 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
SampleMatch: Drum Sample Retrieval by Musical Context
Aug 01, 2022
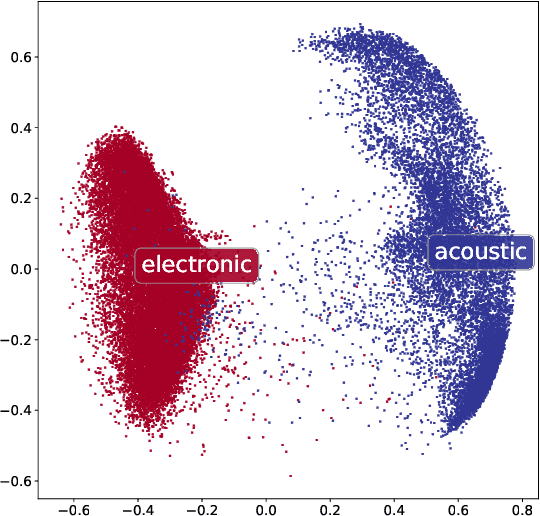
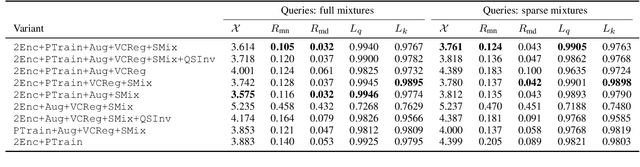
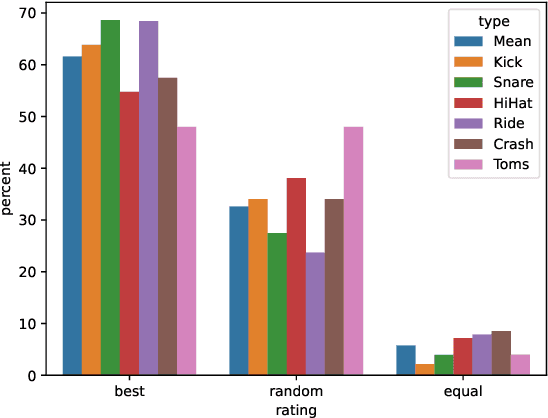
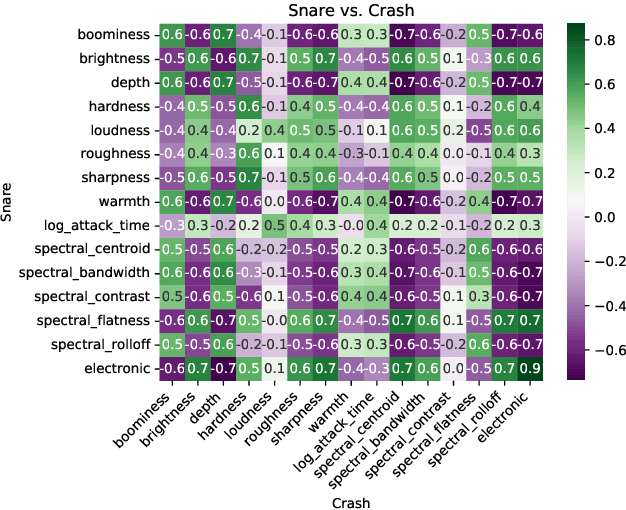
Modern digital music production typically involves combining numerous acoustic elements to compile a piece of music. Important types of such elements are drum samples, which determine the characteristics of the percussive components of the piece. Artists must use their aesthetic judgement to assess whether a given drum sample fits the current musical context. However, selecting drum samples from a potentially large library is tedious and may interrupt the creative flow. In this work, we explore the automatic drum sample retrieval based on aesthetic principles learned from data. As a result, artists can rank the samples in their library by fit to some musical context at different stages of the production process (i.e., by fit to incomplete song mixtures). To this end, we use contrastive learning to maximize the score of drum samples originating from the same song as the mixture. We conduct a listening test to determine whether the human ratings match the automatic scoring function. We also perform objective quantitative analyses to evaluate the efficacy of our approach.
MuseMorphose: Full-Song and Fine-Grained Music Style Transfer with Just One Transformer VAE
May 10, 2021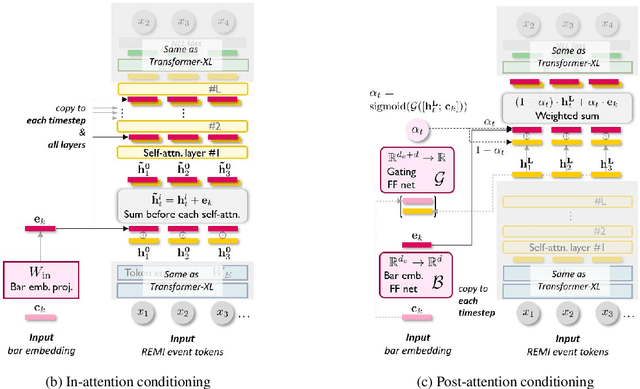

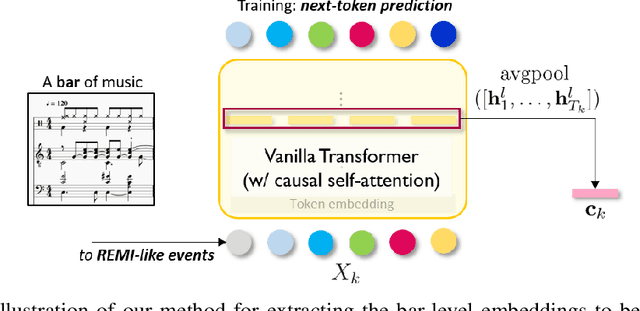

Transformers and variational autoencoders (VAE) have been extensively employed for symbolic (e.g., MIDI) domain music generation. While the former boast an impressive capability in modeling long sequences, the latter allow users to willingly exert control over different parts (e.g., bars) of the music to be generated. In this paper, we are interested in bringing the two together to construct a single model that exhibits both strengths. The task is split into two steps. First, we equip Transformer decoders with the ability to accept segment-level, time-varying conditions during sequence generation. Subsequently, we combine the developed and tested in-attention decoder with a Transformer encoder, and train the resulting MuseMorphose model with the VAE objective to achieve style transfer of long musical pieces, in which users can specify musical attributes including rhythmic intensity and polyphony (i.e., harmonic fullness) they desire, down to the bar level. Experiments show that MuseMorphose outperforms recurrent neural network (RNN) based prior art on numerous widely-used metrics for style transfer tasks.
Carousel Personalization in Music Streaming Apps with Contextual Bandits
Sep 14, 2020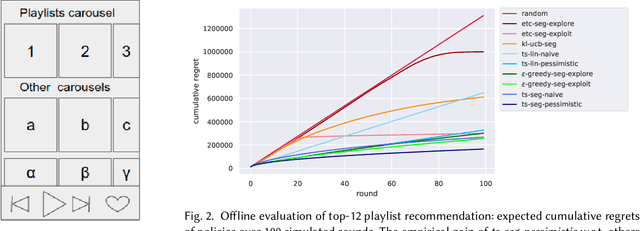
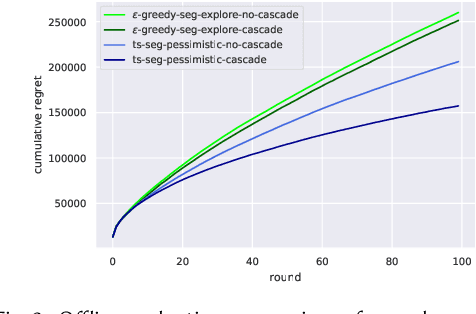
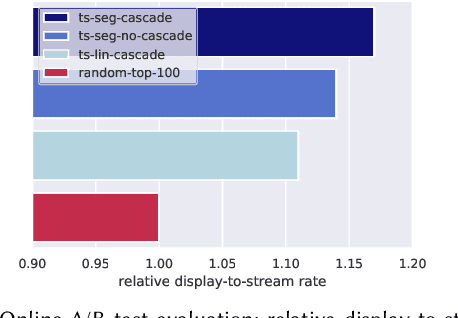
Media services providers, such as music streaming platforms, frequently leverage swipeable carousels to recommend personalized content to their users. However, selecting the most relevant items (albums, artists, playlists...) to display in these carousels is a challenging task, as items are numerous and as users have different preferences. In this paper, we model carousel personalization as a contextual multi-armed bandit problem with multiple plays, cascade-based updates and delayed batch feedback. We empirically show the effectiveness of our framework at capturing characteristics of real-world carousels by addressing a large-scale playlist recommendation task on a global music streaming mobile app. Along with this paper, we publicly release industrial data from our experiments, as well as an open-source environment to simulate comparable carousel personalization learning problems.
A measurement decoupling based fast algorithm for super-resolving point sources with multi-cluster structure
Apr 01, 2022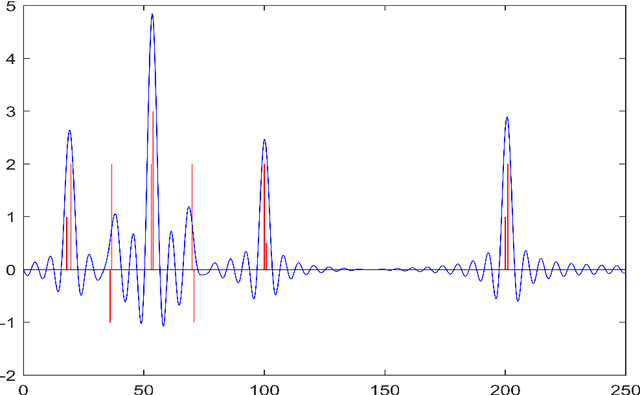
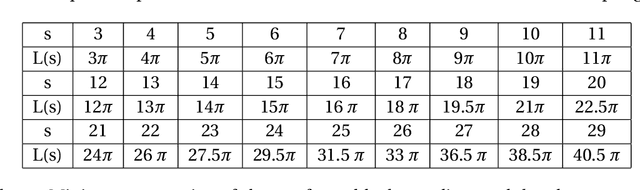
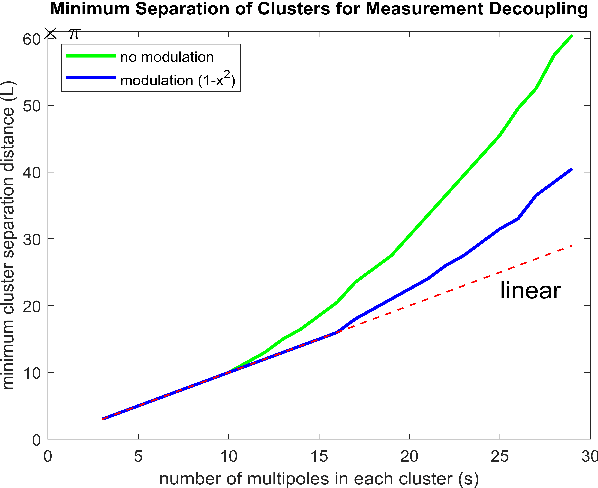
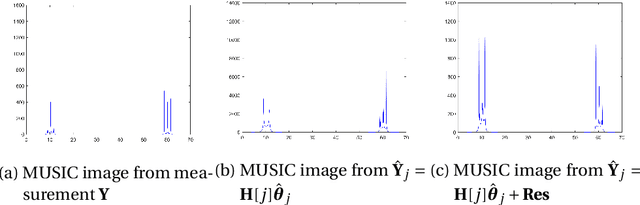
We consider the problem of resolving closely spaced point sources in one dimension from their Fourier data in a bounded domain. Classical subspace methods (e.g., MUSIC algorithm, Matrix Pencil method, etc.) show great superiority in resolving closely spaced sources, but their computational cost is usually heavy. This is especially the case for point sources with a multi-cluster structure which requires processing large-sized data matrix resulted from highly sampled measurements. To address this issue, we propose a fast algorithm termed D-MUSIC, based on a measurement decoupling strategy. We demonstrate theoretically that for point sources with a known cluster structure, their measurement can be decoupled into local measurements of each of the clusters by solving a system of linear equations that are obtained by using a multipole basis. We further develop a subsampled MUSIC algorithm to detect the cluster structure and utilize it to decouple the global measurement. In the end, the MUSIC algorithm was applied to each local measurement to resolve point sources therein. Compared to the standard MUSIC algorithm, the proposed algorithm has comparable super-resolving capability while having a much lower computational complexity.
Learning Embodied Semantics via Music and Dance Semiotic Correlations
Mar 25, 2019

Music semantics is embodied, in the sense that meaning is biologically mediated by and grounded in the human body and brain. This embodied cognition perspective also explains why music structures modulate kinetic and somatosensory perception. We leverage this aspect of cognition, by considering dance as a proxy for music perception, in a statistical computational model that learns semiotic correlations between music audio and dance video. We evaluate the ability of this model to effectively capture underlying semantics in a cross-modal retrieval task. Quantitative results, validated with statistical significance testing, strengthen the body of evidence for embodied cognition in music and show the model can recommend music audio for dance video queries and vice-versa.
Stability and Super-resolution of MUSIC and ESPRIT for Multi-snapshot Spectral Estimation
May 29, 2021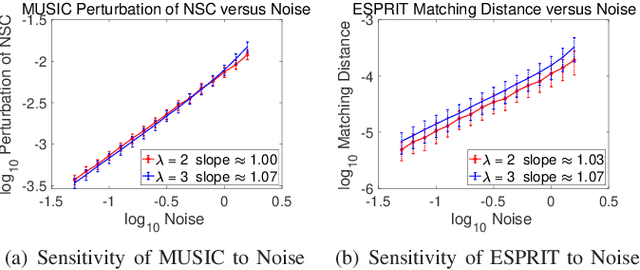
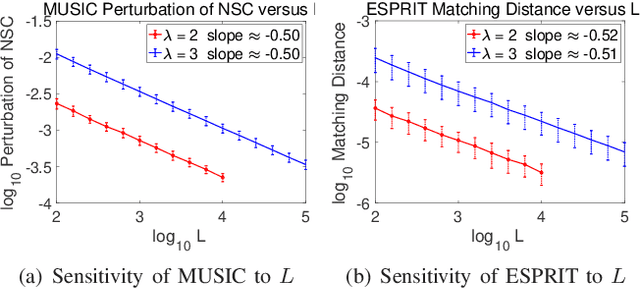
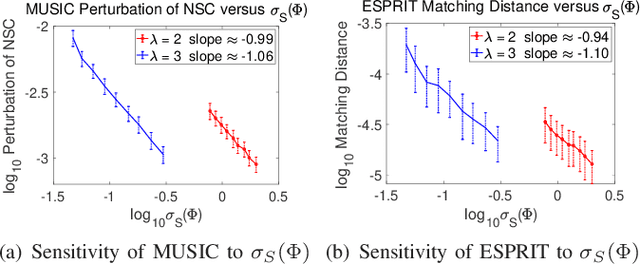
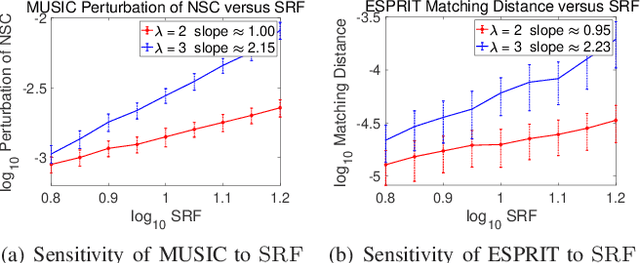
This paper studies the spectral estimation problem of estimating the locations of a fixed number of point sources given multiple snapshots of Fourier measurements collected by a uniform array of sensors. We prove novel non-asymptotic stability bounds for MUSIC and ESPRIT as a function of the noise standard deviation, number of snapshots, source amplitudes, and support. Our most general result is a perturbation bound of the signal space in terms of the minimum singular value of Fourier matrices. When the point sources are located in several separated clumps, we provide an explicit upper bound of the noise-space correlation perturbation error in MUSIC and the support error in ESPRIT in terms of a Super-Resolution Factor (SRF). The upper bound for ESPRIT is then compared with a new Cram\'er-Rao lower bound for the clumps model. As a result, we show that ESPRIT is comparable to that of the optimal unbiased estimator(s) in terms of the dependence on noise, number of snapshots and SRF. As a byproduct of our analysis, we discover several fundamental differences between the single-snapshot and multi-snapshot problems. Our theory is validated by numerical experiments.
Music-oriented Dance Video Synthesis with Pose Perceptual Loss
Dec 13, 2019
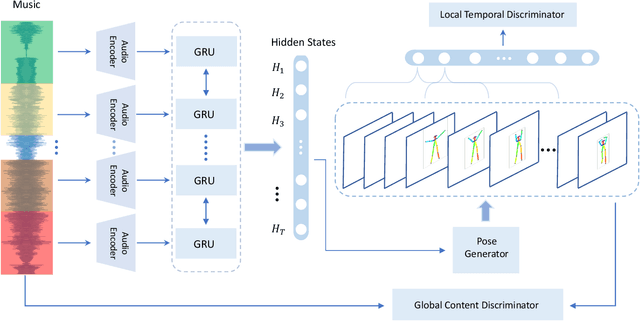
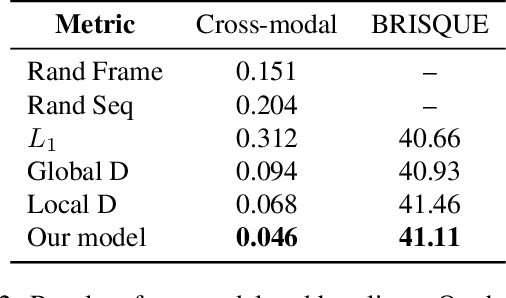
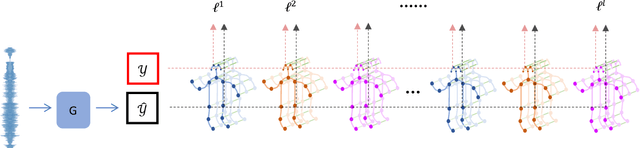
We present a learning-based approach with pose perceptual loss for automatic music video generation. Our method can produce a realistic dance video that conforms to the beats and rhymes of almost any given music. To achieve this, we firstly generate a human skeleton sequence from music and then apply the learned pose-to-appearance mapping to generate the final video. In the stage of generating skeleton sequences, we utilize two discriminators to capture different aspects of the sequence and propose a novel pose perceptual loss to produce natural dances. Besides, we also provide a new cross-modal evaluation to evaluate the dance quality, which is able to estimate the similarity between two modalities of music and dance. Finally, a user study is conducted to demonstrate that dance video synthesized by the presented approach produces surprisingly realistic results. The results are shown in the supplementary video at https://youtu.be/0rMuFMZa_K4
Deep domain adaptation for polyphonic melody extraction
Oct 22, 2022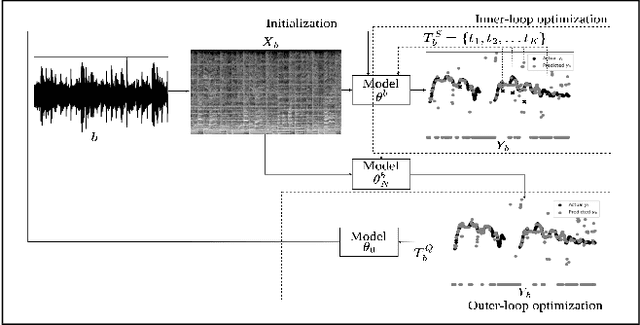
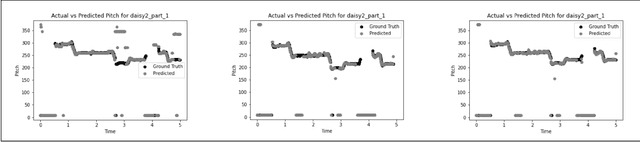
Extraction of the predominant pitch from polyphonic audio is one of the fundamental tasks in the field of music information retrieval and computational musicology. To accomplish this task using machine learning, a large amount of labeled audio data is required to train the model that predicts the pitch contour. But a classical model pre-trained on data from one domain (source), e.g, songs of a particular singer or genre, may not perform comparatively well in extracting melody from other domains (target). The performance of such models can be boosted by adapting the model using some annotated data in the target domain. In this work, we study various adaptation techniques applied to machine learning models for polyphonic melody extraction. Experimental results show that meta-learning-based adaptation performs better than simple fine-tuning. In addition to this, we find that this method outperforms the existing state-of-the-art non-adaptive polyphonic melody extraction algorithms.
Modelling Emotion Dynamics in Song Lyrics with State Space Models
Oct 17, 2022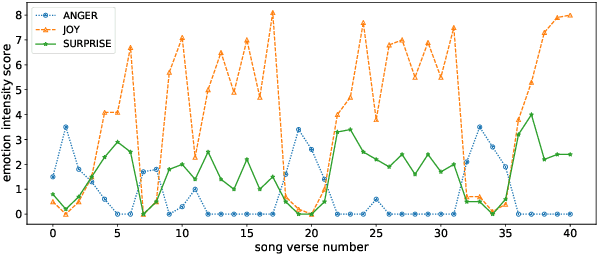
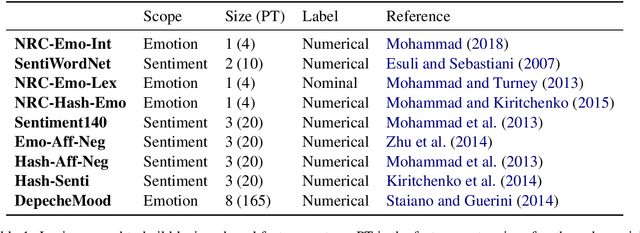
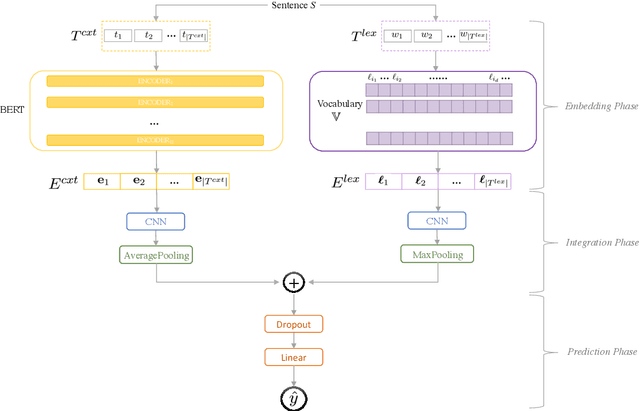
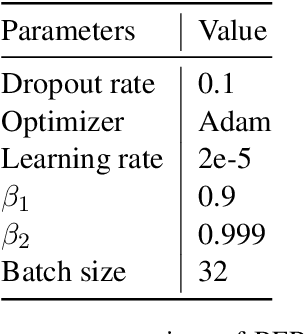
Most previous work in music emotion recognition assumes a single or a few song-level labels for the whole song. While it is known that different emotions can vary in intensity within a song, annotated data for this setup is scarce and difficult to obtain. In this work, we propose a method to predict emotion dynamics in song lyrics without song-level supervision. We frame each song as a time series and employ a State Space Model (SSM), combining a sentence-level emotion predictor with an Expectation-Maximization (EM) procedure to generate the full emotion dynamics. Our experiments show that applying our method consistently improves the performance of sentence-level baselines without requiring any annotated songs, making it ideal for limited training data scenarios. Further analysis through case studies shows the benefits of our method while also indicating the limitations and pointing to future directions.
Perceptions of Diversity in Electronic Music: the Impact of Listener, Artist, and Track Characteristics
Jan 28, 2021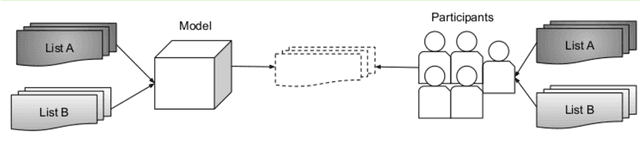
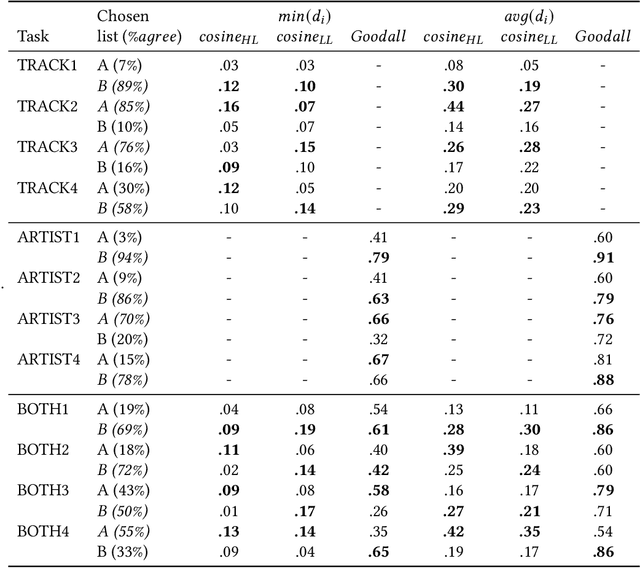
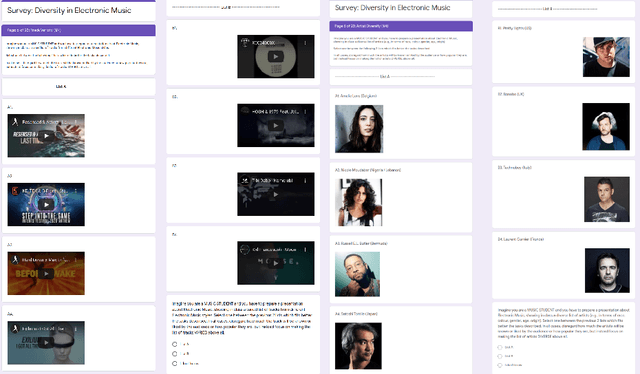
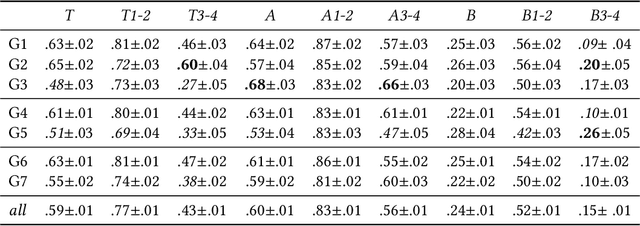
Shared practices to assess the diversity of retrieval system results are still debated in the Information Retrieval community, partly because of the challenges of determining what diversity means in specific scenarios, and of understanding how diversity is perceived by end-users. The field of Music Information Retrieval is not exempt from this issue. Even if fields such as Musicology or Sociology of Music have a long tradition in questioning the representation and the impact of diversity in cultural environments, such knowledge has not been yet embedded into the design and development of music technologies. In this paper, focusing on electronic music, we investigate the characteristics of listeners, artists, and tracks that are influential in the perception of diversity. Specifically, we center our attention on 1) understanding the relationship between perceived diversity and computational methods to measure diversity, and 2) analyzing how listeners' domain knowledge and familiarity influence such perceived diversity. To accomplish this, we design a user-study in which listeners are asked to compare pairs of lists of tracks and artists, and to select the most diverse list from each pair. We compare participants' ratings with results obtained through computational models built using audio tracks' features and artist attributes. We find that such models are generally aligned with participants' choices when most of them agree that one list is more diverse than the other, while they present a mixed behaviour in cases where participants have little agreement. Moreover, we observe how differences in domain knowledge, familiarity, and demographics can influence the level of agreement among listeners, and between listeners and diversity metrics computed automatically.