 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
partitura: A Python Package for Handling Symbolic Musical Data
Jan 31, 2022
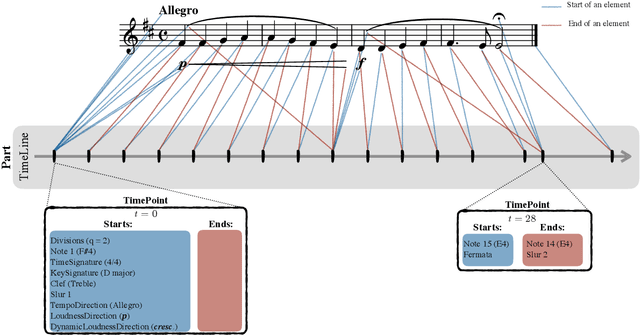
This demo paper introduces partitura, a Python package for handling symbolic musical information. The principal aim of this package is to handle richly structured musical information as conveyed by modern staff music notation. It provides a much wider range of possibilities to deal with music than the more reductive (but very common) piano roll-oriented approach inspired by the MIDI standard. The package is an open source project and is available on GitHub.
A Computationally Efficient 2D MUSIC Approach for 5G and 6G Sensing Networks
May 26, 2021
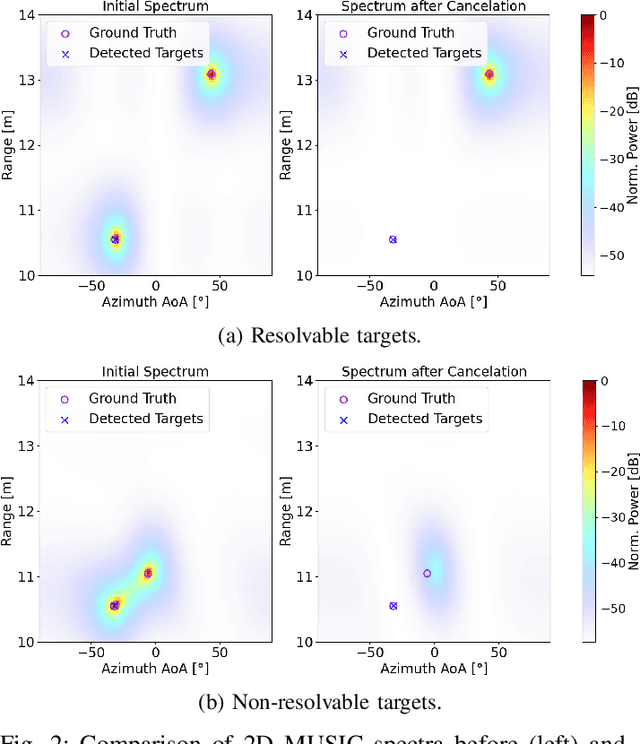
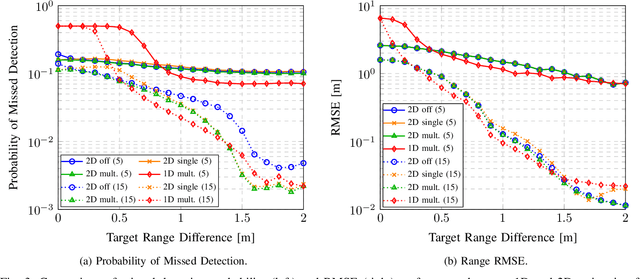

Future cellular networks are intended to have the ability to sense the environment by utilizing reflections of transmitted signals. Multi-dimensional sensing brings along the crucial advantage of being able to resort to multiple domains to resolve targets, enhancing detection capabilities compared to 1D estimation. However, estimating parameters jointly in 5G New Radio (NR) systems poses the challenge of limiting the computational complexity while preserving a high resolution. To that end, we make us of channel state information (CSI) decimation for MUltiple SIgnal Classification (MUSIC)-based joint range-angle of arrival (AoA) estimation. We further introduce multi-peak search routines to achieve additional detection capability improvements. Simulation results with orthogonal frequency-division multiplexing (OFDM) signals show that we attain higher detection probabilities for closely spaced targets than with 1D range-only estimation. Moreover, we demonstrate that for our considered 5G setup, we are able to significantly reduce the required number of computations due to CSI decimation.
Evaluating Recommender System Algorithms for Generating Local Music Playlists
Jul 17, 2019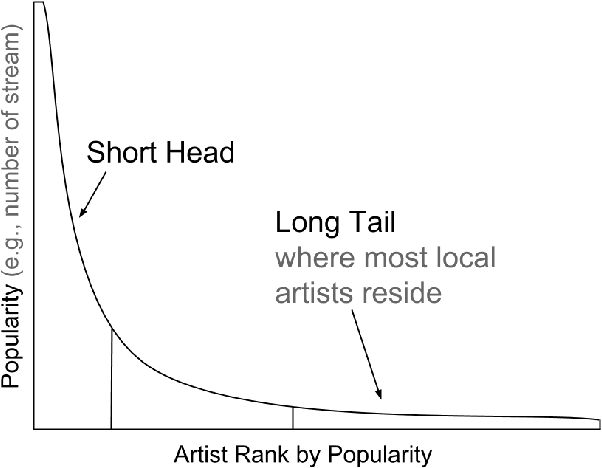


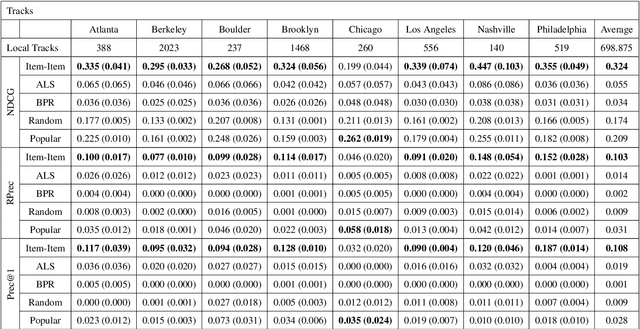
We explore the task of local music recommendation: provide listeners with personalized playlists of relevant tracks by artists who play most of their live events within a small geographic area. Most local artists tend to be obscure, long-tail artists and generally have little or no available user preference data associated with them. This creates a cold-start problem for collaborative filtering-based recommendation algorithms that depend on large amounts of such information to make accurate recommendations. In this paper, we compare the performance of three standard recommender system algorithms (Item-Item Neighborhood (IIN), Alternating Least Squares for Implicit Feedback (ALS), and Bayesian Personalized Ranking (BPR)) on the task of local music recommendation using the Million Playlist Dataset. To do this, we modify the standard evaluation procedure such that the algorithms only rank tracks by local artists for each of the eight different cities. Despite the fact that techniques based on matrix factorization (ALS, BPR) typically perform best on large recommendation tasks, we find that the neighborhood-based approach (IIN) performs best for long-tail local music recommendation.
HAIDA: Biometric technological therapy tools for neurorehabilitation of Cognitive Impairment
Mar 09, 2022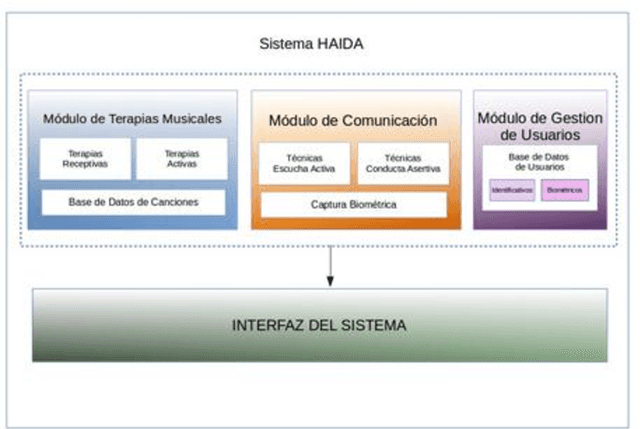
Dementia, and specially Alzheimer s disease (AD) and Mild Cognitive Impairment (MCI) are one of the most important diseases suffered by elderly population. Music therapy is one of the most widely used non-pharmacological treatment in the field of cognitive impairments, given that music influences their mood, behavior, the decrease of anxiety, as well as facilitating reminiscence, emotional expressions and movement. In this work we present HAIDA, a multi-platform support system for Musical Therapy oriented to cognitive impairment, which includes not only therapy tools but also non-invasive biometric analysis, speech, activity and hand activity. At this moment the system is on use and recording the first sets of data.
* 2 pages
Speed Up the Cold-Start Learning in Two-Sided Bandits with Many Arms
Oct 01, 2022



Multi-armed bandit (MAB) algorithms are efficient approaches to reduce the opportunity cost of online experimentation and are used by companies to find the best product from periodically refreshed product catalogs. However, these algorithms face the so-called cold-start at the onset of the experiment due to a lack of knowledge of customer preferences for new products, requiring an initial data collection phase known as the burning period. During this period, MAB algorithms operate like randomized experiments, incurring large burning costs which scale with the large number of products. We attempt to reduce the burning by identifying that many products can be cast into two-sided products, and then naturally model the rewards of the products with a matrix, whose rows and columns represent the two sides respectively. Next, we design two-phase bandit algorithms that first use subsampling and low-rank matrix estimation to obtain a substantially smaller targeted set of products and then apply a UCB procedure on the target products to find the best one. We theoretically show that the proposed algorithms lower costs and expedite the experiment in cases when there is limited experimentation time along with a large product set. Our analysis also reveals three regimes of long, short, and ultra-short horizon experiments, depending on dimensions of the matrix. Empirical evidence from both synthetic data and a real-world dataset on music streaming services validates this superior performance.
ragamAI: A Network Based Recommender System to Arrange a Indian Classical Music Concert
Dec 08, 2019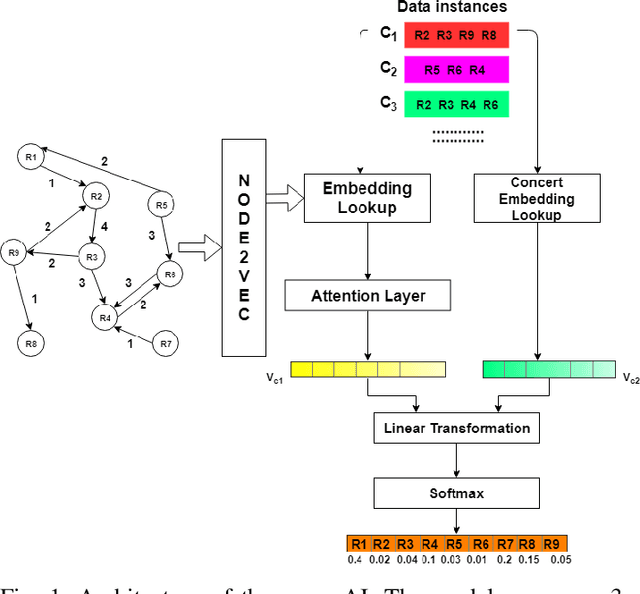
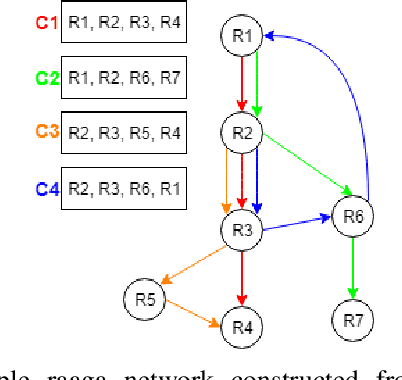
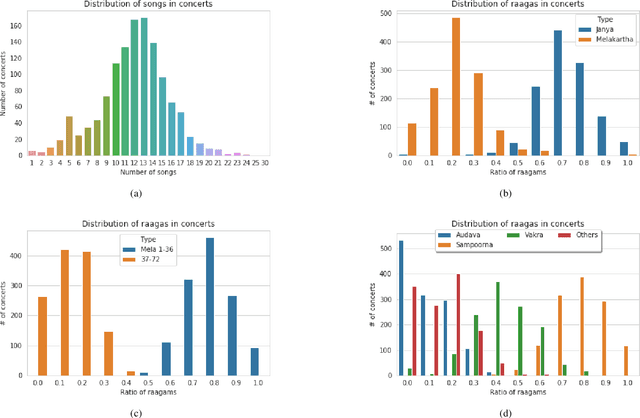
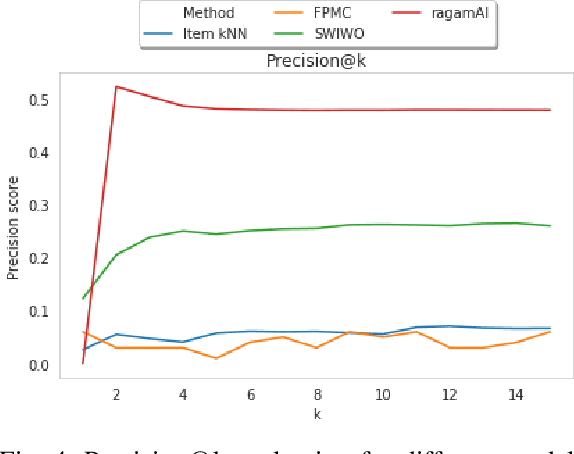
South Indian classical music (Carnatic music) is best consumed through live concerts. A carnatic recital requires meticulous planning accounting for several parameters like the performers' repertoire, composition variety, musical versatility, thematic structure, the recital's arrangement, etc. to ensure that the audience have a comprehensive listening experience. In this work, we present ragamAI a novel machine learning framework that utilizes the tonic nuances and musical structures in the carnatic music to generate a concert recital that melodically captures the entire range in an octave. Utilizing the underlying idea of playlist and session-based recommender models, the proposed model studies the mathematical structure present in past concerts and recommends relevant items for the playlist/concert. ragamAI ensembles recommendations given by multiple models to learn user idea and past preference of sequences in concerts to extract recommendations. Our experiments on a vast collection of concert show that our model performs 25%-50% better than baseline models. ragamAI's applications are two-fold. 1) it will assist musicians to customize their performance with the necessary variety required to sustain the interest of the audience for the entirety of the concert 2) it will generate carefully curated lists of south Indian classical music so that the listener can discover the wide range of melody that the musical system can offer.
Checklist Models for Improved Output Fluency in Piano Fingering Prediction
Sep 12, 2022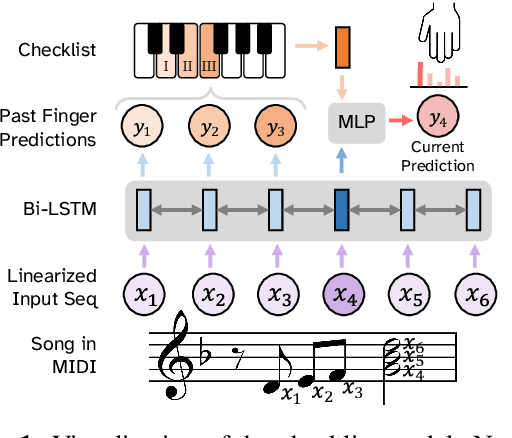
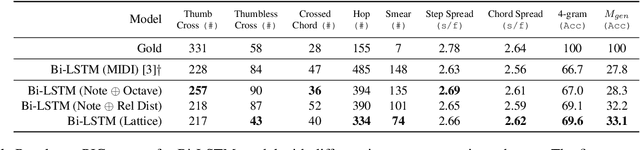
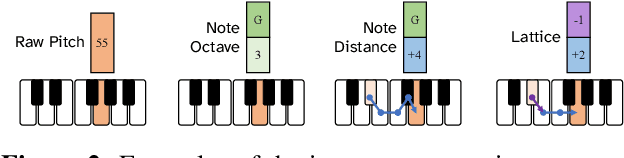
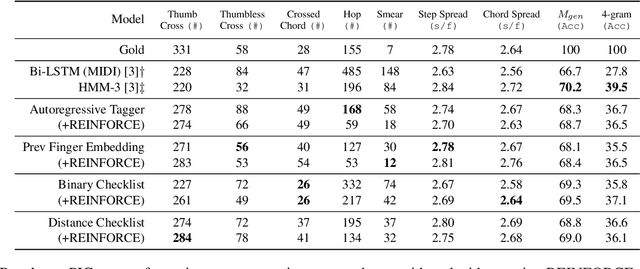
In this work we present a new approach for the task of predicting fingerings for piano music. While prior neural approaches have often treated this as a sequence tagging problem with independent predictions, we put forward a checklist system, trained via reinforcement learning, that maintains a representation of recent predictions in addition to a hidden state, allowing it to learn soft constraints on output structure. We also demonstrate that by modifying input representations -- which in prior work using neural models have often taken the form of one-hot encodings over individual keys on the piano -- to encode relative position on the keyboard to the prior note instead, we can achieve much better performance. Additionally, we reassess the use of raw per-note labeling precision as an evaluation metric, noting that it does not adequately measure the fluency, i.e. human playability, of a model's output. To this end, we compare methods across several statistics which track the frequency of adjacent finger predictions that while independently reasonable would be physically challenging to perform in sequence, and implement a reinforcement learning strategy to minimize these as part of our training loss. Finally through human expert evaluation, we demonstrate significant gains in performability directly attributable to improvements with respect to these metrics.
GAFX: A General Audio Feature eXtractor
Jul 19, 2022
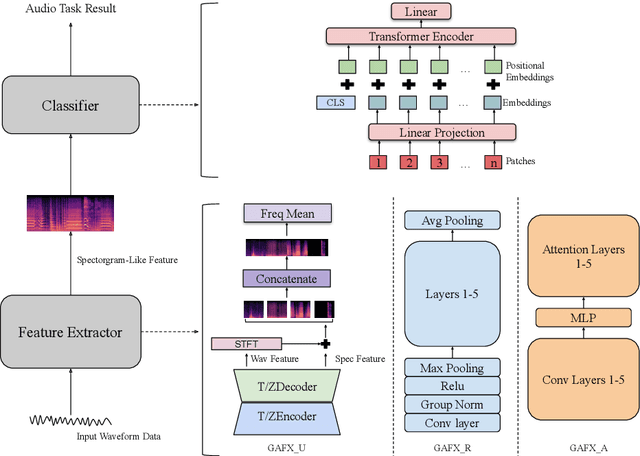
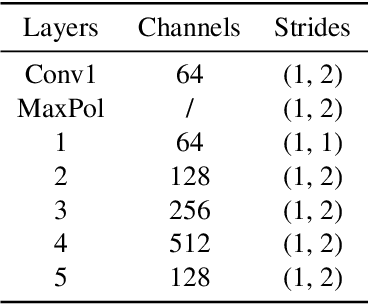

Most machine learning models for audio tasks are dealing with a handcrafted feature, the spectrogram. However, it is still unknown whether the spectrogram could be replaced with deep learning based features. In this paper, we answer this question by comparing the different learnable neural networks extracting features with a successful spectrogram model and proposed a General Audio Feature eXtractor (GAFX) based on a dual U-Net (GAFX-U), ResNet (GAFX-R), and Attention (GAFX-A) modules. We design experiments to evaluate this model on the music genre classification task on the GTZAN dataset and perform a detailed ablation study of different configurations of our framework and our model GAFX-U, following the Audio Spectrogram Transformer (AST) classifier achieves competitive performance.
Learning Features of Music from Scratch
Apr 06, 2017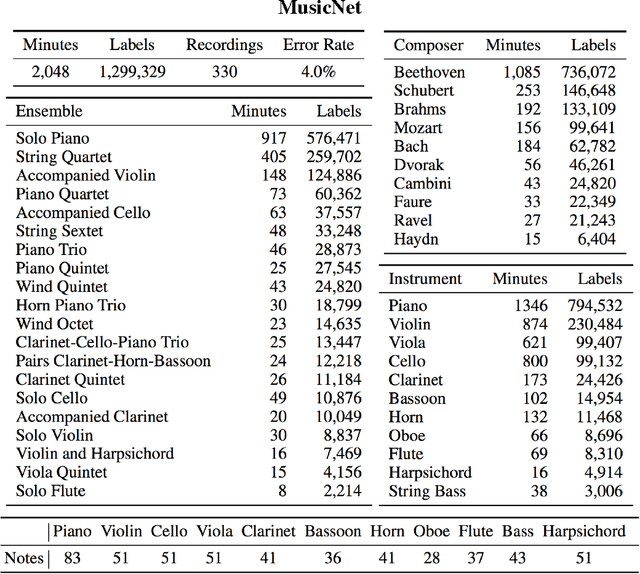
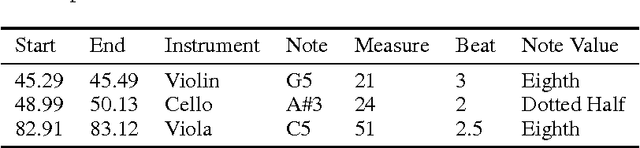
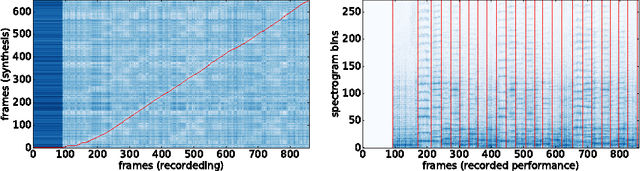
This paper introduces a new large-scale music dataset, MusicNet, to serve as a source of supervision and evaluation of machine learning methods for music research. MusicNet consists of hundreds of freely-licensed classical music recordings by 10 composers, written for 11 instruments, together with instrument/note annotations resulting in over 1 million temporal labels on 34 hours of chamber music performances under various studio and microphone conditions. The paper defines a multi-label classification task to predict notes in musical recordings, along with an evaluation protocol, and benchmarks several machine learning architectures for this task: i) learning from spectrogram features; ii) end-to-end learning with a neural net; iii) end-to-end learning with a convolutional neural net. These experiments show that end-to-end models trained for note prediction learn frequency selective filters as a low-level representation of audio.
Jazz Contrafact Detection
Aug 01, 2022
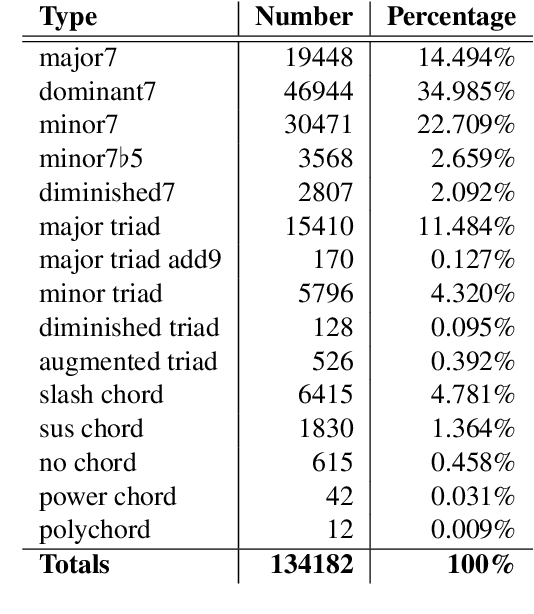

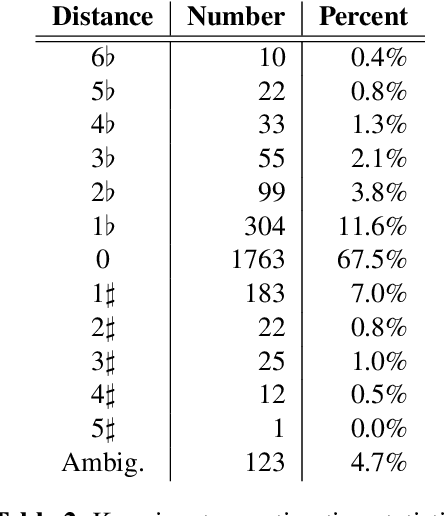
In jazz, a contrafact is a new melody composed over an existing, but often reharmonized chord progression. Because reharmonization can introduce a wide range of variations, detecting contrafacts is a challenging task. This paper develops a novel vector-space model to represent chord progressions, and uses it for contrafact detection. The process applies principles from music theory to reduce the dimensionality of chord space, determine a common key signature representation, and compute a chordal co-occurrence matrix. The rows of the matrix form a basis for the vector space in which chord progressions are represented as piecewise linear functions, and harmonic similarity is evaluated by computing the membrane area, a novel distance metric. To illustrate our method's effectiveness, we apply it to the Impro-Visor corpus of 2,612 chord progressions, and present examples demonstrating its ability to account for reharmonizations and find contrafacts.