 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Exploring single-song autoencoding schemes for audio-based music structure analysis
Oct 27, 2021
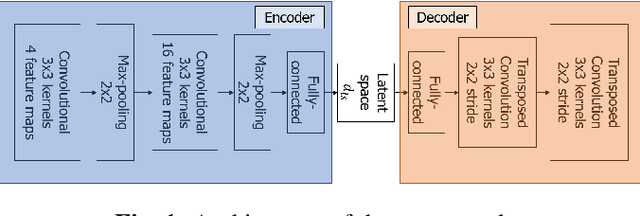
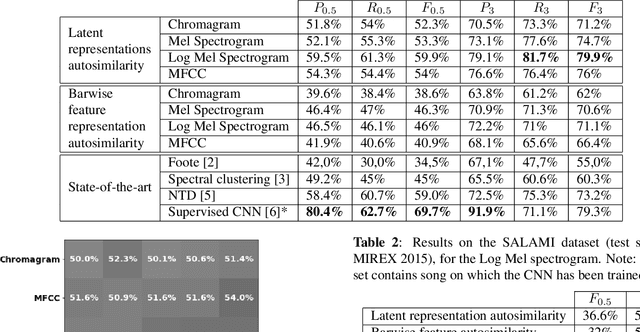
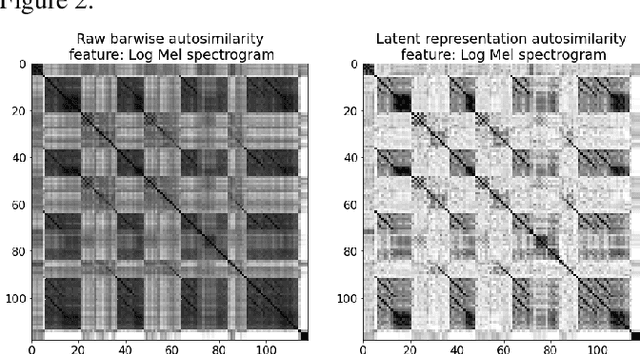

The ability of deep neural networks to learn complex data relations and representations is established nowadays, but it generally relies on large sets of training data. This work explores a "piece-specific" autoencoding scheme, in which a low-dimensional autoencoder is trained to learn a latent/compressed representation specific to a given song, which can then be used to infer the song structure. Such a model does not rely on supervision nor annotations, which are well-known to be tedious to collect and often ambiguous in Music Structure Analysis. We report that the proposed unsupervised auto-encoding scheme achieves the level of performance of supervised state-of-the-art methods with 3 seconds tolerance when using a Log Mel spectrogram representation on the RWC-Pop dataset.
Dance Revolution: Long Sequence Dance Generation with Music via Curriculum Learning
Jun 14, 2020
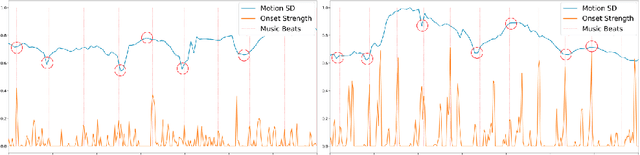

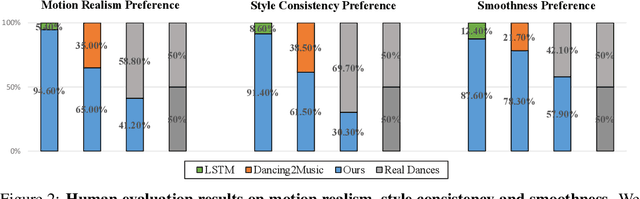
Dancing to music is one of human's innate abilities since ancient times. In artificial intelligence research, however, synthesizing dance movements (complex human motion) from music is a challenging problem, which suffers from the high spatial-temporal complexity in human motion dynamics modeling. Besides, the consistency of dance and music in terms of style, rhythm and beat also needs to be taken into account. Existing works focus on the short-term dance generation with music, e.g. less than 30 seconds. In this paper, we propose a novel seq2seq architecture for long sequence dance generation with music, which consists of a transformer based music encoder and a recurrent structure based dance decoder. By restricting the receptive field of self-attention, our encoder can efficiently process long musical sequences by reducing its quadratic memory requirements to the linear in the sequence length. To further alleviate the error accumulation in human motion synthesis, we introduce a dynamic auto-condition training strategy as a new curriculum learning method to facilitate the long-term dance generation. Extensive experiments demonstrate that our proposed approach significantly outperforms existing methods on both automatic metrics and human evaluation. Additionally, we also make a demo video to exhibit that our approach can generate minute-length dance sequences that are smooth, natural-looking, diverse, style-consistent and beat-matching with the music. The demo video is now available at https://www.youtube.com/watch?v=P6yhfv3vpDI.
Rigid-Body Sound Synthesis with Differentiable Modal Resonators
Oct 28, 2022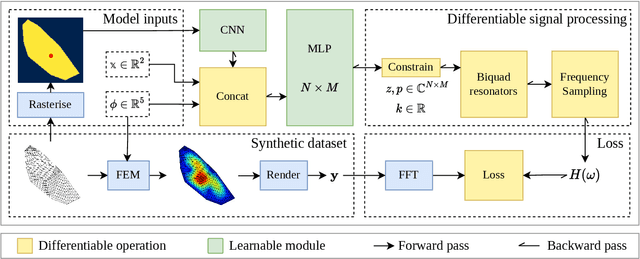

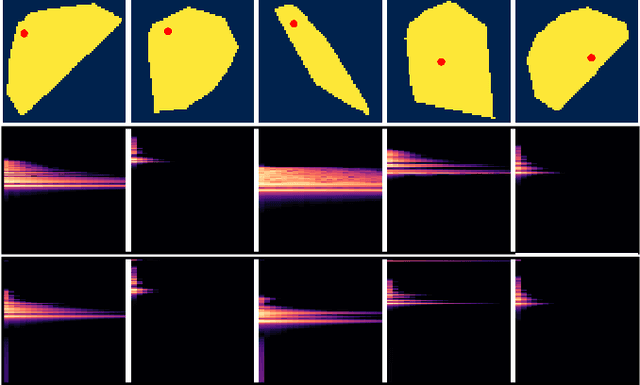
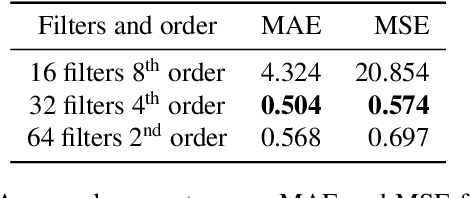
Physical models of rigid bodies are used for sound synthesis in applications from virtual environments to music production. Traditional methods such as modal synthesis often rely on computationally expensive numerical solvers, while recent deep learning approaches are limited by post-processing of their results. In this work we present a novel end-to-end framework for training a deep neural network to generate modal resonators for a given 2D shape and material, using a bank of differentiable IIR filters. We demonstrate our method on a dataset of synthetic objects, but train our model using an audio-domain objective, paving the way for physically-informed synthesisers to be learned directly from recordings of real-world objects.
Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
Jan 07, 2021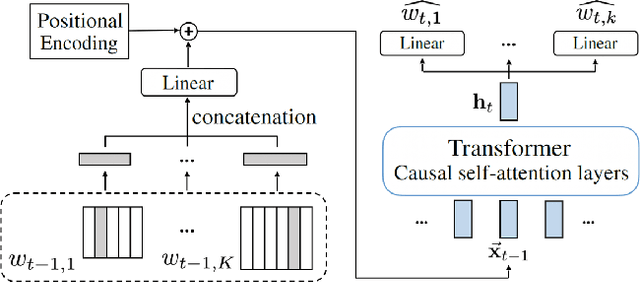
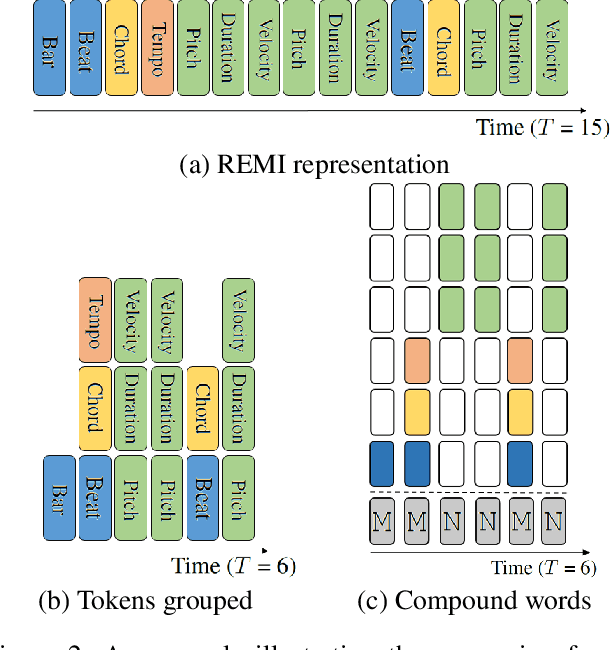

To apply neural sequence models such as the Transformers to music generation tasks, one has to represent a piece of music by a sequence of tokens drawn from a finite set of pre-defined vocabulary. Such a vocabulary usually involves tokens of various types. For example, to describe a musical note, one needs separate tokens to indicate the note's pitch, duration, velocity (dynamics), and placement (onset time) along the time grid. While different types of tokens may possess different properties, existing models usually treat them equally, in the same way as modeling words in natural languages. In this paper, we present a conceptually different approach that explicitly takes into account the type of the tokens, such as note types and metric types. And, we propose a new Transformer decoder architecture that uses different feed-forward heads to model tokens of different types. With an expansion-compression trick, we convert a piece of music to a sequence of compound words by grouping neighboring tokens, greatly reducing the length of the token sequences. We show that the resulting model can be viewed as a learner over dynamic directed hypergraphs. And, we employ it to learn to compose expressive Pop piano music of full-song length (involving up to 10K individual tokens per song), both conditionally and unconditionally. Our experiment shows that, compared to state-of-the-art models, the proposed model converges 5--10 times faster at training (i.e., within a day on a single GPU with 11 GB memory), and with comparable quality in the generated music.
NANSY++: Unified Voice Synthesis with Neural Analysis and Synthesis
Nov 17, 2022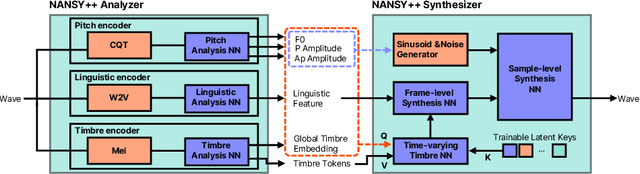
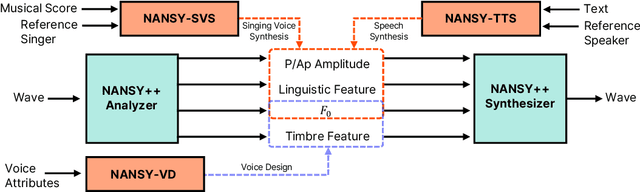

Various applications of voice synthesis have been developed independently despite the fact that they generate "voice" as output in common. In addition, most of the voice synthesis models still require a large number of audio data paired with annotated labels (e.g., text transcription and music score) for training. To this end, we propose a unified framework of synthesizing and manipulating voice signals from analysis features, dubbed NANSY++. The backbone network of NANSY++ is trained in a self-supervised manner that does not require any annotations paired with audio. After training the backbone network, we efficiently tackle four voice applications - i.e. voice conversion, text-to-speech, singing voice synthesis, and voice designing - by partially modeling the analysis features required for each task. Extensive experiments show that the proposed framework offers competitive advantages such as controllability, data efficiency, and fast training convergence, while providing high quality synthesis. Audio samples: tinyurl.com/8tnsy3uc.
Synthesizer Preset Interpolation using Transformer Auto-Encoders
Oct 27, 2022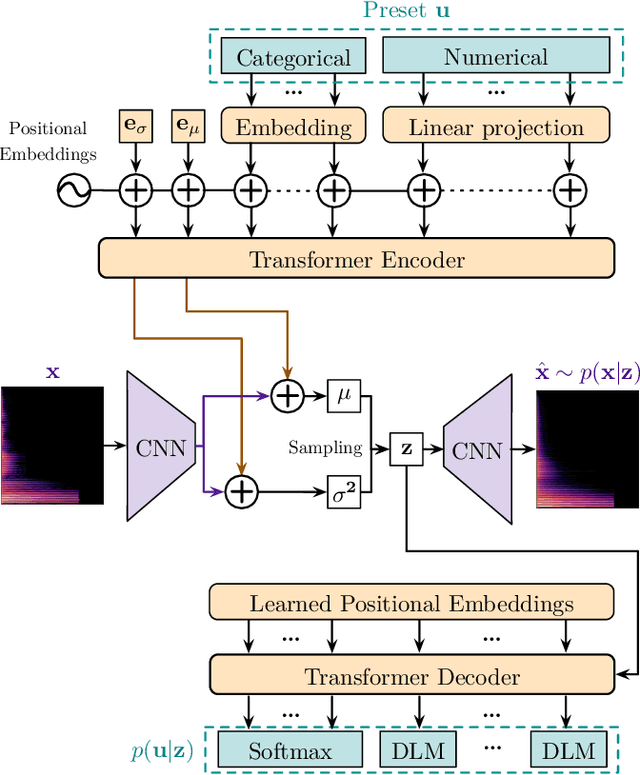
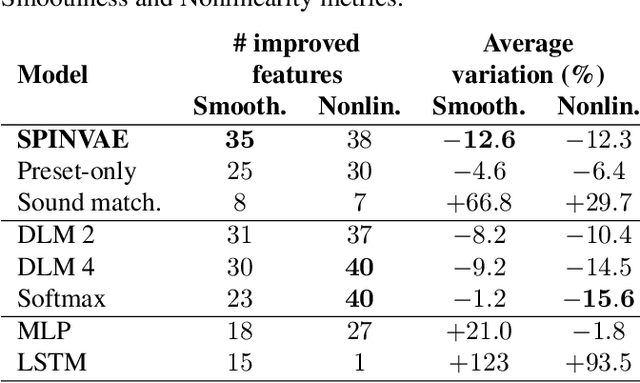
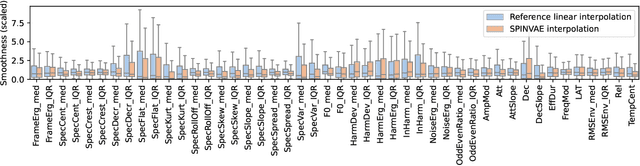
Sound synthesizers are widespread in modern music production but they increasingly require expert skills to be mastered. This work focuses on interpolation between presets, i.e., sets of values of all sound synthesis parameters, to enable the intuitive creation of new sounds from existing ones. We introduce a bimodal auto-encoder neural network, which simultaneously processes presets using multi-head attention blocks, and audio using convolutions. This model has been tested on a popular frequency modulation synthesizer with more than one hundred parameters. Experiments have compared the model to related architectures and methods, and have demonstrated that it performs smoother interpolations. After training, the proposed model can be integrated into commercial synthesizers for live interpolation or sound design tasks.
Towards Music Captioning: Generating Music Playlist Descriptions
Jan 15, 2017
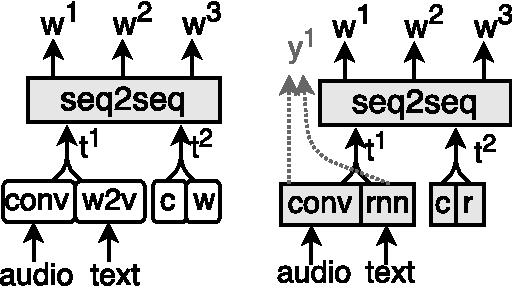
Descriptions are often provided along with recommendations to help users' discovery. Recommending automatically generated music playlists (e.g. personalised playlists) introduces the problem of generating descriptions. In this paper, we propose a method for generating music playlist descriptions, which is called as music captioning. In the proposed method, audio content analysis and natural language processing are adopted to utilise the information of each track.
A framework to compare music generative models using automatic evaluation metrics extended to rhythm
Jan 19, 2021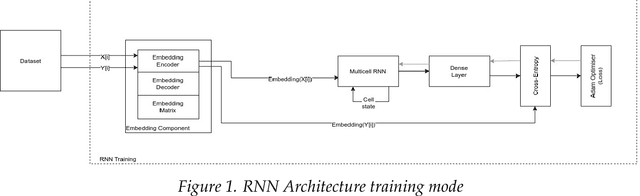
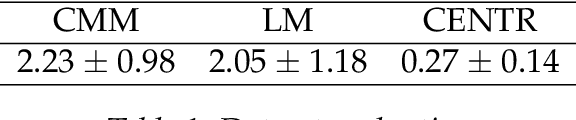
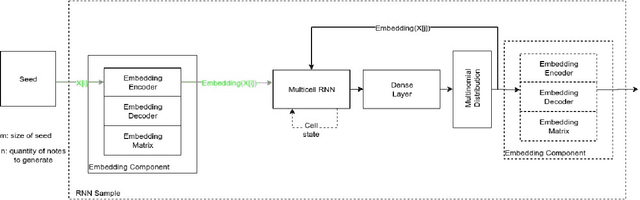

To train a machine learning model is necessary to take numerous decisions about many options for each process involved, in the field of sequence generation and more specifically of music composition, the nature of the problem helps to narrow the options but at the same time, some other options appear for specific challenges. This paper takes the framework proposed in a previous research that did not consider rhythm to make a series of design decisions, then, rhythm support is added to evaluate the performance of two RNN memory cells in the creation of monophonic music. The model considers the handling of music transposition and the framework evaluates the quality of the generated pieces using automatic quantitative metrics based on geometry which have rhythm support added as well.
Composer Style Classification of Piano Sheet Music Images Using Language Model Pretraining
Jul 29, 2020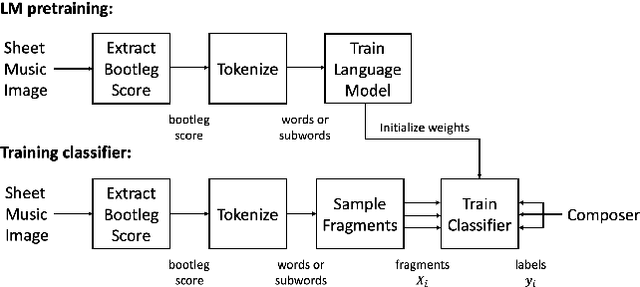

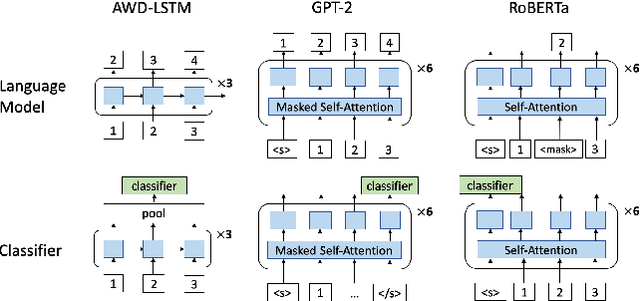
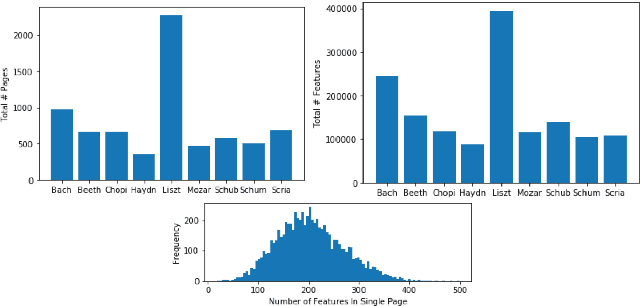
This paper studies composer style classification of piano sheet music images. Previous approaches to the composer classification task have been limited by a scarcity of data. We address this issue in two ways: (1) we recast the problem to be based on raw sheet music images rather than a symbolic music format, and (2) we propose an approach that can be trained on unlabeled data. Our approach first converts the sheet music image into a sequence of musical "words" based on the bootleg feature representation, and then feeds the sequence into a text classifier. We show that it is possible to significantly improve classifier performance by first training a language model on a set of unlabeled data, initializing the classifier with the pretrained language model weights, and then finetuning the classifier on a small amount of labeled data. We train AWD-LSTM, GPT-2, and RoBERTa language models on all piano sheet music images in IMSLP. We find that transformer-based architectures outperform CNN and LSTM models, and pretraining boosts classification accuracy for the GPT-2 model from 46\% to 70\% on a 9-way classification task. The trained model can also be used as a feature extractor that projects piano sheet music into a feature space that characterizes compositional style.