 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Learning Unsupervised Hierarchies of Audio Concepts
Jul 21, 2022
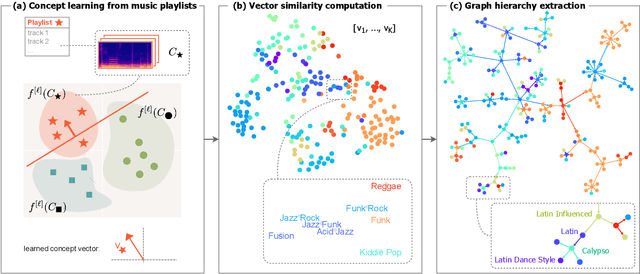
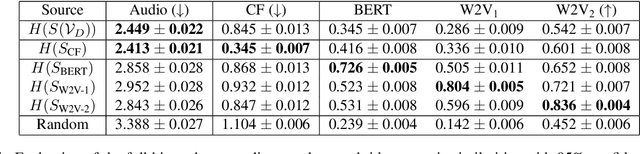
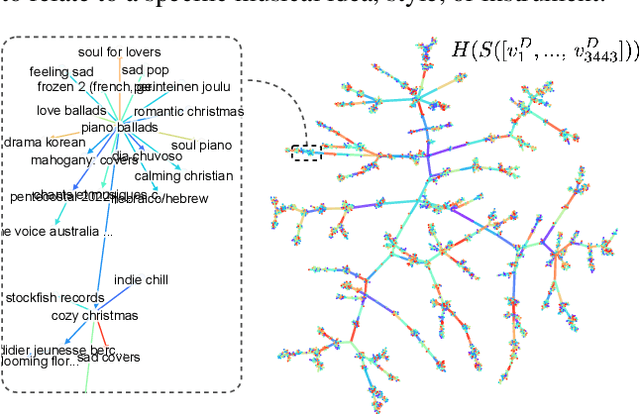
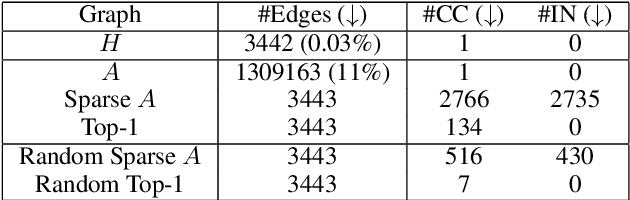
Music signals are difficult to interpret from their low-level features, perhaps even more than images: e.g. highlighting part of a spectrogram or an image is often insufficient to convey high-level ideas that are genuinely relevant to humans. In computer vision, concept learning was therein proposed to adjust explanations to the right abstraction level (e.g. detect clinical concepts from radiographs). These methods have yet to be used for MIR. In this paper, we adapt concept learning to the realm of music, with its particularities. For instance, music concepts are typically non-independent and of mixed nature (e.g. genre, instruments, mood), unlike previous work that assumed disentangled concepts. We propose a method to learn numerous music concepts from audio and then automatically hierarchise them to expose their mutual relationships. We conduct experiments on datasets of playlists from a music streaming service, serving as a few annotated examples for diverse concepts. Evaluations show that the mined hierarchies are aligned with both ground-truth hierarchies of concepts -- when available -- and with proxy sources of concept similarity in the general case.
Novel Recording Studio Features for Music Information Retrieval
Jan 25, 2021

In the recording studio, producers of Electronic Dance Music (EDM) spend more time creating, shaping, mixing and mastering sounds, than with compositional aspects or arrangement. They tune the sound by close listening and by leveraging audio metering and audio analysis tools, until they successfully creat the desired sound aesthetics. DJs of EDM tend to play sets of songs that meet their sound ideal. We therefore suggest using audio metering and monitoring tools from the recording studio to analyze EDM, instead of relying on conventional low-level audio features. We test our novel set of features by a simple classification task. We attribute songs to DJs who would play the specific song. This new set of features and the focus on DJ sets is targeted at EDM as it takes the producer and DJ culture into account. With simple dimensionality reduction and machine learning these features enable us to attribute a song to a DJ with an accuracy of 63%. The features from the audio metering and monitoring tools in the recording studio could serve for many applications in Music Information Retrieval, such as genre, style and era classification and music recommendation for both DJs and consumers of electronic dance music.
An Interpretable Music Similarity Measure Based on Path Interestingness
Aug 04, 2021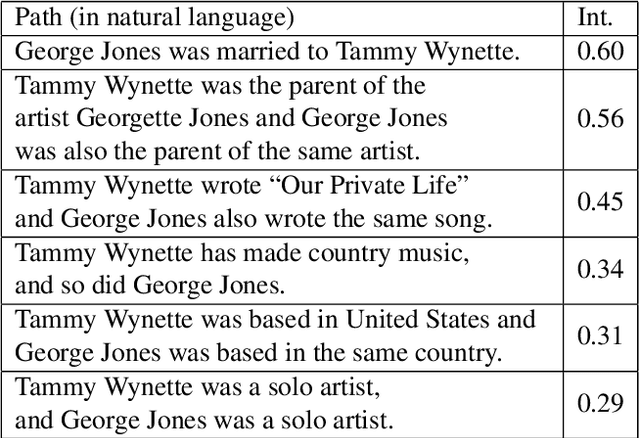

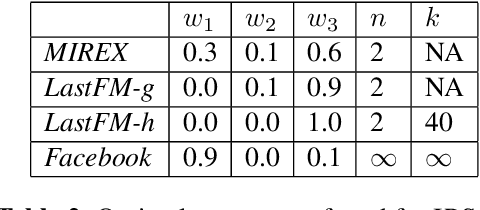
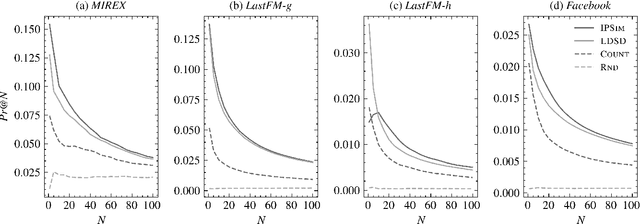
We introduce a novel and interpretable path-based music similarity measure. Our similarity measure assumes that items, such as songs and artists, and information about those items are represented in a knowledge graph. We find paths in the graph between a seed and a target item; we score those paths based on their interestingness; and we aggregate those scores to determine the similarity between the seed and the target. A distinguishing feature of our similarity measure is its interpretability. In particular, we can translate the most interesting paths into natural language, so that the causes of the similarity judgements can be readily understood by humans. We compare the accuracy of our similarity measure with other competitive path-based similarity baselines in two experimental settings and with four datasets. The results highlight the validity of our approach to music similarity, and demonstrate that path interestingness scores can be the basis of an accurate and interpretable similarity measure.
Multi-Channel Target Speaker Extraction with Refinement: The WavLab Submission to the Second Clarity Enhancement Challenge
Feb 15, 2023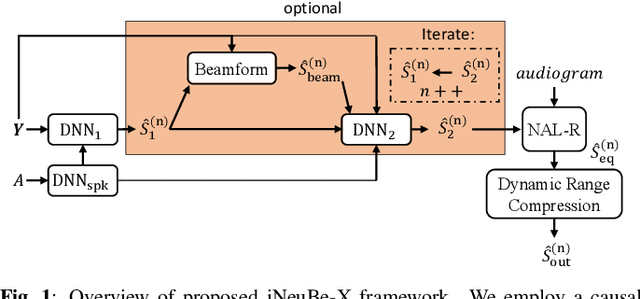
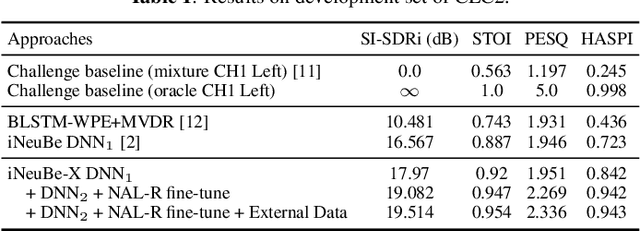
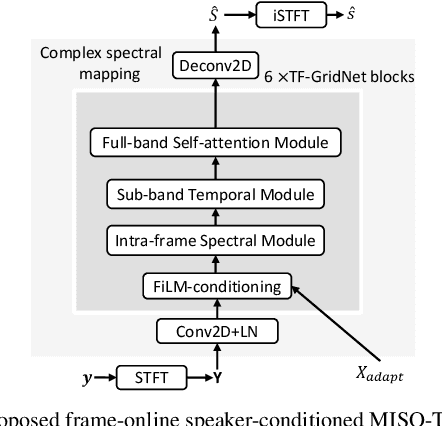
This paper describes our submission to the Second Clarity Enhancement Challenge (CEC2), which consists of target speech enhancement for hearing-aid (HA) devices in noisy-reverberant environments with multiple interferers such as music and competing speakers. Our approach builds upon the powerful iterative neural/beamforming enhancement (iNeuBe) framework introduced in our recent work, and this paper extends it for target speaker extraction. We therefore name the proposed approach as iNeuBe-X, where the X stands for extraction. To address the challenges encountered in the CEC2 setting, we introduce four major novelties: (1) we extend the state-of-the-art TF-GridNet model, originally designed for monaural speaker separation, for multi-channel, causal speech enhancement, and large improvements are observed by replacing the TCNDenseNet used in iNeuBe with this new architecture; (2) we leverage a recent dual window size approach with future-frame prediction to ensure that iNueBe-X satisfies the 5 ms constraint on algorithmic latency required by CEC2; (3) we introduce a novel speaker-conditioning branch for TF-GridNet to achieve target speaker extraction; (4) we propose a fine-tuning step, where we compute an additional loss with respect to the target speaker signal compensated with the listener audiogram. Without using external data, on the official development set our best model reaches a hearing-aid speech perception index (HASPI) score of 0.942 and a scale-invariant signal-to-distortion ratio improvement (SI-SDRi) of 18.8 dB. These results are promising given the fact that the CEC2 data is extremely challenging (e.g., on the development set the mixture SI-SDR is -12.3 dB). A demo of our submitted system is available at WAVLab CEC2 demo.
Towards Robust Unsupervised Disentanglement of Sequential Data -- A Case Study Using Music Audio
May 12, 2022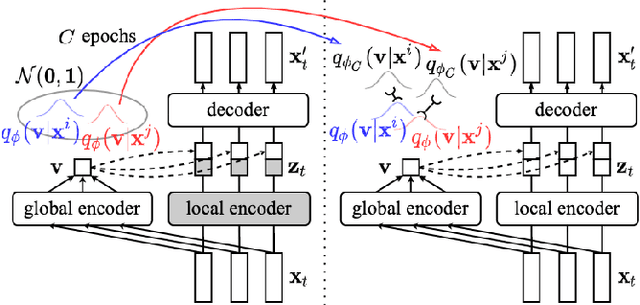



Disentangled sequential autoencoders (DSAEs) represent a class of probabilistic graphical models that describes an observed sequence with dynamic latent variables and a static latent variable. The former encode information at a frame rate identical to the observation, while the latter globally governs the entire sequence. This introduces an inductive bias and facilitates unsupervised disentanglement of the underlying local and global factors. In this paper, we show that the vanilla DSAE suffers from being sensitive to the choice of model architecture and capacity of the dynamic latent variables, and is prone to collapse the static latent variable. As a countermeasure, we propose TS-DSAE, a two-stage training framework that first learns sequence-level prior distributions, which are subsequently employed to regularise the model and facilitate auxiliary objectives to promote disentanglement. The proposed framework is fully unsupervised and robust against the global factor collapse problem across a wide range of model configurations. It also avoids typical solutions such as adversarial training which usually involves laborious parameter tuning, and domain-specific data augmentation. We conduct quantitative and qualitative evaluations to demonstrate its robustness in terms of disentanglement on both artificial and real-world music audio datasets.
CWS-PResUNet: Music Source Separation with Channel-wise Subband Phase-aware ResUNet
Dec 09, 2021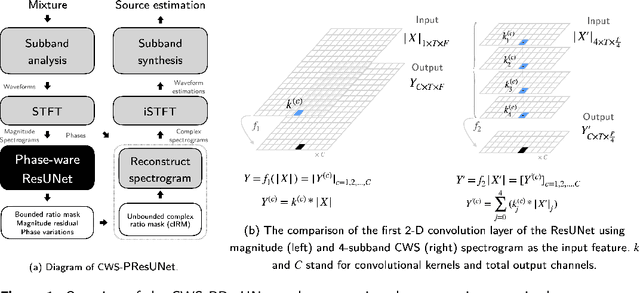
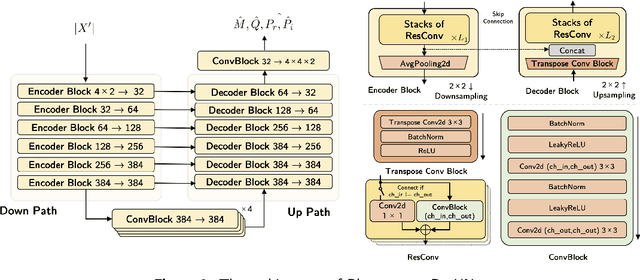
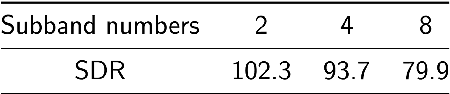
Music source separation (MSS) shows active progress with deep learning models in recent years. Many MSS models perform separations on spectrograms by estimating bounded ratio masks and reusing the phases of the mixture. When using convolutional neural networks (CNN), weights are usually shared within a spectrogram during convolution regardless of the different patterns between frequency bands. In this study, we propose a new MSS model, channel-wise subband phase-aware ResUNet (CWS-PResUNet), to decompose signals into subbands and estimate an unbound complex ideal ratio mask (cIRM) for each source. CWS-PResUNet utilizes a channel-wise subband (CWS) feature to limit unnecessary global weights sharing on the spectrogram and reduce computational resource consumptions. The saved computational cost and memory can in turn allow for a larger architecture. On the MUSDB18HQ test set, we propose a 276-layer CWS-PResUNet and achieve state-of-the-art (SoTA) performance on vocals with an 8.92 signal-to-distortion ratio (SDR) score. By combining CWS-PResUNet and Demucs, our ByteMSS system ranks the 2nd on vocals score and 5th on average score in the 2021 ISMIR Music Demixing (MDX) Challenge limited training data track (leaderboard A). Our code and pre-trained models are publicly available at: https://github.com/haoheliu/2021-ISMIR-MSS-Challenge-CWS-PResUNet
A Hands-on Comparison of DNNs for Dialog SeparationUsing Transfer Learning from Music Source Separation
Jun 16, 2021
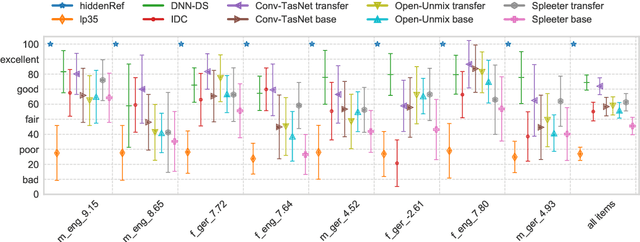
This paper describes a hands-on comparison on using state-of-the-art music source separation deep neural networks (DNNs) before and after task-specific fine-tuning for separating speech content from non-speech content in broadcast audio (i.e., dialog separation). The music separation models are selected as they share the number of channels (2) and sampling rate (44.1 kHz or higher) with the considered broadcast content, and vocals separation in music is considered as a parallel for dialog separation in the target application domain. These similarities are assumed to enable transfer learning between the tasks. Three models pre-trained on music (Open-Unmix, Spleeter, and Conv-TasNet) are considered in the experiments, and fine-tuned with real broadcast data. The performance of the models is evaluated before and after fine-tuning with computational evaluation metrics (SI-SIRi, SI-SDRi, 2f-model), as well as with a listening test simulating an application where the non-speech signal is partially attenuated, e.g., for better speech intelligibility. The evaluations include two reference systems specifically developed for dialog separation. The results indicate that pre-trained music source separation models can be used for dialog separation to some degree, and that they benefit from the fine-tuning, reaching a performance close to task-specific solutions.
Modeling Animal Vocalizations through Synthesizers
Oct 19, 2022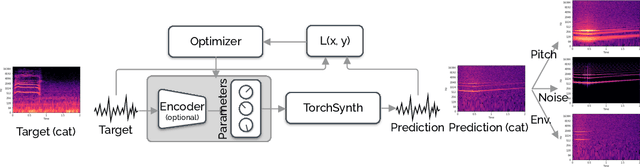
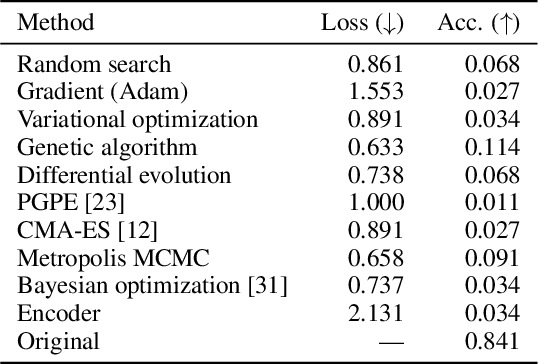
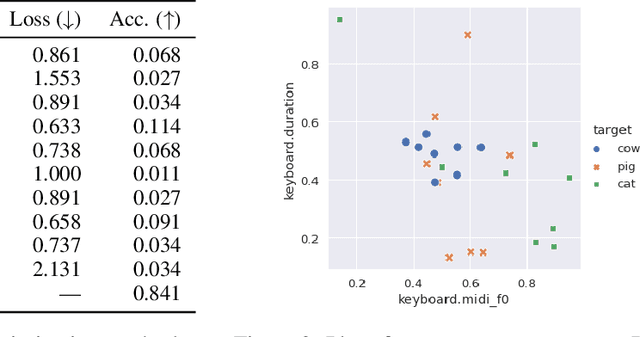
Modeling real-world sound is a fundamental problem in the creative use of machine learning and many other fields, including human speech processing and bioacoustics. Transformer-based generative models and some prior work (e.g., DDSP) are known to produce realistic sound, although they have limited control and are hard to interpret. As an alternative, we aim to use modular synthesizers, i.e., compositional, parametric electronic musical instruments, for modeling non-music sounds. However, inferring synthesizer parameters given a target sound, i.e., the parameter inference task, is not trivial for general sounds, and past research has typically focused on musical sound. In this work, we optimize a differentiable synthesizer from TorchSynth in order to model, emulate, and creatively generate animal vocalizations. We compare an array of optimization methods, from gradient-based search to genetic algorithms, for inferring its parameters, and then demonstrate how one can control and interpret the parameters for modeling non-music sounds.
ChoreoNet: Towards Music to Dance Synthesis with Choreographic Action Unit
Sep 16, 2020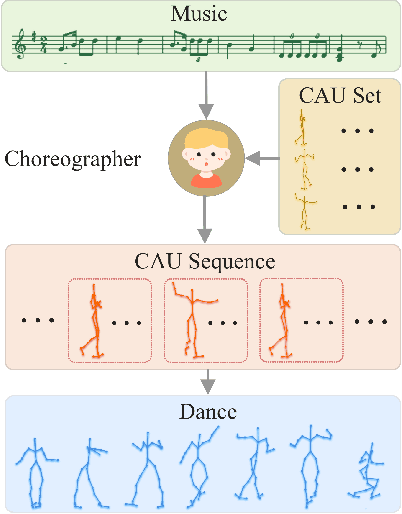

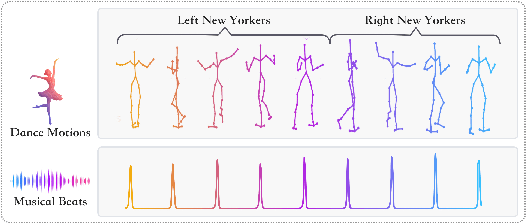
Dance and music are two highly correlated artistic forms. Synthesizing dance motions has attracted much attention recently. Most previous works conduct music-to-dance synthesis via directly music to human skeleton keypoints mapping. Meanwhile, human choreographers design dance motions from music in a two-stage manner: they firstly devise multiple choreographic dance units (CAUs), each with a series of dance motions, and then arrange the CAU sequence according to the rhythm, melody and emotion of the music. Inspired by these, we systematically study such two-stage choreography approach and construct a dataset to incorporate such choreography knowledge. Based on the constructed dataset, we design a two-stage music-to-dance synthesis framework ChoreoNet to imitate human choreography procedure. Our framework firstly devises a CAU prediction model to learn the mapping relationship between music and CAU sequences. Afterwards, we devise a spatial-temporal inpainting model to convert the CAU sequence into continuous dance motions. Experimental results demonstrate that the proposed ChoreoNet outperforms baseline methods (0.622 in terms of CAU BLEU score and 1.59 in terms of user study score).
High Fidelity Speech Enhancement with Band-split RNN
Dec 01, 2022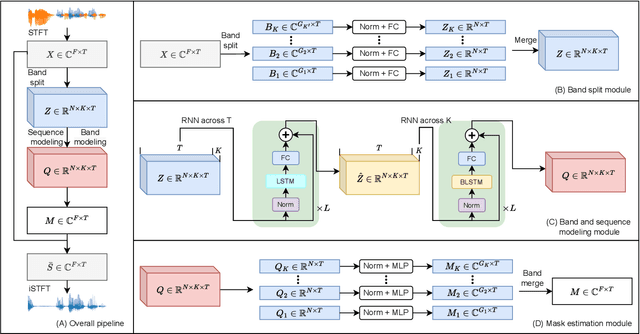
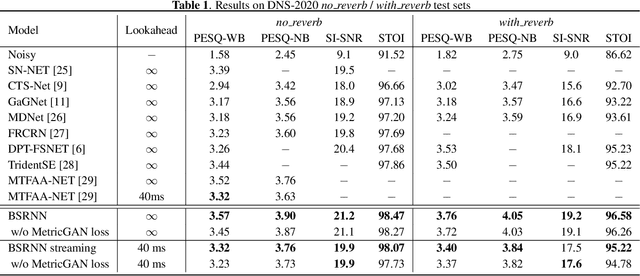
This report presents the development of our speech enhancement system, which includes the use of a recently proposed music separation model, the band-split recurrent neural network (BSRNN), and a MetricGAN-based training objective to improve non-differentiable quality metrics such as perceptual evaluation of speech quality (PESQ) score. Experiment conducted on Interspeech 2021 DNS challenge shows that our BSRNN system outperforms various top-ranking benchmark systems in previous deep noise suppression (DNS) challenges and achieves state-of-the-art (SOTA) result on the DNS-2020 non-blind test set in both offline and online scenarios.