 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Cross-modal Variational Auto-encoder for Content-based Micro-video Background Music Recommendation
Jul 15, 2021
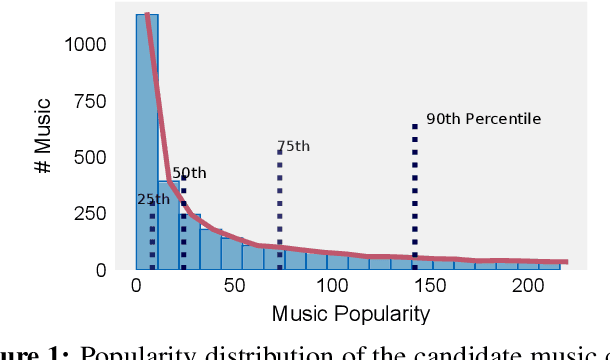
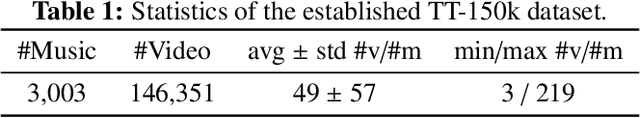

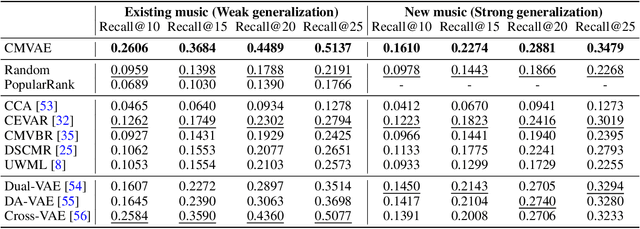
In this paper, we propose a cross-modal variational auto-encoder (CMVAE) for content-based micro-video background music recommendation. CMVAE is a hierarchical Bayesian generative model that matches relevant background music to a micro-video by projecting these two multimodal inputs into a shared low-dimensional latent space, where the alignment of two corresponding embeddings of a matched video-music pair is achieved by cross-generation. Moreover, the multimodal information is fused by the product-of-experts (PoE) principle, where the semantic information in visual and textual modalities of the micro-video are weighted according to their variance estimations such that the modality with a lower noise level is given more weights. Therefore, the micro-video latent variables contain less irrelevant information that results in a more robust model generalization. Furthermore, we establish a large-scale content-based micro-video background music recommendation dataset, TT-150k, composed of approximately 3,000 different background music clips associated to 150,000 micro-videos from different users. Extensive experiments on the established TT-150k dataset demonstrate the effectiveness of the proposed method. A qualitative assessment of CMVAE by visualizing some recommendation results is also included.
Comparison and Analysis of Deep Audio Embeddings for Music Emotion Recognition
Apr 13, 2021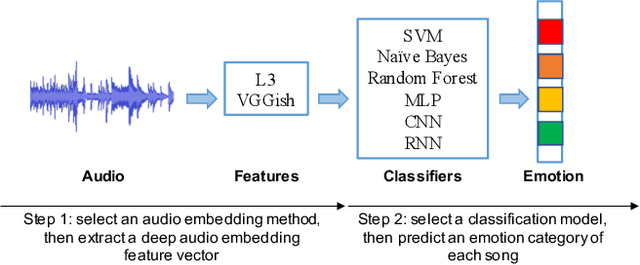
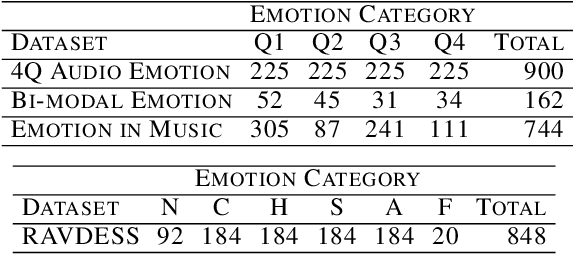
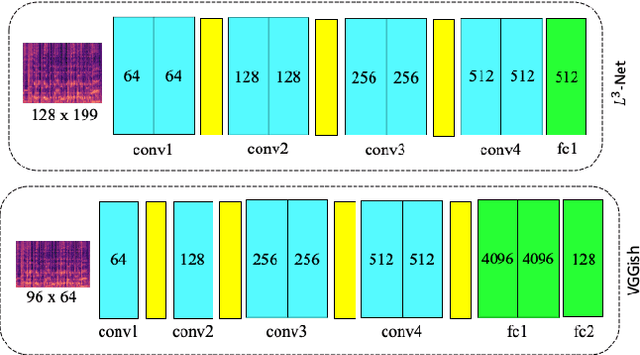
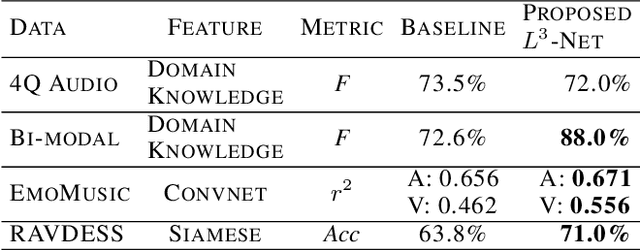
Emotion is a complicated notion present in music that is hard to capture even with fine-tuned feature engineering. In this paper, we investigate the utility of state-of-the-art pre-trained deep audio embedding methods to be used in the Music Emotion Recognition (MER) task. Deep audio embedding methods allow us to efficiently capture the high dimensional features into a compact representation. We implement several multi-class classifiers with deep audio embeddings to predict emotion semantics in music. We investigate the effectiveness of L3-Net and VGGish deep audio embedding methods for music emotion inference over four music datasets. The experiments with several classifiers on the task show that the deep audio embedding solutions can improve the performances of the previous baseline MER models. We conclude that deep audio embeddings represent musical emotion semantics for the MER task without expert human engineering.
* AAAI Workshop on Affective Content Analysis 2021 Camera Ready Version
Analysis and Detection of Singing Techniques in Repertoires of J-POP Solo Singers
Nov 15, 2022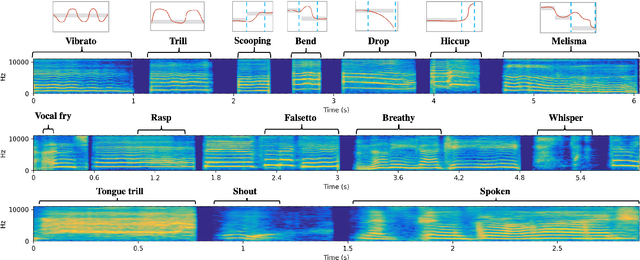
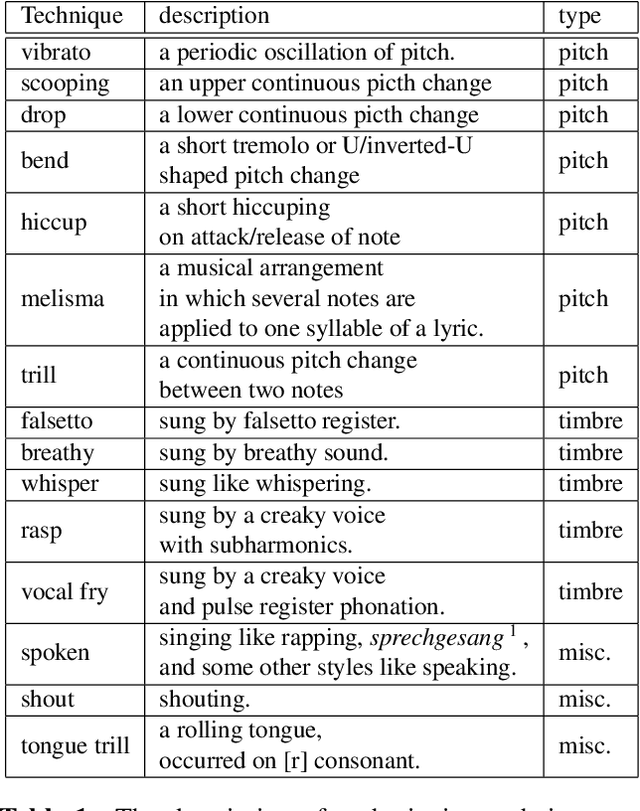
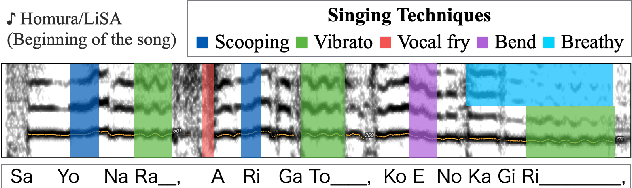
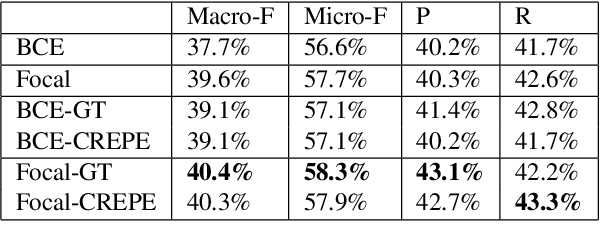
In this paper, we focus on singing techniques within the scope of music information retrieval research. We investigate how singers use singing techniques using real-world recordings of famous solo singers in Japanese popular music songs (J-POP). First, we built a new dataset of singing techniques. The dataset consists of 168 commercial J-POP songs, and each song is annotated using various singing techniques with timestamps and vocal pitch contours. We also present descriptive statistics of singing techniques on the dataset to clarify what and how often singing techniques appear. We further explored the difficulty of the automatic detection of singing techniques using previously proposed machine learning techniques. In the detection, we also investigate the effectiveness of auxiliary information (i.e., pitch and distribution of label duration), not only providing the baseline. The best result achieves 40.4% at macro-average F-measure on nine-way multi-class detection. We provide the annotation of the dataset and its detail on the appendix website 0 .
Pop2Piano : Pop Audio-based Piano Cover Generation
Nov 02, 2022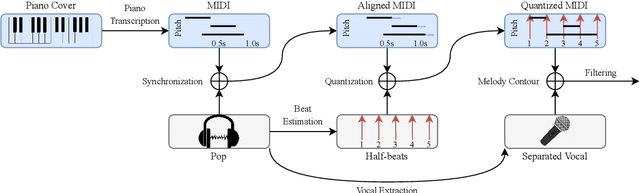

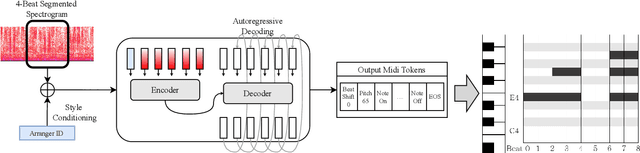
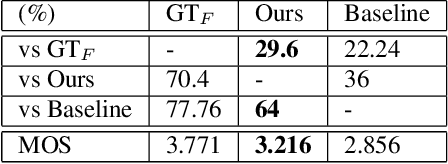
The piano cover of pop music is widely enjoyed by people. However, the generation task of the pop piano cover is still understudied. This is partly due to the lack of synchronized {Pop, Piano Cover} data pairs, which made it challenging to apply the latest data-intensive deep learning-based methods. To leverage the power of the data-driven approach, we make a large amount of paired and synchronized {pop, piano cover} data using an automated pipeline. In this paper, we present Pop2Piano, a Transformer network that generates piano covers given waveforms of pop music. To the best of our knowledge, this is the first model to directly generate a piano cover from pop audio without melody and chord extraction modules. We show that Pop2Piano trained with our dataset can generate plausible piano covers.
Learning to Denoise Historical Music
Aug 05, 2020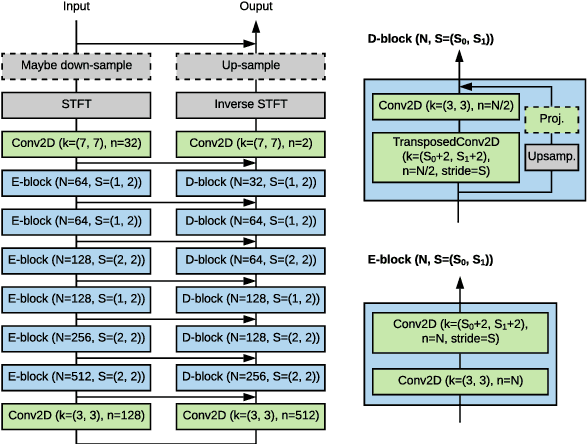
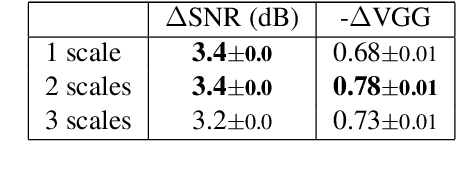
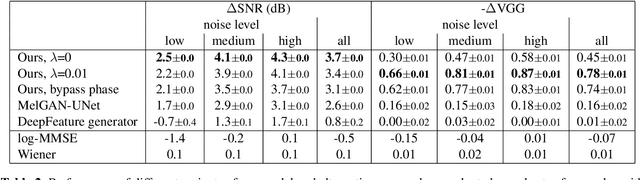
We propose an audio-to-audio neural network model that learns to denoise old music recordings. Our model internally converts its input into a time-frequency representation by means of a short-time Fourier transform (STFT), and processes the resulting complex spectrogram using a convolutional neural network. The network is trained with both reconstruction and adversarial objectives on a synthetic noisy music dataset, which is created by mixing clean music with real noise samples extracted from quiet segments of old recordings. We evaluate our method quantitatively on held-out test examples of the synthetic dataset, and qualitatively by human rating on samples of actual historical recordings. Our results show that the proposed method is effective in removing noise, while preserving the quality and details of the original music.
Embedding Calibration for Music Semantic Similarity using Auto-regressive Transformer
Mar 13, 2021
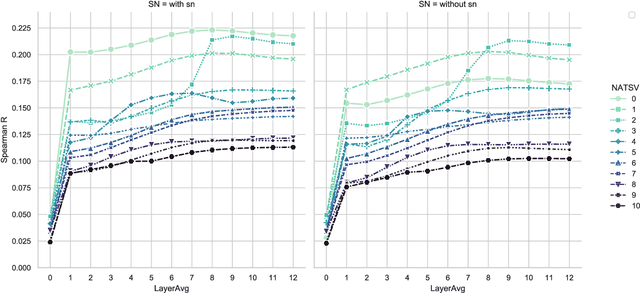
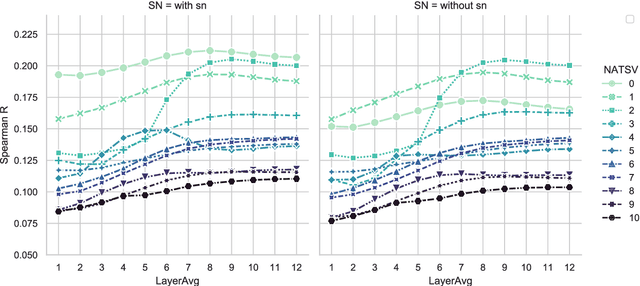
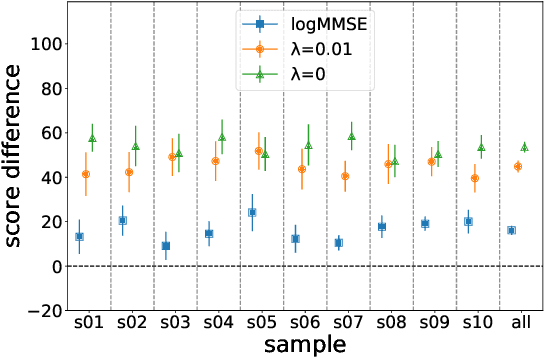
One of the advantages of using natural language processing (NLP) technology for music is to fully exploit the embedding based representation learning paradigm that can easily handle classical tasks such as semantic similarity. However, recent researches have revealed the poor performance issue of common baseline methods for semantic similarity in NLP. They show that some simple embedding calibration methods can easily promote the performance of semantic similarity without extra training hence is ready-to-use. Nevertheless, it is still unclear which is the best combination of calibration methods and by how much can we further improve the performance with such methods. Most importantly, previous works are based on auto-encoder Transformer, hence the performance under auto-regressive model for music is unclear. These render the following open questions: does embedding based semantic similarity also apply for auto-regressive music model, does poor baseline issue for semantic similarity also exists, and if so, are there unexplored embedding calibration methods to better promote the performance of music semantic similarity? In this paper, we answer these questions by exploring different combination of embedding calibration under auto-regressive language model for symbolic music. Our results show that music semantic similarity works under auto-regressive model, and also suffers from poor baseline issues like in NLP. Furthermore, we provide optimal combination of embedding calibration that has not been explored in previous researches. Results show that such combination of embedding calibration can greatly improve music semantic similarity without further training tasks.
SpecTNT: a Time-Frequency Transformer for Music Audio
Oct 18, 2021

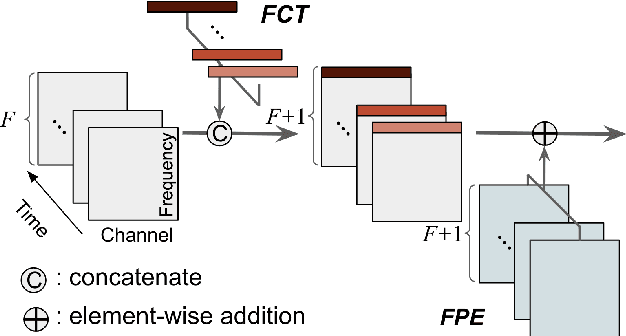
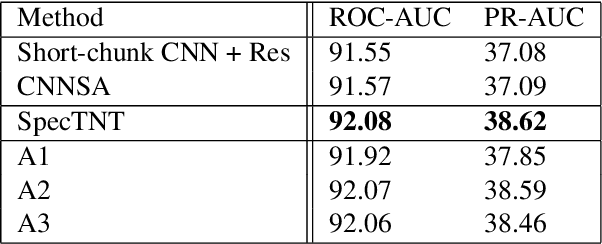
Transformers have drawn attention in the MIR field for their remarkable performance shown in natural language processing and computer vision. However, prior works in the audio processing domain mostly use Transformer as a temporal feature aggregator that acts similar to RNNs. In this paper, we propose SpecTNT, a Transformer-based architecture to model both spectral and temporal sequences of an input time-frequency representation. Specifically, we introduce a novel variant of the Transformer-in-Transformer (TNT) architecture. In each SpecTNT block, a spectral Transformer extracts frequency-related features into the frequency class token (FCT) for each frame. Later, the FCTs are linearly projected and added to the temporal embeddings (TEs), which aggregate useful information from the FCTs. Then, a temporal Transformer processes the TEs to exchange information across the time axis. By stacking the SpecTNT blocks, we build the SpecTNT model to learn the representation for music signals. In experiments, SpecTNT demonstrates state-of-the-art performance in music tagging and vocal melody extraction, and shows competitive performance for chord recognition. The effectiveness of SpecTNT and other design choices are further examined through ablation studies.
* 6 pages
Omnizart: A General Toolbox for Automatic Music Transcription
Jun 01, 2021We present and release Omnizart, a new Python library that provides a streamlined solution to automatic music transcription (AMT). Omnizart encompasses modules that construct the life-cycle of deep learning-based AMT, and is designed for ease of use with a compact command-line interface. To the best of our knowledge, Omnizart is the first transcription toolkit which offers models covering a wide class of instruments ranging from solo, instrument ensembles, percussion instruments to vocal, as well as models for chord recognition and beat/downbeat tracking, two music information retrieval (MIR) tasks highly related to AMT.
Towards Automatic Instrumentation by Learning to Separate Parts in Symbolic Multitrack Music
Jul 13, 2021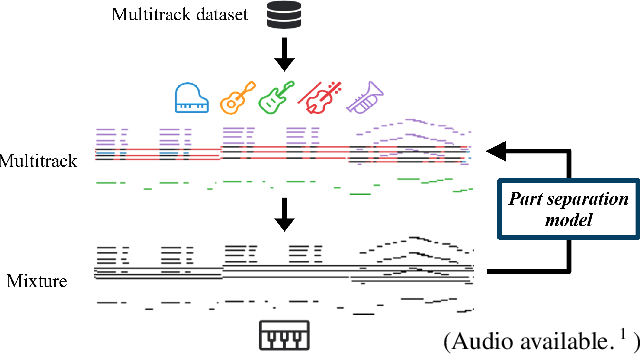


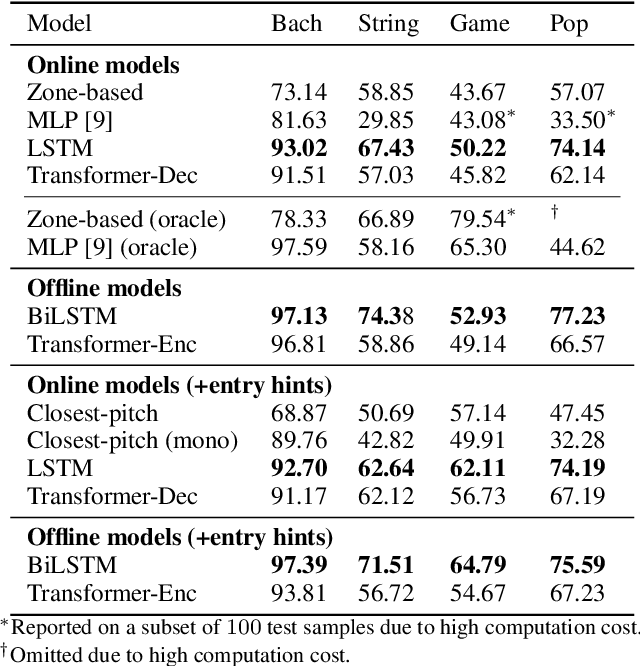
Modern keyboards allow a musician to play multiple instruments at the same time by assigning zones -- fixed pitch ranges of the keyboard -- to different instruments. In this paper, we aim to further extend this idea and examine the feasibility of automatic instrumentation -- dynamically assigning instruments to notes in solo music during performance. In addition to the online, real-time-capable setting for performative use cases, automatic instrumentation can also find applications in assistive composing tools in an offline setting. Due to the lack of paired data of original solo music and their full arrangements, we approach automatic instrumentation by learning to separate parts (e.g., voices, instruments and tracks) from their mixture in symbolic multitrack music, assuming that the mixture is to be played on a keyboard. We frame the task of part separation as a sequential multi-class classification problem and adopt machine learning to map sequences of notes into sequences of part labels. To examine the effectiveness of our proposed models, we conduct a comprehensive empirical evaluation over four diverse datasets of different genres and ensembles -- Bach chorales, string quartets, game music and pop music. Our experiments show that the proposed models outperform various baselines. We also demonstrate the potential for our proposed models to produce alternative convincing instrumentations for an existing arrangement by separating its mixture into parts. All source code and audio samples can be found at https://salu133445.github.io/arranger/ .
Use Cases for Time-Frequency Image Representations and Deep Learning Techniques for Improved Signal Classification
Feb 22, 2023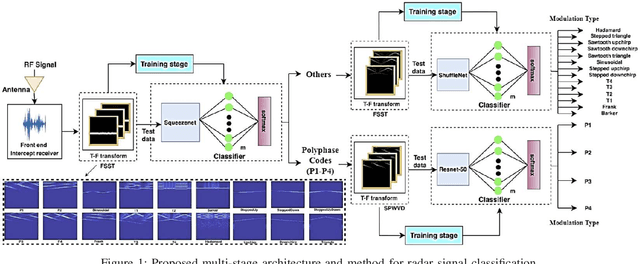
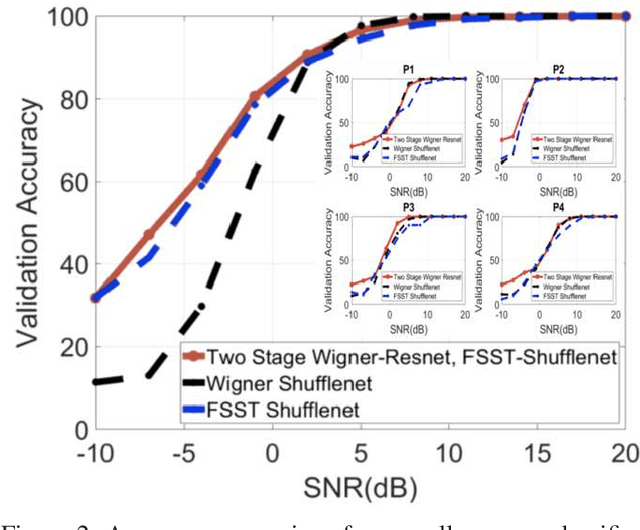
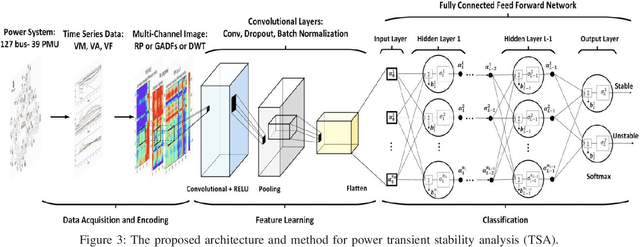
Time-frequency images (TFIs) provide a joint time-frequency representation of a signal and have become an effective tool for analyzing, characterizing, and processing non-stationary signals. Deep learning (DL) techniques have become versatile for signal classification, enabling the automatic extraction of relevant features from raw data. In this paper, we present two use cases on the time-frequency transformation and deep learning techniques for signal classification, where signals are first pre-processed and transformed into TFIs, and their features are then extracted through deep learning neural networks and classification algorithms. The specific methods and algorithms used may vary depending on the particular application, therefore different methods for creating TFIs; the Short-Time Fourier Transform (STFT), Fourier-based Synchrosqueezing Transform (FSST), Wigner Ville distribution (WVD), Smoothed Pseudo-Wigner distribution (SPWD), Choi-Williams distribution (CWD), and Continuous Wavelet Transform (CWT) are investigated. The performance of various deep learning, and convolutional neural network (CNN) models such as ResNet-50, ShuffleNet, and Squeezenet are evaluated for their accuracy of classification in different applications and the results are compared with the results of the conventional machine learning and ensemble methods such as Multilayer Perceptrons (MLP), Support Vector Machine (SVM), Random Forest (RF), Decision Tree (DT), and XGboost. The results of this research demonstrate that significant improvements in signal classification accuracy can be achieved by leveraging the combined power of TFIs, and deep learning models. These advances have found practical applications in a wide range of fields, including radar signal classification, stability analysis of power systems, speech and music recognition, and biomedical signal characterization.