 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Multi-view MidiVAE: Fusing Track- and Bar-view Representations for Long Multi-track Symbolic Music Generation
Jan 15, 2024
Variational Autoencoders (VAEs) constitute a crucial component of neural symbolic music generation, among which some works have yielded outstanding results and attracted considerable attention. Nevertheless, previous VAEs still encounter issues with overly long feature sequences and generated results lack contextual coherence, thus the challenge of modeling long multi-track symbolic music still remains unaddressed. To this end, we propose Multi-view MidiVAE, as one of the pioneers in VAE methods that effectively model and generate long multi-track symbolic music. The Multi-view MidiVAE utilizes the two-dimensional (2-D) representation, OctupleMIDI, to capture relationships among notes while reducing the feature sequences length. Moreover, we focus on instrumental characteristics and harmony as well as global and local information about the musical composition by employing a hybrid variational encoding-decoding strategy to integrate both Track- and Bar-view MidiVAE features. Objective and subjective experimental results on the CocoChorales dataset demonstrate that, compared to the baseline, Multi-view MidiVAE exhibits significant improvements in terms of modeling long multi-track symbolic music.
Beyond Language Models: Byte Models are Digital World Simulators
Feb 29, 2024Traditional deep learning often overlooks bytes, the basic units of the digital world, where all forms of information and operations are encoded and manipulated in binary format. Inspired by the success of next token prediction in natural language processing, we introduce bGPT, a model with next byte prediction to simulate the digital world. bGPT matches specialized models in performance across various modalities, including text, audio, and images, and offers new possibilities for predicting, simulating, and diagnosing algorithm or hardware behaviour. It has almost flawlessly replicated the process of converting symbolic music data, achieving a low error rate of 0.0011 bits per byte in converting ABC notation to MIDI format. In addition, bGPT demonstrates exceptional capabilities in simulating CPU behaviour, with an accuracy exceeding 99.99% in executing various operations. Leveraging next byte prediction, models like bGPT can directly learn from vast binary data, effectively simulating the intricate patterns of the digital world.
On the Effect of Data-Augmentation on Local Embedding Properties in the Contrastive Learning of Music Audio Representations
Jan 17, 2024Audio embeddings are crucial tools in understanding large catalogs of music. Typically embeddings are evaluated on the basis of the performance they provide in a wide range of downstream tasks, however few studies have investigated the local properties of the embedding spaces themselves which are important in nearest neighbor algorithms, commonly used in music search and recommendation. In this work we show that when learning audio representations on music datasets via contrastive learning, musical properties that are typically homogeneous within a track (e.g., key and tempo) are reflected in the locality of neighborhoods in the resulting embedding space. By applying appropriate data augmentation strategies, localisation of such properties can not only be reduced but the localisation of other attributes is increased. For example, locality of features such as pitch and tempo that are less relevant to non-expert listeners, may be mitigated while improving the locality of more salient features such as genre and mood, achieving state-of-the-art performance in nearest neighbor retrieval accuracy. Similarly, we show that the optimal selection of data augmentation strategies for contrastive learning of music audio embeddings is dependent on the downstream task, highlighting this as an important embedding design decision.
LiveScaler: Live control of the harmony of an electronic music track
Jan 16, 2024In Electronic Dance Music (EDM), many artists use DJing techniques in order to perform their own productions live. As a consequence, they do not have access during the performance to the internal structure of their tracks, and specifically to their equivalent of a partition: MIDI files. On the other hand, if an artist attempts to remix or interpret their own production live, the number of tracks that they can simultaneously control is limited without suitable software. This article introduces LiveScaler, a software that allows live control of the harmony and pitch of electronic music. A set of pitch transformations, termed affine transformations, is presented. These transformations are applied to all MIDI streams of a prepared track. A MaxMSP implementation, in conjunction with Ableton Live, is proposed. Special attention is given to control issues, mapping, and practical live experimentation in the context of EDM.
* in French language
MCMChaos: Improvising Rap Music with MCMC Methods and Chaos Theory
Jan 15, 2024A novel freestyle rap software, MCMChaos 0.0.1, based on rap music transcriptions created in previous research is presented. The software has three different versions, each making use of different mathematical simulation methods: collapsed gibbs sampler and lorenz attractor simulation. As far as we know, these simulation methods have never been used in rap music generation before. The software implements Python Text-to-Speech processing (pyttxs) to convert text wrangled from the MCFlow corpus into English speech. In each version, values simulated from each respective mathematical model alter the rate of speech, volume, and (in the multiple voice case) the voice of the text-to-speech engine on a line-by-line basis. The user of the software is presented with a real-time graphical user interface (GUI) which instantaneously changes the initial values read into the mathematical simulation methods. Future research might attempt to allow for more user control and autonomy.
EnchantDance: Unveiling the Potential of Music-Driven Dance Movement
Dec 26, 2023The task of music-driven dance generation involves creating coherent dance movements that correspond to the given music. While existing methods can produce physically plausible dances, they often struggle to generalize to out-of-set data. The challenge arises from three aspects: 1) the high diversity of dance movements and significant differences in the distribution of music modalities, which make it difficult to generate music-aligned dance movements. 2) the lack of a large-scale music-dance dataset, which hinders the generation of generalized dance movements from music. 3) The protracted nature of dance movements poses a challenge to the maintenance of a consistent dance style. In this work, we introduce the EnchantDance framework, a state-of-the-art method for dance generation. Due to the redundancy of the original dance sequence along the time axis, EnchantDance first constructs a strong dance latent space and then trains a dance diffusion model on the dance latent space. To address the data gap, we construct a large-scale music-dance dataset, ChoreoSpectrum3D Dataset, which includes four dance genres and has a total duration of 70.32 hours, making it the largest reported music-dance dataset to date. To enhance consistency between music genre and dance style, we pre-train a music genre prediction network using transfer learning and incorporate music genre as extra conditional information in the training of the dance diffusion model. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on dance quality, diversity, and consistency.
Fast Timing-Conditioned Latent Audio Diffusion
Feb 08, 2024Generating long-form 44.1kHz stereo audio from text prompts can be computationally demanding. Further, most previous works do not tackle that music and sound effects naturally vary in their duration. Our research focuses on the efficient generation of long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model. Stable Audio is based on latent diffusion, with its latent defined by a fully-convolutional variational autoencoder. It is conditioned on text prompts as well as timing embeddings, allowing for fine control over both the content and length of the generated music and sounds. Stable Audio is capable of rendering stereo signals of up to 95 sec at 44.1kHz in 8 sec on an A100 GPU. Despite its compute efficiency and fast inference, it is one of the best in two public text-to-music and -audio benchmarks and, differently from state-of-the-art models, can generate music with structure and stereo sounds.
Music-PAW: Learning Music Representations via Hierarchical Part-whole Interaction and Contrast
Dec 11, 2023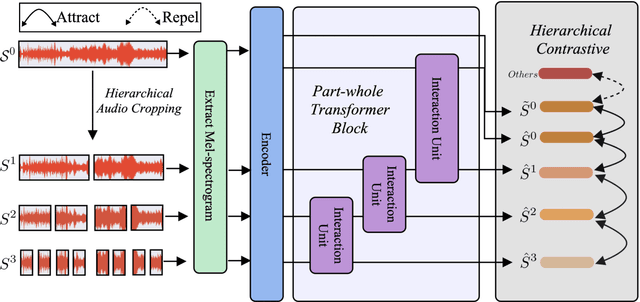
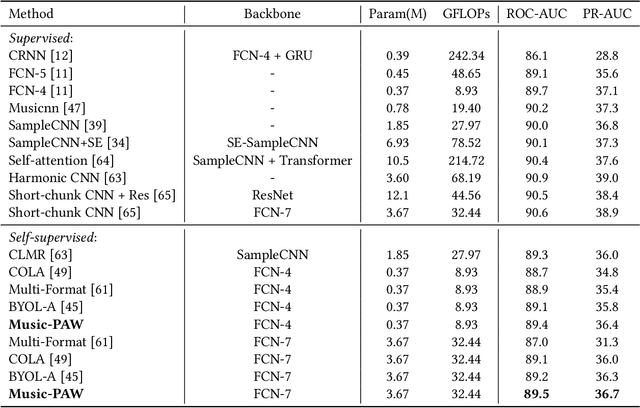
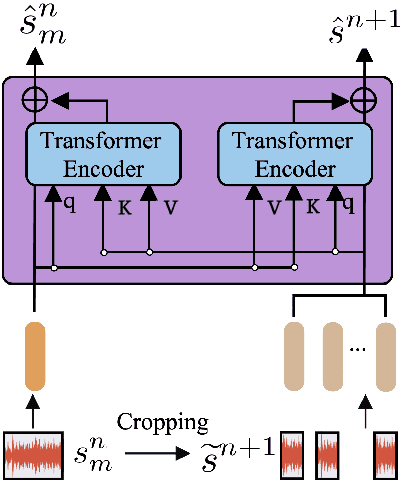
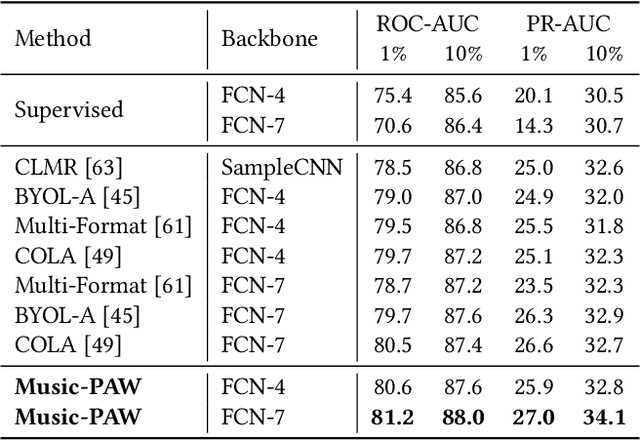
The excellent performance of recent self-supervised learning methods on various downstream tasks has attracted great attention from academia and industry. Some recent research efforts have been devoted to self-supervised music representation learning. Nevertheless, most of them learn to represent equally-sized music clips in the waveform or a spectrogram. Despite being effective in some tasks, learning music representations in such a manner largely neglect the inherent part-whole hierarchies of music. Due to the hierarchical nature of the auditory cortex [24], understanding the bottom-up structure of music, i.e., how different parts constitute the whole at different levels, is essential for music understanding and representation learning. This work pursues hierarchical music representation learning and introduces the Music-PAW framework, which enables feature interactions of cropped music clips with part-whole hierarchies. From a technical perspective, we propose a transformer-based part-whole interaction module to progressively reason the structural relationships between part-whole music clips at adjacent levels. Besides, to create a multi-hierarchy representation space, we devise a hierarchical contrastive learning objective to align part-whole music representations in adjacent hierarchies. The merits of audio representation learning from part-whole hierarchies have been validated on various downstream tasks, including music classification (single-label and multi-label), cover song identification and acoustic scene classification.
SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
Jan 30, 2024Generative adversarial network (GAN) models can synthesize highquality audio signals while ensuring fast sample generation. However, they are difficult to train and are prone to several issues including mode collapse and divergence. In this paper, we introduce SpecDiff-GAN, a neural vocoder based on HiFi-GAN, which was initially devised for speech synthesis from mel spectrogram. In our model, the training stability is enhanced by means of a forward diffusion process which consists in injecting noise from a Gaussian distribution to both real and fake samples before inputting them to the discriminator. We further improve the model by exploiting a spectrally-shaped noise distribution with the aim to make the discriminator's task more challenging. We then show the merits of our proposed model for speech and music synthesis on several datasets. Our experiments confirm that our model compares favorably in audio quality and efficiency compared to several baselines.
* Accepted at ICASSP 2024
Zero-Shot Unsupervised and Text-Based Audio Editing Using DDPM Inversion
Feb 25, 2024Editing signals using large pre-trained models, in a zero-shot manner, has recently seen rapid advancements in the image domain. However, this wave has yet to reach the audio domain. In this paper, we explore two zero-shot editing techniques for audio signals, which use DDPM inversion on pre-trained diffusion models. The first, adopted from the image domain, allows text-based editing. The second, is a novel approach for discovering semantically meaningful editing directions without supervision. When applied to music signals, this method exposes a range of musically interesting modifications, from controlling the participation of specific instruments to improvisations on the melody. Samples and code can be found on our examples page in https://hilamanor.github.io/AudioEditing/ .