 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Pop Music Highlighter: Marking the Emotion Keypoints
Sep 25, 2018
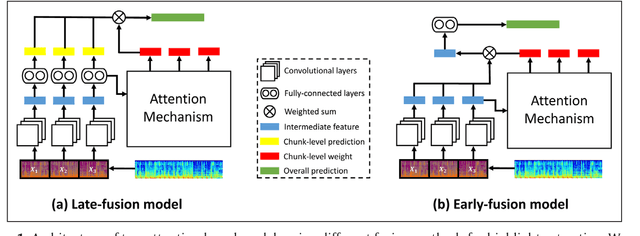
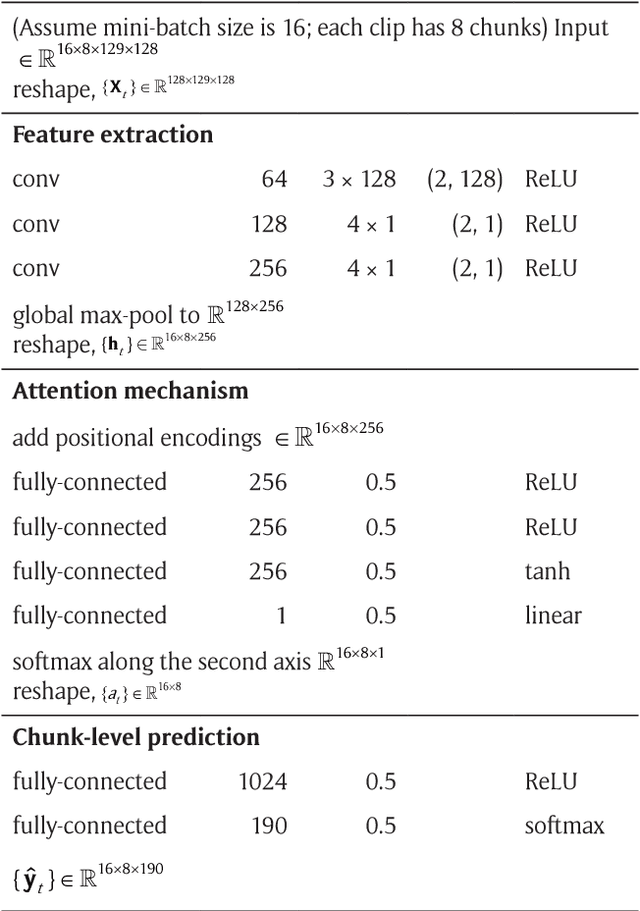
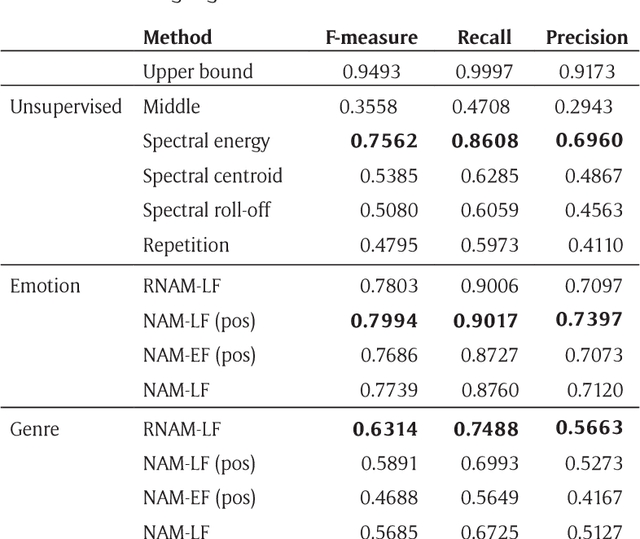
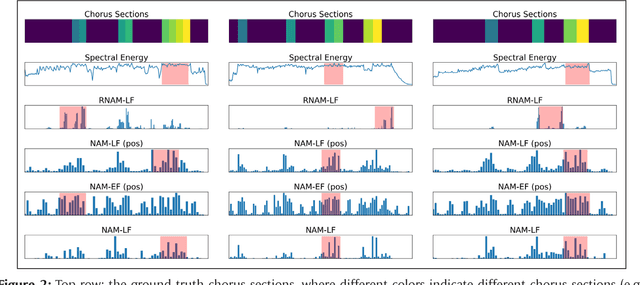
The goal of music highlight extraction is to get a short consecutive segment of a piece of music that provides an effective representation of the whole piece. In a previous work, we introduced an attention-based convolutional recurrent neural network that uses music emotion classification as a surrogate task for music highlight extraction, for Pop songs. The rationale behind that approach is that the highlight of a song is usually the most emotional part. This paper extends our previous work in the following two aspects. First, methodology-wise we experiment with a new architecture that does not need any recurrent layers, making the training process faster. Moreover, we compare a late-fusion variant and an early-fusion variant to study which one better exploits the attention mechanism. Second, we conduct and report an extensive set of experiments comparing the proposed attention-based methods against a heuristic energy-based method, a structural repetition-based method, and a few other simple feature-based methods for this task. Due to the lack of public-domain labeled data for highlight extraction, following our previous work we use the RWC POP 100-song data set to evaluate how the detected highlights overlap with any chorus sections of the songs. The experiments demonstrate the effectiveness of our methods over competing methods. For reproducibility, we open source the code and pre-trained model at https://github.com/remyhuang/pop-music-highlighter/.
Rethinking Recurrent Latent Variable Model for Music Composition
Oct 07, 2018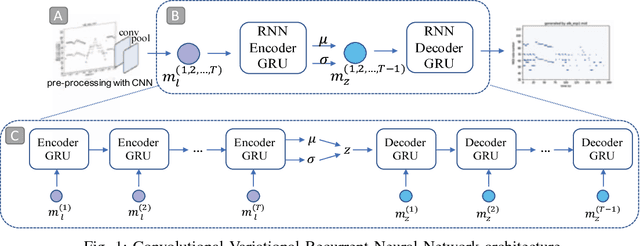
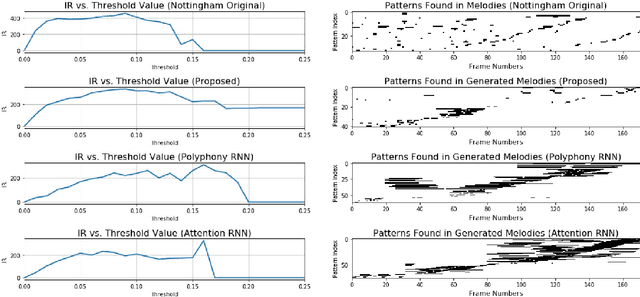

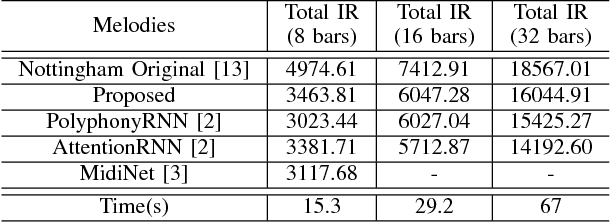
We present a model for capturing musical features and creating novel sequences of music, called the Convolutional Variational Recurrent Neural Network. To generate sequential data, the model uses an encoder-decoder architecture with latent probabilistic connections to capture the hidden structure of music. Using the sequence-to-sequence model, our generative model can exploit samples from a prior distribution and generate a longer sequence of music. We compare the performance of our proposed model with other types of Neural Networks using the criteria of Information Rate that is implemented by Variable Markov Oracle, a method that allows statistical characterization of musical information dynamics and detection of motifs in a song. Our results suggest that the proposed model has a better statistical resemblance to the musical structure of the training data, which improves the creation of new sequences of music in the style of the originals.
Improved singing voice separation with chromagram-based pitch-aware remixing
Mar 28, 2022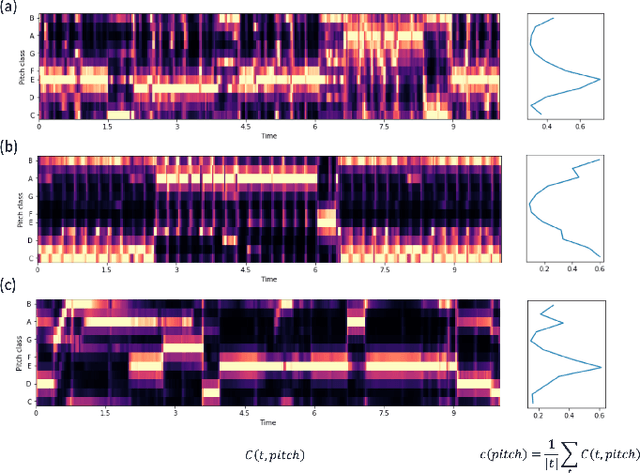
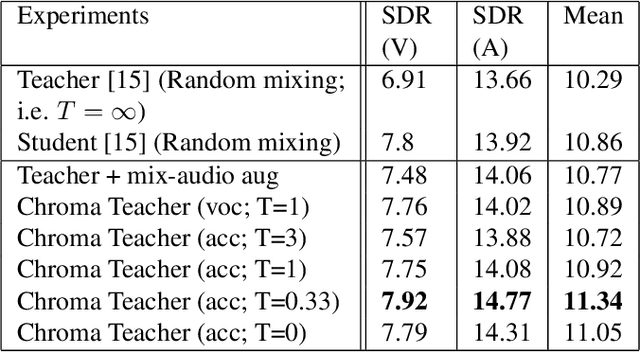
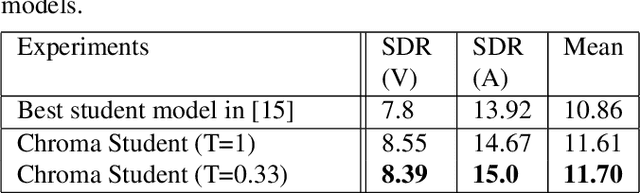
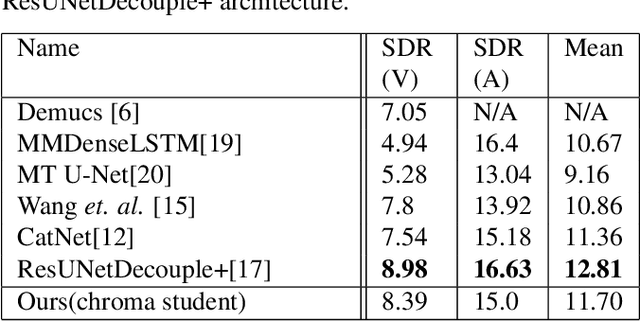
Singing voice separation aims to separate music into vocals and accompaniment components. One of the major constraints for the task is the limited amount of training data with separated vocals. Data augmentation techniques such as random source mixing have been shown to make better use of existing data and mildly improve model performance. We propose a novel data augmentation technique, chromagram-based pitch-aware remixing, where music segments with high pitch alignment are mixed. By performing controlled experiments in both supervised and semi-supervised settings, we demonstrate that training models with pitch-aware remixing significantly improves the test signal-to-distortion ratio (SDR)
GANs & Reels: Creating Irish Music using a Generative Adversarial Network
Oct 29, 2020
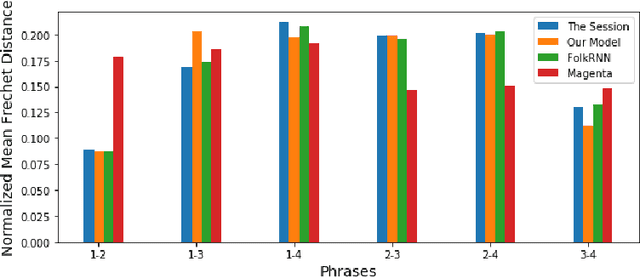
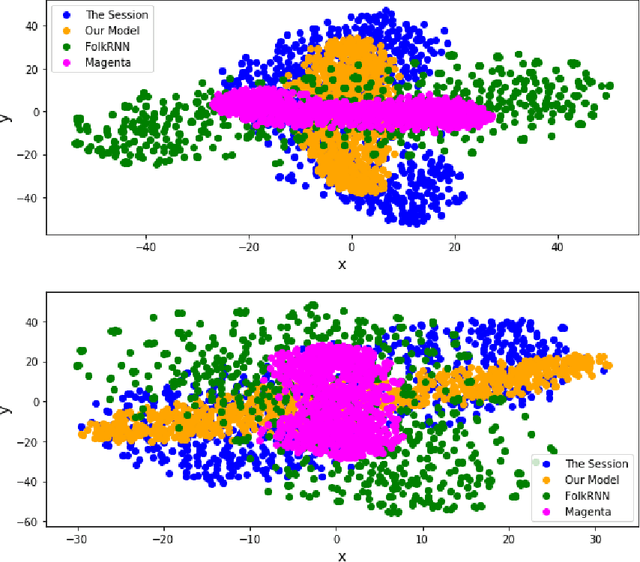
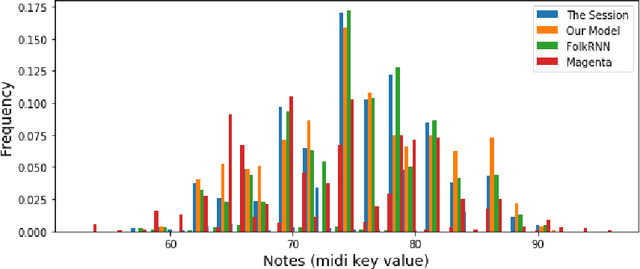
In this paper we present a method for algorithmic melody generation using a generative adversarial network without recurrent components. Music generation has been successfully done using recurrent neural networks, where the model learns sequence information that can help create authentic sounding melodies. Here, we use DC-GAN architecture with dilated convolutions and towers to capture sequential information as spatial image information, and learn long-range dependencies in fixed-length melody forms such as Irish traditional reel.
Beyond Statistical Relations: Integrating Knowledge Relations into Style Correlations for Multi-Label Music Style Classification
Nov 09, 2019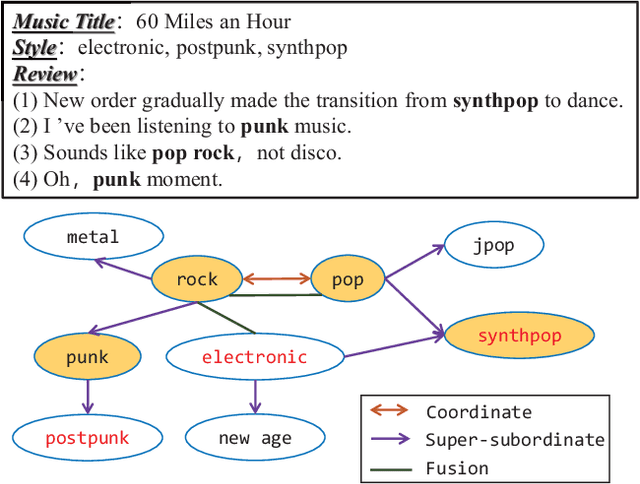
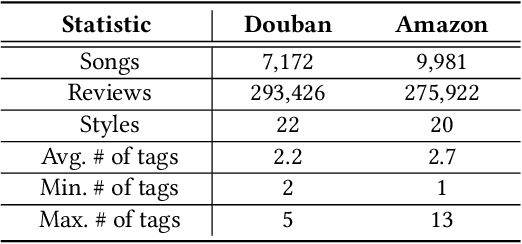
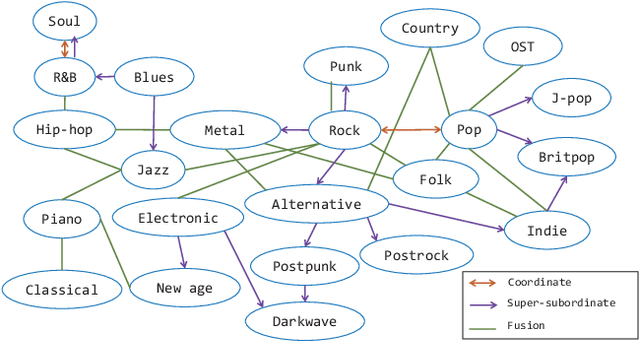
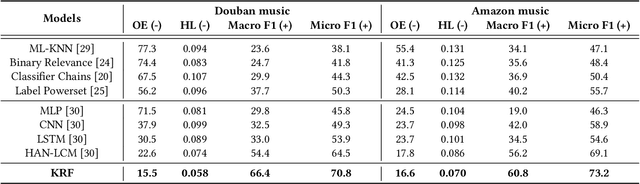
Automatically labeling multiple styles for every song is a comprehensive application in all kinds of music websites. Recently, some researches explore review-driven multi-label music style classification and exploit style correlations for this task. However, their methods focus on mining the statistical relations between different music styles and only consider shallow style relations. Moreover, these statistical relations suffer from the underfitting problem because some music styles have little training data. To tackle these problems, we propose a novel knowledge relations integrated framework (KRF) to capture the complete style correlations, which jointly exploits the inherent relations between music styles according to external knowledge and their statistical relations. Based on the two types of relations, we use graph convolutional network to learn the deep correlations between styles automatically. Experimental results show that our framework significantly outperforms state-of-the-art methods. Further studies demonstrate that our framework can effectively alleviate the underfitting problem and learn meaningful style correlations.
Constrained Policy Optimization for Controlled Self-Learning in Conversational AI Systems
Sep 17, 2022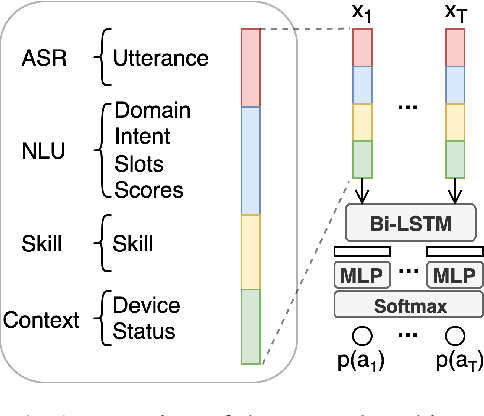
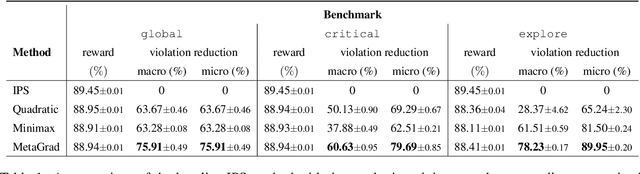

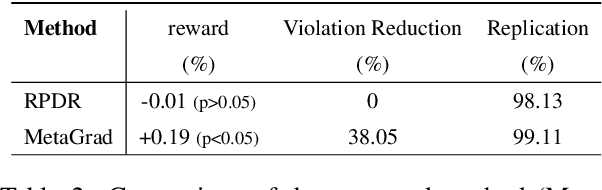
Recently, self-learning methods based on user satisfaction metrics and contextual bandits have shown promising results to enable consistent improvements in conversational AI systems. However, directly targeting such metrics by off-policy bandit learning objectives often increases the risk of making abrupt policy changes that break the current user experience. In this study, we introduce a scalable framework for supporting fine-grained exploration targets for individual domains via user-defined constraints. For example, we may want to ensure fewer policy deviations in business-critical domains such as shopping, while allocating more exploration budget to domains such as music. Furthermore, we present a novel meta-gradient learning approach that is scalable and practical to address this problem. The proposed method adjusts constraint violation penalty terms adaptively through a meta objective that encourages balanced constraint satisfaction across domains. We conduct extensive experiments using data from a real-world conversational AI on a set of realistic constraint benchmarks. Based on the experimental results, we demonstrate that the proposed approach is capable of achieving the best balance between the policy value and constraint satisfaction rate.
Machines listening to music: the role of signal representations in learning from music
Mar 27, 2019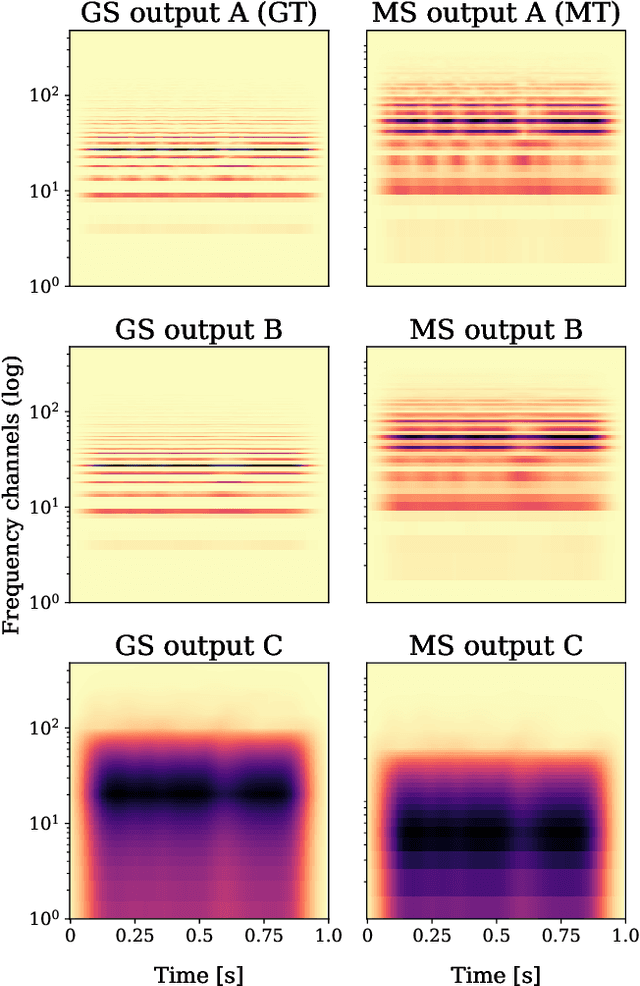
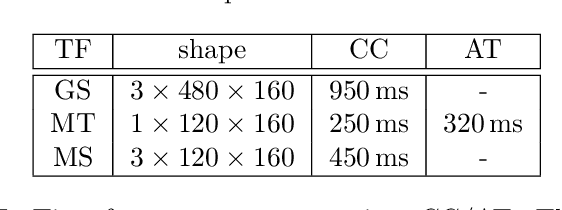
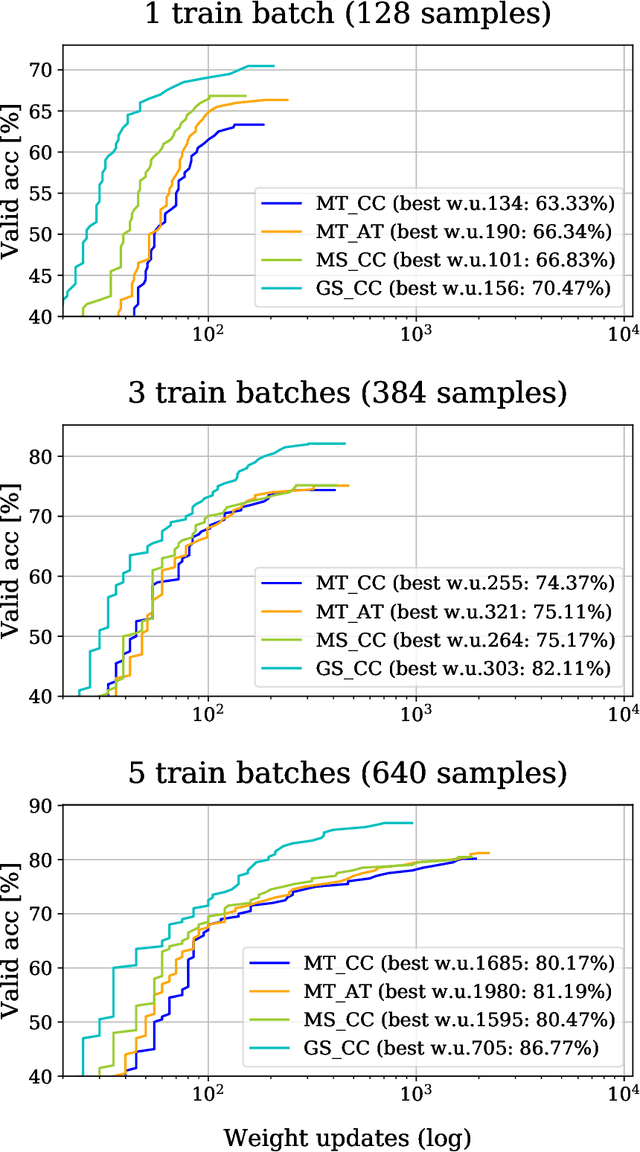
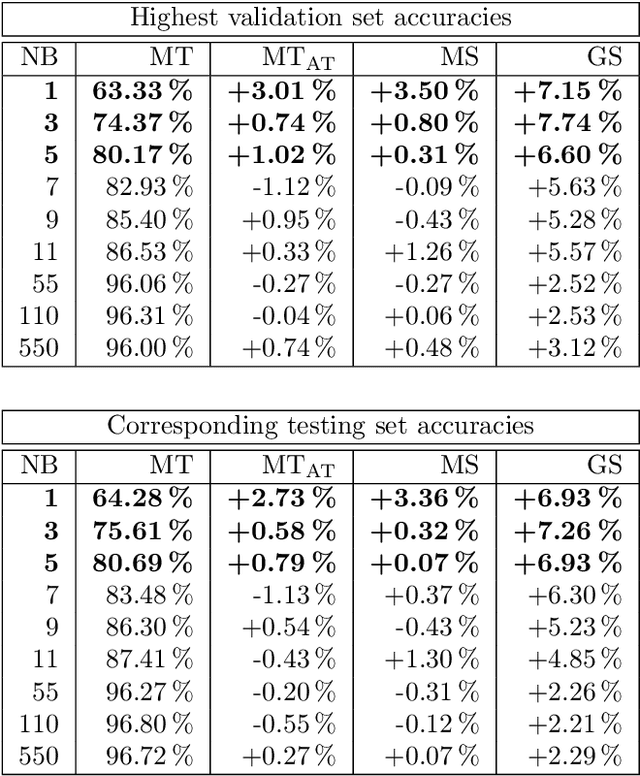
Recent, extremely successful methods in deep learning, such as convolutional neural networks (CNNs) have originated in machine learning for images. When applied to music signals and related music information retrieval (MIR) problems, researchers often apply standard FFT-based signal processing methods in order to create an image from the raw audio data. The impact of this basic signal processing step on the final outcome of the MIR task has not been widely studied and is not well understood. In this contribution, we study Gabor Scattering and a new representation, namely Mel Scattering. Furthermore, we suggest an alternative enhancement of the loss function that uses transformed representations of the output data to incorporate additional available information. We show how applying various different signal analysis methods can lead to useful invariances and improve the overall performance in MIR problems by reducing the amount of necessary training data or the necessity of augmentation.
Three more Decades in Array Signal Processing Research: An Optimization and Structure Exploitation Perspective
Oct 26, 2022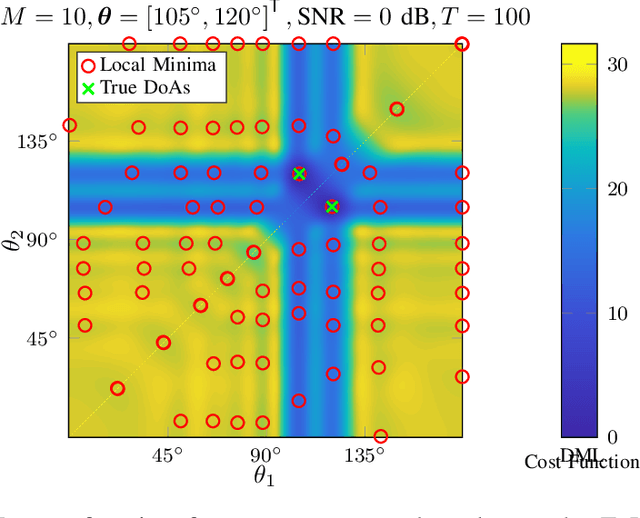
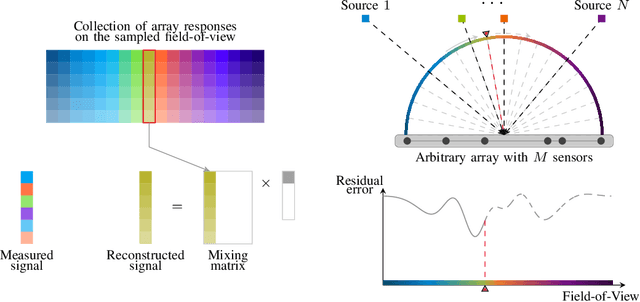
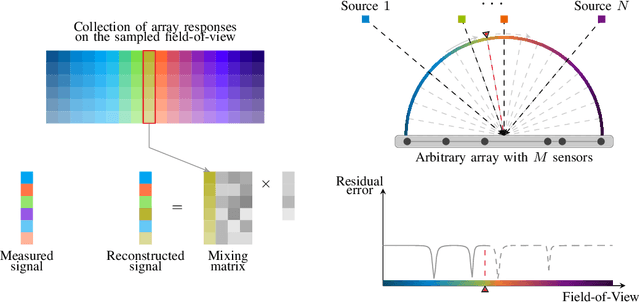
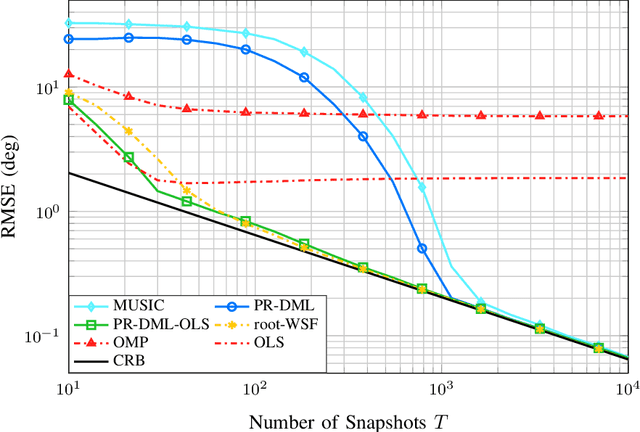
The signal processing community currently witnesses the emergence of sensor array processing and Direction-of-Arrival (DoA) estimation in various modern applications, such as automotive radar, mobile user and millimeter wave indoor localization, drone surveillance, as well as in new paradigms, such as joint sensing and communication in future wireless systems. This trend is further enhanced by technology leaps and availability of powerful and affordable multi-antenna hardware platforms. The history of advances in super resolution DoA estimation techniques is long, starting from the early parametric multi-source methods such as the computationally expensive maximum likelihood (ML) techniques to the early subspace-based techniques such as Pisarenko and MUSIC. Inspired by the seminal review paper Two Decades of Array Signal Processing Research: The Parametric Approach by Krim and Viberg published in the IEEE Signal Processing Magazine, we are looking back at another three decades in Array Signal Processing Research under the classical narrowband array processing model based on second order statistics. We revisit major trends in the field and retell the story of array signal processing from a modern optimization and structure exploitation perspective. In our overview, through prominent examples, we illustrate how different DoA estimation methods can be cast as optimization problems with side constraints originating from prior knowledge regarding the structure of the measurement system. Due to space limitations, our review of the DoA estimation research in the past three decades is by no means complete. For didactic reasons, we mainly focus on developments in the field that easily relate the traditional multi-source estimation criteria and choose simple illustrative examples.
From Context to Concept: Exploring Semantic Relationships in Music with Word2Vec
Nov 29, 2018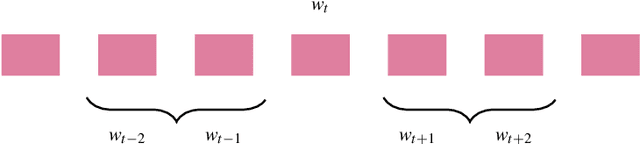

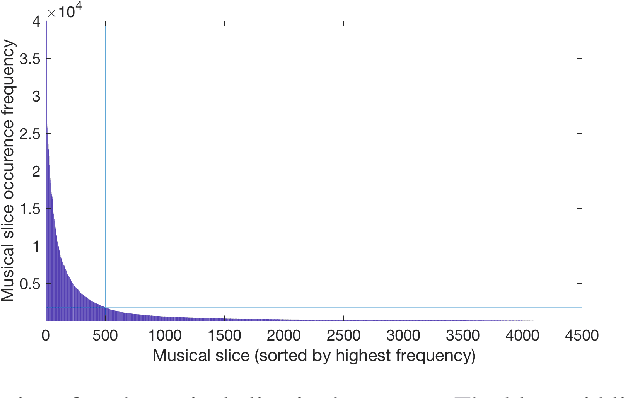
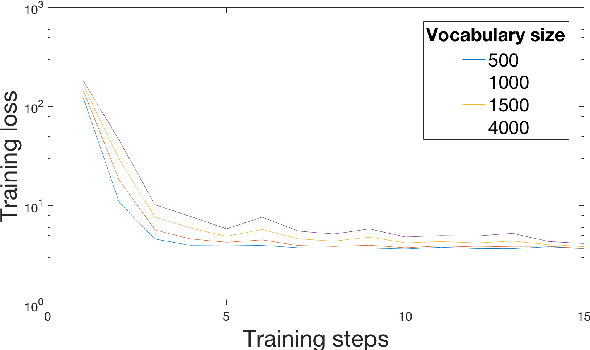
We explore the potential of a popular distributional semantics vector space model, word2vec, for capturing meaningful relationships in ecological (complex polyphonic) music. More precisely, the skip-gram version of word2vec is used to model slices of music from a large corpus spanning eight musical genres. In this newly learned vector space, a metric based on cosine distance is able to distinguish between functional chord relationships, as well as harmonic associations in the music. Evidence, based on cosine distance between chord-pair vectors, suggests that an implicit circle-of-fifths exists in the vector space. In addition, a comparison between pieces in different keys reveals that key relationships are represented in word2vec space. These results suggest that the newly learned embedded vector representation does in fact capture tonal and harmonic characteristics of music, without receiving explicit information about the musical content of the constituent slices. In order to investigate whether proximity in the discovered space of embeddings is indicative of `semantically-related' slices, we explore a music generation task, by automatically replacing existing slices from a given piece of music with new slices. We propose an algorithm to find substitute slices based on spatial proximity and the pitch class distribution inferred in the chosen subspace. The results indicate that the size of the subspace used has a significant effect on whether slices belonging to the same key are selected. In sum, the proposed word2vec model is able to learn music-vector embeddings that capture meaningful tonal and harmonic relationships in music, thereby providing a useful tool for exploring musical properties and comparisons across pieces, as a potential input representation for deep learning models, and as a music generation device.
* Accepted for publication in Neural Computing and Applications, Springer. In Press
Data-Augmented Counterfactual Learning for Bundle Recommendation
Oct 19, 2022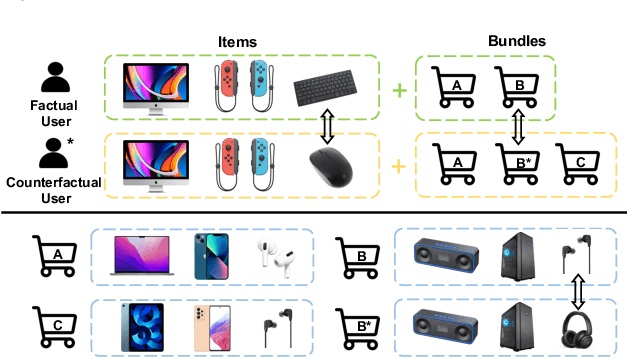
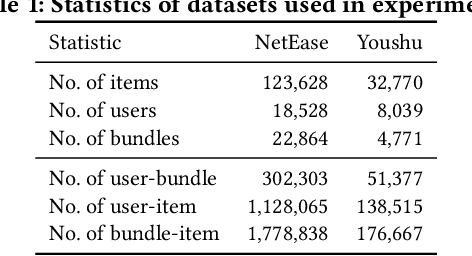
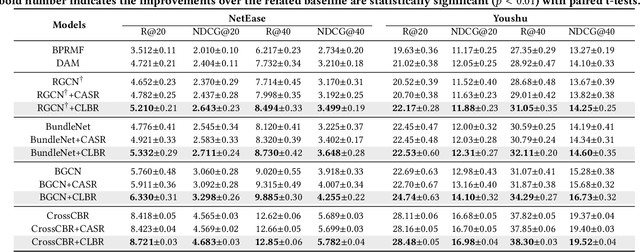
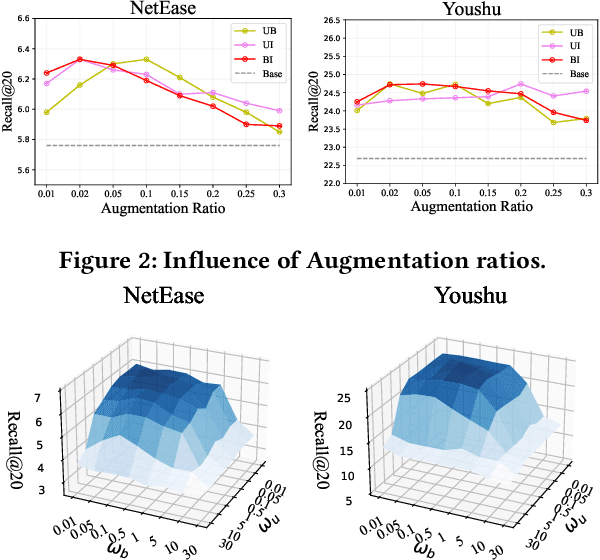
Bundle Recommendation (BR) aims at recommending bundled items on online content or e-commerce platform, such as song lists on a music platform or book lists on a reading website. Several graph based models have achieved state-of-the-art performance on BR task. But their performance is still sub-optimal, since the data sparsity problem tends to be more severe in real bundle recommendation scenarios, which limits graph-based models from more sufficient learning. In this paper, we propose a novel graph learning paradigm called Counterfactual Learning for Bundle Recommendation (CLBR) to mitigate the impact of data sparsity problem and improve bundle recommendation. Our paradigm consists of two main parts: counterfactual data augmentation and counterfactual constraint. The main idea of our paradigm lies in answering the counterfactual questions: "What would a user interact with if his/her interaction history changes?" "What would a user interact with if the bundle-item affiliation relations change?" In counterfactual data augmentation, we design a heuristic sampler to generate counterfactual graph views for graph-based models, which has better noise controlling than the stochastic sampler. We further propose counterfactual loss to constrain model learning for mitigating the effects of residual noise in augmented data and achieving more sufficient model optimization. Further theoretical analysis demonstrates the rationality of our design. Extensive experiments of BR models applied with our paradigm on two real-world datasets are conducted to verify the effectiveness of the paradigm