 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Multi-Channel Target Speaker Extraction with Refinement: The WavLab Submission to the Second Clarity Enhancement Challenge
Feb 15, 2023
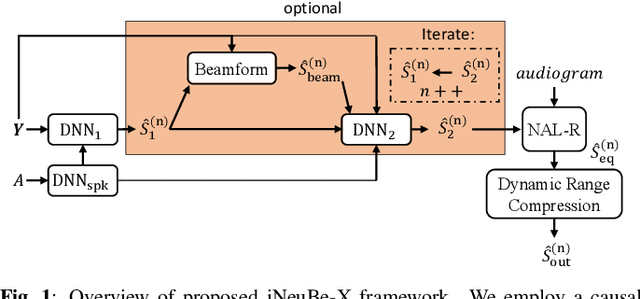
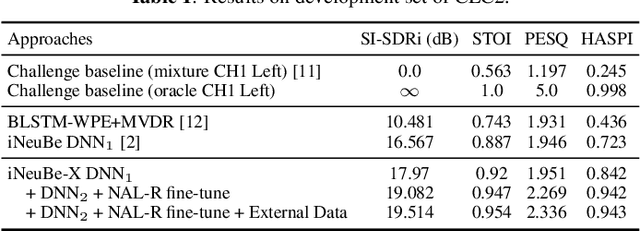
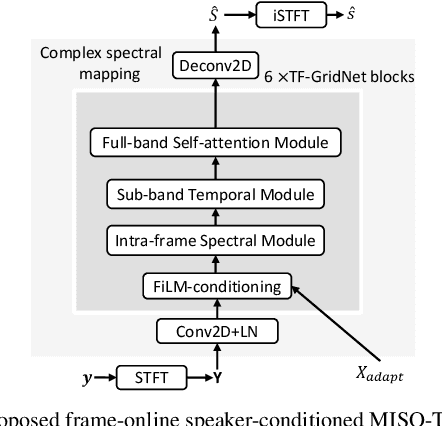
This paper describes our submission to the Second Clarity Enhancement Challenge (CEC2), which consists of target speech enhancement for hearing-aid (HA) devices in noisy-reverberant environments with multiple interferers such as music and competing speakers. Our approach builds upon the powerful iterative neural/beamforming enhancement (iNeuBe) framework introduced in our recent work, and this paper extends it for target speaker extraction. We therefore name the proposed approach as iNeuBe-X, where the X stands for extraction. To address the challenges encountered in the CEC2 setting, we introduce four major novelties: (1) we extend the state-of-the-art TF-GridNet model, originally designed for monaural speaker separation, for multi-channel, causal speech enhancement, and large improvements are observed by replacing the TCNDenseNet used in iNeuBe with this new architecture; (2) we leverage a recent dual window size approach with future-frame prediction to ensure that iNueBe-X satisfies the 5 ms constraint on algorithmic latency required by CEC2; (3) we introduce a novel speaker-conditioning branch for TF-GridNet to achieve target speaker extraction; (4) we propose a fine-tuning step, where we compute an additional loss with respect to the target speaker signal compensated with the listener audiogram. Without using external data, on the official development set our best model reaches a hearing-aid speech perception index (HASPI) score of 0.942 and a scale-invariant signal-to-distortion ratio improvement (SI-SDRi) of 18.8 dB. These results are promising given the fact that the CEC2 data is extremely challenging (e.g., on the development set the mixture SI-SDR is -12.3 dB). A demo of our submitted system is available at WAVLab CEC2 demo.
Singing Beat Tracking With Self-supervised Front-end and Linear Transformers
Aug 31, 2022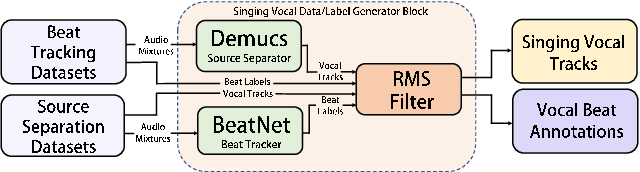

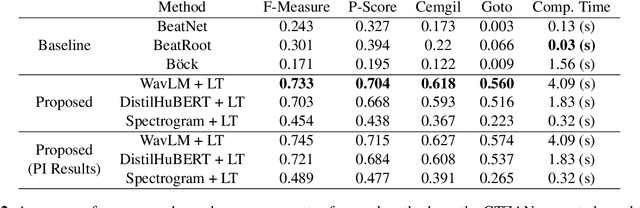
Tracking beats of singing voices without the presence of musical accompaniment can find many applications in music production, automatic song arrangement, and social media interaction. Its main challenge is the lack of strong rhythmic and harmonic patterns that are important for music rhythmic analysis in general. Even for human listeners, this can be a challenging task. As a result, existing music beat tracking systems fail to deliver satisfactory performance on singing voices. In this paper, we propose singing beat tracking as a novel task, and propose the first approach to solving this task. Our approach leverages semantic information of singing voices by employing pre-trained self-supervised WavLM and DistilHuBERT speech representations as the front-end and uses a self-attention encoder layer to predict beats. To train and test the system, we obtain separated singing voices and their beat annotations using source separation and beat tracking on complete songs, followed by manual corrections. Experiments on the 741 separated vocal tracks of the GTZAN dataset show that the proposed system outperforms several state-of-the-art music beat tracking methods by a large margin in terms of beat tracking accuracy. Ablation studies also confirm the advantages of pre-trained self-supervised speech representations over generic spectral features.
TunesFormer: Forming Tunes with Control Codes
Jan 07, 2023

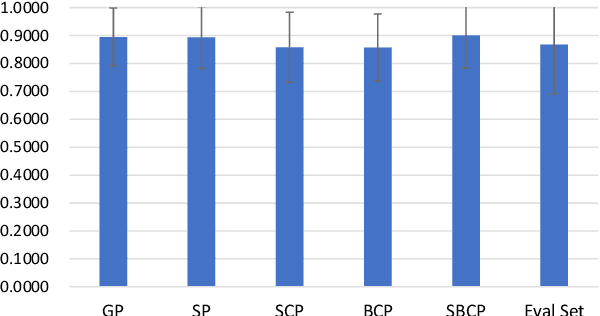
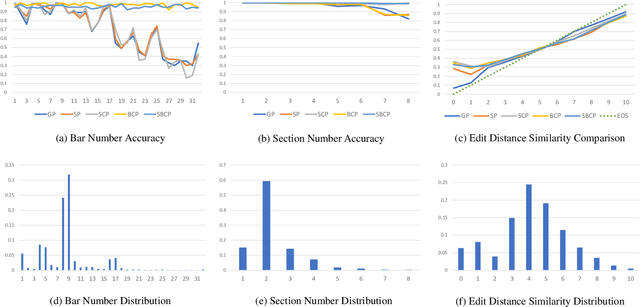
In recent years, deep learning techniques have been applied to music generation systems with promising results. However, one of the main challenges in this field has been the lack of annotated datasets, making it difficult for models to learn musical forms in compositions. To address this issue, we present TunesFormer, a Transformer-based melody generation system that is trained on a large dataset of 285,449 ABC tunes. By utilizing specific symbols commonly found in ABC notation to indicate section boundaries, TunesFormer can understand and generate melodies with given musical forms based on control codes. Our objective evaluations demonstrate the effectiveness of the control codes in achieving controlled musical forms, and subjective experiments show that the generated melodies are of comparable quality to human compositions. Our results also provide insights into the optimal placement of control codes and their impact on the generated melodies. TunesFormer presents a promising approach for generating melodies with desired musical forms through the use of deep learning techniques.
An empirical study of weakly supervised audio tagging embeddings for general audio representations
Sep 30, 2022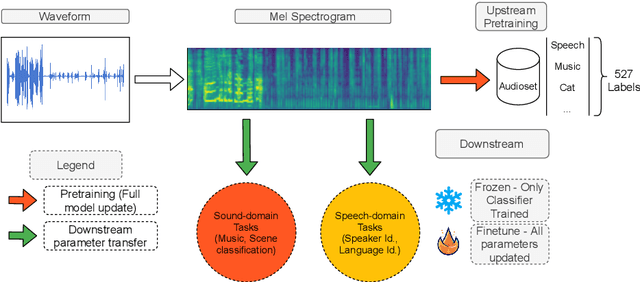
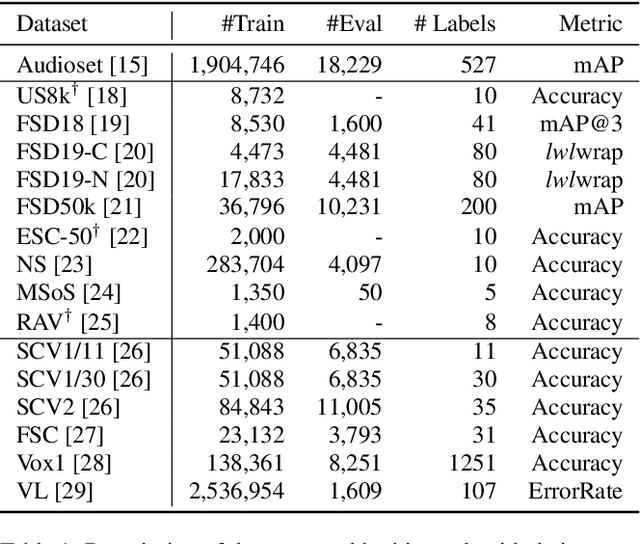
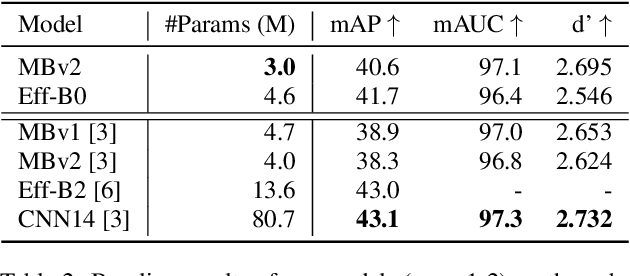
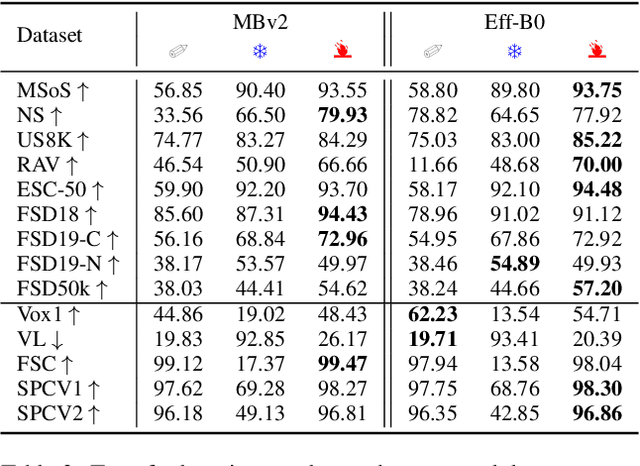
We study the usability of pre-trained weakly supervised audio tagging (AT) models as feature extractors for general audio representations. We mainly analyze the feasibility of transferring those embeddings to other tasks within the speech and sound domains. Specifically, we benchmark weakly supervised pre-trained models (MobileNetV2 and EfficientNet-B0) against modern self-supervised learning methods (BYOL-A) as feature extractors. Fourteen downstream tasks are used for evaluation ranging from music instrument classification to language classification. Our results indicate that AT pre-trained models are an excellent transfer learning choice for music, event, and emotion recognition tasks. Further, finetuning AT models can also benefit speech-related tasks such as keyword spotting and intent classification.
PIANOTREE VAE: Structured Representation Learning for Polyphonic Music
Aug 17, 2020
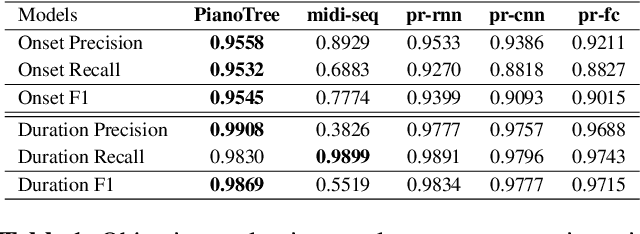
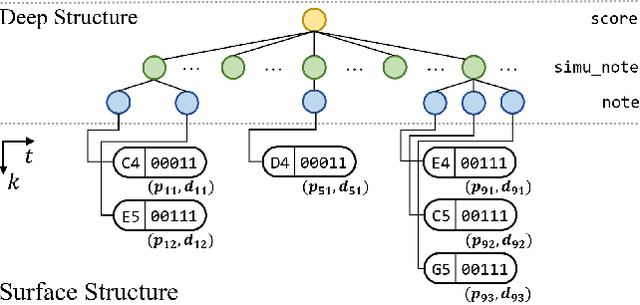
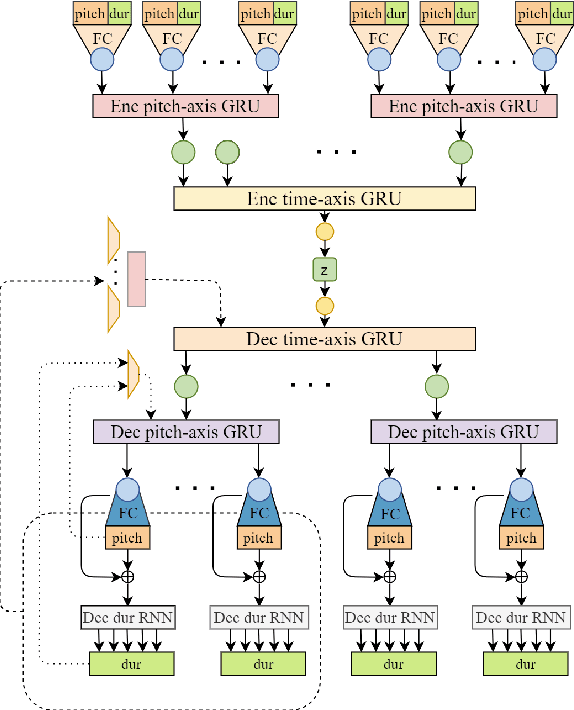
The dominant approach for music representation learning involves the deep unsupervised model family variational autoencoder (VAE). However, most, if not all, viable attempts on this problem have largely been limited to monophonic music. Normally composed of richer modality and more complex musical structures, the polyphonic counterpart has yet to be addressed in the context of music representation learning. In this work, we propose the PianoTree VAE, a novel tree-structure extension upon VAE aiming to fit the polyphonic music learning. The experiments prove the validity of the PianoTree VAE via (i)-semantically meaningful latent code for polyphonic segments; (ii)-more satisfiable reconstruction aside of decent geometry learned in the latent space; (iii)-this model's benefits to the variety of the downstream music generation.
Improving Community Detection Performance in Heterogeneous Music Network by Learning Edge-type Usefulness Distribution
May 03, 2021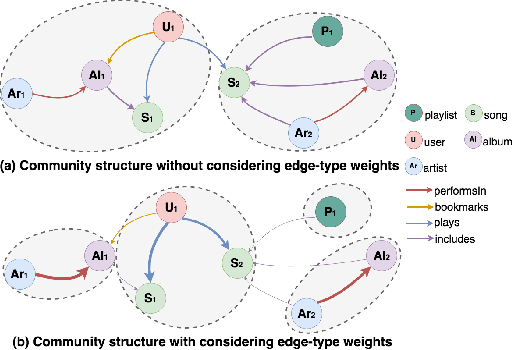
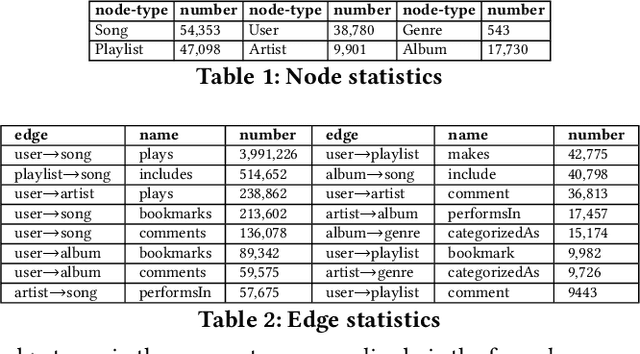
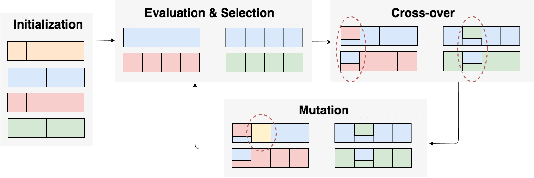
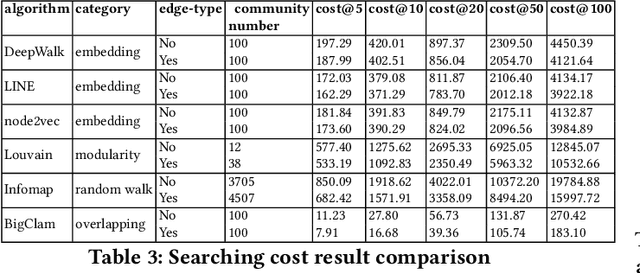
Music is becoming an essential part of daily life. There is an urgent need to develop recommendation systems to assist people targeting better songs with fewer efforts. As the interactions between users and songs naturally construct a complex network, community detection approaches can be applied to reveal users' potential interests on songs by grouping relevant users \& songs to the same community. However, as the types of interaction are diverse, it challenges conventional community detection methods which are designed originally for homogeneous networks. Although there are existing works focusing on heterogeneous community detection, they are mostly task-driven approaches and not feasible for music retrieval and recommendation directly. In this paper, we propose a genetic based approach to learn an edge-type usefulness distribution (ETUD) for all edge-types in heterogeneous music networks. ETUD can be regarded as a linear function to project all edges to the same latent space and make them comparable. Therefore a heterogeneous network can be converted to a homogeneous one where those conventional methods are eligible to use. We validate the proposed model on a heterogeneous music network constructed from an online music streaming service. Results show that for conventional methods, ETUD can help to detect communities significantly improving music recommendation accuracy while reducing user searching cost simultaneously.
Neural Network architectures to classify emotions in Indian Classical Music
Feb 01, 2021
Music is often considered as the language of emotions. It has long been known to elicit emotions in human being and thus categorizing music based on the type of emotions they induce in human being is a very intriguing topic of research. When the task comes to classify emotions elicited by Indian Classical Music (ICM), it becomes much more challenging because of the inherent ambiguity associated with ICM. The fact that a single musical performance can evoke a variety of emotional response in the audience is implicit to the nature of ICM renditions. With the rapid advancements in the field of Deep Learning, this Music Emotion Recognition (MER) task is becoming more and more relevant and robust, hence can be applied to one of the most challenging test case i.e. classifying emotions elicited from ICM. In this paper we present a new dataset called JUMusEmoDB which presently has 400 audio clips (30 seconds each) where 200 clips correspond to happy emotions and the remaining 200 clips correspond to sad emotion. For supervised classification purposes, we have used 4 existing deep Convolutional Neural Network (CNN) based architectures (resnet18, mobilenet v2.0, squeezenet v1.0 and vgg16) on corresponding music spectrograms of the 2000 sub-clips (where every clip was segmented into 5 sub-clips of about 5 seconds each) which contain both time as well as frequency domain information. The initial results are quite inspiring, and we look forward to setting the baseline values for the dataset using this architecture. This type of CNN based classification algorithm using a rich corpus of Indian Classical Music is unique even in the global perspective and can be replicated in other modalities of music also. This dataset is still under development and we plan to include more data containing other emotional features as well. We plan to make the dataset publicly available soon.
Learning Unsupervised Hierarchies of Audio Concepts
Jul 21, 2022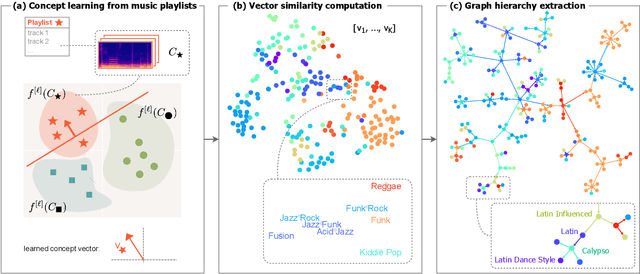
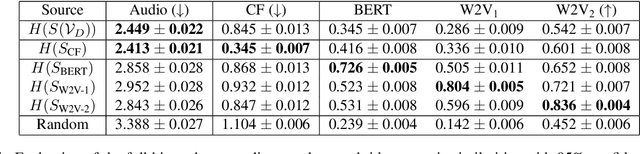
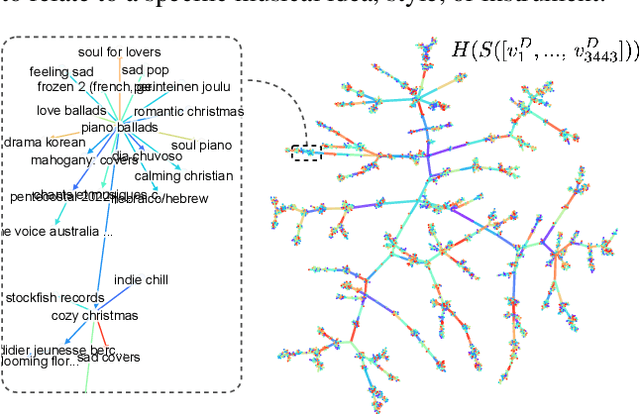
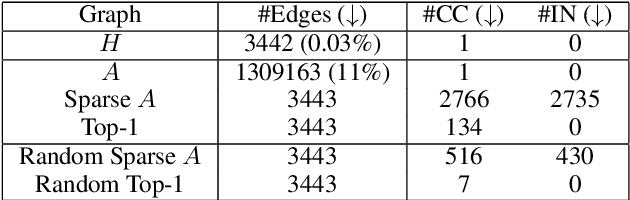
Music signals are difficult to interpret from their low-level features, perhaps even more than images: e.g. highlighting part of a spectrogram or an image is often insufficient to convey high-level ideas that are genuinely relevant to humans. In computer vision, concept learning was therein proposed to adjust explanations to the right abstraction level (e.g. detect clinical concepts from radiographs). These methods have yet to be used for MIR. In this paper, we adapt concept learning to the realm of music, with its particularities. For instance, music concepts are typically non-independent and of mixed nature (e.g. genre, instruments, mood), unlike previous work that assumed disentangled concepts. We propose a method to learn numerous music concepts from audio and then automatically hierarchise them to expose their mutual relationships. We conduct experiments on datasets of playlists from a music streaming service, serving as a few annotated examples for diverse concepts. Evaluations show that the mined hierarchies are aligned with both ground-truth hierarchies of concepts -- when available -- and with proxy sources of concept similarity in the general case.
Dual-track Music Generation using Deep Learning
May 09, 2020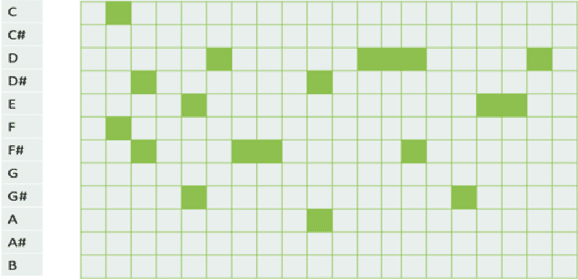
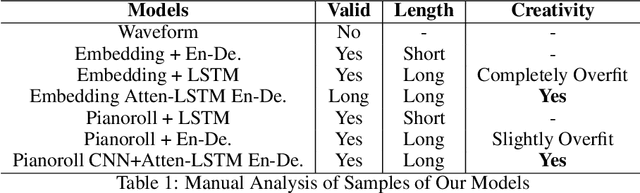


Music generation is always interesting in a sense that there is no formalized recipe. In this work, we propose a novel dual-track architecture for generating classical piano music, which is able to model the inter-dependency of left-hand and right-hand piano music. Particularly, we experimented with a lot of different models of neural network as well as different representations of music, and the results show that our proposed model outperforms all other tested methods. Besides, we deployed some special policies for model training and generation, which contributed to the model performance remarkably. Finally, under two evaluation methods, we compared our models with the MuseGAN project and true music.
Violent music vs violence and music: Drill rap and violent crime in London
Apr 09, 2020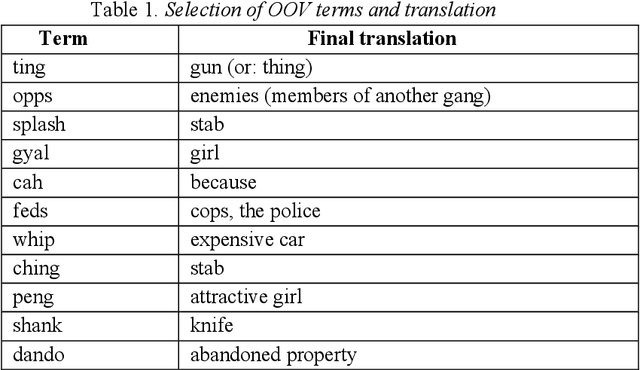
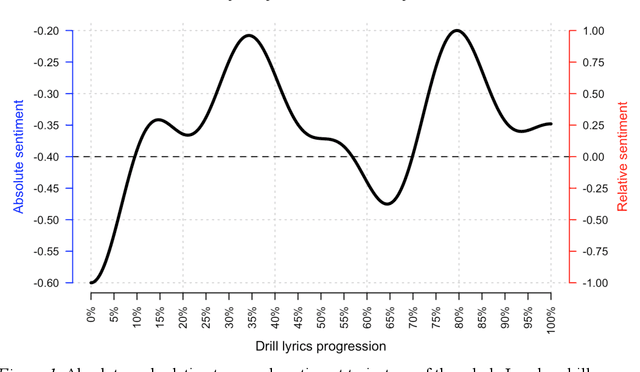
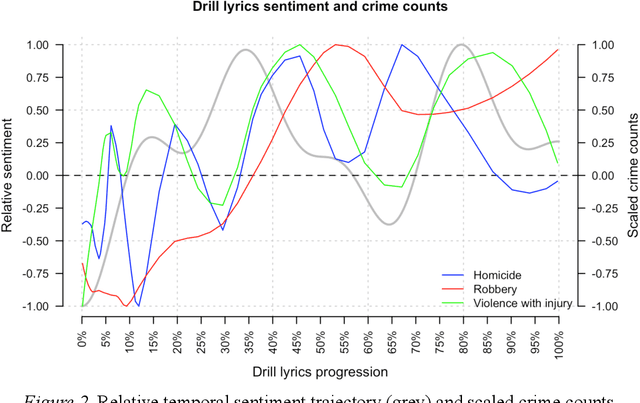
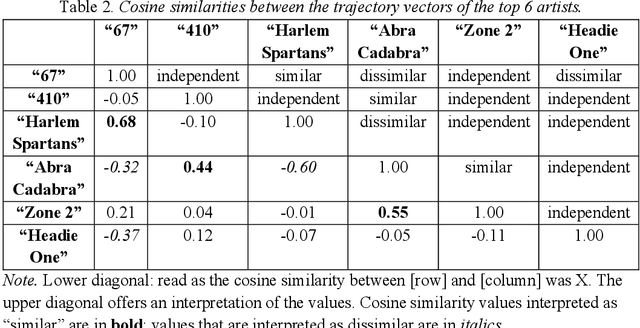
The current policy of removing drill music videos from social media platforms such as YouTube remains controversial because it risks conflating the co-occurrence of drill rap and violence with a causal chain of the two. Empirically, we revisit the question of whether there is evidence to support the conjecture that drill music and gang violence are linked. We provide new empirical insights suggesting that: i) drill music lyrics have not become more negative over time if anything they have become more positive; ii) individual drill artists have similar sentiment trajectories to other artists in the drill genre, and iii) there is no meaningful relationship between drill music and real-life violence when compared to three kinds of police-recorded violent crime data in London. We suggest ideas for new work that can help build a much-needed evidence base around the problem.