 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Embeddings as representation for symbolic music
May 19, 2020
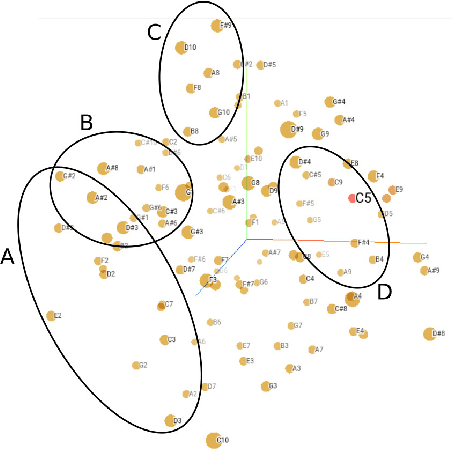
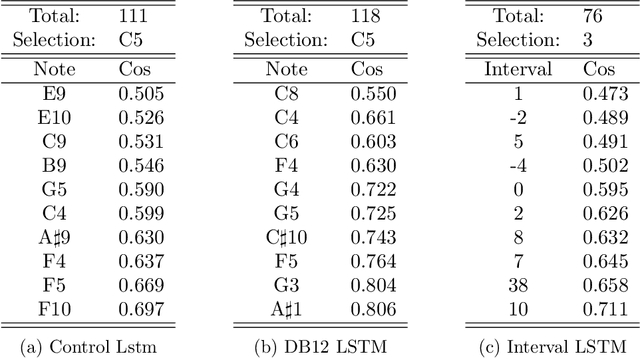
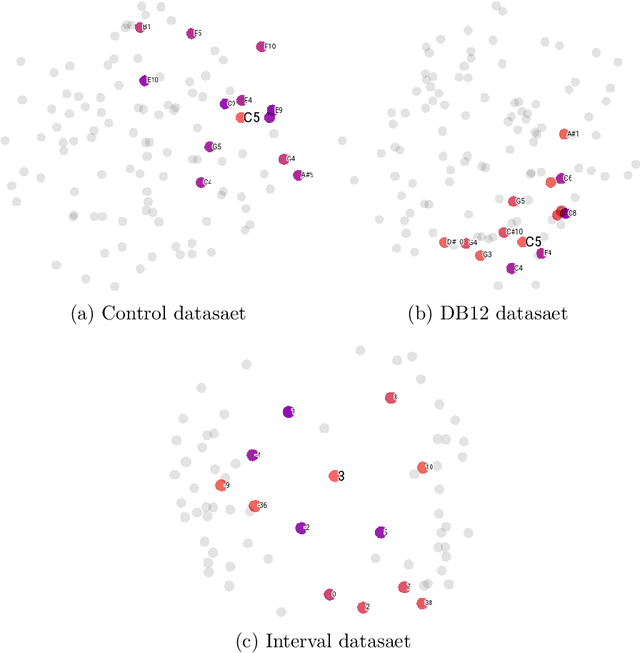
A representation technique that allows encoding music in a way that contains musical meaning would improve the results of any model trained for computer music tasks like generation of melodies and harmonies of better quality. The field of natural language processing has done a lot of work in finding a way to capture the semantic meaning of words and sentences, and word embeddings have successfully shown the capabilities for such a task. In this paper, we experiment with embeddings to represent musical notes from 3 different variations of a dataset and analyze if the model can capture useful musical patterns. To do this, the resulting embeddings are visualized in projections using the t-SNE technique.
Symphony Generation with Permutation Invariant Language Model
May 10, 2022
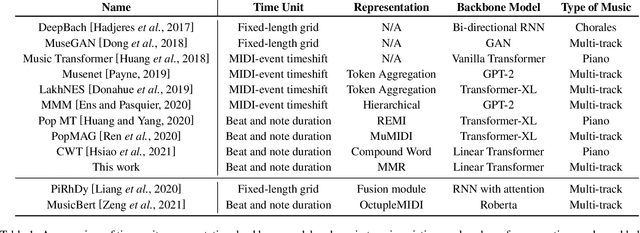
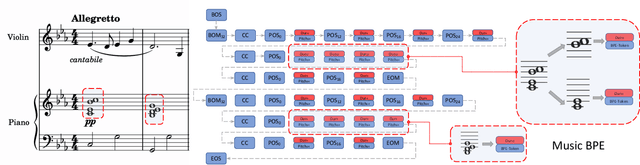
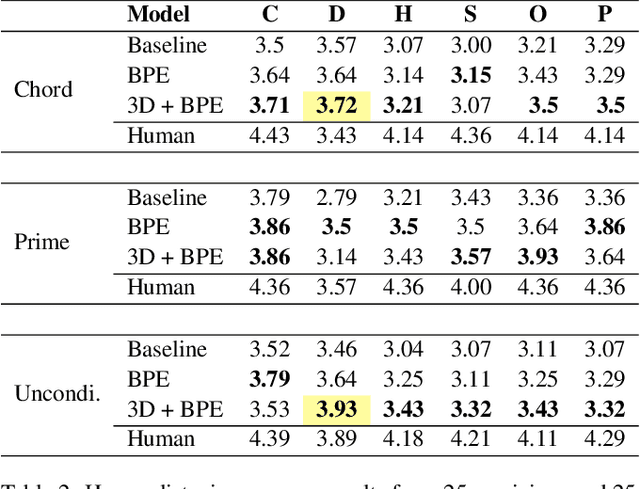
In this work, we present a symbolic symphony music generation solution, SymphonyNet, based on a permutation invariant language model. To bridge the gap between text generation and symphony generation task, we propose a novel Multi-track Multi-instrument Repeatable (MMR) representation with particular 3-D positional embedding and a modified Byte Pair Encoding algorithm (Music BPE) for music tokens. A novel linear transformer decoder architecture is introduced as a backbone for modeling extra-long sequences of symphony tokens. Meanwhile, we train the decoder to learn automatic orchestration as a joint task by masking instrument information from the input. We also introduce a large-scale symbolic symphony dataset for the advance of symphony generation research. Our empirical results show that our proposed approach can generate coherent, novel, complex and harmonious symphony compared to human composition, which is the pioneer solution for multi-track multi-instrument symbolic music generation.
POP909: A Pop-song Dataset for Music Arrangement Generation
Aug 17, 2020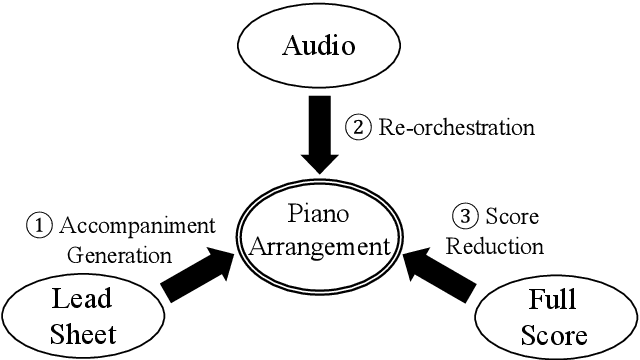
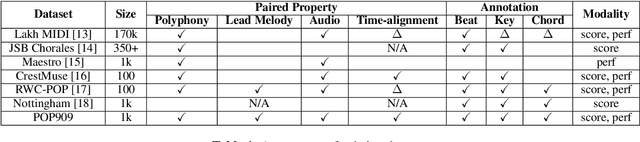
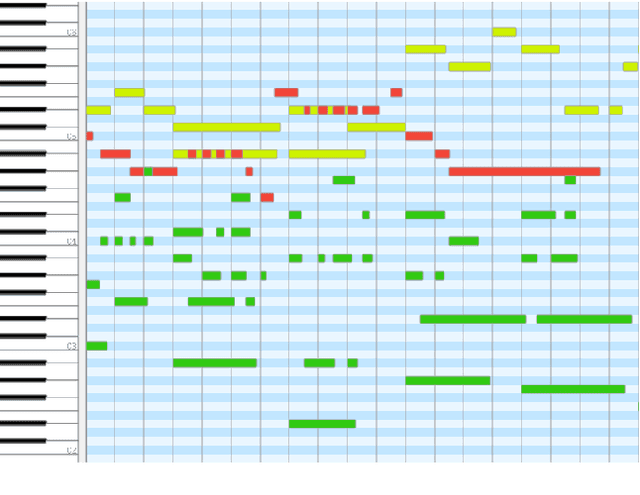
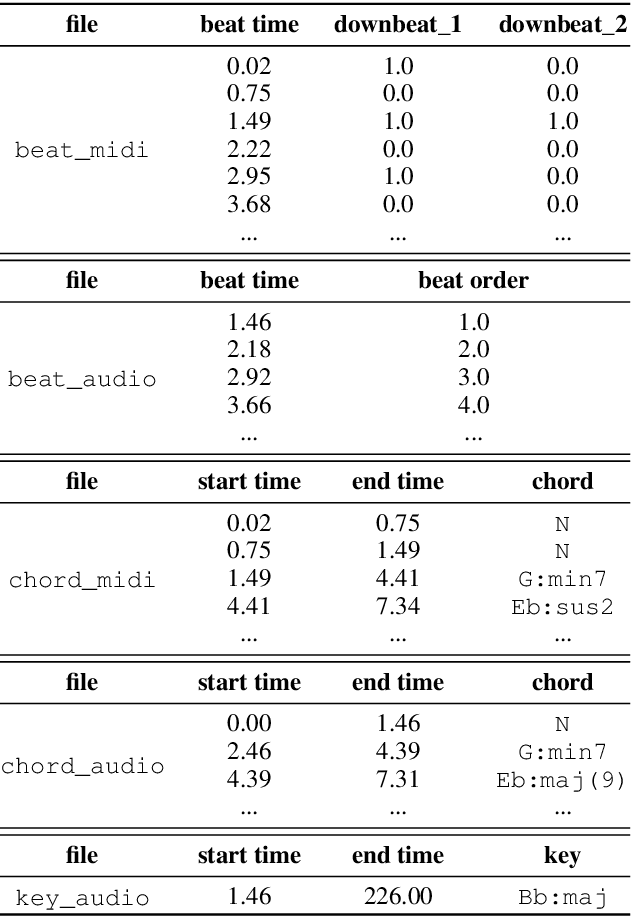
Music arrangement generation is a subtask of automatic music generation, which involves reconstructing and re-conceptualizing a piece with new compositional techniques. Such a generation process inevitably requires reference from the original melody, chord progression, or other structural information. Despite some promising models for arrangement, they lack more refined data to achieve better evaluations and more practical results. In this paper, we propose POP909, a dataset which contains multiple versions of the piano arrangements of 909 popular songs created by professional musicians. The main body of the dataset contains the vocal melody, the lead instrument melody, and the piano accompaniment for each song in MIDI format, which are aligned to the original audio files. Furthermore, we provide the annotations of tempo, beat, key, and chords, where the tempo curves are hand-labeled and others are done by MIR algorithms. Finally, we conduct several baseline experiments with this dataset using standard deep music generation algorithms.
JamBot: Music Theory Aware Chord Based Generation of Polyphonic Music with LSTMs
Nov 21, 2017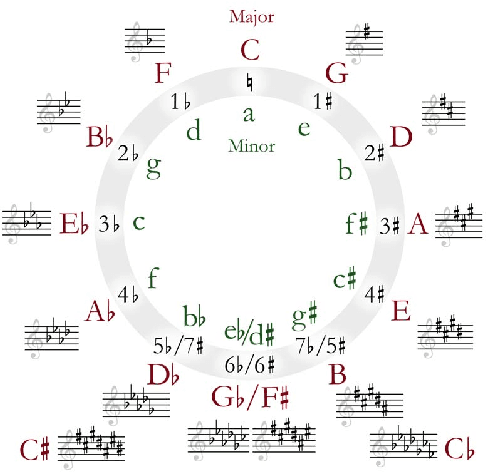
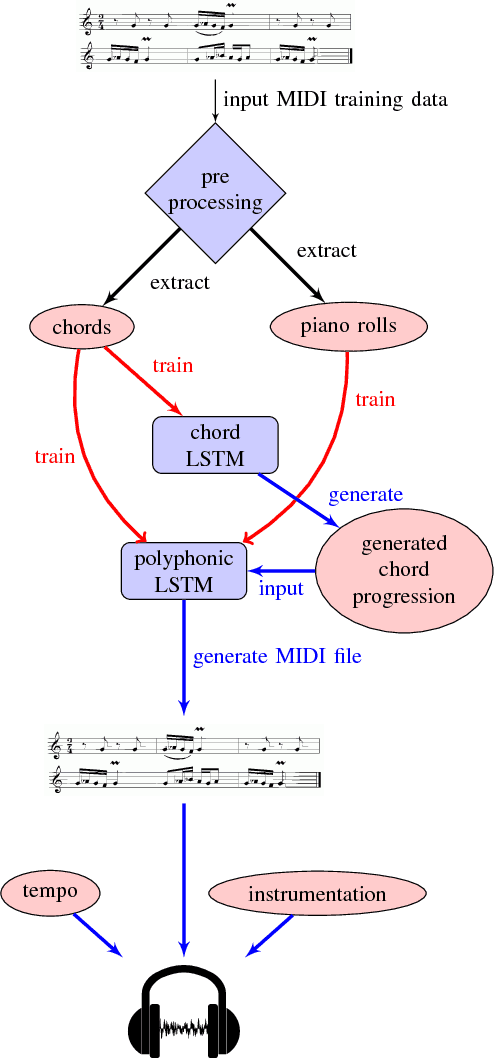
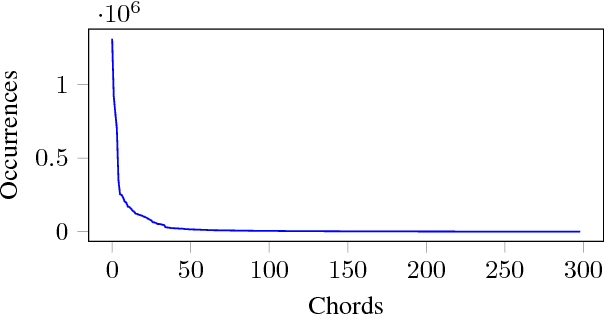
We propose a novel approach for the generation of polyphonic music based on LSTMs. We generate music in two steps. First, a chord LSTM predicts a chord progression based on a chord embedding. A second LSTM then generates polyphonic music from the predicted chord progression. The generated music sounds pleasing and harmonic, with only few dissonant notes. It has clear long-term structure that is similar to what a musician would play during a jam session. We show that our approach is sensible from a music theory perspective by evaluating the learned chord embeddings. Surprisingly, our simple model managed to extract the circle of fifths, an important tool in music theory, from the dataset.
Re-creation of Creations: A New Paradigm for Lyric-to-Melody Generation
Aug 18, 2022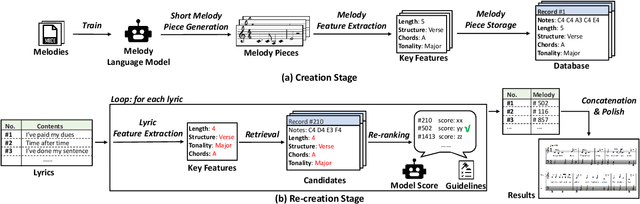
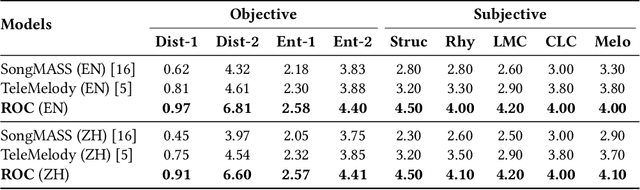
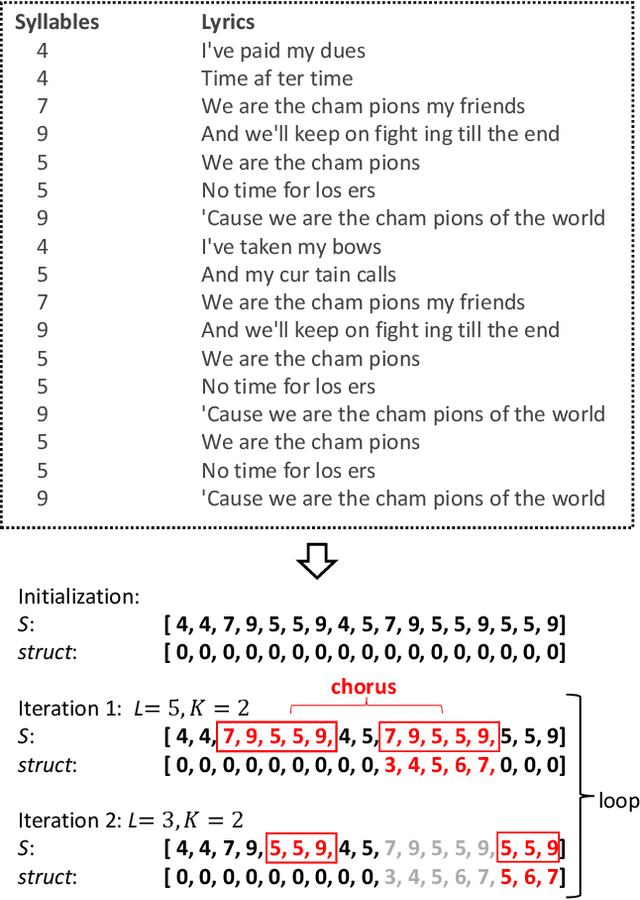
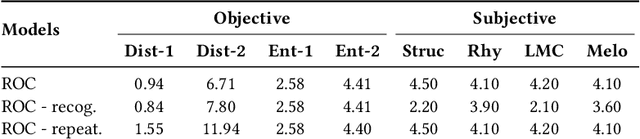
Lyric-to-melody generation is an important task in songwriting, and is also quite challenging due to its distinctive characteristics: the generated melodies should not only follow good musical patterns, but also align with features in lyrics such as rhythms and structures. These characteristics cannot be well handled by neural generation models that learn lyric-to-melody mapping in an end-to-end way, due to several issues: (1) lack of aligned lyric-melody training data to sufficiently learn lyric-melody feature alignment; (2) lack of controllability in generation to explicitly guarantee the lyric-melody feature alignment. In this paper, we propose Re-creation of Creations (ROC), a new paradigm for lyric-to-melody generation that addresses the above issues through a generation-retrieval pipeline. Specifically, our paradigm has two stages: (1) creation stage, where a huge amount of music pieces are generated by a neural-based melody language model and indexed in a database through several key features (e.g., chords, tonality, rhythm, and structural information including chorus or verse); (2) re-creation stage, where melodies are recreated by retrieving music pieces from the database according to the key features from lyrics and concatenating best music pieces based on composition guidelines and melody language model scores. Our new paradigm has several advantages: (1) It only needs unpaired melody data to train melody language model, instead of paired lyric-melody data in previous models. (2) It achieves good lyric-melody feature alignment in lyric-to-melody generation. Experiments on English and Chinese datasets demonstrate that ROC outperforms previous neural based lyric-to-melody generation models on both objective and subjective metrics.
Deep Music Analogy Via Latent Representation Disentanglement
Jul 08, 2019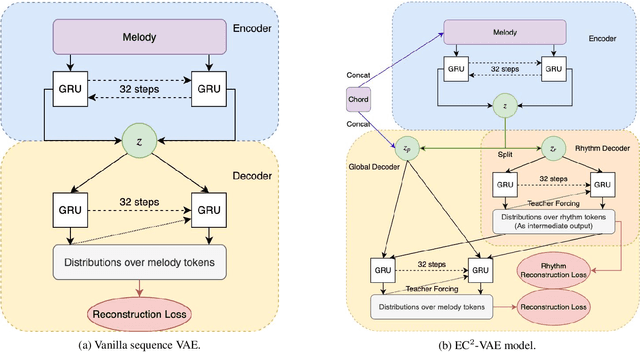
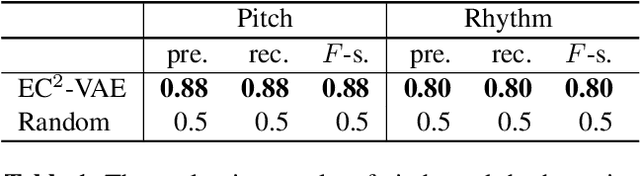
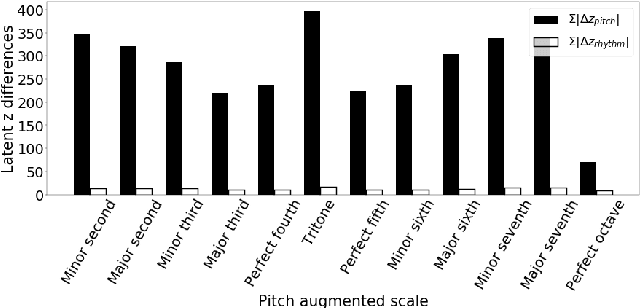
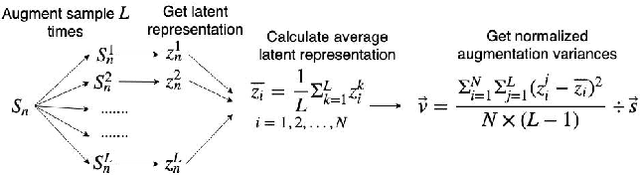
Analogy-making is a key method for computer algorithms to generate both natural and creative music pieces. In general, an analogy is made by partially transferring the music abstractions, i.e., high-level representations and their relationships, from one piece to another; however, this procedure requires disentangling music representations, which usually takes little effort for musicians but is non-trivial for computers. Three sub-problems arise: extracting latent representations from the observation, disentangling the representations so that each part has a unique semantic interpretation, and mapping the latent representations back to actual music. In this paper, we contribute an explicitly-constrained variational autoencoder (EC$^2$-VAE) as a unified solution to all three sub-problems. We focus on disentangling the pitch and rhythm representations of 8-beat music clips conditioned on chords. In producing music analogies, this model helps us to realize the imaginary situation of "what if" a piece is composed using a different pitch contour, rhythm pattern, or chord progression by borrowing the representations from other pieces. Finally, we validate the proposed disentanglement method using objective measurements and evaluate the analogy examples by a subjective study.
Feel The Music: Automatically Generating A Dance For An Input Song
Jun 23, 2020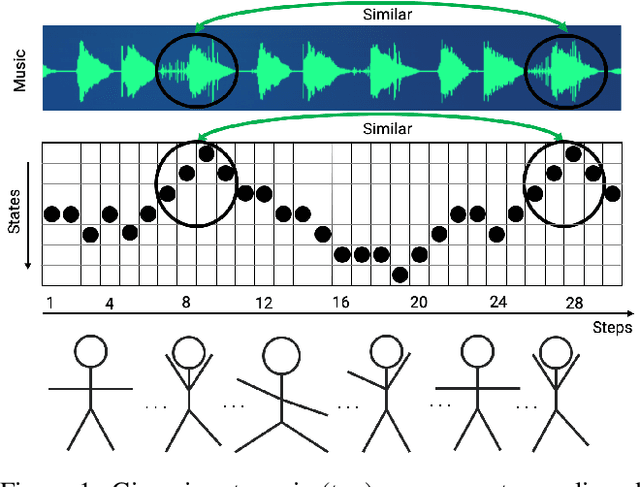
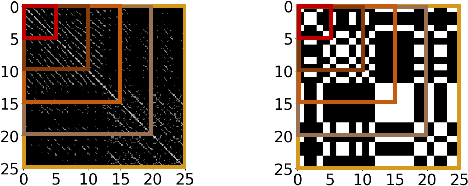
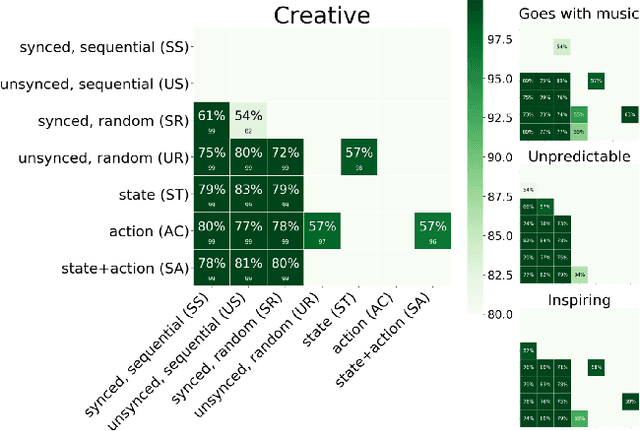
We present a general computational approach that enables a machine to generate a dance for any input music. We encode intuitive, flexible heuristics for what a 'good' dance is: the structure of the dance should align with the structure of the music. This flexibility allows the agent to discover creative dances. Human studies show that participants find our dances to be more creative and inspiring compared to meaningful baselines. We also evaluate how perception of creativity changes based on different presentations of the dance. Our code is available at https://github.com/purvaten/feel-the-music.
UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
Dec 06, 2022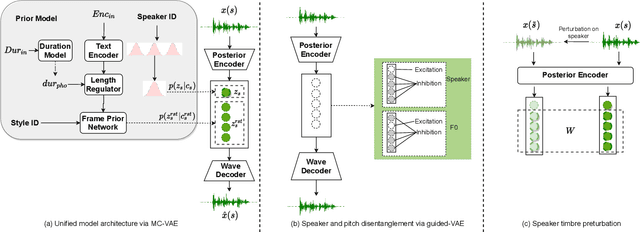
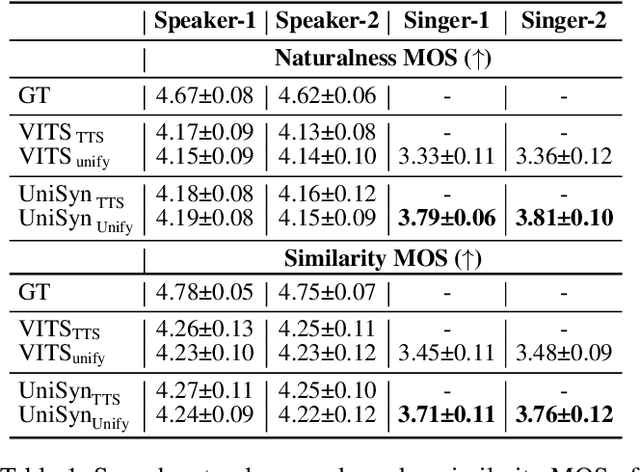
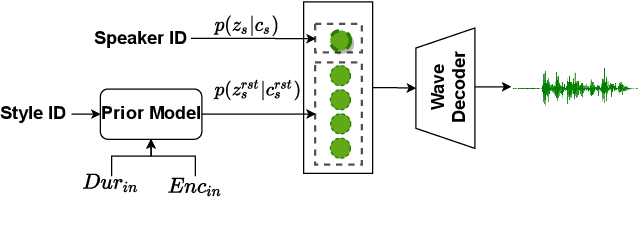
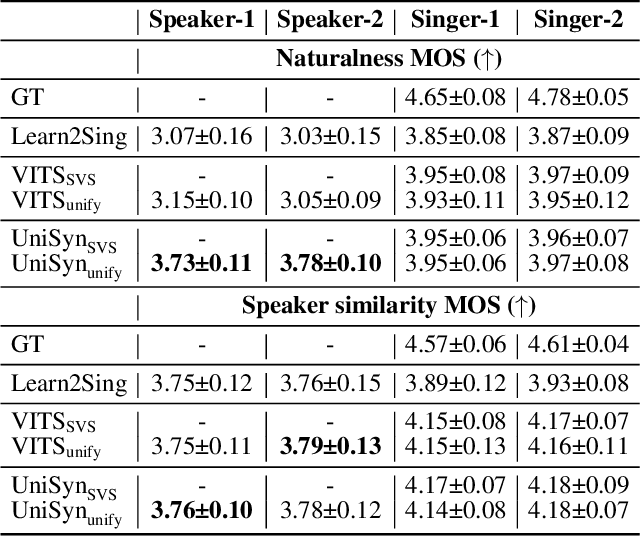
Text-to-speech (TTS) and singing voice synthesis (SVS) aim at generating high-quality speaking and singing voice according to textual input and music scores, respectively. Unifying TTS and SVS into a single system is crucial to the applications requiring both of them. Existing methods usually suffer from some limitations, which rely on either both singing and speaking data from the same person or cascaded models of multiple tasks. To address these problems, a simplified elegant framework for TTS and SVS, named UniSyn, is proposed in this paper. It is an end-to-end unified model that can make a voice speak and sing with only singing or speaking data from this person. To be specific, a multi-conditional variational autoencoder (MC-VAE), which constructs two independent latent sub-spaces with the speaker- and style-related (i.e. speak or sing) conditions for flexible control, is proposed in UniSyn. Moreover, supervised guided-VAE and timbre perturbation with the Wasserstein distance constraint are leveraged to further disentangle the speaker timbre and style. Experiments conducted on two speakers and two singers demonstrate that UniSyn can generate natural speaking and singing voice without corresponding training data. The proposed approach outperforms the state-of-the-art end-to-end voice generation work, which proves the effectiveness and advantages of UniSyn.