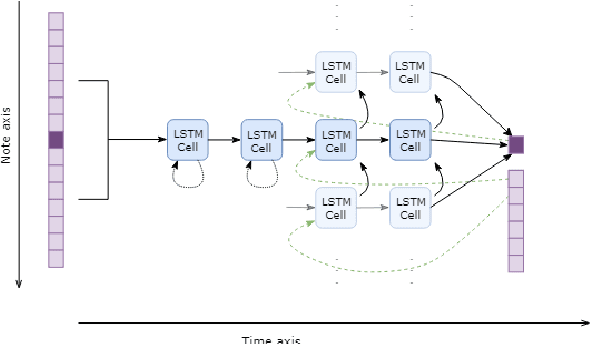
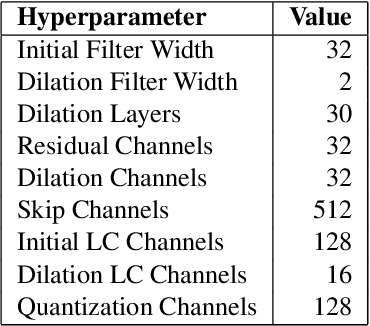
Existing automatic music generation approaches that feature deep learning can be broadly classified into two types: raw audio models and symbolic models. Symbolic models, which train and generate at the note level, are currently the more prevalent approach; these models can capture long-range dependencies of melodic structure, but fail to grasp the nuances and richness of raw audio generations. Raw audio models, such as DeepMind's WaveNet, train directly on sampled audio waveforms, allowing them to produce realistic-sounding, albeit unstructured music. In this paper, we propose an automatic music generation methodology combining both of these approaches to create structured, realistic-sounding compositions. We consider a Long Short Term Memory network to learn the melodic structure of different styles of music, and then use the unique symbolic generations from this model as a conditioning input to a WaveNet-based raw audio generator, creating a model for automatic, novel music. We then evaluate this approach by showcasing results of this work.
The emotions that we perceive in music: the influence of language and lyrics comprehension on agreement
Oct 25, 2019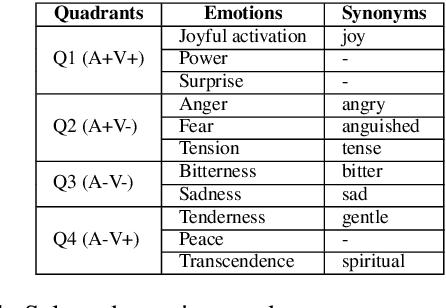
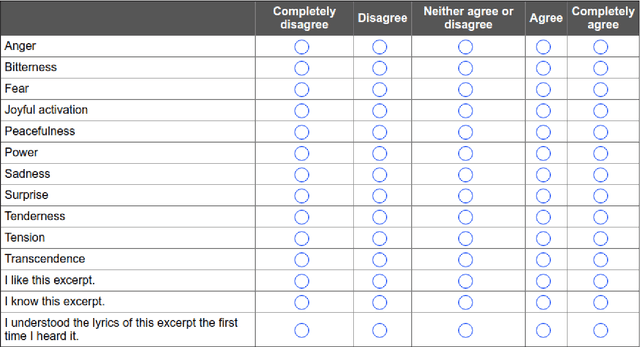
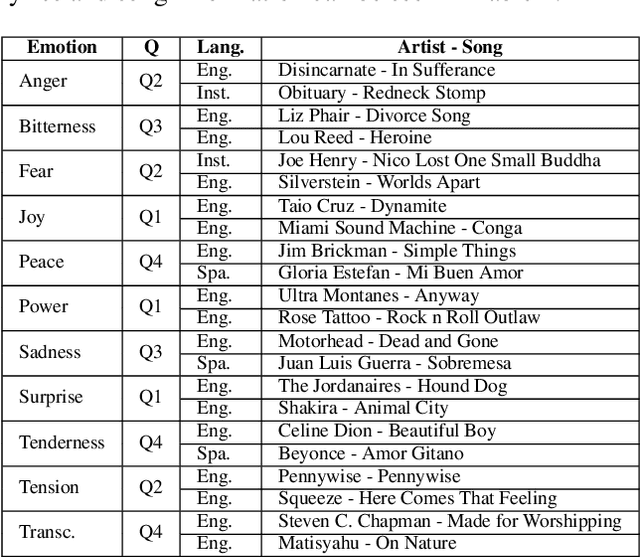

In the present study, we address the relationship between the emotions perceived in pop and rock music (mainly in Euro-American styles with English lyrics) and the language spoken by the listener. Our goal is to understand the influence of lyrics comprehension on the perception of emotions and use this information to improve Music Emotion Recognition (MER) models. Two main research questions are addressed: 1. Are there differences and similarities between the emotions perceived in pop/rock music by listeners raised with different mother tongues? 2. Do personal characteristics have an influence on the perceived emotions for listeners of a given language? Personal characteristics include the listeners' general demographics, familiarity and preference for the fragments, and music sophistication. Our hypothesis is that inter-rater agreement (as defined by Krippendorff's alpha coefficient) from subjects is directly influenced by the comprehension of lyrics.
Learning to Answer Questions in Dynamic Audio-Visual Scenarios
Apr 05, 2022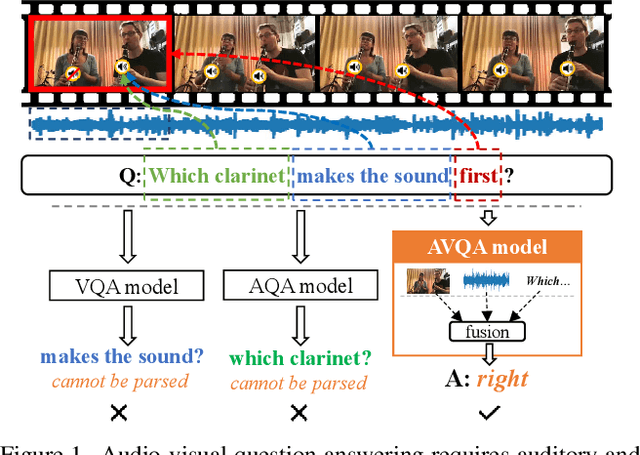

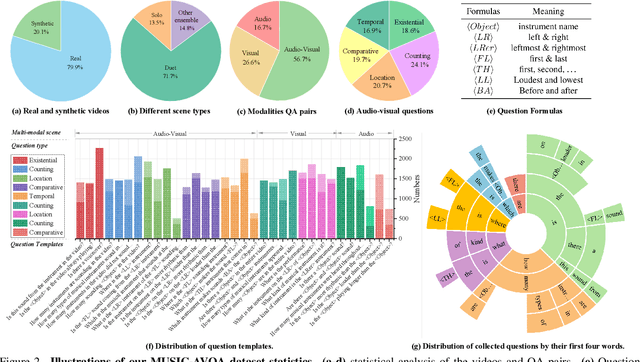
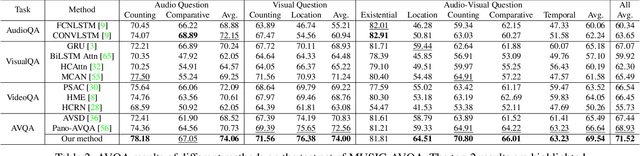
In this paper, we focus on the Audio-Visual Question Answering (AVQA) task, which aims to answer questions regarding different visual objects, sounds, and their associations in videos. The problem requires comprehensive multimodal understanding and spatio-temporal reasoning over audio-visual scenes. To benchmark this task and facilitate our study, we introduce a large-scale MUSIC-AVQA dataset, which contains more than 45K question-answer pairs covering 33 different question templates spanning over different modalities and question types. We develop several baselines and introduce a spatio-temporal grounded audio-visual network for the AVQA problem. Our results demonstrate that AVQA benefits from multisensory perception and our model outperforms recent A-, V-, and AVQA approaches. We believe that our built dataset has the potential to serve as testbed for evaluating and promoting progress in audio-visual scene understanding and spatio-temporal reasoning. Code and dataset: http://gewu-lab.github.io/MUSIC-AVQA/
MIDI-VAE: Modeling Dynamics and Instrumentation of Music with Applications to Style Transfer
Sep 20, 2018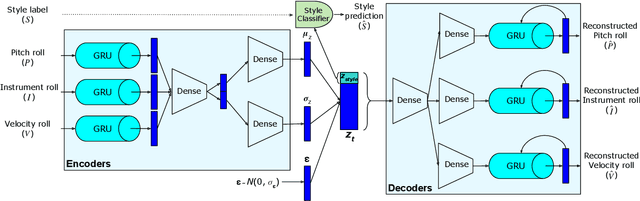
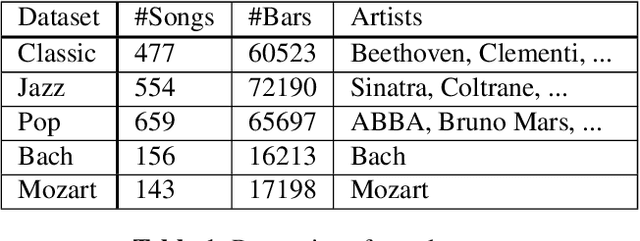
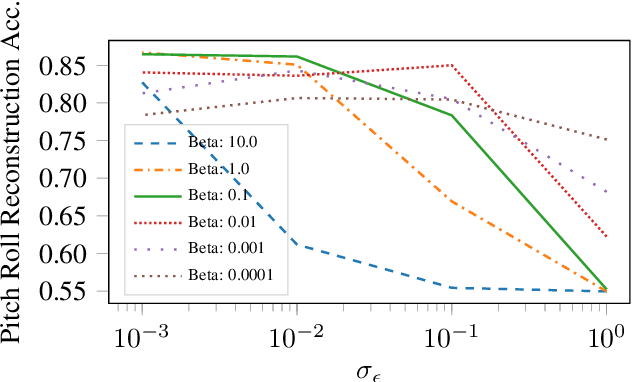
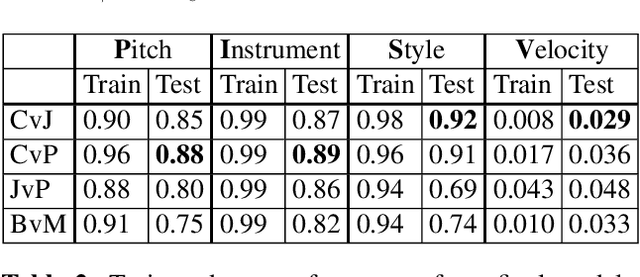
We introduce MIDI-VAE, a neural network model based on Variational Autoencoders that is capable of handling polyphonic music with multiple instrument tracks, as well as modeling the dynamics of music by incorporating note durations and velocities. We show that MIDI-VAE can perform style transfer on symbolic music by automatically changing pitches, dynamics and instruments of a music piece from, e.g., a Classical to a Jazz style. We evaluate the efficacy of the style transfer by training separate style validation classifiers. Our model can also interpolate between short pieces of music, produce medleys and create mixtures of entire songs. The interpolations smoothly change pitches, dynamics and instrumentation to create a harmonic bridge between two music pieces. To the best of our knowledge, this work represents the first successful attempt at applying neural style transfer to complete musical compositions.
A Computationally Efficient 2D MUSIC Approach for 5G and 6G Sensing Networks
Apr 30, 2021
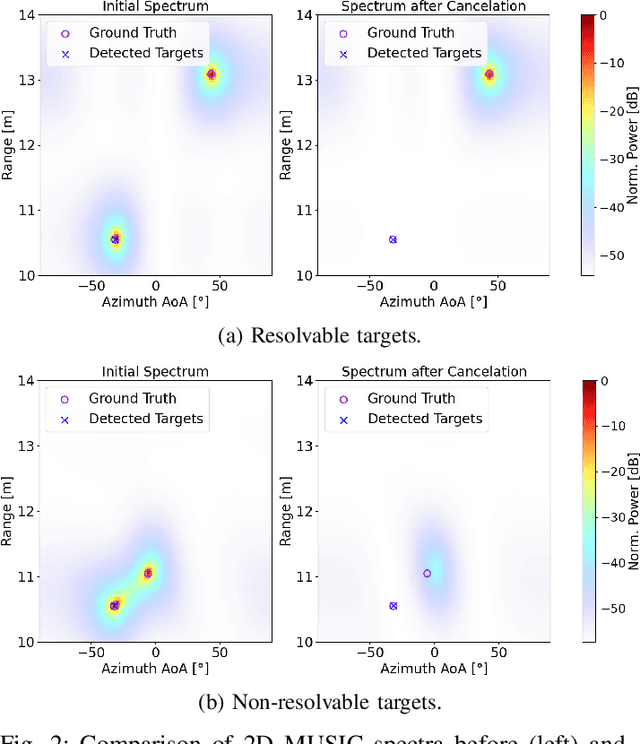
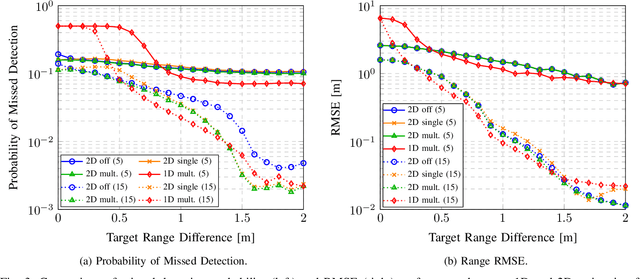

Future cellular networks are intended to have the ability to sense the environment by utilizing reflections of transmitted signals. Multi-dimensional sensing brings along the crucial advantage of being able to resort to multiple domains to resolve targets, enhancing detection capabilities compared to 1D estimation. However, estimating parameters jointly in 5G New Radio (NR) systems poses the challenge of limiting the computational complexity while preserving a high resolution. To that end, wepropose a channel state information (CSI) decimation technique for MUltiple SIgnal Classification (MUSIC)-based joint rangeangle of arrival (AoA) estimation. We further introduce multi-peak search routines to achieve additional detection capability improvements. Simulation results with orthogonal frequency-division multiplexing (OFDM) signals show that we attain higher detection probabilities for closely spaced targets than with 1D range-only estimation. Moreover, we demonstrate that for our considered 5G setup, we are able to significantly reduce the required number of computations due to CSI decimation.