 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Music Transcription Based on Bayesian Piece-Specific Score Models Capturing Repetitions
Aug 18, 2019
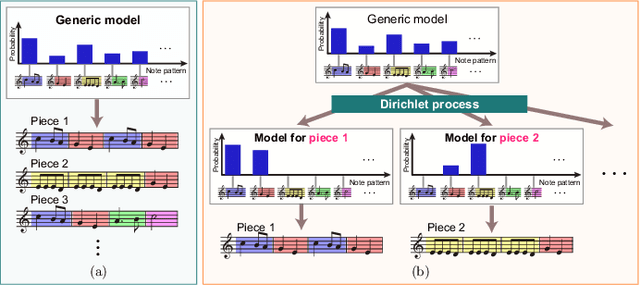
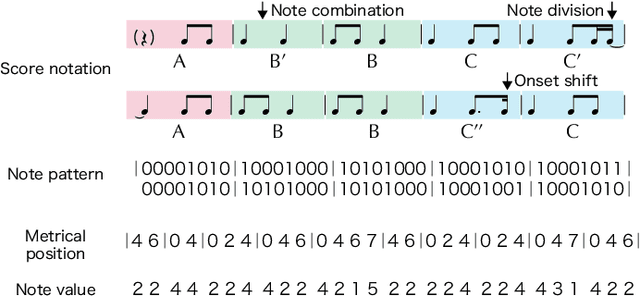
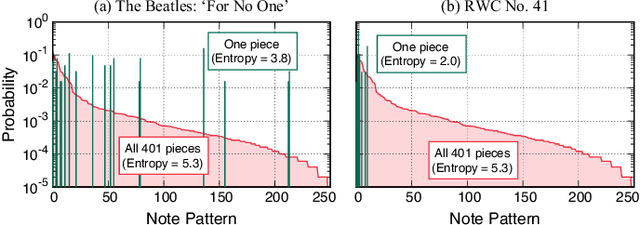
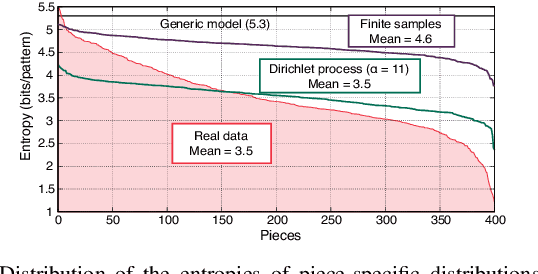
Most work on models for music transcription has focused on describing local sequential dependence of notes in musical scores and failed to capture their global repetitive structure, which can be a useful guide for transcribing music. Focusing on the rhythm, we formulate several classes of Bayesian Markov models of musical scores that describe repetitions indirectly by sparse transition probabilities of notes or note patterns. This enables us to construct piece-specific models for unseen scores with unfixed repetitive structure and to derive tractable inference algorithms. Moreover, to describe approximate repetitions, we explicitly incorporate a process of modifying the repeated notes/note patterns. We apply these models as a prior music language model for rhythm transcription, where piece-specific score models are inferred from performed MIDI data by unsupervised learning, in contrast to the conventional supervised construction of score models. Evaluations using vocal melodies of popular music showed that the Bayesian models improved the transcription accuracy for most of the tested model types, indicating the universal efficacy of the proposed approach.
Metric Learning vs Classification for Disentangled Music Representation Learning
Aug 12, 2020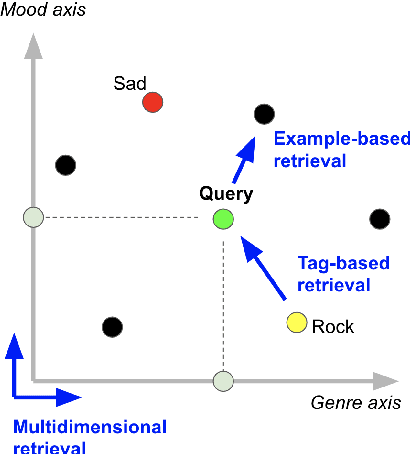
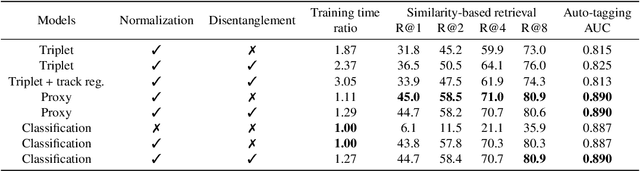
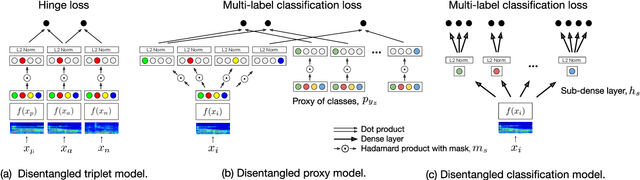

Deep representation learning offers a powerful paradigm for mapping input data onto an organized embedding space and is useful for many music information retrieval tasks. Two central methods for representation learning include deep metric learning and classification, both having the same goal of learning a representation that can generalize well across tasks. Along with generalization, the emerging concept of disentangled representations is also of great interest, where multiple semantic concepts (e.g., genre, mood, instrumentation) are learned jointly but remain separable in the learned representation space. In this paper we present a single representation learning framework that elucidates the relationship between metric learning, classification, and disentanglement in a holistic manner. For this, we (1) outline past work on the relationship between metric learning and classification, (2) extend this relationship to multi-label data by exploring three different learning approaches and their disentangled versions, and (3) evaluate all models on four tasks (training time, similarity retrieval, auto-tagging, and triplet prediction). We find that classification-based models are generally advantageous for training time, similarity retrieval, and auto-tagging, while deep metric learning exhibits better performance for triplet-prediction. Finally, we show that our proposed approach yields state-of-the-art results for music auto-tagging.
Transfer learning for music classification and regression tasks
Sep 13, 2017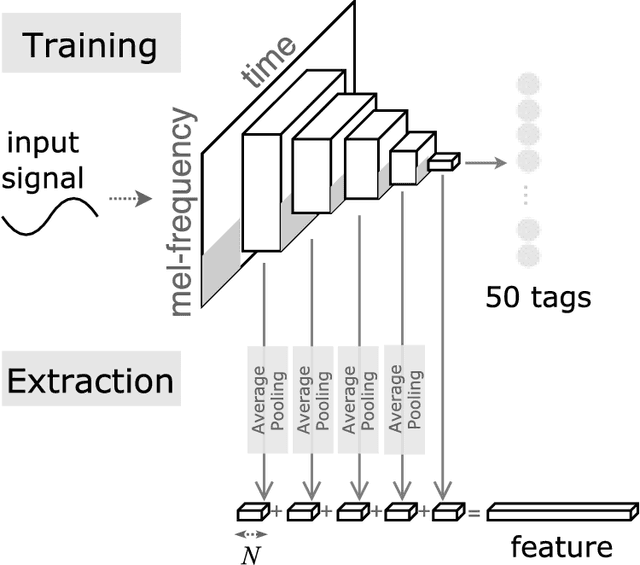
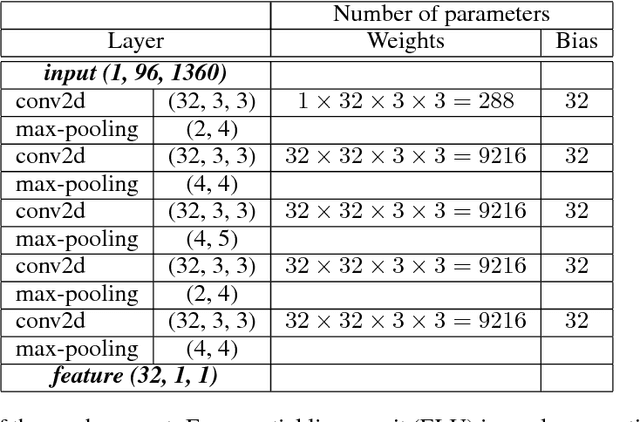
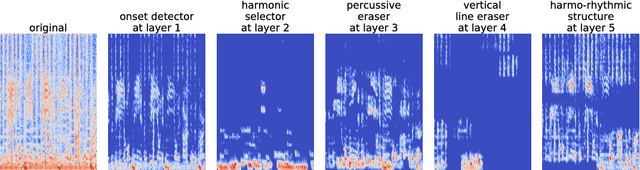
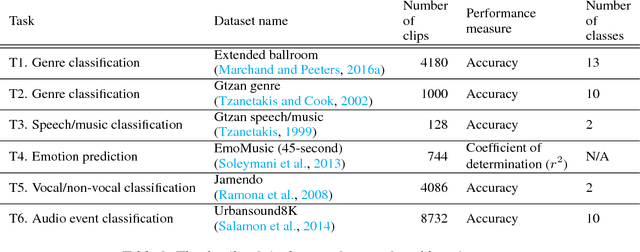
In this paper, we present a transfer learning approach for music classification and regression tasks. We propose to use a pre-trained convnet feature, a concatenated feature vector using the activations of feature maps of multiple layers in a trained convolutional network. We show how this convnet feature can serve as general-purpose music representation. In the experiments, a convnet is trained for music tagging and then transferred to other music-related classification and regression tasks. The convnet feature outperforms the baseline MFCC feature in all the considered tasks and several previous approaches that are aggregating MFCCs as well as low- and high-level music features.
Exploring Transformer's potential on automatic piano transcription
Apr 08, 2022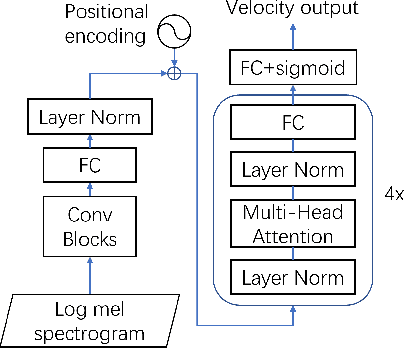

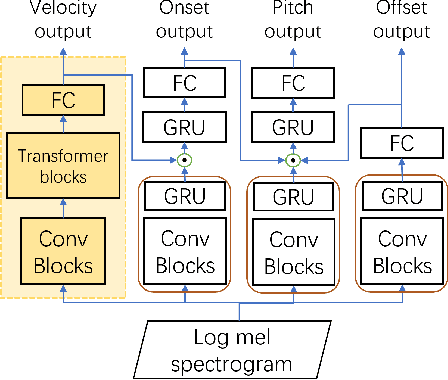
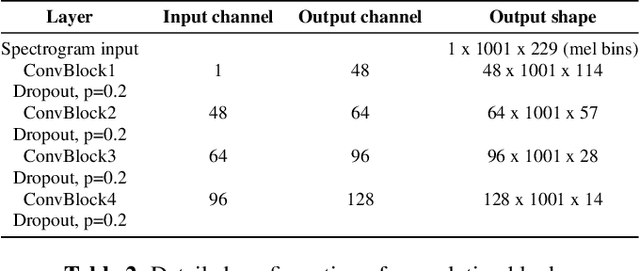
Most recent research about automatic music transcription (AMT) uses convolutional neural networks and recurrent neural networks to model the mapping from music signals to symbolic notation. Based on a high-resolution piano transcription system, we explore the possibility of incorporating another powerful sequence transformation tool -- the Transformer -- to deal with the AMT problem. We argue that the properties of the Transformer make it more suitable for certain AMT subtasks. We confirm the Transformer's superiority on the velocity detection task by experiments on the MAESTRO dataset and a cross-dataset evaluation on the MAPS dataset. We observe a performance improvement on both frame-level and note-level metrics after introducing the Transformer network.
Deep-Learning Architectures for Multi-Pitch Estimation: Towards Reliable Evaluation
Feb 18, 2022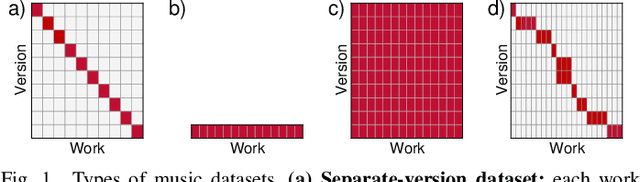
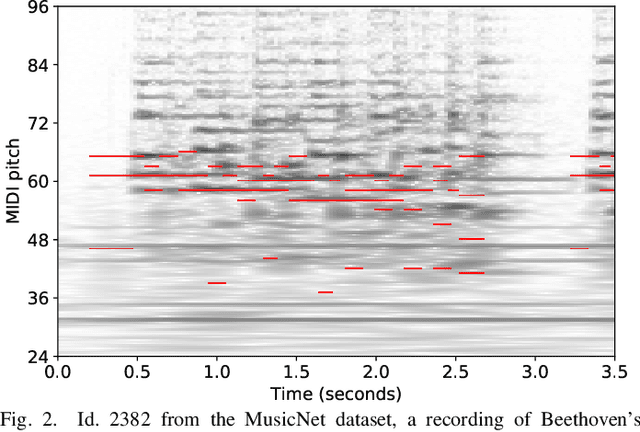
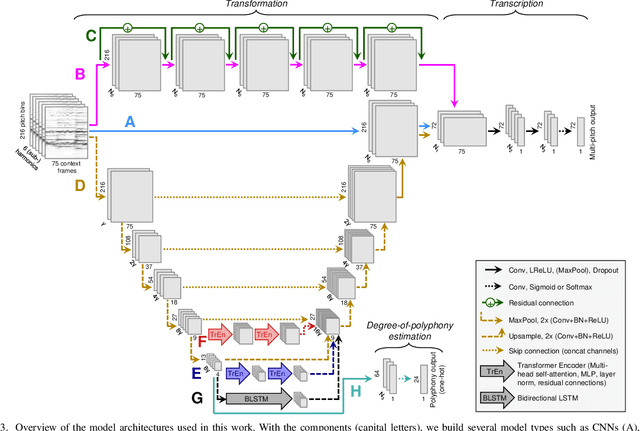
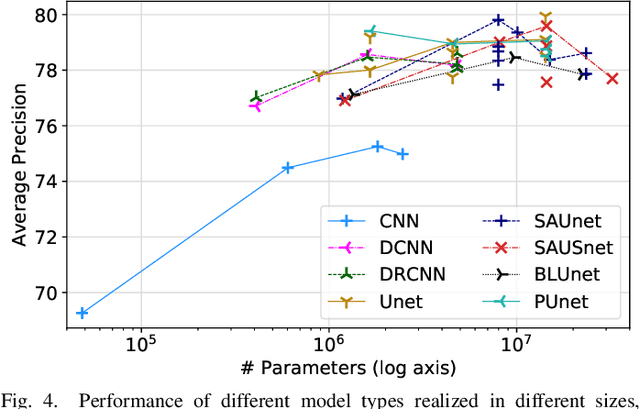
Extracting pitch information from music recordings is a challenging but important problem in music signal processing. Frame-wise transcription or multi-pitch estimation aims for detecting the simultaneous activity of pitches in polyphonic music recordings and has recently seen major improvements thanks to deep-learning techniques, with a variety of proposed network architectures. In this paper, we realize different architectures based on CNNs, the U-net structure, and self-attention components. We propose several modifications to these architectures including self-attention modules for skip connections, recurrent layers to replace the self-attention, and a multi-task strategy with simultaneous prediction of the degree of polyphony. We compare variants of these architectures in different sizes for multi-pitch estimation, focusing on Western classical music beyond the piano-solo scenario using the MusicNet and Schubert Winterreise datasets. Our experiments indicate that most architectures yield competitive results and that larger model variants seem to be beneficial. However, we find that these results substantially depend on randomization effects and the particular choice of the training-test split, which questions the claim of superiority for particular architectures given only small improvements. We therefore investigate the influence of dataset splits in the presence of several movements of a work cycle (cross-version evaluation) and propose a best-practice splitting strategy for MusicNet, which weakens the influence of individual test tracks and suppresses overfitting to specific works and recording conditions. A final evaluation on a mixed dataset suggests that improvements on one specific dataset do not necessarily generalize to other scenarios, thus emphasizing the need for further high-quality multi-pitch datasets in order to reliably measure progress in music transcription tasks.
Multi-objective Hyper-parameter Optimization of Behavioral Song Embeddings
Aug 26, 2022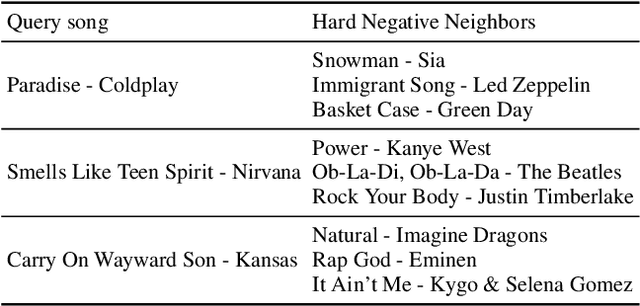
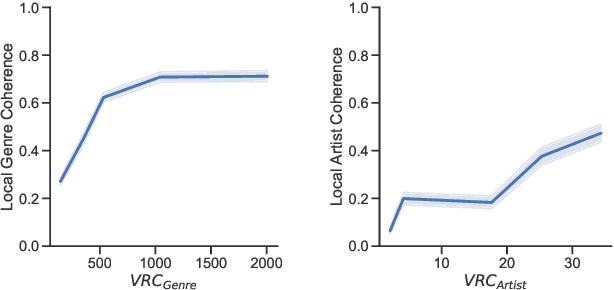
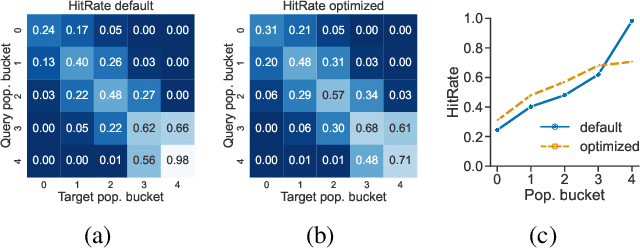
Song embeddings are a key component of most music recommendation engines. In this work, we study the hyper-parameter optimization of behavioral song embeddings based on Word2Vec on a selection of downstream tasks, namely next-song recommendation, false neighbor rejection, and artist and genre clustering. We present new optimization objectives and metrics to monitor the effects of hyper-parameter optimization. We show that single-objective optimization can cause side effects on the non optimized metrics and propose a simple multi-objective optimization to mitigate these effects. We find that next-song recommendation quality of Word2Vec is anti-correlated with song popularity, and we show how song embedding optimization can balance performance across different popularity levels. We then show potential positive downstream effects on the task of play prediction. Finally, we provide useful insights on the effects of training dataset scale by testing hyper-parameter optimization on an industry-scale dataset.
Multi-scale Embedded CNN for Music Tagging (MsE-CNN)
Jun 16, 2019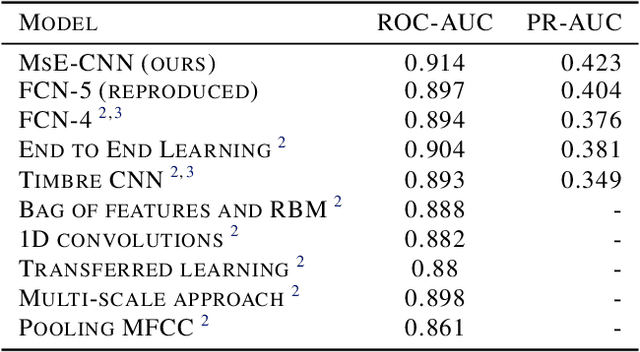
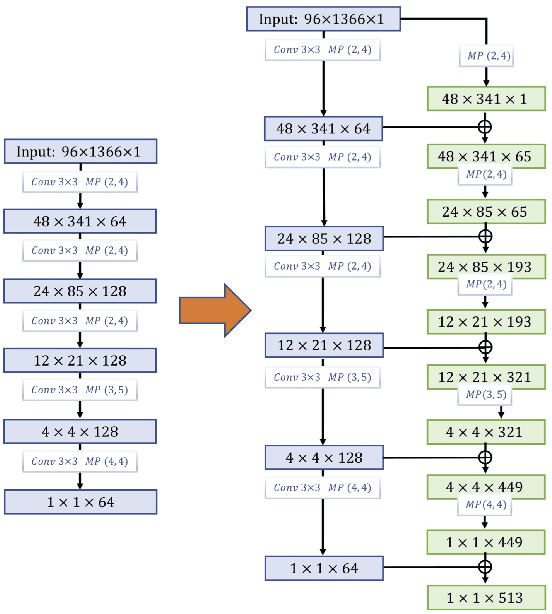
Convolutional neural networks (CNN) recently gained notable attraction in a variety of machine learning tasks: including music classification and style tagging. In this work, we propose implementing intermediate connections to the CNN architecture to facilitate the transfer of multi-scale/level knowledge between different layers. Our novel model for music tagging shows significant improvement in comparison to the proposed approaches in the literature, due to its ability to carry low-level timbral features to the last layer.
Concept-Based Techniques for "Musicologist-friendly" Explanations in a Deep Music Classifier
Aug 29, 2022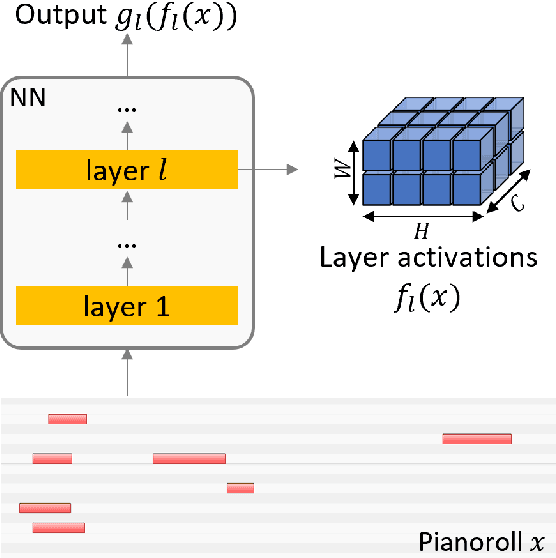

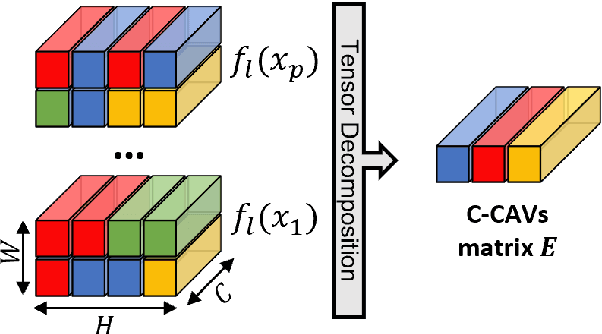
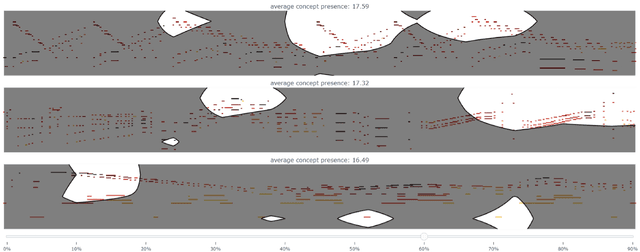
Current approaches for explaining deep learning systems applied to musical data provide results in a low-level feature space, e.g., by highlighting potentially relevant time-frequency bins in a spectrogram or time-pitch bins in a piano roll. This can be difficult to understand, particularly for musicologists without technical knowledge. To address this issue, we focus on more human-friendly explanations based on high-level musical concepts. Our research targets trained systems (post-hoc explanations) and explores two approaches: a supervised one, where the user can define a musical concept and test if it is relevant to the system; and an unsupervised one, where musical excerpts containing relevant concepts are automatically selected and given to the user for interpretation. We demonstrate both techniques on an existing symbolic composer classification system, showcase their potential, and highlight their intrinsic limitations.
Sketching the Expression: Flexible Rendering of Expressive Piano Performance with Self-Supervised Learning
Aug 31, 2022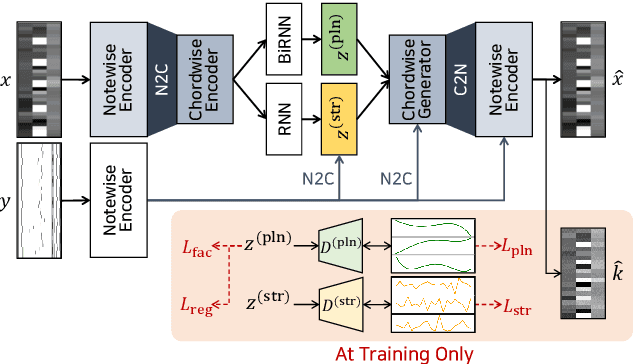
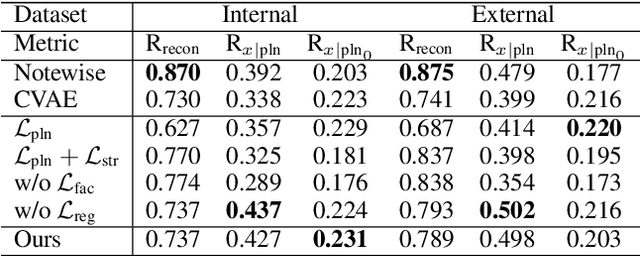
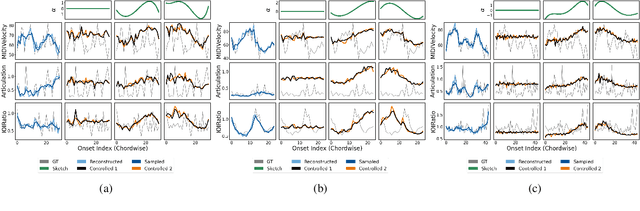
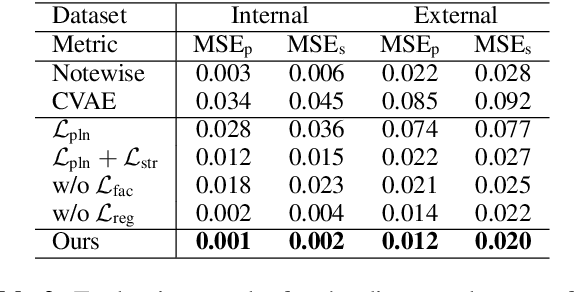
We propose a system for rendering a symbolic piano performance with flexible musical expression. It is necessary to actively control musical expression for creating a new music performance that conveys various emotions or nuances. However, previous approaches were limited to following the composer's guidelines of musical expression or dealing with only a part of the musical attributes. We aim to disentangle the entire musical expression and structural attribute of piano performance using a conditional VAE framework. It stochastically generates expressive parameters from latent representations and given note structures. In addition, we employ self-supervised approaches that force the latent variables to represent target attributes. Finally, we leverage a two-step encoder and decoder that learn hierarchical dependency to enhance the naturalness of the output. Experimental results show that our system can stably generate performance parameters relevant to the given musical scores, learn disentangled representations, and control musical attributes independently of each other.