 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Camera-Based Piano Sheet Music Identification
Jul 29, 2020
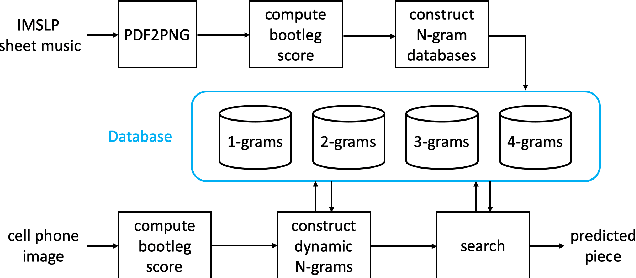
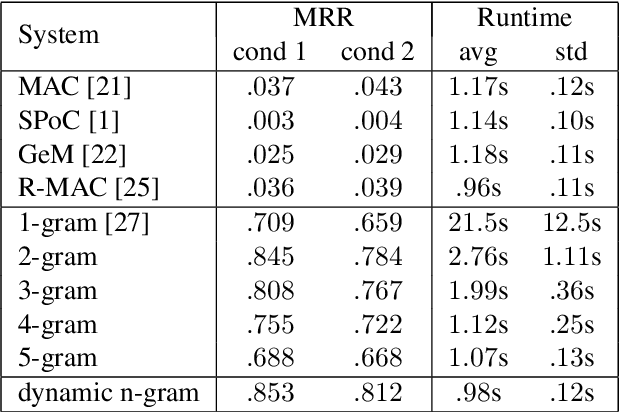

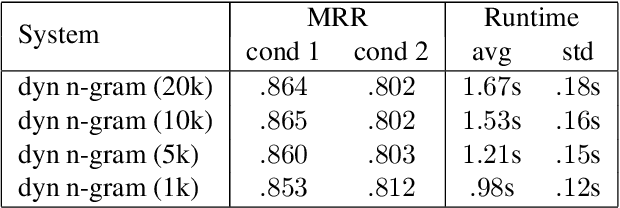
This paper presents a method for large-scale retrieval of piano sheet music images. Our work differs from previous studies on sheet music retrieval in two ways. First, we investigate the problem at a much larger scale than previous studies, using all solo piano sheet music images in the entire IMSLP dataset as a searchable database. Second, we use cell phone images of sheet music as our input queries, which lends itself to a practical, user-facing application. We show that a previously proposed fingerprinting method for sheet music retrieval is far too slow for a real-time application, and we diagnose its shortcomings. We propose a novel hashing scheme called dynamic n-gram fingerprinting that significantly reduces runtime while simultaneously boosting retrieval accuracy. In experiments on IMSLP data, our proposed method achieves a mean reciprocal rank of 0.85 and an average runtime of 0.98 seconds per query.
Audio-to-Score Alignment Using Deep Automatic Music Transcription
Jul 27, 2021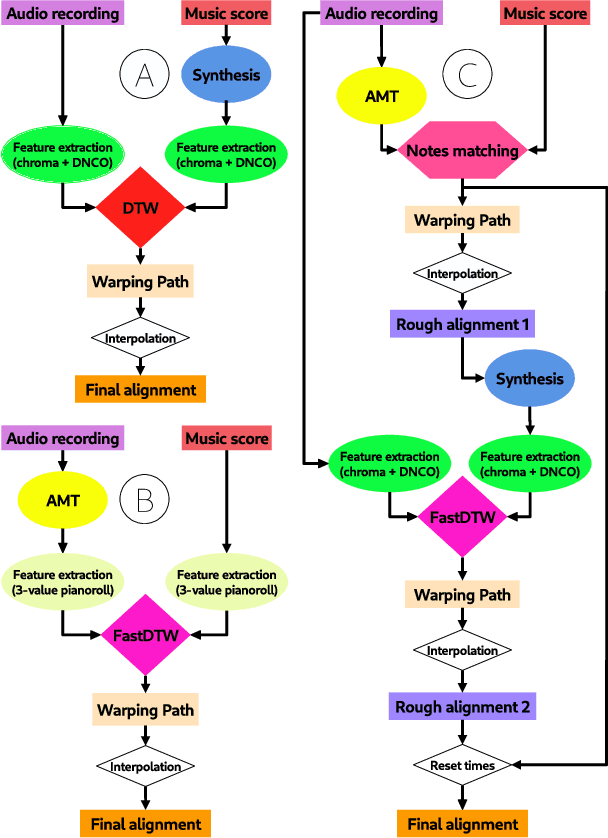
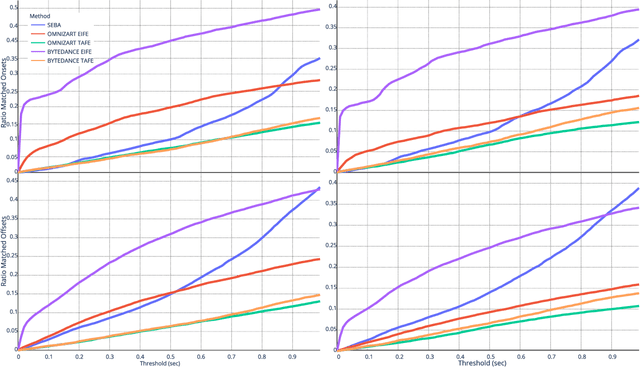
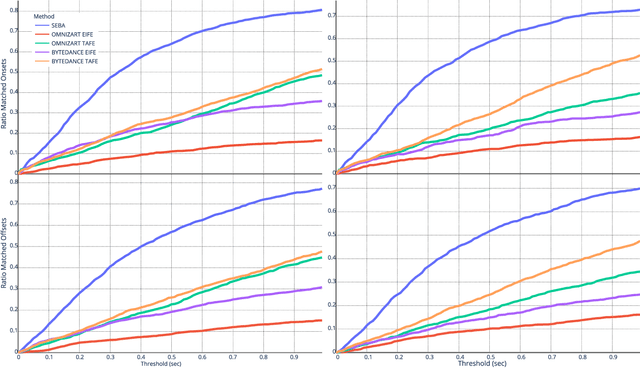
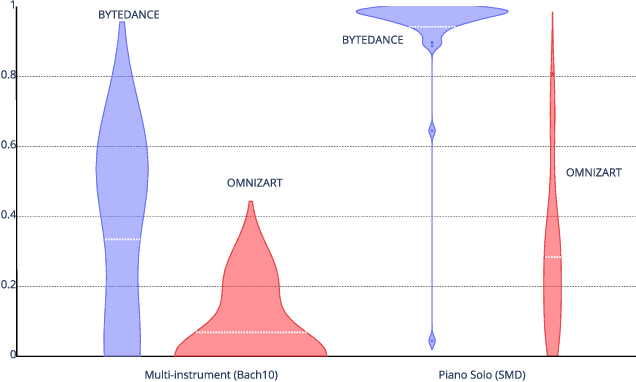
Audio-to-score alignment (A2SA) is a multimodal task consisting in the alignment of audio signals to music scores. Recent literature confirms the benefits of Automatic Music Transcription (AMT) for A2SA at the frame-level. In this work, we aim to elaborate on the exploitation of AMT Deep Learning (DL) models for achieving alignment at the note-level. We propose a method which benefits from HMM-based score-to-score alignment and AMT, showing a remarkable advancement beyond the state-of-the-art. We design a systematic procedure to take advantage of large datasets which do not offer an aligned score. Finally, we perform a thorough comparison and extensive tests on multiple datasets.
Multi-Instrumentalist Net: Unsupervised Generation of Music from Body Movements
Dec 07, 2020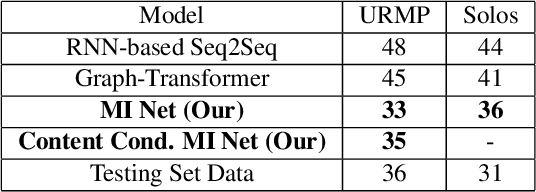
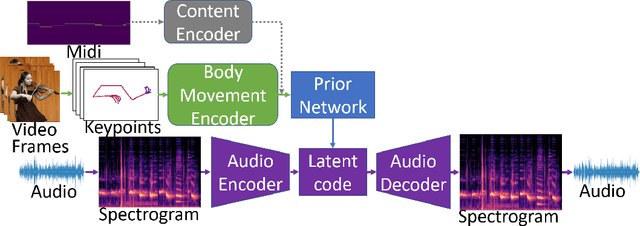
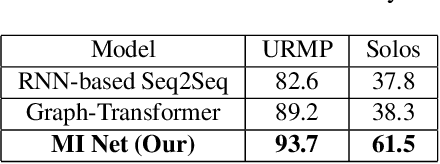

We propose a novel system that takes as an input body movements of a musician playing a musical instrument and generates music in an unsupervised setting. Learning to generate multi-instrumental music from videos without labeling the instruments is a challenging problem. To achieve the transformation, we built a pipeline named 'Multi-instrumentalistNet' (MI Net). At its base, the pipeline learns a discrete latent representation of various instruments music from log-spectrogram using a Vector Quantized Variational Autoencoder (VQ-VAE) with multi-band residual blocks. The pipeline is then trained along with an autoregressive prior conditioned on the musician's body keypoints movements encoded by a recurrent neural network. Joint training of the prior with the body movements encoder succeeds in the disentanglement of the music into latent features indicating the musical components and the instrumental features. The latent space results in distributions that are clustered into distinct instruments from which new music can be generated. Furthermore, the VQ-VAE architecture supports detailed music generation with additional conditioning. We show that a Midi can further condition the latent space such that the pipeline will generate the exact content of the music being played by the instrument in the video. We evaluate MI Net on two datasets containing videos of 13 instruments and obtain generated music of reasonable audio quality, easily associated with the corresponding instrument, and consistent with the music audio content.
PopMAG: Pop Music Accompaniment Generation
Aug 18, 2020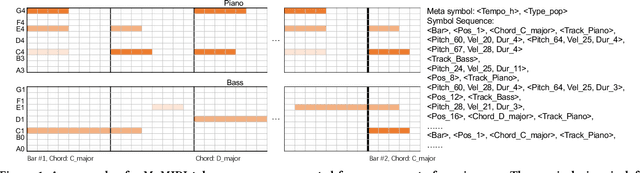

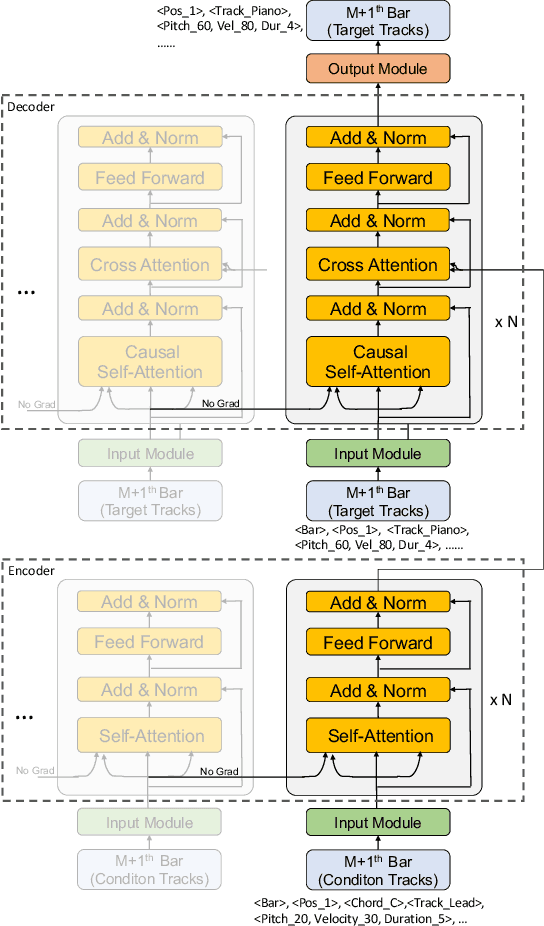
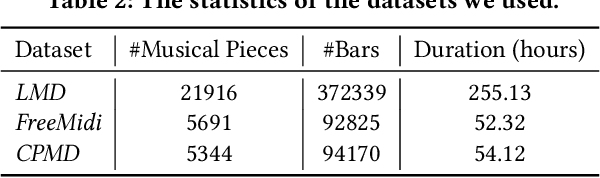
In pop music, accompaniments are usually played by multiple instruments (tracks) such as drum, bass, string and guitar, and can make a song more expressive and contagious by arranging together with its melody. Previous works usually generate multiple tracks separately and the music notes from different tracks not explicitly depend on each other, which hurts the harmony modeling. To improve harmony, in this paper, we propose a novel MUlti-track MIDI representation (MuMIDI), which enables simultaneous multi-track generation in a single sequence and explicitly models the dependency of the notes from different tracks. While this greatly improves harmony, unfortunately, it enlarges the sequence length and brings the new challenge of long-term music modeling. We further introduce two new techniques to address this challenge: 1) We model multiple note attributes (e.g., pitch, duration, velocity) of a musical note in one step instead of multiple steps, which can shorten the length of a MuMIDI sequence. 2) We introduce extra long-context as memory to capture long-term dependency in music. We call our system for pop music accompaniment generation as PopMAG. We evaluate PopMAG on multiple datasets (LMD, FreeMidi and CPMD, a private dataset of Chinese pop songs) with both subjective and objective metrics. The results demonstrate the effectiveness of PopMAG for multi-track harmony modeling and long-term context modeling. Specifically, PopMAG wins 42\%/38\%/40\% votes when comparing with ground truth musical pieces on LMD, FreeMidi and CPMD datasets respectively and largely outperforms other state-of-the-art music accompaniment generation models and multi-track MIDI representations in terms of subjective and objective metrics.
Neural Font Rendering
Nov 29, 2022
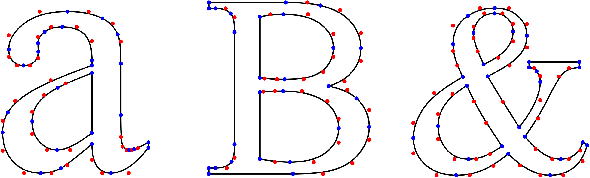

Recent advances in deep learning techniques and applications have revolutionized artistic creation and manipulation in many domains (text, images, music); however, fonts have not yet been integrated with deep learning architectures in a manner that supports their multi-scale nature. In this work we aim to bridge this gap, proposing a network architecture capable of rasterizing glyphs in multiple sizes, potentially paving the way for easy and accessible creation and manipulation of fonts.
Nonnegative Tucker Decomposition with Beta-divergence for Music Structure Analysis of audio signals
Nov 04, 2021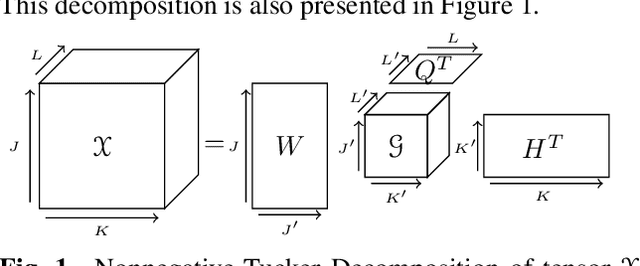
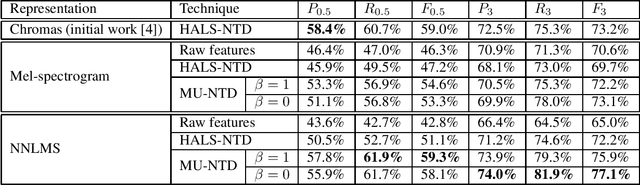

Nonnegative Tucker Decomposition (NTD), a tensor decomposition model, has received increased interest in the recent years because of its ability to blindly extract meaningful patterns in tensor data. Nevertheless, existing algorithms to compute NTD are mostly designed for the Euclidean loss. On the other hand, NTD has recently proven to be a powerful tool in Music Information Retrieval. This work proposes a Multiplicative Updates algorithm to compute NTD with the beta-divergence loss, often considered a better loss for audio processing. We notably show how to implement efficiently the multiplicative rules using tensor algebra, a naive approach being intractable. Finally, we show on a Music Structure Analysis task that unsupervised NTD fitted with beta-divergence loss outperforms earlier results obtained with the Euclidean loss.
ArchiSound: Audio Generation with Diffusion
Jan 30, 2023
The recent surge in popularity of diffusion models for image generation has brought new attention to the potential of these models in other areas of media generation. One area that has yet to be fully explored is the application of diffusion models to audio generation. Audio generation requires an understanding of multiple aspects, such as the temporal dimension, long term structure, multiple layers of overlapping sounds, and the nuances that only trained listeners can detect. In this work, we investigate the potential of diffusion models for audio generation. We propose a set of models to tackle multiple aspects, including a new method for text-conditional latent audio diffusion with stacked 1D U-Nets, that can generate multiple minutes of music from a textual description. For each model, we make an effort to maintain reasonable inference speed, targeting real-time on a single consumer GPU. In addition to trained models, we provide a collection of open source libraries with the hope of simplifying future work in the field. Samples can be found at https://bit.ly/audio-diffusion. Codes are at https://github.com/archinetai/audio-diffusion-pytorch.
LSTM Networks for Music Generation
Jun 16, 2020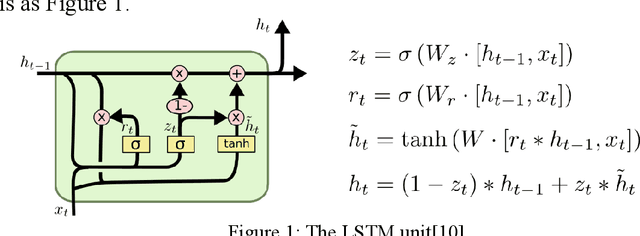
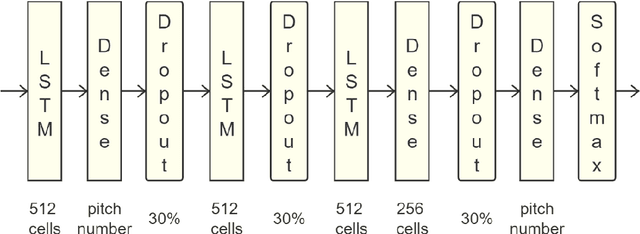
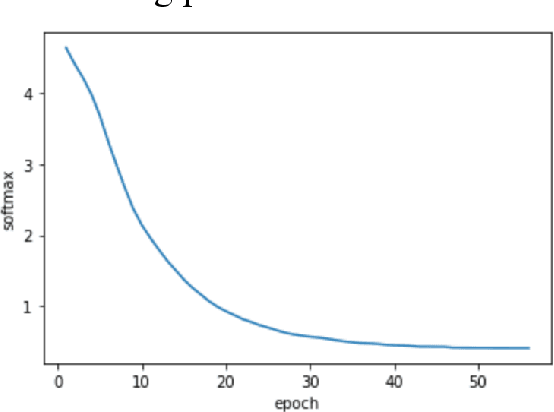
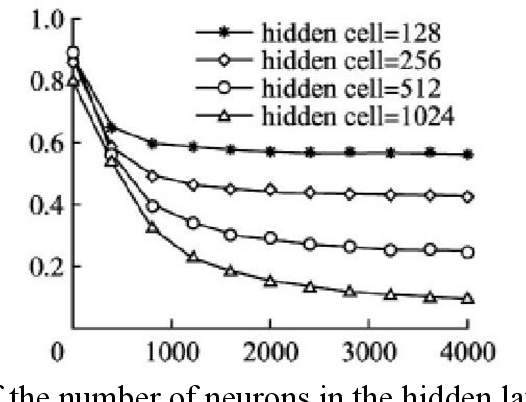
The paper presents a method of the music generation based on LSTM (Long Short-Term Memory), contrasts the effects of different network structures on the music generation and introduces other methods used by some researchers.
The Chamber Ensemble Generator: Limitless High-Quality MIR Data via Generative Modeling
Sep 28, 2022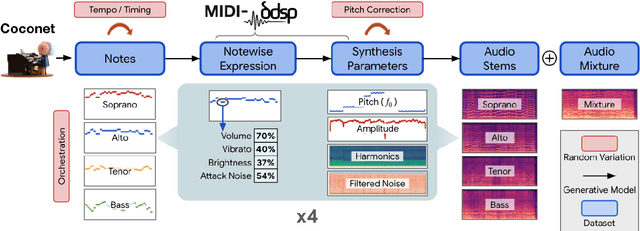
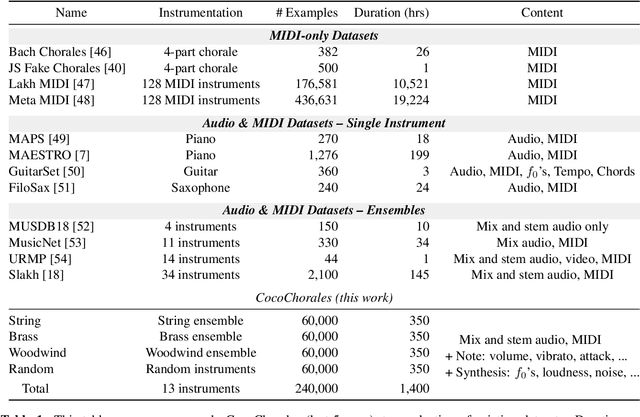
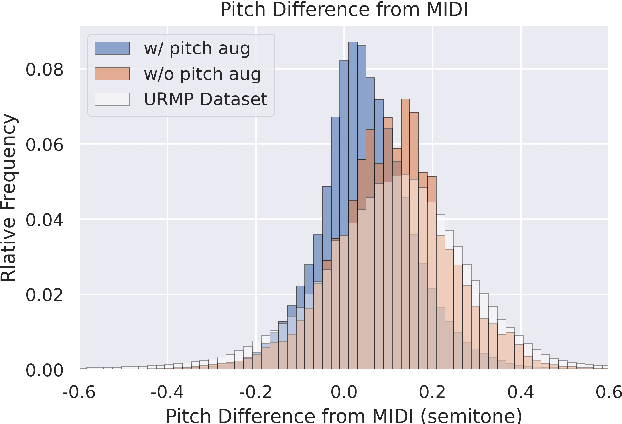
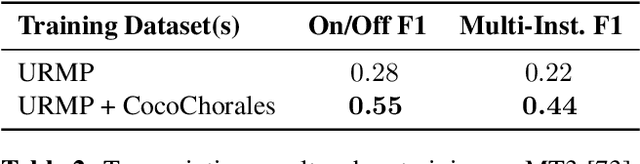
Data is the lifeblood of modern machine learning systems, including for those in Music Information Retrieval (MIR). However, MIR has long been mired by small datasets and unreliable labels. In this work, we propose to break this bottleneck using generative modeling. By pipelining a generative model of notes (Coconet trained on Bach Chorales) with a structured synthesis model of chamber ensembles (MIDI-DDSP trained on URMP), we demonstrate a system capable of producing unlimited amounts of realistic chorale music with rich annotations including mixes, stems, MIDI, note-level performance attributes (staccato, vibrato, etc.), and even fine-grained synthesis parameters (pitch, amplitude, etc.). We call this system the Chamber Ensemble Generator (CEG), and use it to generate a large dataset of chorales from four different chamber ensembles (CocoChorales). We demonstrate that data generated using our approach improves state-of-the-art models for music transcription and source separation, and we release both the system and the dataset as an open-source foundation for future work in the MIR community.
Multi-view Audio and Music Classification
Mar 03, 2021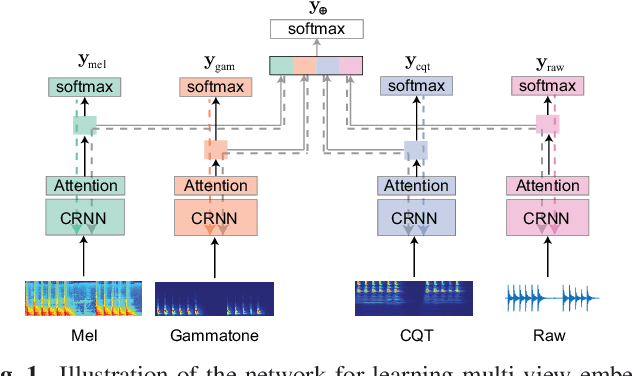
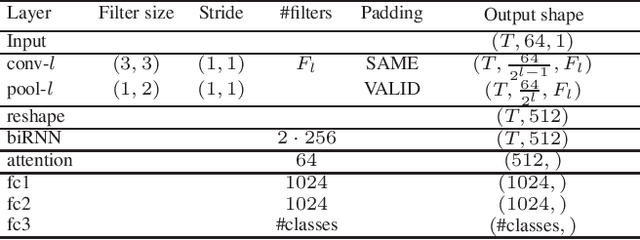
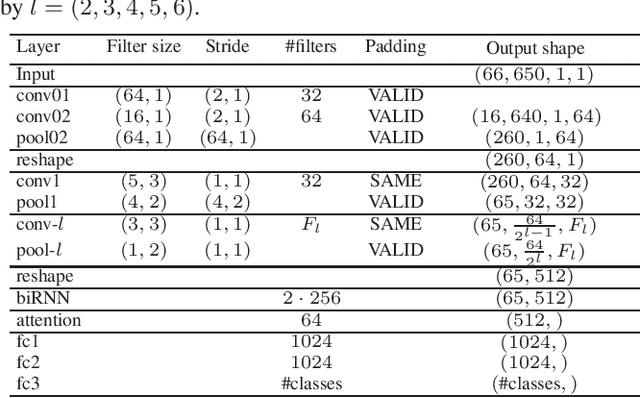
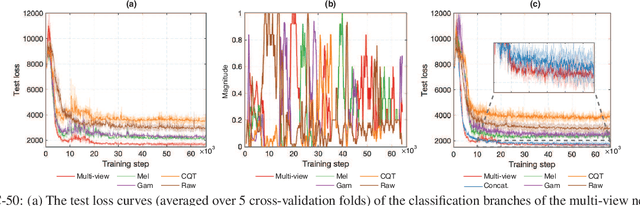
We propose in this work a multi-view learning approach for audio and music classification. Considering four typical low-level representations (i.e. different views) commonly used for audio and music recognition tasks, the proposed multi-view network consists of four subnetworks, each handling one input types. The learned embedding in the subnetworks are then concatenated to form the multi-view embedding for classification similar to a simple concatenation network. However, apart from the joint classification branch, the network also maintains four classification branches on the single-view embedding of the subnetworks. A novel method is then proposed to keep track of the learning behavior on the classification branches and adapt their weights to proportionally blend their gradients for network training. The weights are adapted in such a way that learning on a branch that is generalizing well will be encouraged whereas learning on a branch that is overfitting will be slowed down. Experiments on three different audio and music classification tasks show that the proposed multi-view network not only outperforms the single-view baselines but also is superior to the multi-view baselines based on concatenation and late fusion.