 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Machine learning for music genre: multifaceted review and experimentation with audioset
Nov 28, 2019
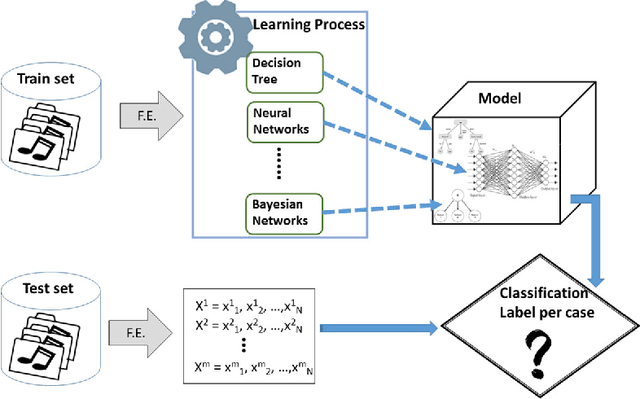
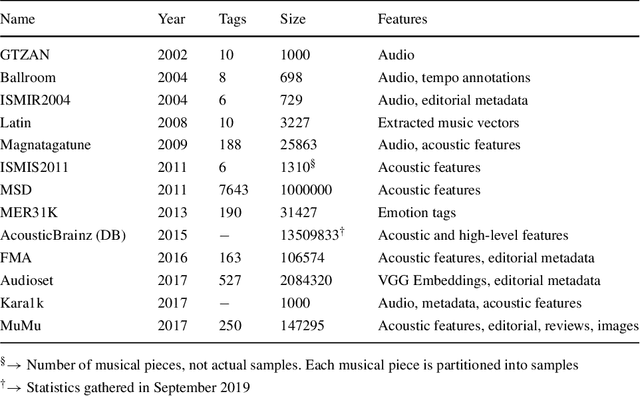
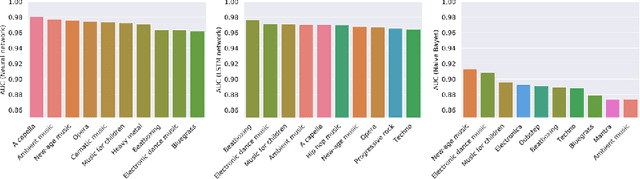
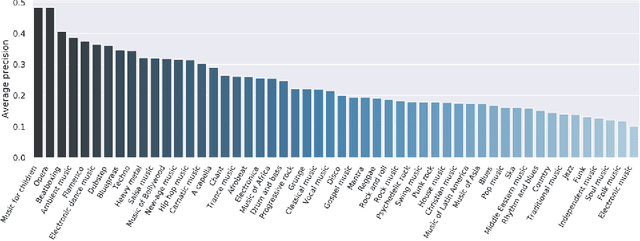
Music genre classification is one of the sub-disciplines of music information retrieval (MIR) with growing popularity among researchers, mainly due to the already open challenges. Although research has been prolific in terms of number of published works, the topic still suffers from a problem in its foundations: there is no clear and formal definition of what genre is. Music categorizations are vague and unclear, suffering from human subjectivity and lack of agreement. In its first part, this paper offers a survey trying to cover the many different aspects of the matter. Its main goal is give the reader an overview of the history and the current state-of-the-art, exploring techniques and datasets used to the date, as well as identifying current challenges, such as this ambiguity of genre definitions or the introduction of human-centric approaches. The paper pays special attention to new trends in machine learning applied to the music annotation problem. Finally, we also include a music genre classification experiment that compares different machine learning models using Audioset.
MMM : Exploring Conditional Multi-Track Music Generation with the Transformer
Aug 20, 2020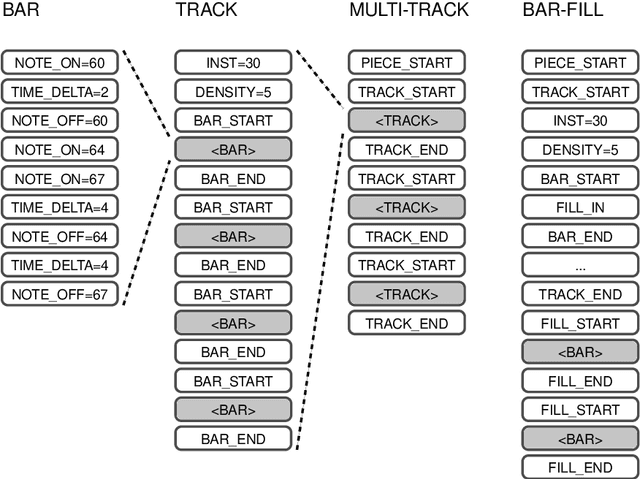
We propose the Multi-Track Music Machine (MMM), a generative system based on the Transformer architecture that is capable of generating multi-track music. In contrast to previous work, which represents musical material as a single time-ordered sequence, where the musical events corresponding to different tracks are interleaved, we create a time-ordered sequence of musical events for each track and concatenate several tracks into a single sequence. This takes advantage of the Transformer's attention-mechanism, which can adeptly handle long-term dependencies. We explore how various representations can offer the user a high degree of control at generation time, providing an interactive demo that accommodates track-level and bar-level inpainting, and offers control over track instrumentation and note density.
Generating Music with a Self-Correcting Non-Chronological Autoregressive Model
Aug 18, 2020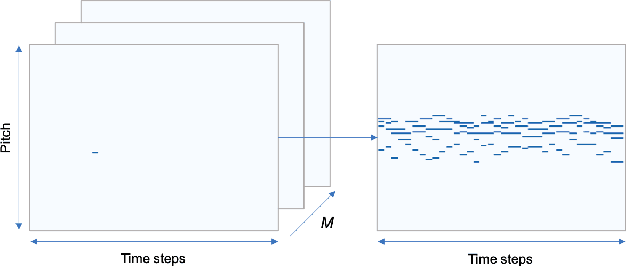

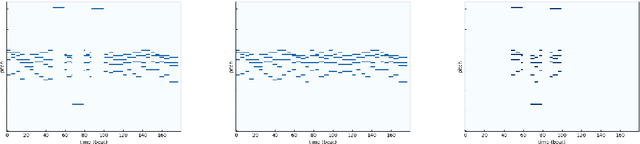
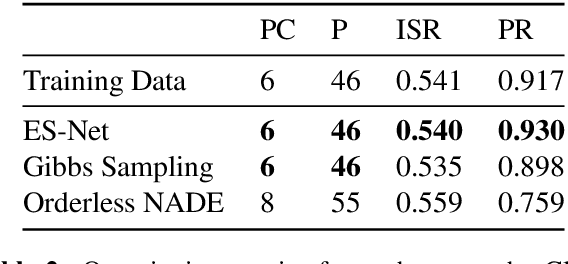
We describe a novel approach for generating music using a self-correcting, non-chronological, autoregressive model. We represent music as a sequence of edit events, each of which denotes either the addition or removal of a note---even a note previously generated by the model. During inference, we generate one edit event at a time using direct ancestral sampling. Our approach allows the model to fix previous mistakes such as incorrectly sampled notes and prevent accumulation of errors which autoregressive models are prone to have. Another benefit is a finer, note-by-note control during human and AI collaborative composition. We show through quantitative metrics and human survey evaluation that our approach generates better results than orderless NADE and Gibbs sampling approaches.
Joint Blind Room Acoustic Characterization From Speech And Music Signals Using Convolutional Recurrent Neural Networks
Oct 21, 2020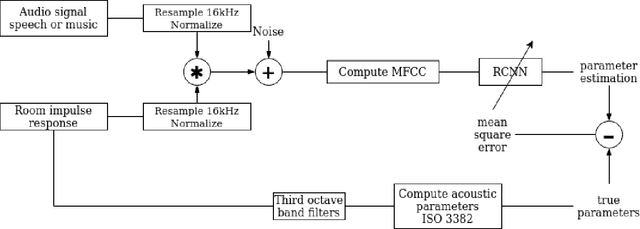
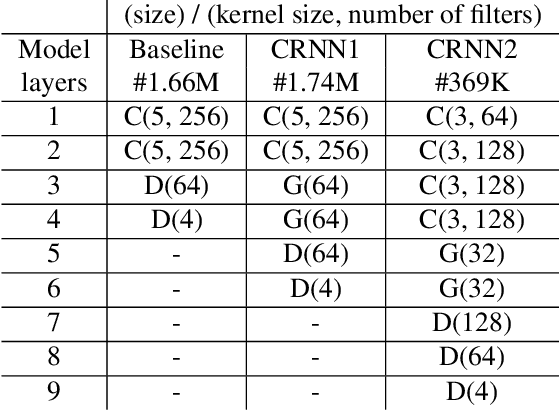
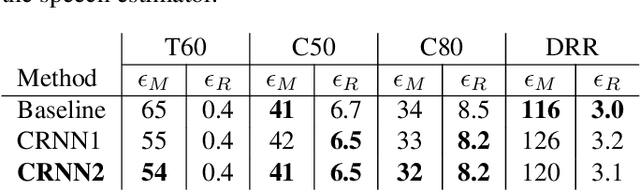
Acoustic environment characterization opens doors for sound reproduction innovations, smart EQing, speech enhancement, hearing aids, and forensics. Reverberation time, clarity, and direct-to-reverberant ratio are acoustic parameters that have been defined to describe reverberant environments. They are closely related to speech intelligibility and sound quality. As explained in the ISO3382 standard, they can be derived from a room measurement called the Room Impulse Response (RIR). However, measuring RIRs requires specific equipment and intrusive sound to be played. The recent audio combined with machine learning suggests that one could estimate those parameters blindly using speech or music signals. We follow these advances and propose a robust end-to-end method to achieve blind joint acoustic parameter estimation using speech and/or music signals. Our results indicate that convolutional recurrent neural networks perform best for this task, and including music in training also helps improve inference from speech.
3D Localization with a Single Partially-Connected Receiving RIS: Positioning Error Analysis and Algorithmic Design
Dec 05, 2022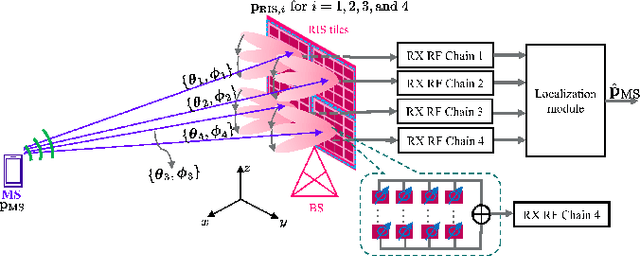
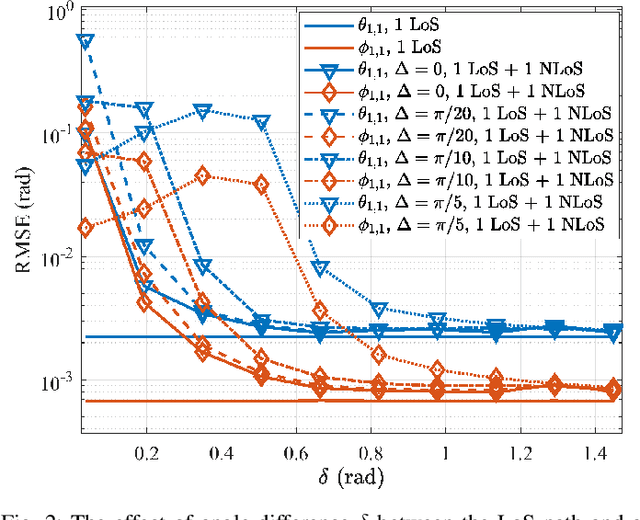
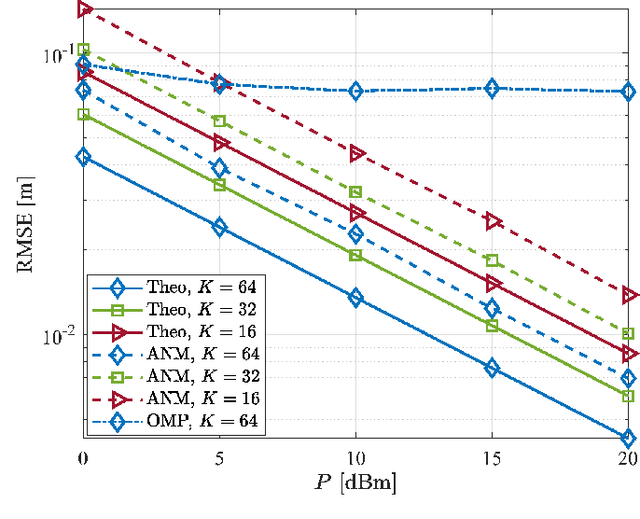
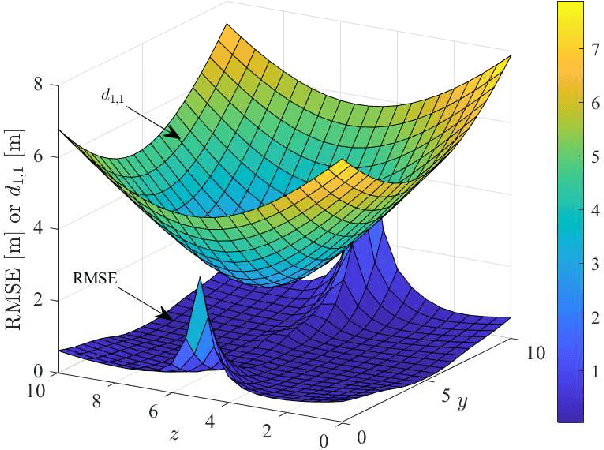
In this paper, we introduce the concept of partially-connected Receiving Reconfigurable Intelligent Surfaces (R-RISs), which refers to metasurfaces designed to efficiently sense electromagnetic waveforms impinging on them, and perform localization of the users emitting them. The presented R-RIS hardware architecture comprises subarrays of meta-atoms, with each of them incorporating a waveguide assigned to direct the waveforms reaching its meta-atoms to a reception Radio-Frequency (RF) chain, enabling signal/channel parameter estimation. We particularly focus on the scenarios where the user is located in the far-field of all the R-RIS subarrays, and present a three-Dimensional (3D) localization method which is based on narrowband signaling and Angle of Arrival (AoA) estimates of the impinging signals at each single-receive-RF R-RIS subarray. For the AoA estimation, which relies on spatially sampled versions of the received signals via each subarray's phase configuration of meta-atoms, we devise an off-grid atomic norm minimization approach, which is followed by subspace-based root MUltiple SIgnal Classification (MUSIC). The AoA estimates are finally combined via a least-squared line intersection method to obtain the position coordinates of a user emitting synchronized localization pilots. Our derived theoretical Cram\'er Rao Lower Bounds (CRLBs) on the estimation parameters, which are compared with extensive computer simulation results of our localization approach, verify the effectiveness of the proposed R-RIS-empowered 3D localization system, which is showcased to offer cm-level positioning accuracy. Our comprehensive performance evaluations also demonstrate the impact of various system parameters on the localization performance, namely the training overhead and the distance between the R-RIS and the user, as well as the spacing among the R-RIS's subarrays and its partitioning patterns.
Integrated Parameter-Efficient Tuning for General-Purpose Audio Models
Nov 04, 2022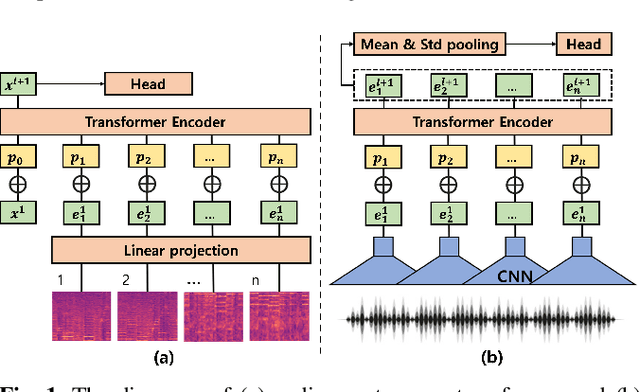
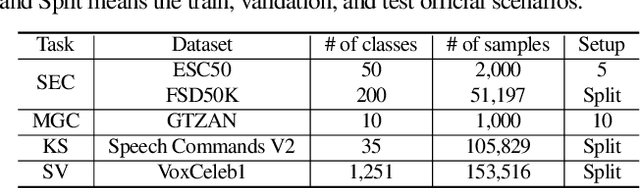
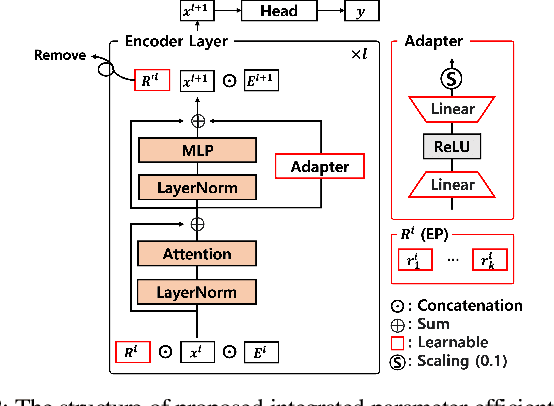
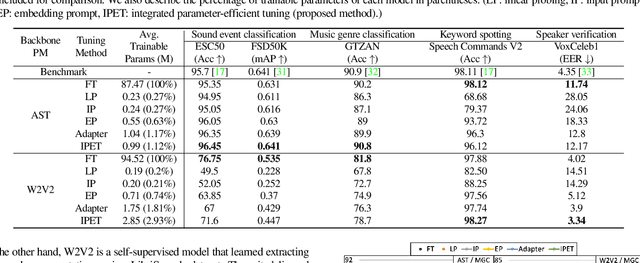
The advent of hyper-scale and general-purpose pre-trained models is shifting the paradigm of building task-specific models for target tasks. In the field of audio research, task-agnostic pre-trained models with high transferability and adaptability have achieved state-of-the-art performances through fine-tuning for downstream tasks. Nevertheless, re-training all the parameters of these massive models entails an enormous amount of time and cost, along with a huge carbon footprint. To overcome these limitations, the present study explores and applies efficient transfer learning methods in the audio domain. We also propose an integrated parameter-efficient tuning (IPET) framework by aggregating the embedding prompt (a prompt-based learning approach), and the adapter (an effective transfer learning method). We demonstrate the efficacy of the proposed framework using two backbone pre-trained audio models with different characteristics: the audio spectrogram transformer and wav2vec 2.0. The proposed IPET framework exhibits remarkable performance compared to fine-tuning method with fewer trainable parameters in four downstream tasks: sound event classification, music genre classification, keyword spotting, and speaker verification. Furthermore, the authors identify and analyze the shortcomings of the IPET framework, providing lessons and research directions for parameter efficient tuning in the audio domain.
Multitask learning for instrument activation aware music source separation
Aug 03, 2020



Music source separation is a core task in music information retrieval which has seen a dramatic improvement in the past years. Nevertheless, most of the existing systems focus exclusively on the problem of source separation itself and ignore the utilization of other~---possibly related---~MIR tasks which could lead to additional quality gains. In this work, we propose a novel multitask structure to investigate using instrument activation information to improve source separation performance. Furthermore, we investigate our system on six independent instruments, a more realistic scenario than the three instruments included in the widely-used MUSDB dataset, by leveraging a combination of the MedleyDB and Mixing Secrets datasets. The results show that our proposed multitask model outperforms the baseline Open-Unmix model on the mixture of Mixing Secrets and MedleyDB dataset while maintaining comparable performance on the MUSDB dataset.
musicnn: Pre-trained convolutional neural networks for music audio tagging
Sep 14, 2019Pronounced as "musician", the musicnn library contains a set of pre-trained musically motivated convolutional neural networks for music audio tagging: https://github.com/jordipons/musicnn. This repository also includes some pre-trained vgg-like baselines. These models can be used as out-of-the-box music audio taggers, as music feature extractors, or as pre-trained models for transfer learning. We also provide the code to train the aforementioned models: https://github.com/jordipons/musicnn-training. This framework also allows implementing novel models. For example, a musically motivated convolutional neural network with an attention-based output layer (instead of the temporal pooling layer) can achieve state-of-the-art results for music audio tagging: 90.77 ROC-AUC / 38.61 PR-AUC on the MagnaTagATune dataset --- and 88.81 ROC-AUC / 31.51 PR-AUC on the Million Song Dataset.
Musical Audio Similarity with Self-supervised Convolutional Neural Networks
Feb 04, 2022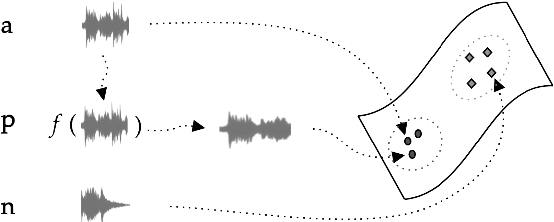
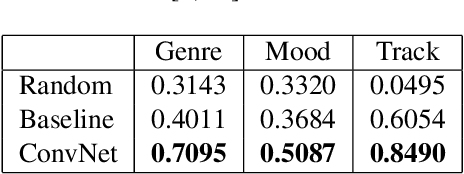
We have built a music similarity search engine that lets video producers search by listenable music excerpts, as a complement to traditional full-text search. Our system suggests similar sounding track segments in a large music catalog by training a self-supervised convolutional neural network with triplet loss terms and musical transformations. Semi-structured user interviews demonstrate that we can successfully impress professional video producers with the quality of the search experience, and perceived similarities to query tracks averaged 7.8/10 in user testing. We believe this search tool will make for a more natural search experience that is easier to find music to soundtrack videos with.