 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Embeddings as representation for symbolic music
May 19, 2020
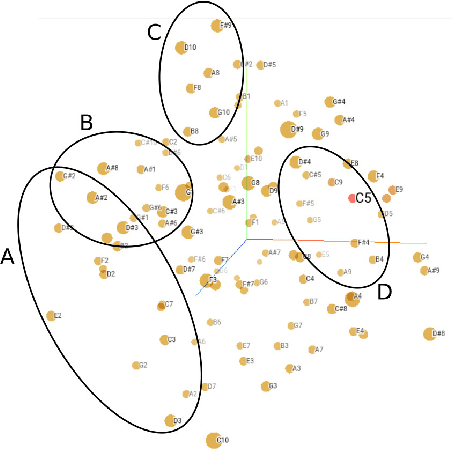
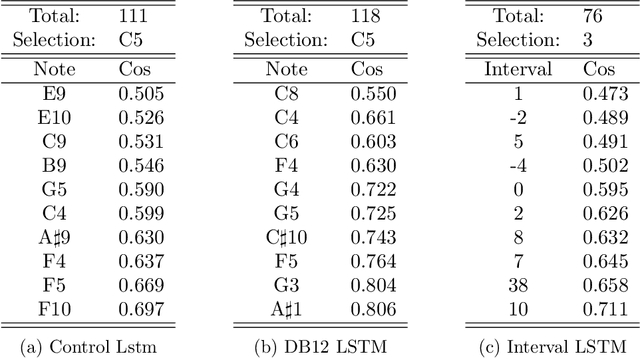
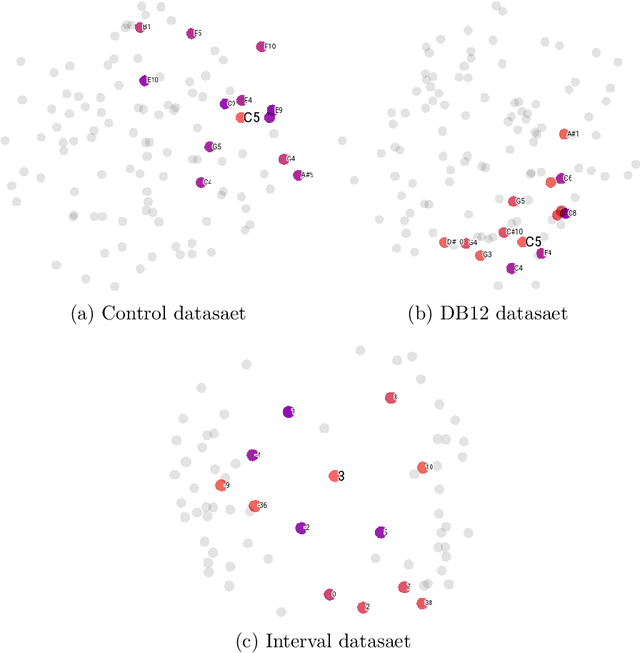
A representation technique that allows encoding music in a way that contains musical meaning would improve the results of any model trained for computer music tasks like generation of melodies and harmonies of better quality. The field of natural language processing has done a lot of work in finding a way to capture the semantic meaning of words and sentences, and word embeddings have successfully shown the capabilities for such a task. In this paper, we experiment with embeddings to represent musical notes from 3 different variations of a dataset and analyze if the model can capture useful musical patterns. To do this, the resulting embeddings are visualized in projections using the t-SNE technique.
Quantum Natural Language Generation on Near-Term Devices
Nov 01, 2022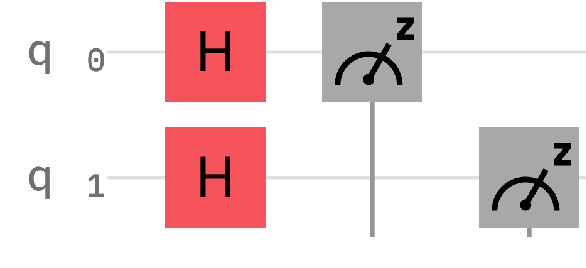
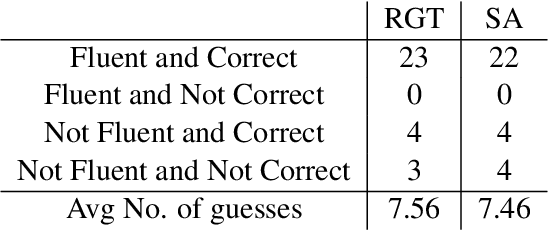
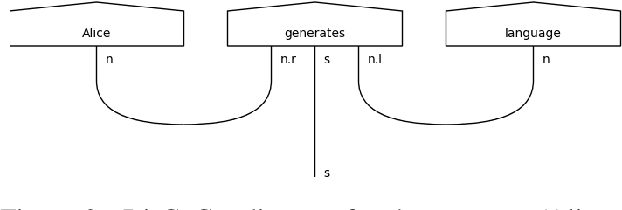
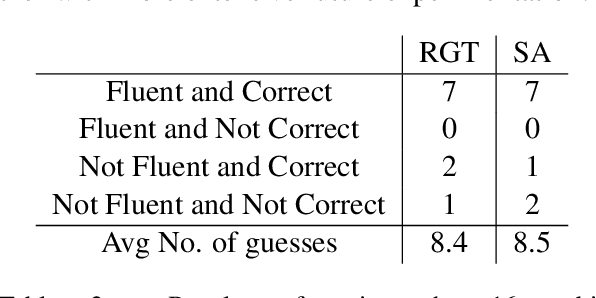
The emergence of noisy medium-scale quantum devices has led to proof-of-concept applications for quantum computing in various domains. Examples include Natural Language Processing (NLP) where sentence classification experiments have been carried out, as well as procedural generation, where tasks such as geopolitical map creation, and image manipulation have been performed. We explore applications at the intersection of these two areas by designing a hybrid quantum-classical algorithm for sentence generation. Our algorithm is based on the well-known simulated annealing technique for combinatorial optimisation. An implementation is provided and used to demonstrate successful sentence generation on both simulated and real quantum hardware. A variant of our algorithm can also be used for music generation. This paper aims to be self-contained, introducing all the necessary background on NLP and quantum computing along the way.
POP909: A Pop-song Dataset for Music Arrangement Generation
Aug 17, 2020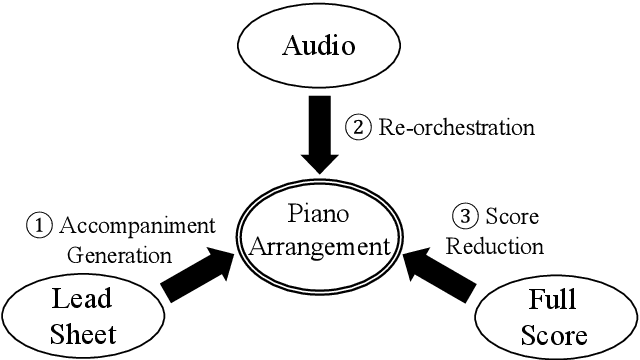
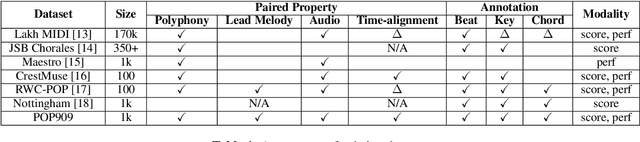
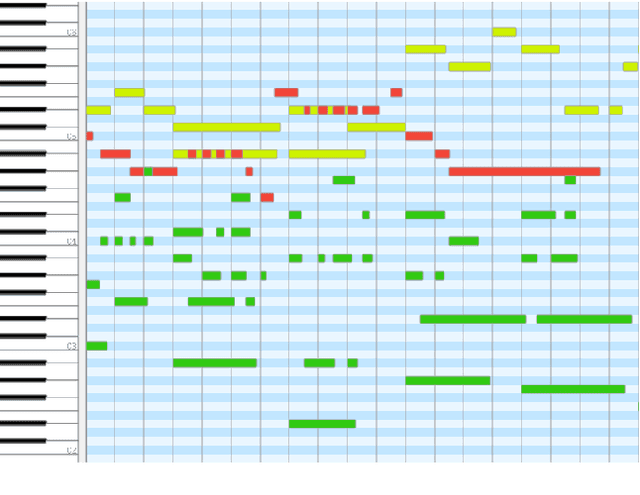
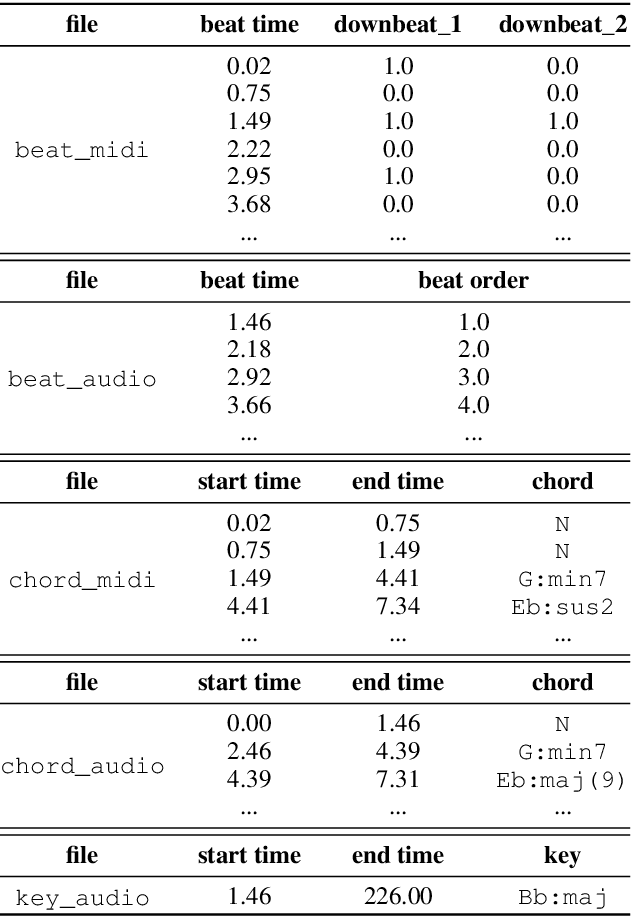
Music arrangement generation is a subtask of automatic music generation, which involves reconstructing and re-conceptualizing a piece with new compositional techniques. Such a generation process inevitably requires reference from the original melody, chord progression, or other structural information. Despite some promising models for arrangement, they lack more refined data to achieve better evaluations and more practical results. In this paper, we propose POP909, a dataset which contains multiple versions of the piano arrangements of 909 popular songs created by professional musicians. The main body of the dataset contains the vocal melody, the lead instrument melody, and the piano accompaniment for each song in MIDI format, which are aligned to the original audio files. Furthermore, we provide the annotations of tempo, beat, key, and chords, where the tempo curves are hand-labeled and others are done by MIR algorithms. Finally, we conduct several baseline experiments with this dataset using standard deep music generation algorithms.
Feel The Music: Automatically Generating A Dance For An Input Song
Jun 23, 2020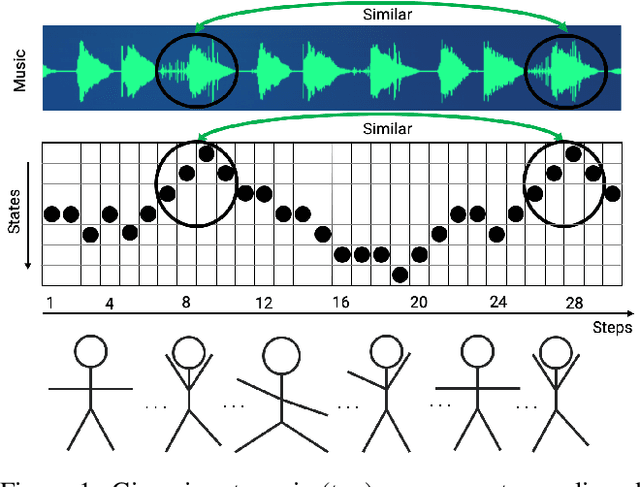
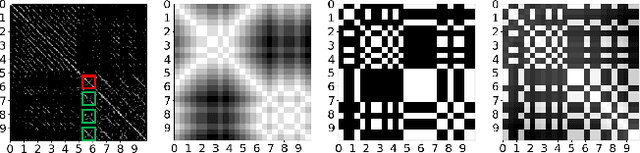
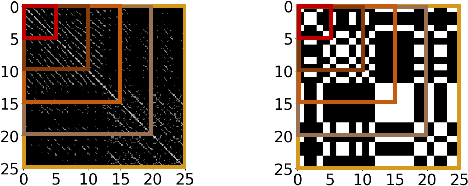
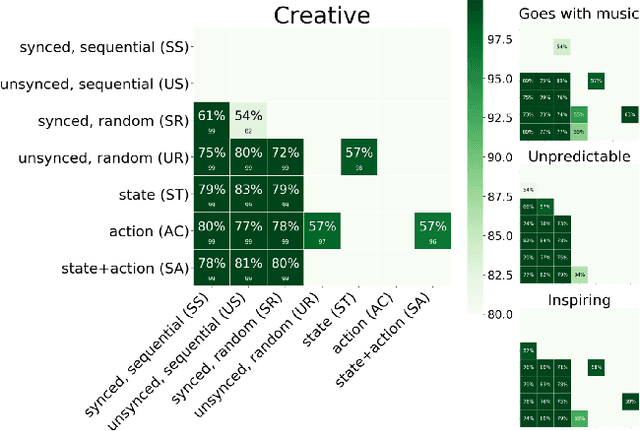
We present a general computational approach that enables a machine to generate a dance for any input music. We encode intuitive, flexible heuristics for what a 'good' dance is: the structure of the dance should align with the structure of the music. This flexibility allows the agent to discover creative dances. Human studies show that participants find our dances to be more creative and inspiring compared to meaningful baselines. We also evaluate how perception of creativity changes based on different presentations of the dance. Our code is available at https://github.com/purvaten/feel-the-music.
JamBot: Music Theory Aware Chord Based Generation of Polyphonic Music with LSTMs
Nov 21, 2017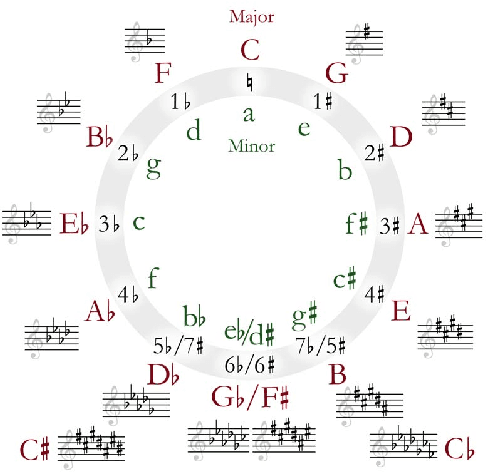
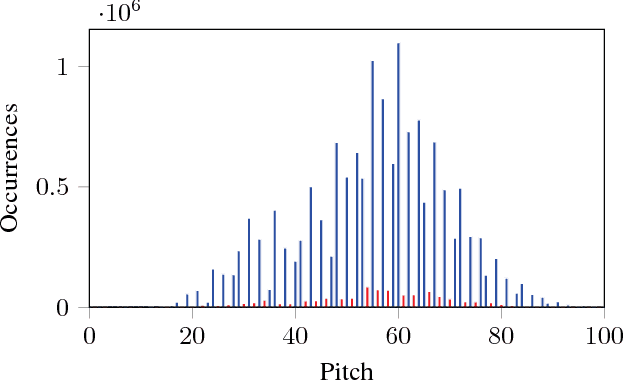
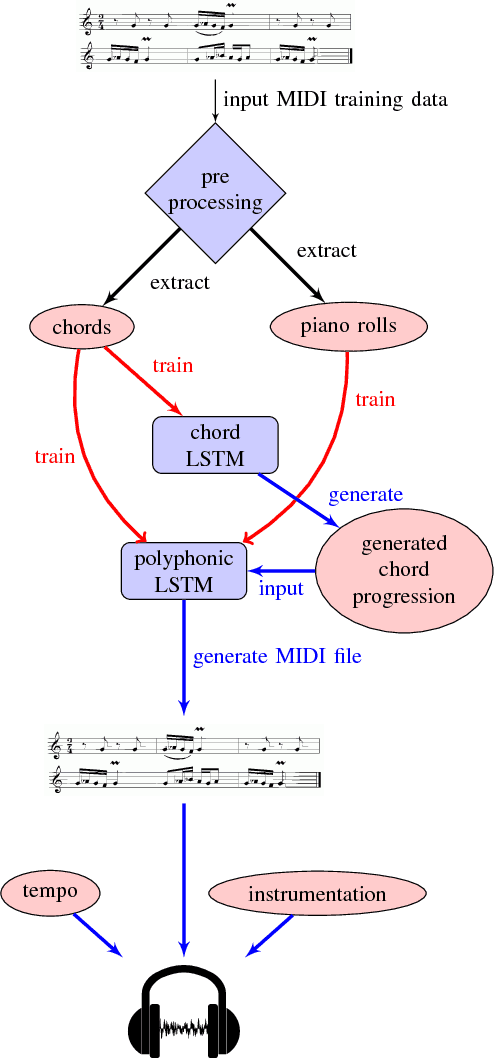
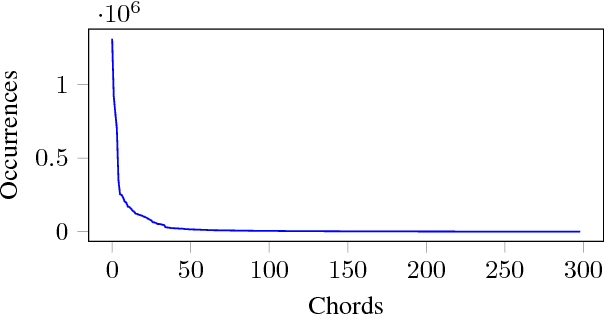
We propose a novel approach for the generation of polyphonic music based on LSTMs. We generate music in two steps. First, a chord LSTM predicts a chord progression based on a chord embedding. A second LSTM then generates polyphonic music from the predicted chord progression. The generated music sounds pleasing and harmonic, with only few dissonant notes. It has clear long-term structure that is similar to what a musician would play during a jam session. We show that our approach is sensible from a music theory perspective by evaluating the learned chord embeddings. Surprisingly, our simple model managed to extract the circle of fifths, an important tool in music theory, from the dataset.
Deep Music Analogy Via Latent Representation Disentanglement
Jul 08, 2019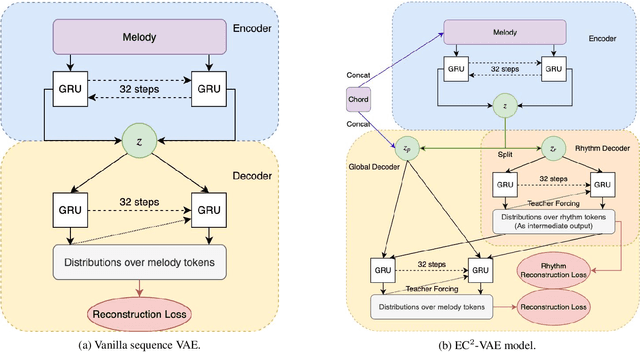
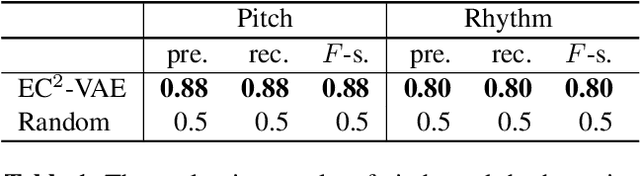
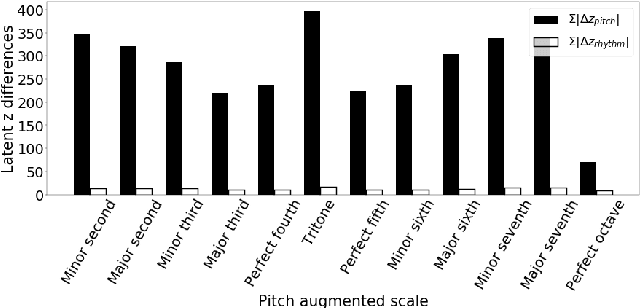
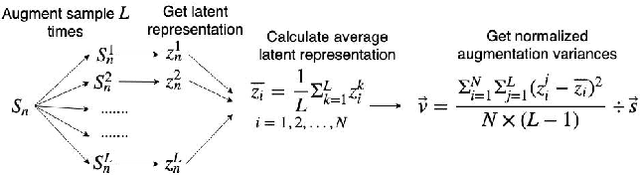
Analogy-making is a key method for computer algorithms to generate both natural and creative music pieces. In general, an analogy is made by partially transferring the music abstractions, i.e., high-level representations and their relationships, from one piece to another; however, this procedure requires disentangling music representations, which usually takes little effort for musicians but is non-trivial for computers. Three sub-problems arise: extracting latent representations from the observation, disentangling the representations so that each part has a unique semantic interpretation, and mapping the latent representations back to actual music. In this paper, we contribute an explicitly-constrained variational autoencoder (EC$^2$-VAE) as a unified solution to all three sub-problems. We focus on disentangling the pitch and rhythm representations of 8-beat music clips conditioned on chords. In producing music analogies, this model helps us to realize the imaginary situation of "what if" a piece is composed using a different pitch contour, rhythm pattern, or chord progression by borrowing the representations from other pieces. Finally, we validate the proposed disentanglement method using objective measurements and evaluate the analogy examples by a subjective study.
A-Muze-Net: Music Generation by Composing the Harmony based on the Generated Melody
Nov 25, 2021
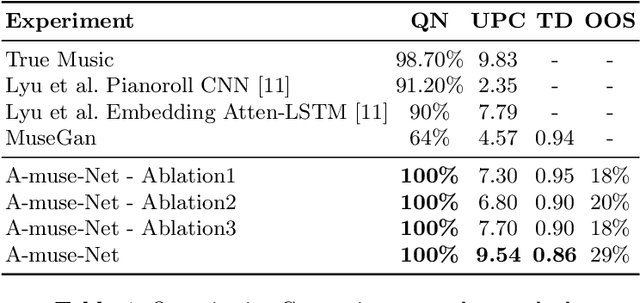

We present a method for the generation of Midi files of piano music. The method models the right and left hands using two networks, where the left hand is conditioned on the right hand. This way, the melody is generated before the harmony. The Midi is represented in a way that is invariant to the musical scale, and the melody is represented, for the purpose of conditioning the harmony, by the content of each bar, viewed as a chord. Finally, notes are added randomly, based on this chord representation, in order to enrich the generated audio. Our experiments show a significant improvement over the state of the art for training on such datasets, and demonstrate the contribution of each of the novel components.
Receptive-Field Regularized CNNs for Music Classification and Tagging
Jul 27, 2020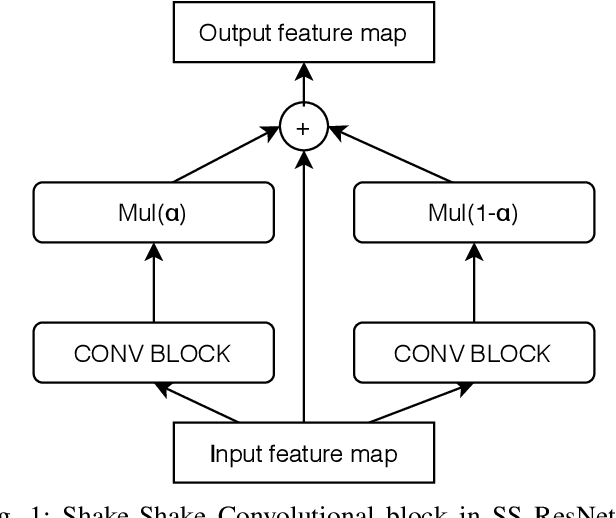
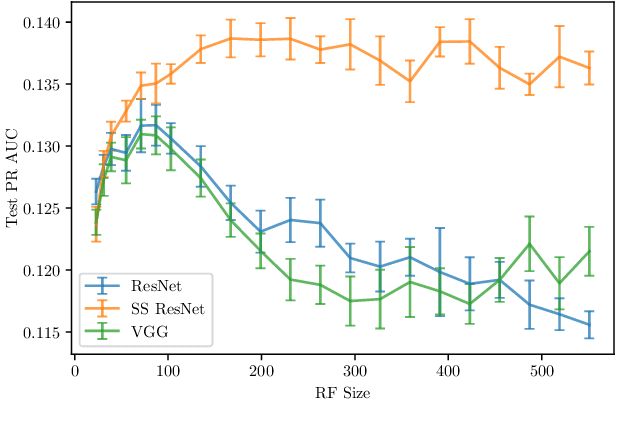
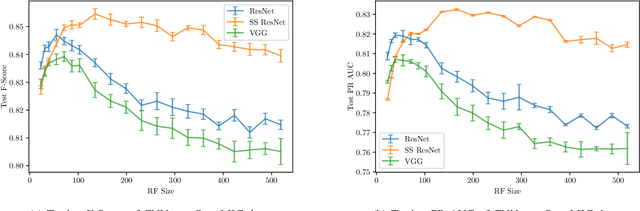
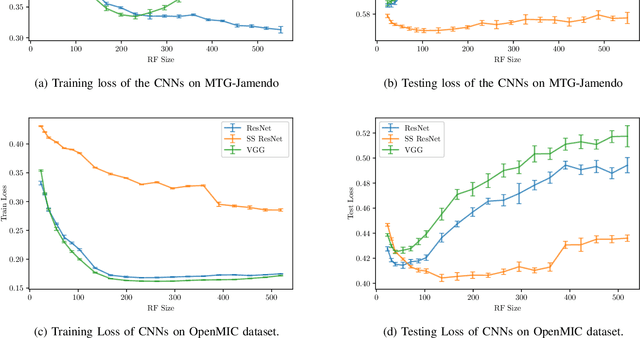
Convolutional Neural Networks (CNNs) have been successfully used in various Music Information Retrieval (MIR) tasks, both as end-to-end models and as feature extractors for more complex systems. However, the MIR field is still dominated by the classical VGG-based CNN architecture variants, often in combination with more complex modules such as attention, and/or techniques such as pre-training on large datasets. Deeper models such as ResNet -- which surpassed VGG by a large margin in other domains -- are rarely used in MIR. One of the main reasons for this, as we will show, is the lack of generalization of deeper CNNs in the music domain. In this paper, we present a principled way to make deep architectures like ResNet competitive for music-related tasks, based on well-designed regularization strategies. In particular, we analyze the recently introduced Receptive-Field Regularization and Shake-Shake, and show that they significantly improve the generalization of deep CNNs on music-related tasks, and that the resulting deep CNNs can outperform current more complex models such as CNNs augmented with pre-training and attention. We demonstrate this on two different MIR tasks and two corresponding datasets, thus offering our deep regularized CNNs as a new baseline for these datasets, which can also be used as a feature-extracting module in future, more complex approaches.