 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
SCNet: Sparse Compression Network for Music Source Separation
Jan 24, 2024
Deep learning-based methods have made significant achievements in music source separation. However, obtaining good results while maintaining a low model complexity remains challenging in super wide-band music source separation. Previous works either overlook the differences in subbands or inadequately address the problem of information loss when generating subband features. In this paper, we propose SCNet, a novel frequency-domain network to explicitly split the spectrogram of the mixture into several subbands and introduce a sparsity-based encoder to model different frequency bands. We use a higher compression ratio on subbands with less information to improve the information density and focus on modeling subbands with more information. In this way, the separation performance can be significantly improved using lower computational consumption. Experiment results show that the proposed model achieves a signal to distortion ratio (SDR) of 9.0 dB on the MUSDB18-HQ dataset without using extra data, which outperforms state-of-the-art methods. Specifically, SCNet's CPU inference time is only 48% of HT Demucs, one of the previous state-of-the-art models.
Spiking Music: Audio Compression with Event Based Auto-encoders
Feb 02, 2024Neurons in the brain communicate information via punctual events called spikes. The timing of spikes is thought to carry rich information, but it is not clear how to leverage this in digital systems. We demonstrate that event-based encoding is efficient for audio compression. To build this event-based representation we use a deep binary auto-encoder, and under high sparsity pressure, the model enters a regime where the binary event matrix is stored more efficiently with sparse matrix storage algorithms. We test this on the large MAESTRO dataset of piano recordings against vector quantized auto-encoders. Not only does our "Spiking Music compression" algorithm achieve a competitive compression/reconstruction trade-off, but selectivity and synchrony between encoded events and piano key strikes emerge without supervision in the sparse regime.
MoodLoopGP: Generating Emotion-Conditioned Loop Tablature Music with Multi-Granular Features
Jan 25, 2024Loopable music generation systems enable diverse applications, but they often lack controllability and customization capabilities. We argue that enhancing controllability can enrich these models, with emotional expression being a crucial aspect for both creators and listeners. Hence, building upon LooperGP, a loopable tablature generation model, this paper explores endowing systems with control over conveyed emotions. To enable such conditional generation, we propose integrating musical knowledge by utilizing multi-granular semantic and musical features during model training and inference. Specifically, we incorporate song-level features (Emotion Labels, Tempo, and Mode) and bar-level features (Tonal Tension) together to guide emotional expression. Through algorithmic and human evaluations, we demonstrate the approach's effectiveness in producing music conveying two contrasting target emotions, happiness and sadness. An ablation study is also conducted to clarify the contributing factors behind our approach's results.
Answering Diverse Questions via Text Attached with Key Audio-Visual Clues
Mar 11, 2024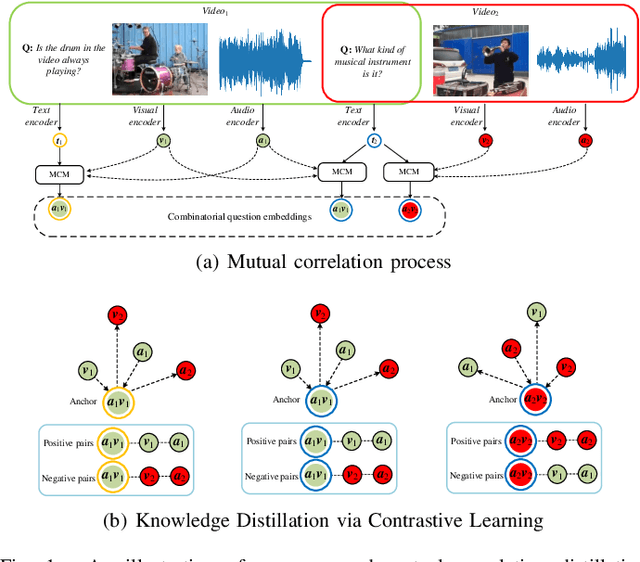
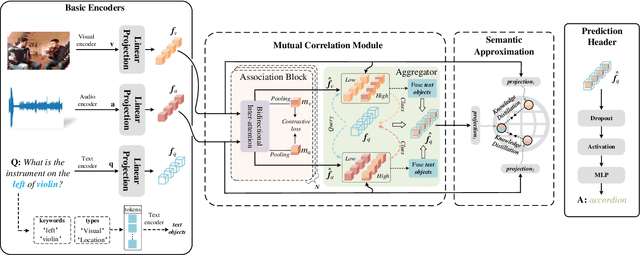
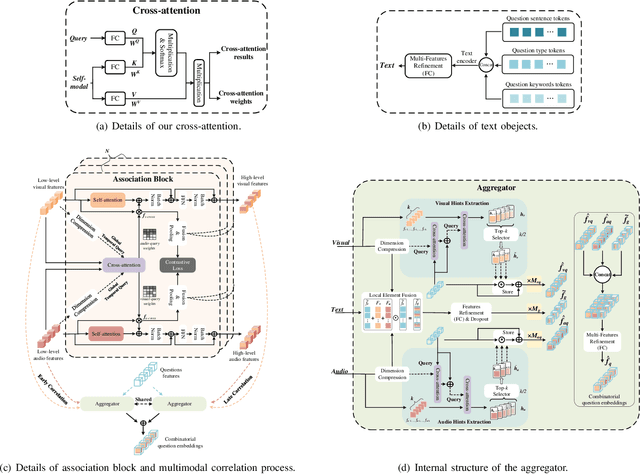
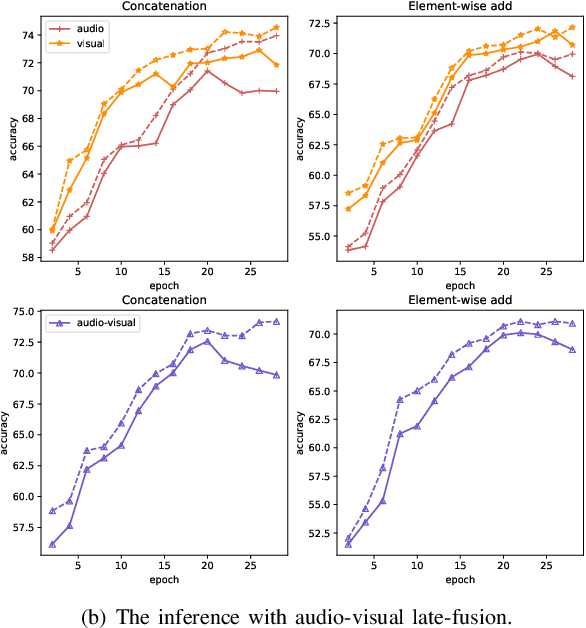
Audio-visual question answering (AVQA) requires reference to video content and auditory information, followed by correlating the question to predict the most precise answer. Although mining deeper layers of audio-visual information to interact with questions facilitates the multimodal fusion process, the redundancy of audio-visual parameters tends to reduce the generalization of the inference engine to multiple question-answer pairs in a single video. Indeed, the natural heterogeneous relationship between audiovisuals and text makes the perfect fusion challenging, to prevent high-level audio-visual semantics from weakening the network's adaptability to diverse question types, we propose a framework for performing mutual correlation distillation (MCD) to aid question inference. MCD is divided into three main steps: 1) firstly, the residual structure is utilized to enhance the audio-visual soft associations based on self-attention, then key local audio-visual features relevant to the question context are captured hierarchically by shared aggregators and coupled in the form of clues with specific question vectors. 2) Secondly, knowledge distillation is enforced to align audio-visual-text pairs in a shared latent space to narrow the cross-modal semantic gap. 3) And finally, the audio-visual dependencies are decoupled by discarding the decision-level integrations. We evaluate the proposed method on two publicly available datasets containing multiple question-and-answer pairs, i.e., Music-AVQA and AVQA. Experiments show that our method outperforms other state-of-the-art methods, and one interesting finding behind is that removing deep audio-visual features during inference can effectively mitigate overfitting. The source code is released at http://github.com/rikeilong/MCD-forAVQA.
DITTO: Diffusion Inference-Time T-Optimization for Music Generation
Jan 22, 2024We propose Diffusion Inference-Time T-Optimization (DITTO), a general-purpose frame-work for controlling pre-trained text-to-music diffusion models at inference-time via optimizing initial noise latents. Our method can be used to optimize through any differentiable feature matching loss to achieve a target (stylized) output and leverages gradient checkpointing for memory efficiency. We demonstrate a surprisingly wide-range of applications for music generation including inpainting, outpainting, and looping as well as intensity, melody, and musical structure control - all without ever fine-tuning the underlying model. When we compare our approach against related training, guidance, and optimization-based methods, we find DITTO achieves state-of-the-art performance on nearly all tasks, including outperforming comparable approaches on controllability, audio quality, and computational efficiency, thus opening the door for high-quality, flexible, training-free control of diffusion models. Sound examples can be found at https://DITTO-Music.github.io/web/.
Room Impulse Response Estimation using Optimal Transport: Simulation-Informed Inference
Mar 06, 2024The ability to accurately estimate room impulse responses (RIRs) is integral to many applications of spatial audio processing. Regrettably, estimating the RIR using ambient signals, such as speech or music, remains a challenging problem due to, e.g., low signal-to-noise ratios, finite sample lengths, and poor spectral excitation. Commonly, in order to improve the conditioning of the estimation problem, priors are placed on the amplitudes of the RIR. Although serving as a regularizer, this type of prior is generally not useful when only approximate knowledge of the delay structure is available, which, for example, is the case when the prior is a simulated RIR from an approximation of the room geometry. In this work, we target the delay structure itself, constructing a prior based on the concept of optimal transport. As illustrated using both simulated and measured data, the resulting method is able to beneficially incorporate information even from simple simulation models, displaying considerable robustness to perturbations in the assumed room dimensions and its temperature.
Generating Rhythm Game Music with Jukebox
Dec 29, 2023Music has always been thought of as a "human" endeavor -- when praising a piece of music, we emphasize the composer's creativity and the emotions the music invokes. Because music also heavily relies on patterns and repetition in the form of recurring melodic themes and chord progressions, artificial intelligence has increasingly been able to replicate music in a human-like fashion. This research investigated the capabilities of Jukebox, an open-source commercially available neural network, to accurately replicate two genres of music often found in rhythm games, artcore and orchestral. A Google Colab notebook provided the computational resources necessary to sample and extend a total of sixteen piano arrangements of both genres. A survey containing selected samples was distributed to a local youth orchestra to gauge people's perceptions of the musicality of AI and human-generated music. Even though humans preferred human-generated music, Jukebox's slightly high rating showed that it was somewhat capable at mimicking the styles of both genres. Despite limitations of Jukebox only using raw audio and a relatively small sample size, it shows promise for the future of AI as a collaborative tool in music production.
Toward Fully Self-Supervised Multi-Pitch Estimation
Feb 23, 2024Multi-pitch estimation is a decades-long research problem involving the detection of pitch activity associated with concurrent musical events within multi-instrument mixtures. Supervised learning techniques have demonstrated solid performance on more narrow characterizations of the task, but suffer from limitations concerning the shortage of large-scale and diverse polyphonic music datasets with multi-pitch annotations. We present a suite of self-supervised learning objectives for multi-pitch estimation, which encourage the concentration of support around harmonics, invariance to timbral transformations, and equivariance to geometric transformations. These objectives are sufficient to train an entirely convolutional autoencoder to produce multi-pitch salience-grams directly, without any fine-tuning. Despite training exclusively on a collection of synthetic single-note audio samples, our fully self-supervised framework generalizes to polyphonic music mixtures, and achieves performance comparable to supervised models trained on conventional multi-pitch datasets.
Expressivity-aware Music Performance Retrieval using Mid-level Perceptual Features and Emotion Word Embeddings
Jan 26, 2024This paper explores a specific sub-task of cross-modal music retrieval. We consider the delicate task of retrieving a performance or rendition of a musical piece based on a description of its style, expressive character, or emotion from a set of different performances of the same piece. We observe that a general purpose cross-modal system trained to learn a common text-audio embedding space does not yield optimal results for this task. By introducing two changes -- one each to the text encoder and the audio encoder -- we demonstrate improved performance on a dataset of piano performances and associated free-text descriptions. On the text side, we use emotion-enriched word embeddings (EWE) and on the audio side, we extract mid-level perceptual features instead of generic audio embeddings. Our results highlight the effectiveness of mid-level perceptual features learnt from music and emotion enriched word embeddings learnt from emotion-labelled text in capturing musical expression in a cross-modal setting. Additionally, our interpretable mid-level features provide a route for introducing explainability in the retrieval and downstream recommendation processes.
Arbitrary Discrete Fourier Analysis and Its Application in Replayed Speech Detection
Mar 02, 2024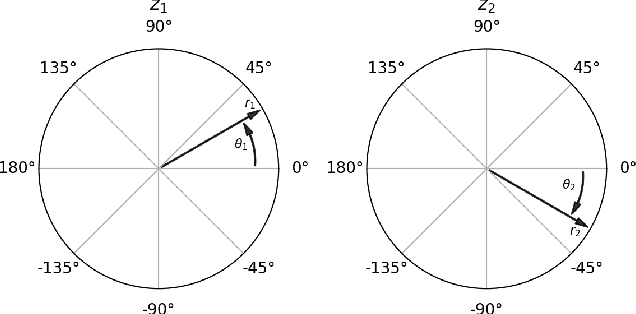
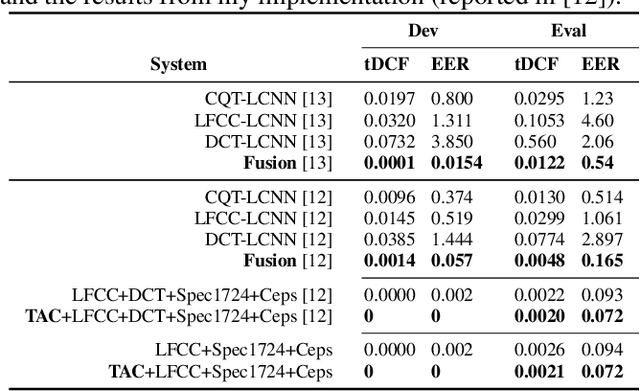
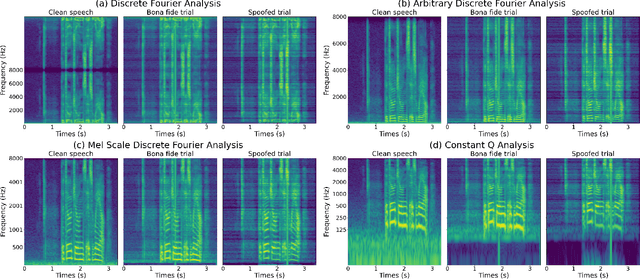
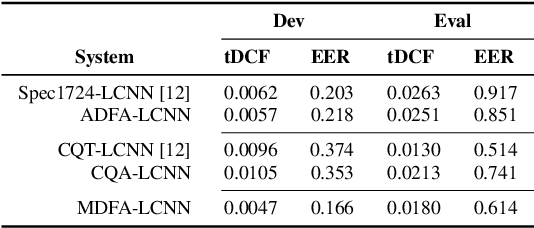
In this paper, a signal analysis concept is derived when revisiting how a specific frequency component in spectrum is analyzed in Fourier analysis. Three signal analysis methods are then developed based on the derived concept, namely Arbitrary Discrete Fourier Analysis (ADFA), Mel-scale Discrete Fourier Analysis (MDFA), and constant Q Analysis (CQA). I validate the effectiveness of these three signal analysis methods by testing their performance on a replayed speech detection benchmark (i.e., the ASVspoof 2019 Physical Access) along with a state-of-the-art model. Experimental results show that the performance of these three signal analysis methods is comparable to the best reported systems. At the same time, it is show that the computation time of the developed method CQA is much shorter than the convention method constant Q Transform, which is commonly used in spoofed and fake speech detection and music processing.