 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Listen to Your Favorite Melodies with img2Mxml, Producing MusicXML from Sheet Music Image by Measure-based Multimodal Deep Learning-driven Assembly
Jun 16, 2021
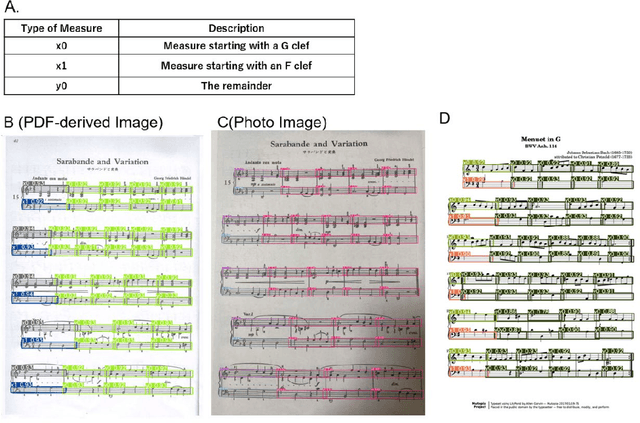

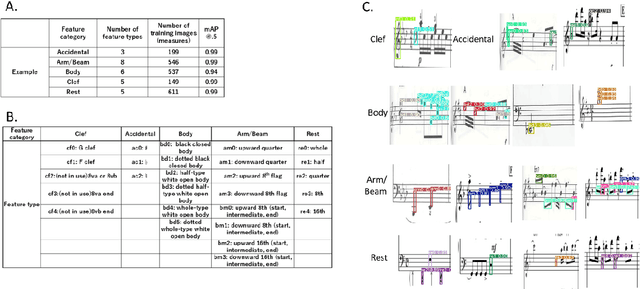
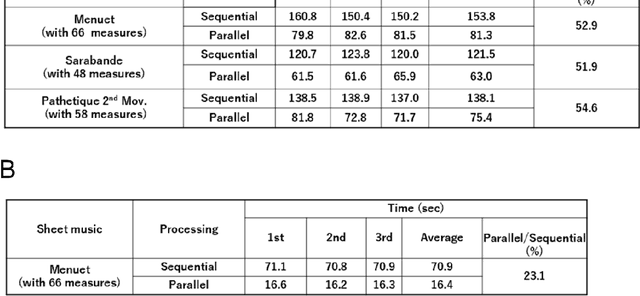
Deep learning has recently been applied to optical music recognition (OMR). However, currently OMR processing from various sheet music images still lacks precision to be widely applicable. Here, we present an MMdA (Measure-based Multimodal deep learning (DL)-driven Assembly) method allowing for end-to-end OMR processing from various images including inclined photo images. Using this method, measures are extracted by a deep learning model, aligned, and resized to be used for inference of given musical symbol components by using multiple deep learning models in sequence or in parallel. Use of each standardized measure enables efficient training of the models and accurate adjustment of five staff lines in each measure. Multiple musical symbol component category models with a small number of feature types can represent a diverse set of notes and other musical symbols including chords. This MMdA method provides a solution to end-to-end OMR processing with precision.
Bach2Bach: Generating Music Using A Deep Reinforcement Learning Approach
Dec 03, 2018
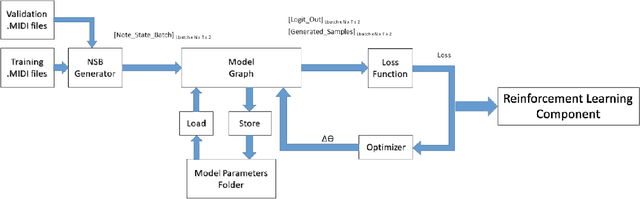
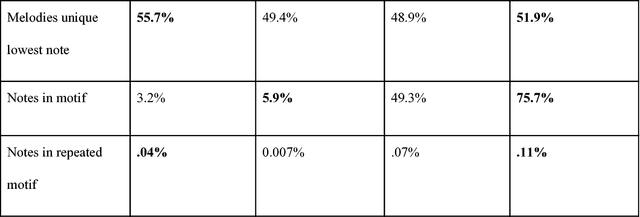
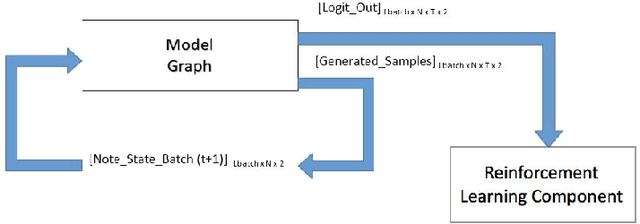
A model of music needs to have the ability to recall past details and have a clear, coherent understanding of musical structure. Detailed in the paper is a deep reinforcement learning architecture that predicts and generates polyphonic music aligned with musical rules. The probabilistic model presented is a Bi-axial LSTM trained with a pseudo-kernel reminiscent of a convolutional kernel. To encourage exploration and impose greater global coherence on the generated music, a deep reinforcement learning approach DQN is adopted. When analyzed quantitatively and qualitatively, this approach performs well in composing polyphonic music.
Toward Interpretable Music Tagging with Self-Attention
Jun 12, 2019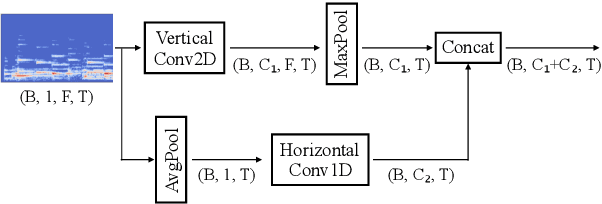
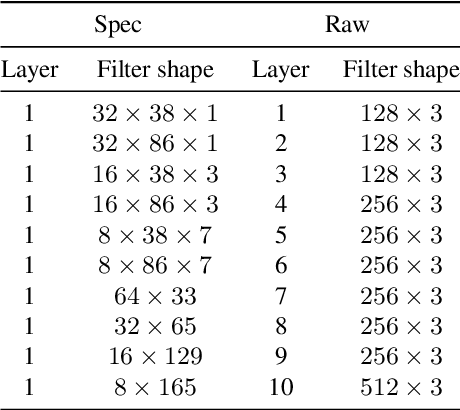
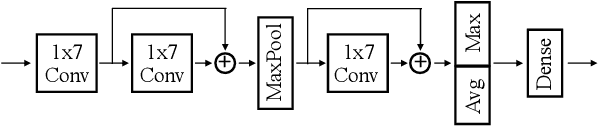
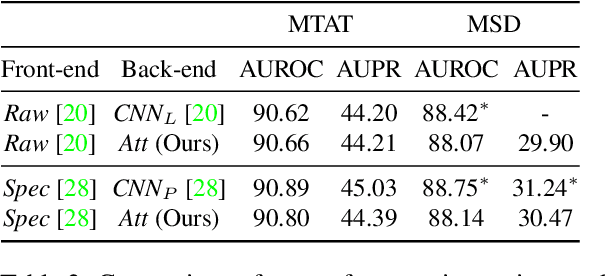
Self-attention is an attention mechanism that learns a representation by relating different positions in the sequence. The transformer, which is a sequence model solely based on self-attention, and its variants achieved state-of-the-art results in many natural language processing tasks. Since music composes its semantics based on the relations between components in sparse positions, adopting the self-attention mechanism to solve music information retrieval (MIR) problems can be beneficial. Hence, we propose a self-attention based deep sequence model for music tagging. The proposed architecture consists of shallow convolutional layers followed by stacked Transformer encoders. Compared to conventional approaches using fully convolutional or recurrent neural networks, our model is more interpretable while reporting competitive results. We validate the performance of our model with the MagnaTagATune and the Million Song Dataset. In addition, we demonstrate the interpretability of the proposed architecture with a heat map visualization.
A holistic approach to polyphonic music transcription with neural networks
Oct 26, 2019
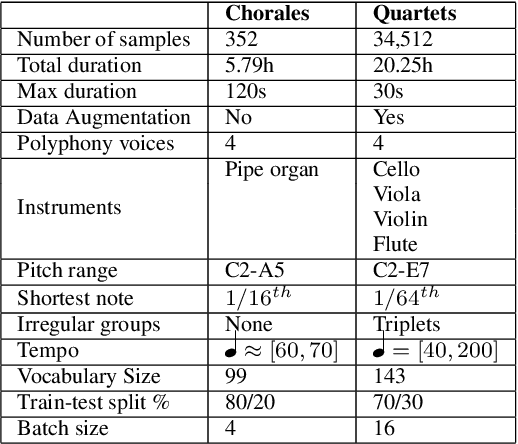
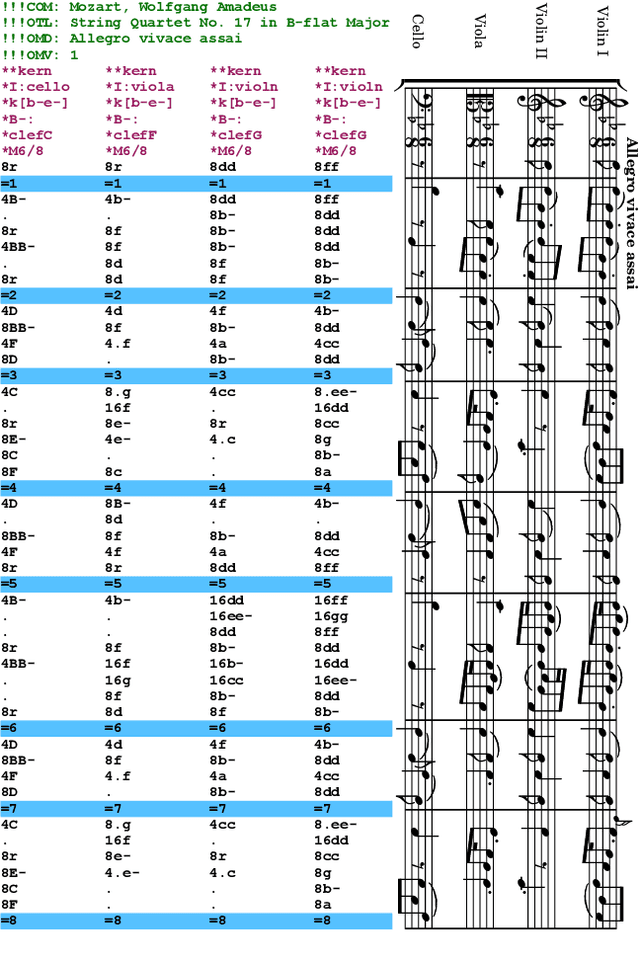
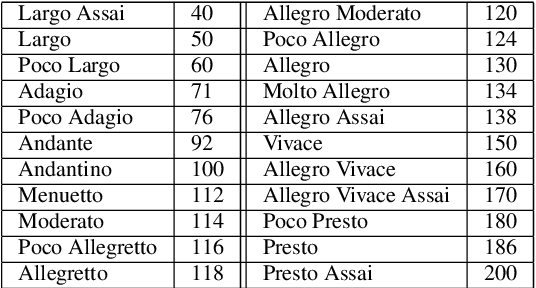
We present a framework based on neural networks to extract music scores directly from polyphonic audio in an end-to-end fashion. Most previous Automatic Music Transcription (AMT) methods seek a piano-roll representation of the pitches, that can be further transformed into a score by incorporating tempo estimation, beat tracking, key estimation or rhythm quantization. Unlike these methods, our approach generates music notation directly from the input audio in a single stage. For this, we use a Convolutional Recurrent Neural Network (CRNN) with Connectionist Temporal Classification (CTC) loss function which does not require annotated alignments of audio frames with the score rhythmic information. We trained our model using as input Haydn, Mozart, and Beethoven string quartets and Bach chorales synthesized with different tempos and expressive performances. The output is a textual representation of four-voice music scores based on **kern format. Although the proposed approach is evaluated in a simplified scenario, results show that this model can learn to transcribe scores directly from audio signals, opening a promising avenue towards complete AMT.
High Fidelity Neural Audio Compression
Oct 24, 2022
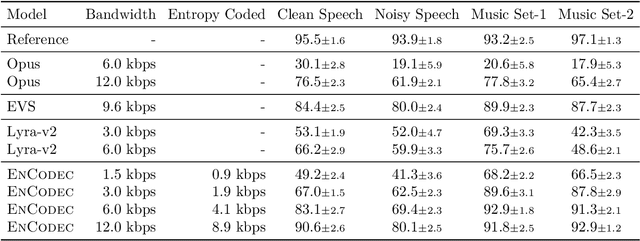
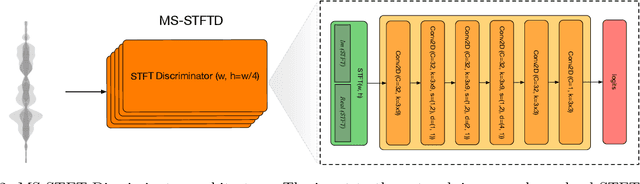
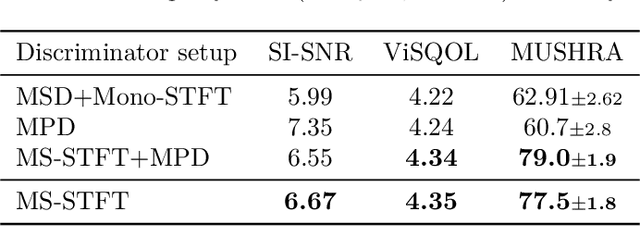
We introduce a state-of-the-art real-time, high-fidelity, audio codec leveraging neural networks. It consists in a streaming encoder-decoder architecture with quantized latent space trained in an end-to-end fashion. We simplify and speed-up the training by using a single multiscale spectrogram adversary that efficiently reduces artifacts and produce high-quality samples. We introduce a novel loss balancer mechanism to stabilize training: the weight of a loss now defines the fraction of the overall gradient it should represent, thus decoupling the choice of this hyper-parameter from the typical scale of the loss. Finally, we study how lightweight Transformer models can be used to further compress the obtained representation by up to 40%, while staying faster than real time. We provide a detailed description of the key design choices of the proposed model including: training objective, architectural changes and a study of various perceptual loss functions. We present an extensive subjective evaluation (MUSHRA tests) together with an ablation study for a range of bandwidths and audio domains, including speech, noisy-reverberant speech, and music. Our approach is superior to the baselines methods across all evaluated settings, considering both 24 kHz monophonic and 48 kHz stereophonic audio. Code and models are available at github.com/facebookresearch/encodec.
Polyphonic Music Composition with LSTM Neural Networks and Reinforcement Learning
Mar 03, 2019
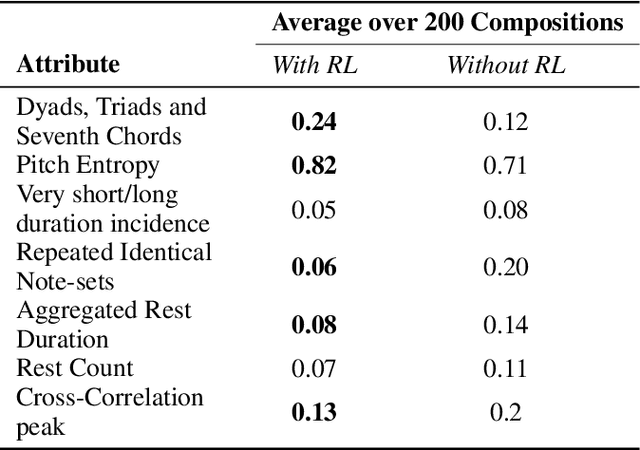

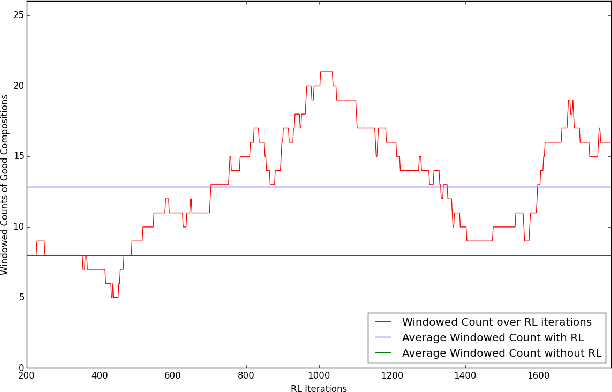
In the domain of algorithmic music composition, machine learning-driven systems eliminate the need for carefully hand-crafting rules for composition. In particular, the capability of recurrent neural networks to learn complex temporal patterns lends itself well to the musical domain. Promising results have been observed across a number of recent attempts at music composition using deep RNNs. These approaches generally aim at first training neural networks to reproduce subsequences drawn from existing songs. Subsequently, they are used to compose music either at the audio sample-level or at the note-level. We designed a representation that divides polyphonic music into a small number of monophonic streams. This representation greatly reduces the complexity of the problem and eliminates an exponential number of probably poor compositions. On top of our LSTM neural network that learnt musical sequences in this representation, we built an RL agent that learnt to find combinations of songs whose joint dominance produced pleasant compositions. We present Amadeus, an algorithmic music composition system that composes music that consists of intricate melodies, basic chords, and even occasional contrapuntal sequences.
Now Playing: Continuous low-power music recognition
Nov 29, 2017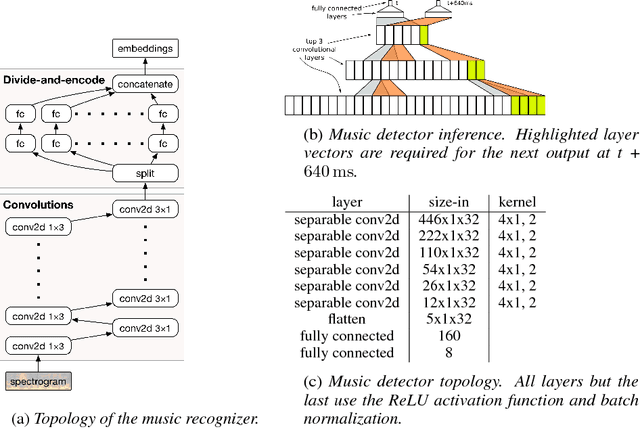
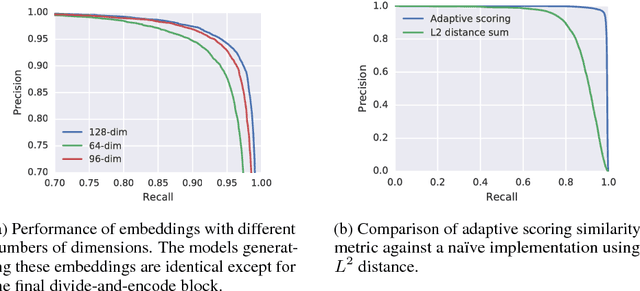
Existing music recognition applications require a connection to a server that performs the actual recognition. In this paper we present a low-power music recognizer that runs entirely on a mobile device and automatically recognizes music without user interaction. To reduce battery consumption, a small music detector runs continuously on the mobile device's DSP chip and wakes up the main application processor only when it is confident that music is present. Once woken, the recognizer on the application processor is provided with a few seconds of audio which is fingerprinted and compared to the stored fingerprints in the on-device fingerprint database of tens of thousands of songs. Our presented system, Now Playing, has a daily battery usage of less than 1% on average, respects user privacy by running entirely on-device and can passively recognize a wide range of music.
Classical Music Prediction and Composition by means of Variational Autoencoders
Jun 21, 2019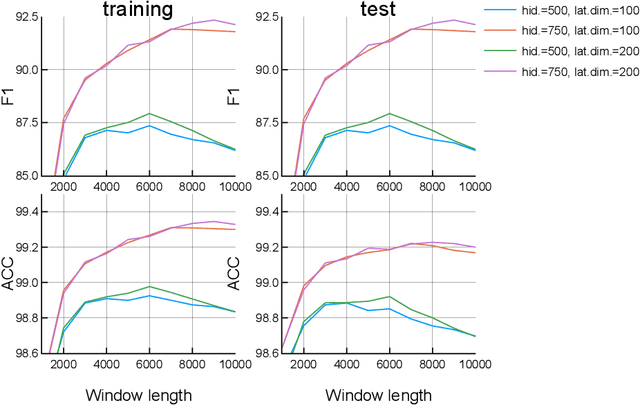

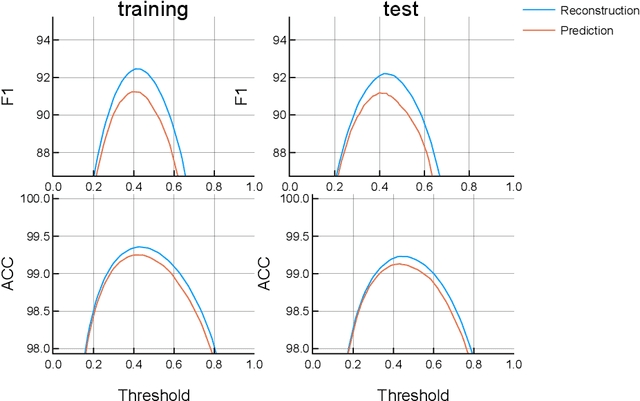
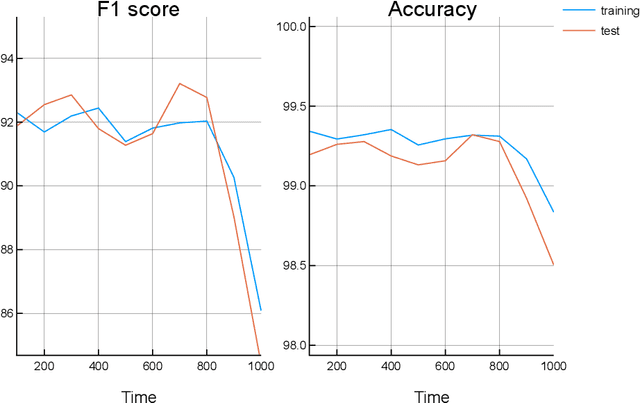
This paper proposes a new model for music prediction based on Variational Autoencoders (VAEs). In this work, VAEs are used in a novel way in order to address two different problems: music representation into the latent space, and using this representation to make predictions of the future values of the musical piece. This approach was trained with different songs of a classical composer. As a result, the system can represent the music in the latent space, and make accurate predictions. Therefore, the system can be used to compose new music either from an existing piece or from a random starting point. An additional feature of this system is that a small dataset was used for training. However, results show that the system is able to return accurate representations and predictions in unseen data.
Multi-modal Conditional Bounding Box Regression for Music Score Following
May 10, 2021
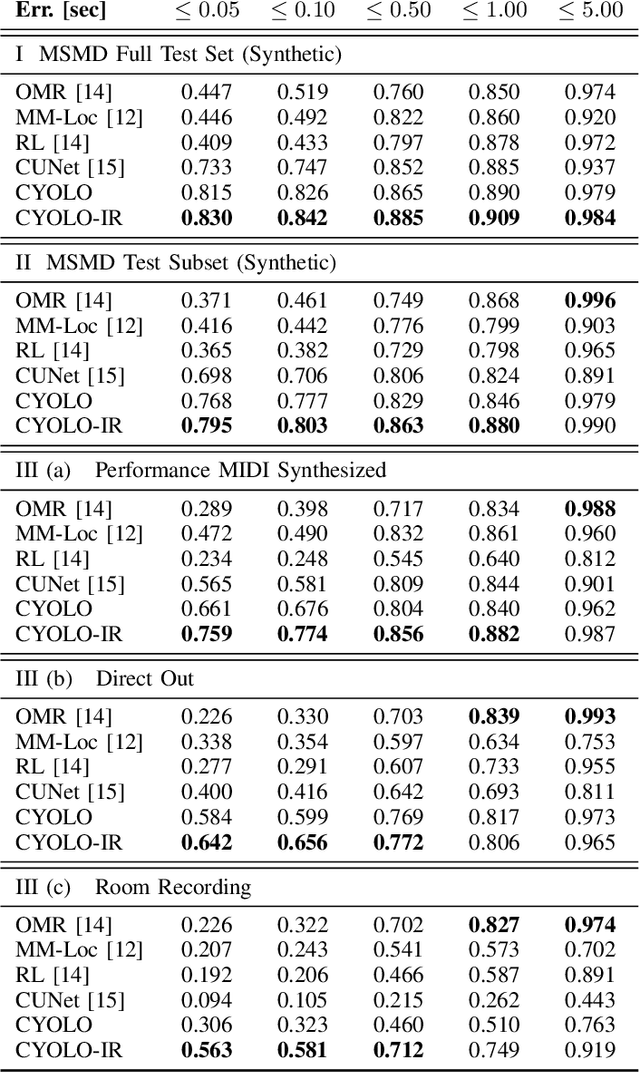
This paper addresses the problem of sheet-image-based on-line audio-to-score alignment also known as score following. Drawing inspiration from object detection, a conditional neural network architecture is proposed that directly predicts x,y coordinates of the matching positions in a complete score sheet image at each point in time for a given musical performance. Experiments are conducted on a synthetic polyphonic piano benchmark dataset and the new method is compared to several existing approaches from the literature for sheet-image-based score following as well as an Optical Music Recognition baseline. The proposed approach achieves new state-of-the-art results and furthermore significantly improves the alignment performance on a set of real-world piano recordings by applying Impulse Responses as a data augmentation technique.
The Impact of Label Noise on a Music Tagger
Aug 14, 2020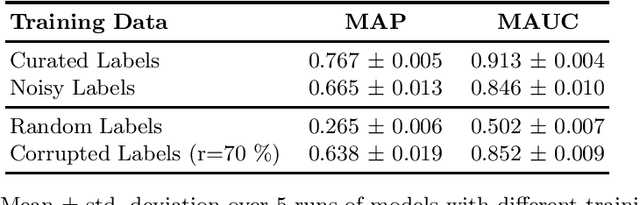
We explore how much can be learned from noisy labels in audio music tagging. Our experiments show that carefully annotated labels result in highest figures of merit, but even high amounts of noisy labels contain enough information for successful learning. Artificial corruption of curated data allows us to quantize this contribution of noisy labels.