 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
ChoreoNet: Towards Music to Dance Synthesis with Choreographic Action Unit
Sep 16, 2020
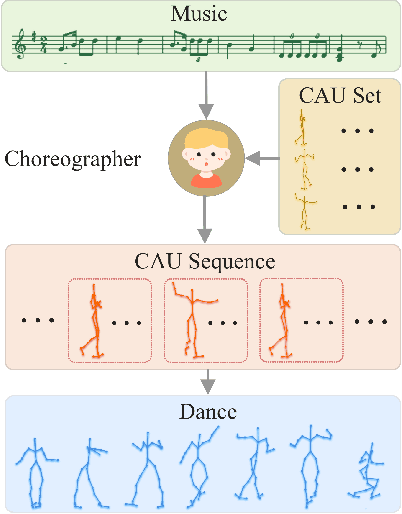

Dance and music are two highly correlated artistic forms. Synthesizing dance motions has attracted much attention recently. Most previous works conduct music-to-dance synthesis via directly music to human skeleton keypoints mapping. Meanwhile, human choreographers design dance motions from music in a two-stage manner: they firstly devise multiple choreographic dance units (CAUs), each with a series of dance motions, and then arrange the CAU sequence according to the rhythm, melody and emotion of the music. Inspired by these, we systematically study such two-stage choreography approach and construct a dataset to incorporate such choreography knowledge. Based on the constructed dataset, we design a two-stage music-to-dance synthesis framework ChoreoNet to imitate human choreography procedure. Our framework firstly devises a CAU prediction model to learn the mapping relationship between music and CAU sequences. Afterwards, we devise a spatial-temporal inpainting model to convert the CAU sequence into continuous dance motions. Experimental results demonstrate that the proposed ChoreoNet outperforms baseline methods (0.622 in terms of CAU BLEU score and 1.59 in terms of user study score).
Modeling Animal Vocalizations through Synthesizers
Oct 19, 2022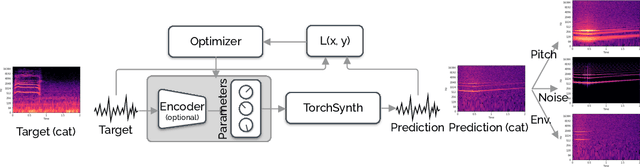
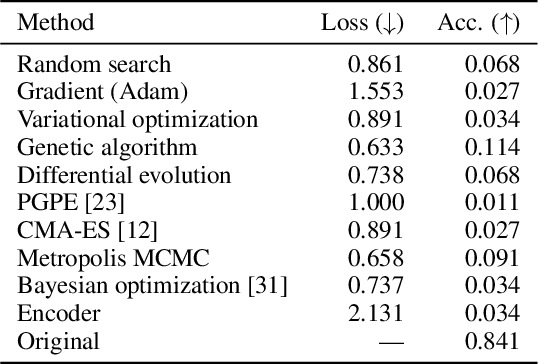
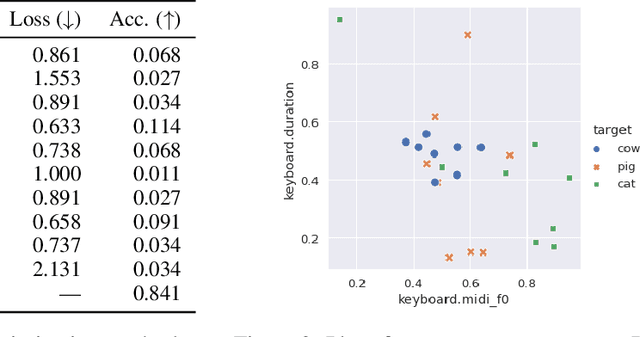
Modeling real-world sound is a fundamental problem in the creative use of machine learning and many other fields, including human speech processing and bioacoustics. Transformer-based generative models and some prior work (e.g., DDSP) are known to produce realistic sound, although they have limited control and are hard to interpret. As an alternative, we aim to use modular synthesizers, i.e., compositional, parametric electronic musical instruments, for modeling non-music sounds. However, inferring synthesizer parameters given a target sound, i.e., the parameter inference task, is not trivial for general sounds, and past research has typically focused on musical sound. In this work, we optimize a differentiable synthesizer from TorchSynth in order to model, emulate, and creatively generate animal vocalizations. We compare an array of optimization methods, from gradient-based search to genetic algorithms, for inferring its parameters, and then demonstrate how one can control and interpret the parameters for modeling non-music sounds.
Music2Dance: DanceNet for Music-driven Dance Generation
Mar 10, 2020
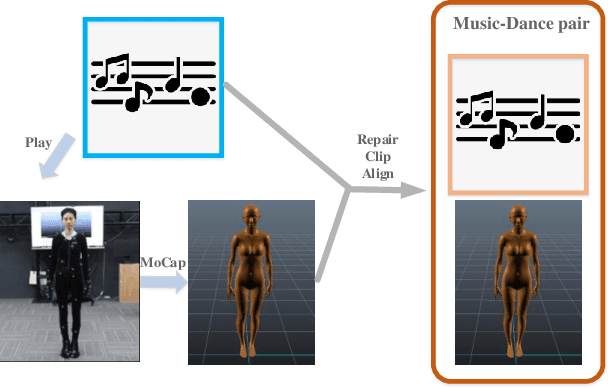

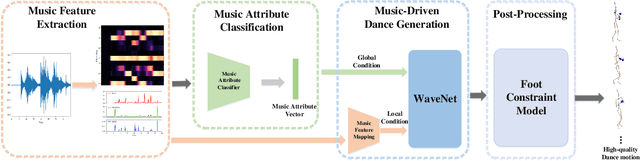
Synthesize human motions from music, i.e., music to dance, is appealing and attracts lots of research interests in recent years. It is challenging due to not only the requirement of realistic and complex human motions for dance, but more importantly, the synthesized motions should be consistent with the style, rhythm and melody of the music. In this paper, we propose a novel autoregressive generative model, DanceNet, to take the style, rhythm and melody of music as the control signals to generate 3D dance motions with high realism and diversity. To boost the performance of our proposed model, we capture several synchronized music-dance pairs by professional dancers, and build a high-quality music-dance pair dataset. Experiments have demonstrated that the proposed method can achieve the state-of-the-art results.
High Fidelity Speech Enhancement with Band-split RNN
Dec 01, 2022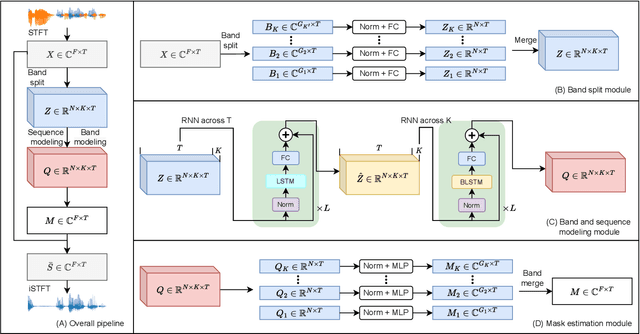
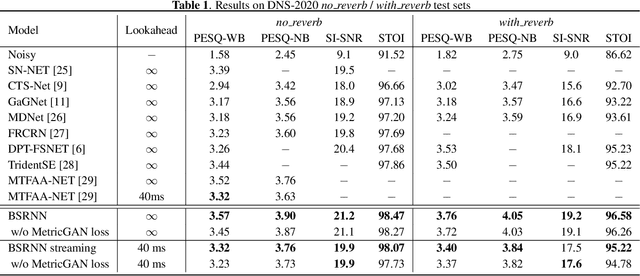
This report presents the development of our speech enhancement system, which includes the use of a recently proposed music separation model, the band-split recurrent neural network (BSRNN), and a MetricGAN-based training objective to improve non-differentiable quality metrics such as perceptual evaluation of speech quality (PESQ) score. Experiment conducted on Interspeech 2021 DNS challenge shows that our BSRNN system outperforms various top-ranking benchmark systems in previous deep noise suppression (DNS) challenges and achieves state-of-the-art (SOTA) result on the DNS-2020 non-blind test set in both offline and online scenarios.
Incorporating Music Knowledge in Continual Dataset Augmentation for Music Generation
Jul 17, 2020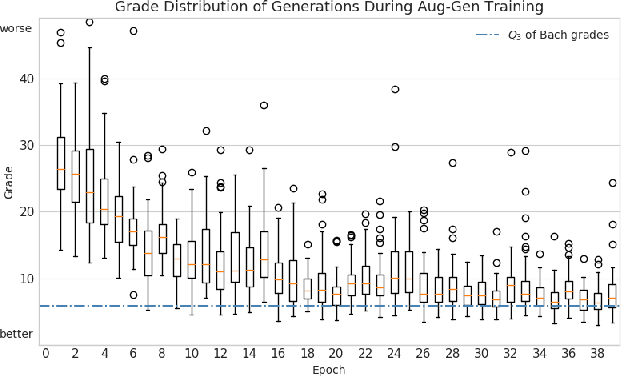
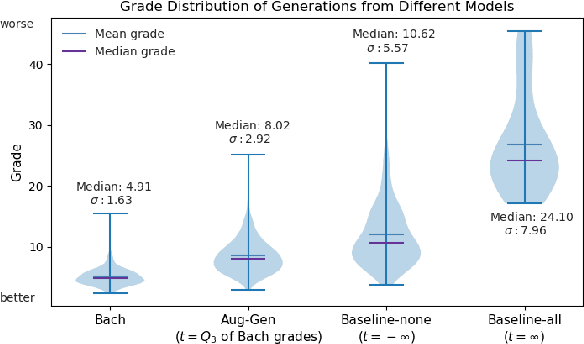
Deep learning has rapidly become the state-of-the-art approach for music generation. However, training a deep model typically requires a large training set, which is often not available for specific musical styles. In this paper, we present augmentative generation (Aug-Gen), a method of dataset augmentation for any music generation system trained on a resource-constrained domain. The key intuition of this method is that the training data for a generative system can be augmented by examples the system produces during the course of training, provided these examples are of sufficiently high quality and variety. We apply Aug-Gen to Transformer-based chorale generation in the style of J.S. Bach, and show that this allows for longer training and results in better generative output.
MAQA: A Multimodal QA Benchmark for Negation
Jan 09, 2023
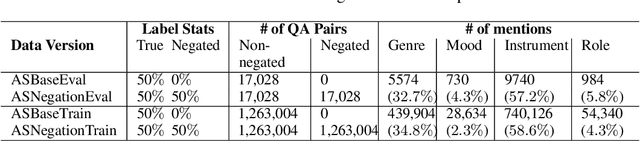
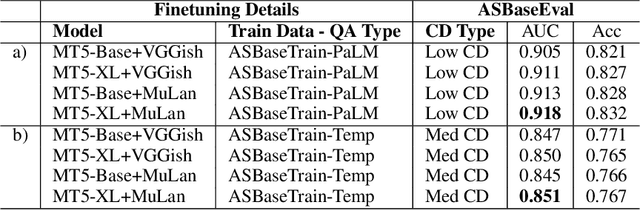

Multimodal learning can benefit from the representation power of pretrained Large Language Models (LLMs). However, state-of-the-art transformer based LLMs often ignore negations in natural language and there is no existing benchmark to quantitatively evaluate whether multimodal transformers inherit this weakness. In this study, we present a new multimodal question answering (QA) benchmark adapted from labeled music videos in AudioSet (Gemmeke et al., 2017) with the goal of systematically evaluating if multimodal transformers can perform complex reasoning to recognize new concepts as negation of previously learned concepts. We show that with standard fine-tuning approach multimodal transformers are still incapable of correctly interpreting negation irrespective of model size. However, our experiments demonstrate that augmenting the original training task distributions with negated QA examples allow the model to reliably reason with negation. To do this, we describe a novel data generation procedure that prompts the 540B-parameter PaLM model to automatically generate negated QA examples as compositions of easily accessible video tags. The generated examples contain more natural linguistic patterns and the gains compared to template-based task augmentation approach are significant.
Multiple Signal Classification Based Joint Communication and Sensing System
Nov 08, 2022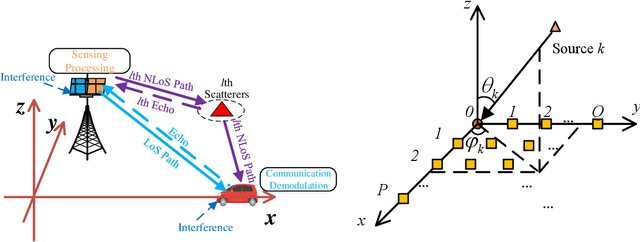
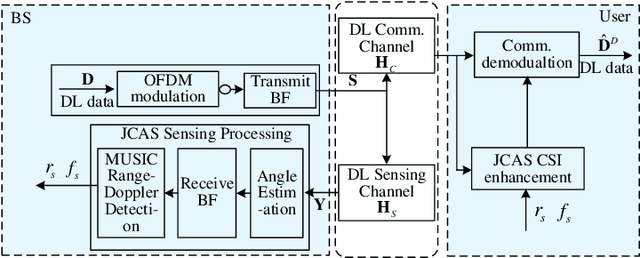
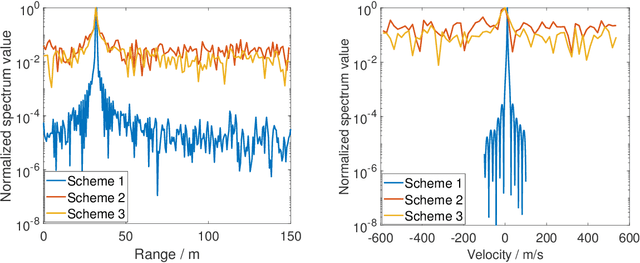
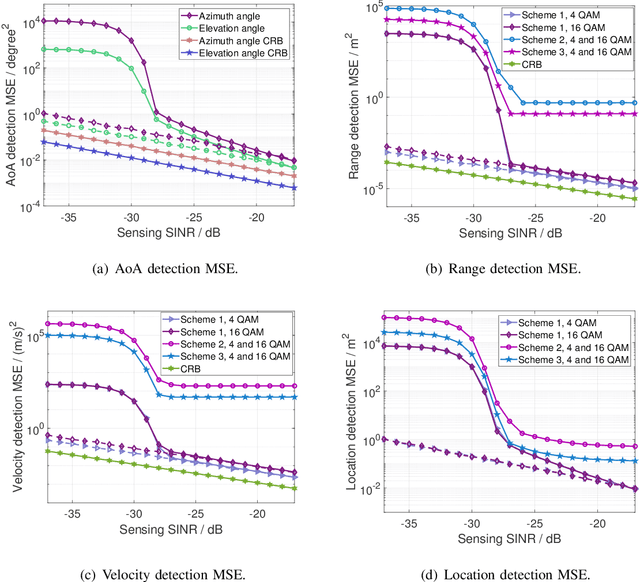
Joint communication and sensing (JCS) has become a promising technology for mobile networks because of its higher spectrum and energy efficiency. Up to now, the prevalent fast Fourier transform (FFT)-based sensing method for mobile JCS networks is on-grid based, and the grid interval determines the resolution. Because the mobile network usually has limited consecutive OFDM symbols in a downlink (DL) time slot, the sensing accuracy is restricted by the limited resolution, especially for velocity estimation. In this paper, we propose a multiple signal classification (MUSIC)-based JCS system that can achieve higher sensing accuracy for the angle of arrival, range, and velocity estimation, compared with the traditional FFT-based JCS method. We further propose a JCS channel state information (CSI) enhancement method by leveraging the JCS sensing results. Finally, we derive a theoretical lower bound for sensing mean square error (MSE) by using perturbation analysis. Simulation results show that in terms of the sensing MSE performance, the proposed MUSIC-based JCS outperforms the FFT-based one by more than 20 dB. Moreover, the bit error rate (BER) of communication demodulation using the proposed JCS CSI enhancement method is significantly reduced compared with communication using the originally estimated CSI.
A Hands-on Comparison of DNNs for Dialog Separation Using Transfer Learning from Music Source Separation
Jun 22, 2021
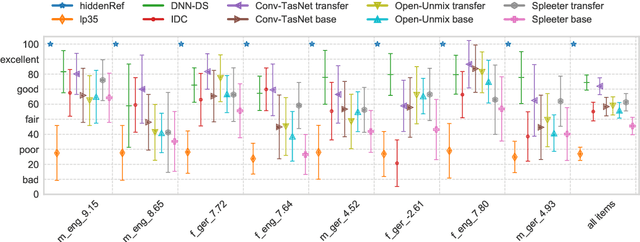
This paper describes a hands-on comparison on using state-of-the-art music source separation deep neural networks (DNNs) before and after task-specific fine-tuning for separating speech content from non-speech content in broadcast audio (i.e., dialog separation). The music separation models are selected as they share the number of channels (2) and sampling rate (44.1 kHz or higher) with the considered broadcast content, and vocals separation in music is considered as a parallel for dialog separation in the target application domain. These similarities are assumed to enable transfer learning between the tasks. Three models pre-trained on music (Open-Unmix, Spleeter, and Conv-TasNet) are considered in the experiments, and fine-tuned with real broadcast data. The performance of the models is evaluated before and after fine-tuning with computational evaluation metrics (SI-SIRi, SI-SDRi, 2f-model), as well as with a listening test simulating an application where the non-speech signal is partially attenuated, e.g., for better speech intelligibility. The evaluations include two reference systems specifically developed for dialog separation. The results indicate that pre-trained music source separation models can be used for dialog separation to some degree, and that they benefit from the fine-tuning, reaching a performance close to task-specific solutions.
Quantum Representations of Sound: from mechanical waves to quantum circuits
Jan 01, 2023
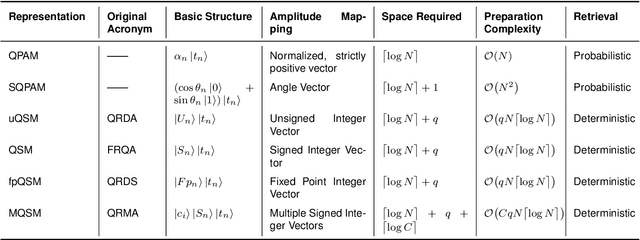
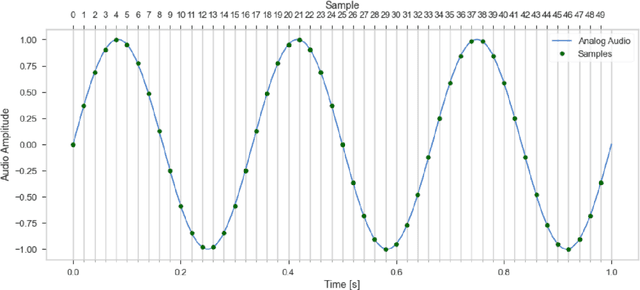
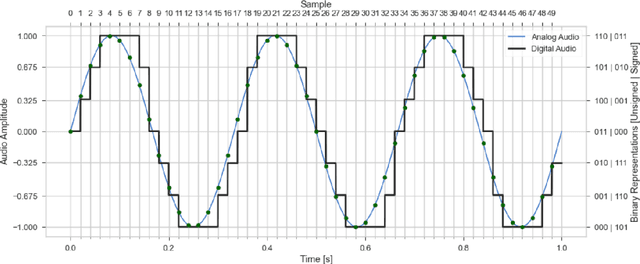
By the time of writing, quantum audio still is a very young area of study, even within the quantum signal processing community. This chapter introduces the state of the art in quantum audio and discusses methods for the quantum representation of audio signals. Currently, no quantum representation strategy claims to be the best one for audio applications. Each one presents advantages and disadvantages. It can be argued that future quantum audio representation schemes will make use of multiple strategies aimed at specific applications. NOTE: This is an unedited abridged version of the pre-submission draft of a chapter, with the same title, published in the book Quantum Computer Music: Foundations, Methods and Advanced Concepts, by E. R. Miranda (pp. 223 - 274). Please refer to the version in this book for application examples and a discussion on sound synthesis methods based on quantum audio representation and their potential for developing new types of musical instruments. https://link.springer.com/book/10.1007/978-3-031-13909-3
Scaling and compressing melodies using geometric similarity measures
Sep 19, 2022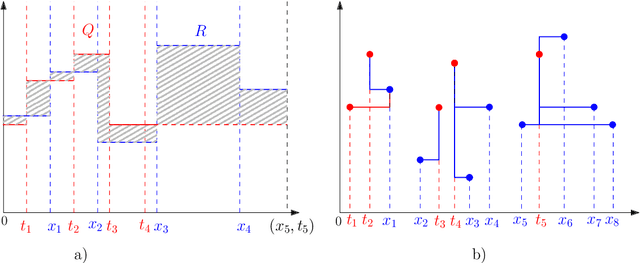
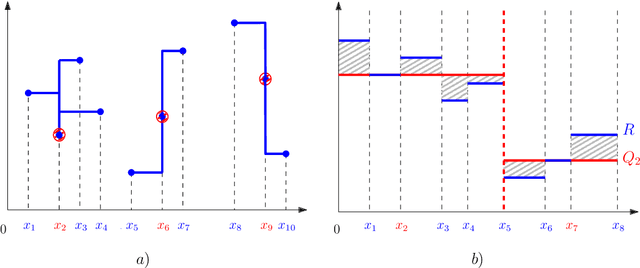

Melodic similarity measurement is of key importance in music information retrieval. In this paper, we use geometric matching techniques to measure the similarity between two melodies. We represent music as sets of points or sets of horizontal line segments in the Euclidean plane and propose efficient algorithms for optimization problems inspired in two operations on melodies; linear scaling and audio compression. In the scaling problem, an incoming query melody is scaled forward until the similarity measure between the query and a reference melody is minimized. The compression problem asks for a subset of notes of a given melody such that the matching cost between the selected notes and the reference melody is minimized.