 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Scaling and compressing melodies using geometric similarity measures
Sep 19, 2022
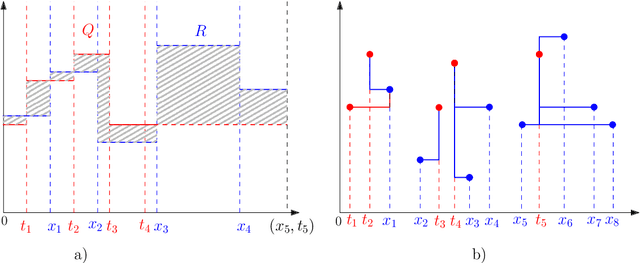
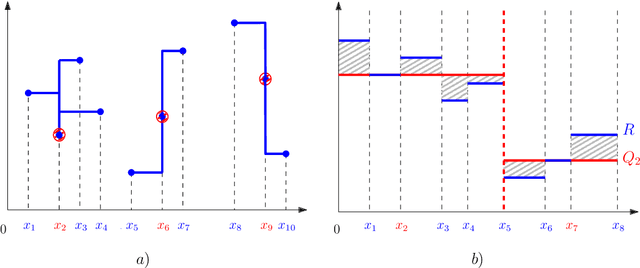

Melodic similarity measurement is of key importance in music information retrieval. In this paper, we use geometric matching techniques to measure the similarity between two melodies. We represent music as sets of points or sets of horizontal line segments in the Euclidean plane and propose efficient algorithms for optimization problems inspired in two operations on melodies; linear scaling and audio compression. In the scaling problem, an incoming query melody is scaled forward until the similarity measure between the query and a reference melody is minimized. The compression problem asks for a subset of notes of a given melody such that the matching cost between the selected notes and the reference melody is minimized.
A Human-Computer Duet System for Music Performance
Sep 16, 2020
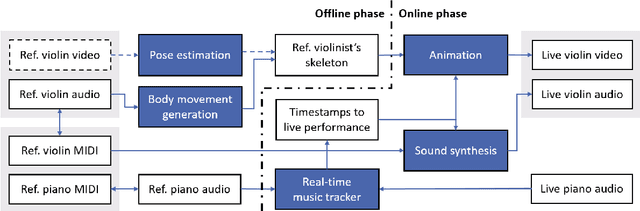
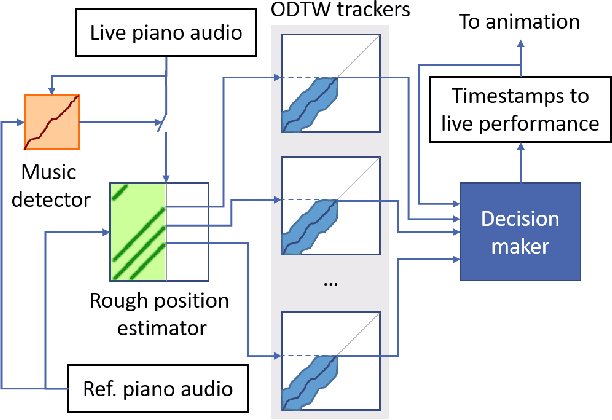
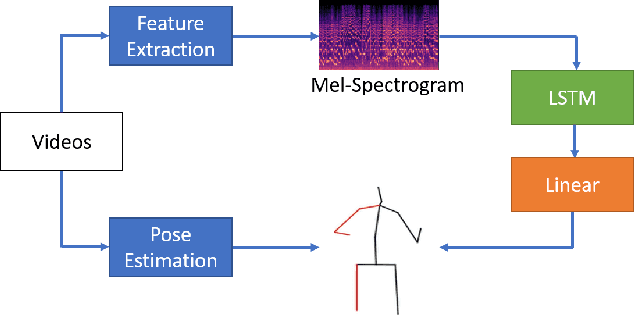
Virtual musicians have become a remarkable phenomenon in the contemporary multimedia arts. However, most of the virtual musicians nowadays have not been endowed with abilities to create their own behaviors, or to perform music with human musicians. In this paper, we firstly create a virtual violinist, who can collaborate with a human pianist to perform chamber music automatically without any intervention. The system incorporates the techniques from various fields, including real-time music tracking, pose estimation, and body movement generation. In our system, the virtual musician's behavior is generated based on the given music audio alone, and such a system results in a low-cost, efficient and scalable way to produce human and virtual musicians' co-performance. The proposed system has been validated in public concerts. Objective quality assessment approaches and possible ways to systematically improve the system are also discussed.
Extract fundamental frequency based on CNN combined with PYIN
Aug 17, 2022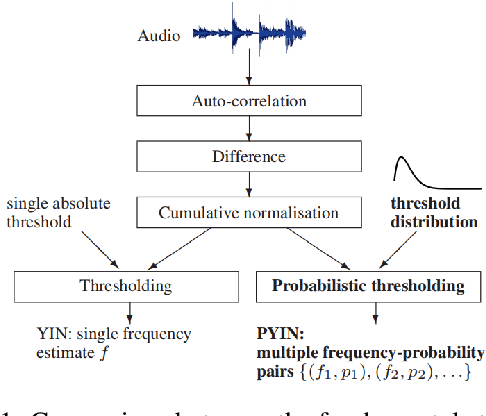
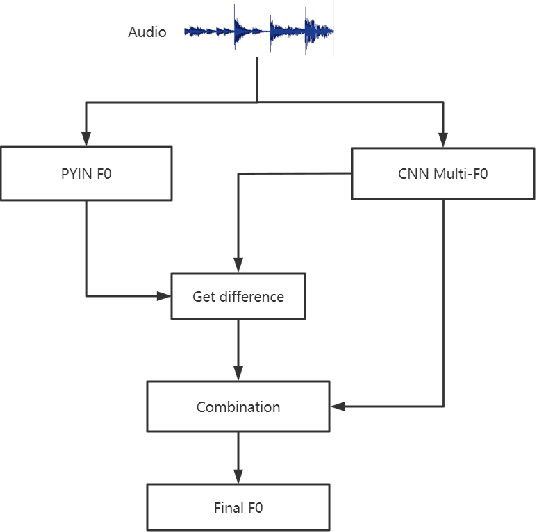
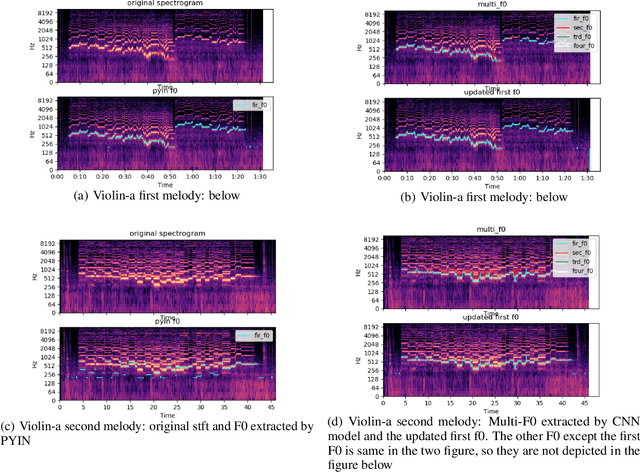
This paper refers to the extraction of multiple fundamental frequencies (multiple F0) based on PYIN, an algorithm for extracting the fundamental frequency (F0) of monophonic music, and a trained convolutional neural networks (CNN) model, where a pitch salience function of the input signal is produced to estimate the multiple F0. The implementation of these two algorithms and their corresponding advantages and disadvantages are discussed in this article. Analysing the different performance of these two methods, PYIN is applied to supplement the F0 extracted from the trained CNN model to combine the advantages of these two algorithms. For evaluation, four pieces played by two violins are used, and the performance of the models are evaluated accoring to the flatness of the F0 curve extracted. The result shows the combined model outperforms the original algorithms when extracting F0 from monophonic music and polyphonic music.
Learning to rank music tracks using triplet loss
May 18, 2020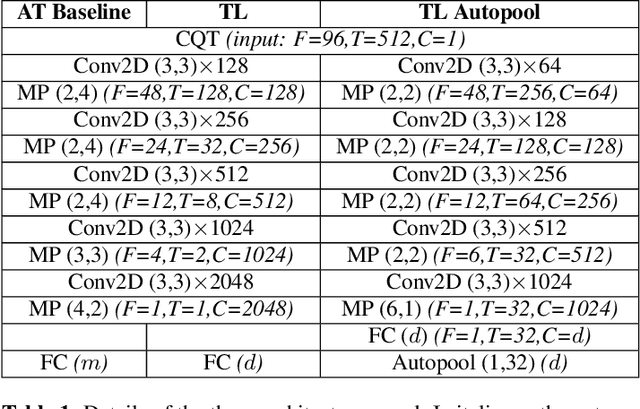
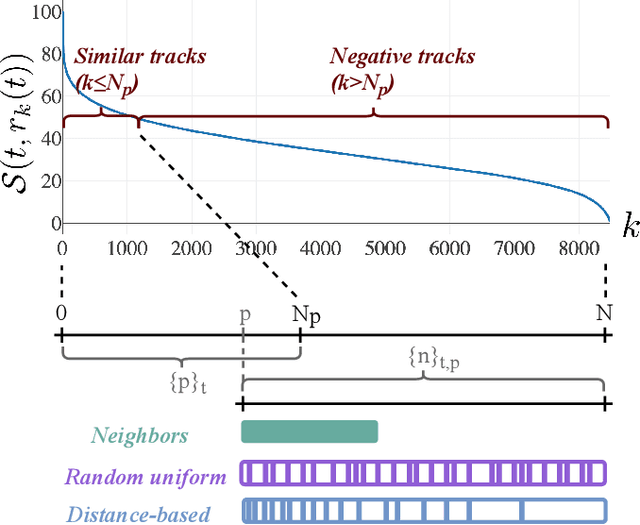
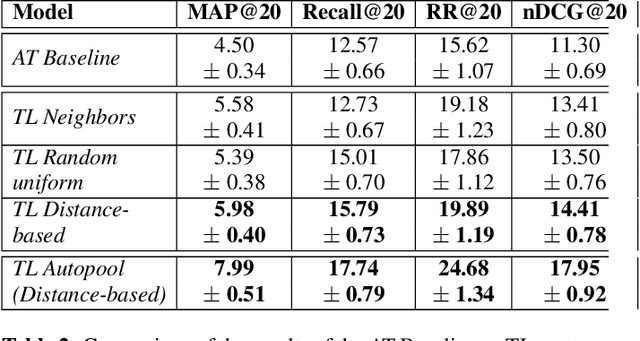
Most music streaming services rely on automatic recommendation algorithms to exploit their large music catalogs. These algorithms aim at retrieving a ranked list of music tracks based on their similarity with a target music track. In this work, we propose a method for direct recommendation based on the audio content without explicitly tagging the music tracks. To that aim, we propose several strategies to perform triplet mining from ranked lists. We train a Convolutional Neural Network to learn the similarity via triplet loss. These different strategies are compared and validated on a large-scale experiment against an auto-tagging based approach. The results obtained highlight the efficiency of our system, especially when associated with an Auto-pooling layer.
Incorporating Music Knowledge in Continual Dataset Augmentation for Music Generation
Jun 25, 2020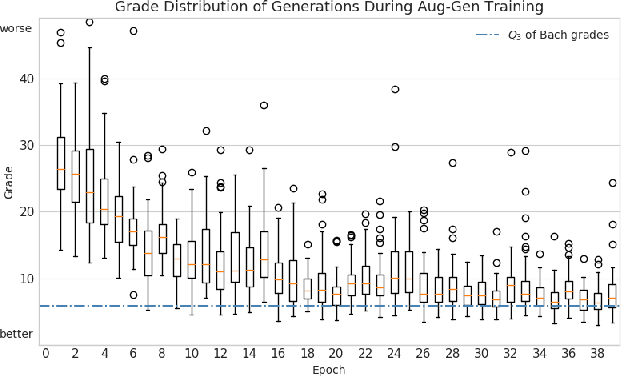
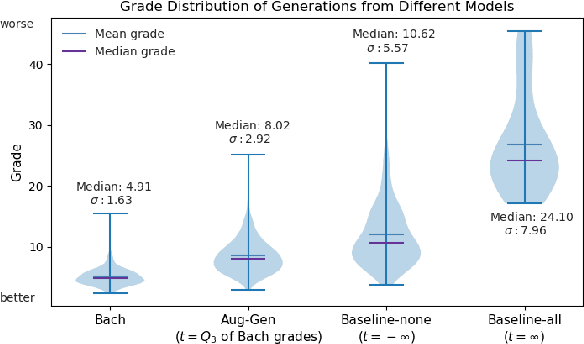
Deep learning has rapidly become the state-of-the-art approach for music generation. However, training a deep model typically requires a large training set, which is often not available for specific musical styles. In this paper, we present augmentative generation (Aug-Gen), a method of dataset augmentation for any music generation system trained on a resource-constrained domain. The key intuition of this method is that the training data for a generative system can be augmented by examples the system produces during the course of training, provided these examples are of sufficiently high quality and variety. We apply Aug-Gen to Transformer-based chorale generation in the style of J.S. Bach, and show that this allows for longer training and results in better generative output.
MYRiAD: A Multi-Array Room Acoustic Database
Jan 30, 2023
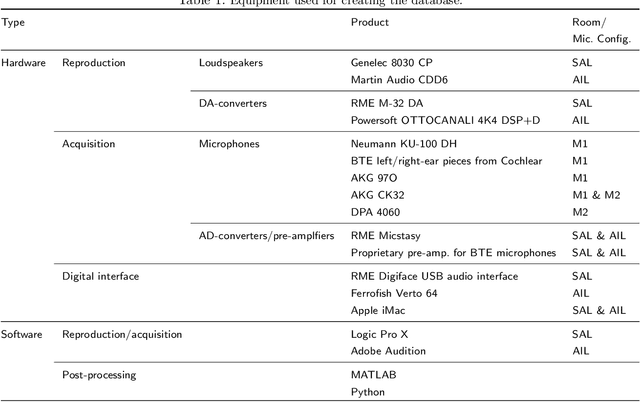

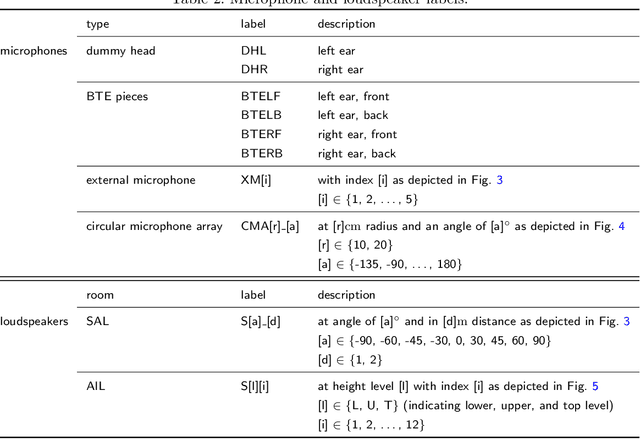
In the development of acoustic signal processing algorithms, their evaluation in various acoustic environments is of utmost importance. In order to advance evaluation in realistic and reproducible scenarios, several high-quality acoustic databases have been developed over the years. In this paper, we present another complementary database of acoustic recordings, referred to as the Multi-arraY Room Acoustic Database (MYRiAD). The MYRiAD database is unique in its diversity of microphone configurations suiting a wide range of enhancement and reproduction applications (such as assistive hearing, teleconferencing, or sound zoning), the acoustics of the two recording spaces, and the variety of contained signals including 1214 room impulse responses (RIRs), reproduced speech, music, and stationary noise, as well as recordings of live cocktail parties held in both rooms. The microphone configurations comprise a dummy head (DH) with in-ear omnidirectional microphones, two behind-the-ear (BTE) pieces equipped with 2 omnidirectional microphones each, 5 external omnidirectional microphones (XMs), and two concentric circular microphone arrays (CMAs) consisting of 12 omnidirectional microphones in total. The two recording spaces, namely the SONORA Audio Laboratory (SAL) and the Alamire Interactive Laboratory (AIL), have reverberation times of 2.1s and 0.5s, respectively. Audio signals were reproduced using 10 movable loudspeakers in the SAL and a built-in array of 24 loudspeakers in the AIL. MATLAB and Python scripts are included for accessing the signals as well as microphone and loudspeaker coordinates. The database is publicly available at [1].
A Study of Transfer Learning in Music Source Separation
Oct 23, 2020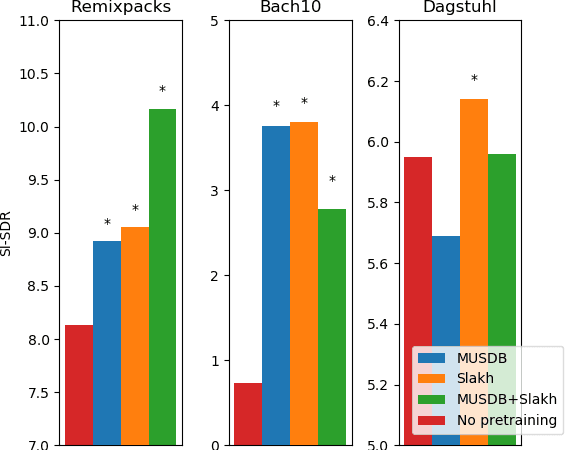
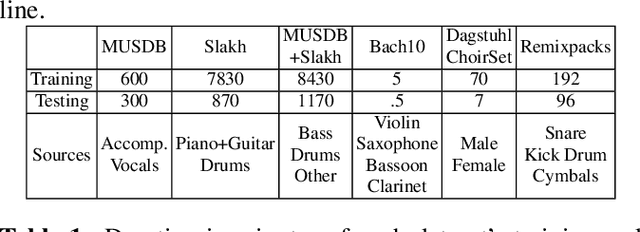
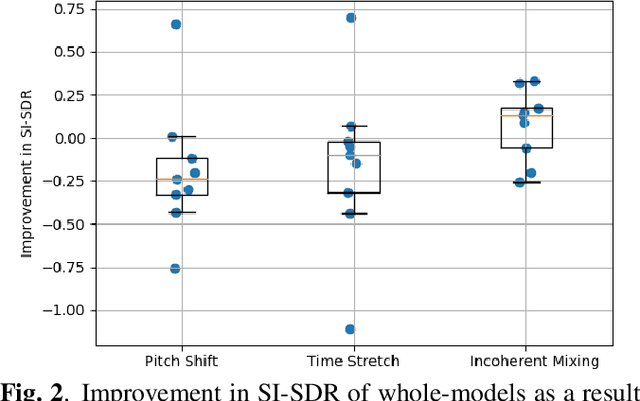
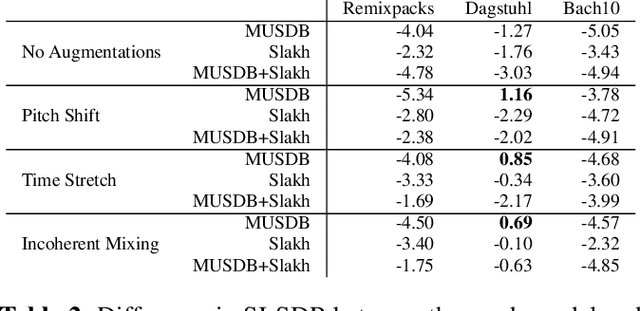
Supervised deep learning methods for performing audio source separation can be very effective in domains where there is a large amount of training data. While some music domains have enough data suitable for training a separation system, such as rock and pop genres, many musical domains do not, such as classical music, choral music, and non-Western music traditions. It is well known that transferring learning from related domains can result in a performance boost for deep learning systems, but it is not always clear how best to do pretraining. In this work we investigate the effectiveness of data augmentation during pretraining, the impact on performance as a result of pretraining and downstream datasets having similar content domains, and also explore how much of a model must be retrained on the final target task, once pretrained.
General Theory of Music by Icosahedron 3: Musical invariant and Melakarta raga
Sep 26, 2021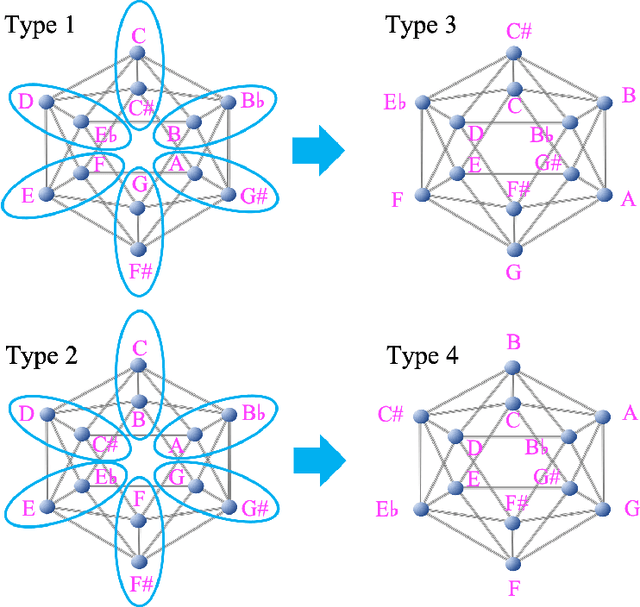
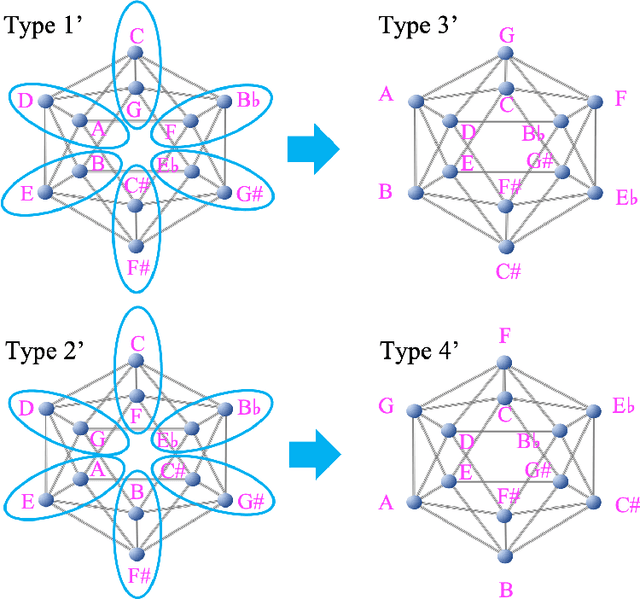
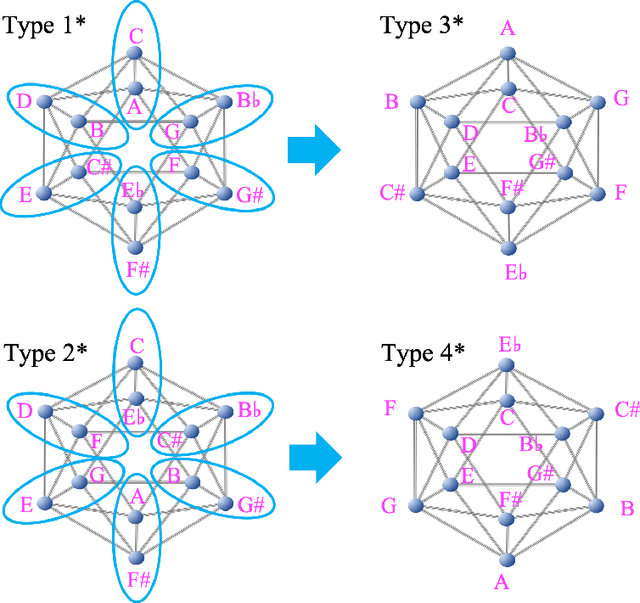
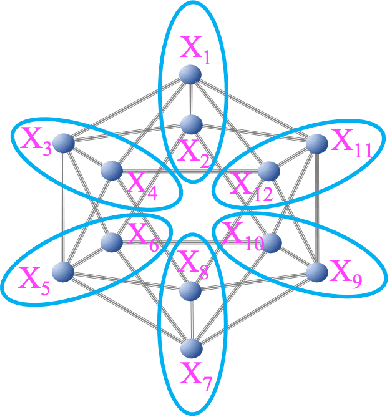
Raga is a central musical concept in South Asia, especially India, and we investigate connections between Western classical music and Melakarta raga that is a raga in Karnatak (south Indian) classical music, through musical icosahedron. In our previous study, we introduced some kinds of musical icosahedra connecting various musical concepts in Western music: chromatic/whole tone musical icosahedra, Pythagorean/whole tone musical icosahedra, and exceptional musical icosahedra. In this paper, first, we introduce kinds of musical icosahedra that connect the above musical icosahedra through two kinds of permutations of 12 tones: inter-permutations and intra-permutations, and we call them intermediate musical icosahedra. Next, we define a neighboring number as a number of pairs of neighboring two tones in a given scale that neighbor each other on a given musical icosahedron, and we also define a musical invariant as a linear combination of the neighboring numbers. We find there exists a pair of a musical invariant and scales that is constant for some musical icosahedra and analyze their mathematical structure. Last, we define an extension of a given scale by the inter-permutations of a given musical icosahedron: the permutation-extension. Then, we show that the permutation-extension of the C major scale by Melakarta raga musical icosahedra that are four of the intermediate musical icosahedra from the type 1 chromatic/whole tone musical icosahedron to the type 1' Pythagorean/whole tone musical icosahedron, is a set of all the scales included in Melakarta raga. There exists a musical invariant that is constant for all the musical icosahedra corresponding to the scales of Melakarta raga, and we obtained a diagram representation of those scales characterizing the musical invariant.
Content-based Music Similarity with Triplet Networks
Aug 11, 2020
We explore the feasibility of using triplet neural networks to embed songs based on content-based music similarity. Our network is trained using triplets of songs such that two songs by the same artist are embedded closer to one another than to a third song by a different artist. We compare two models that are trained using different ways of picking this third song: at random vs. based on shared genre labels. Our experiments are conducted using songs from the Free Music Archive and use standard audio features. The initial results show that shallow Siamese networks can be used to embed music for a simple artist retrieval task.