 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
On loss functions and evaluation metrics for music source separation
Feb 16, 2022
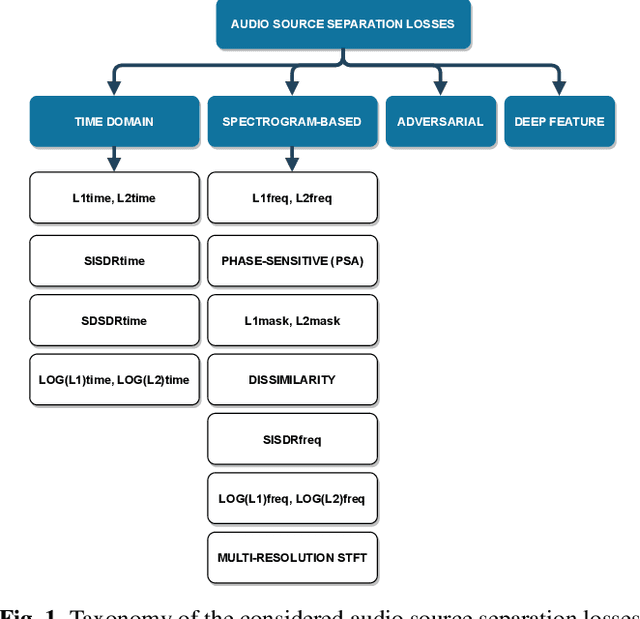
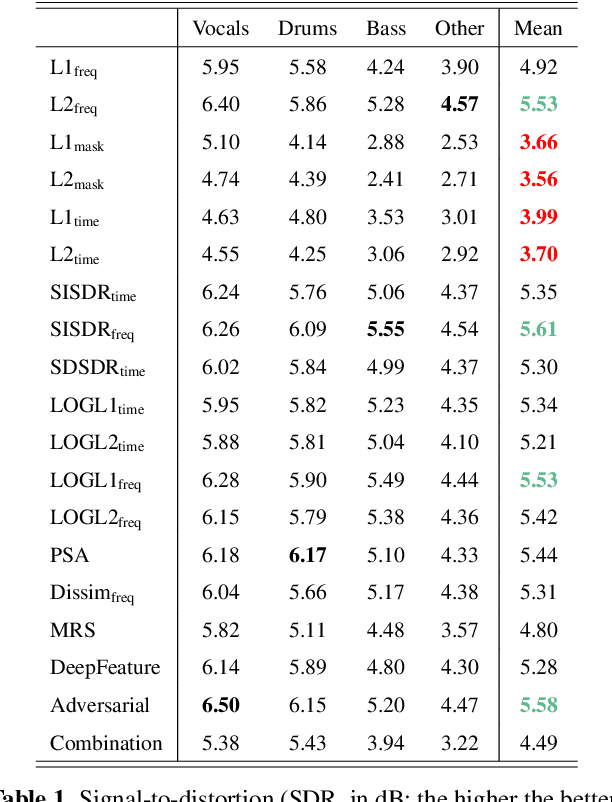
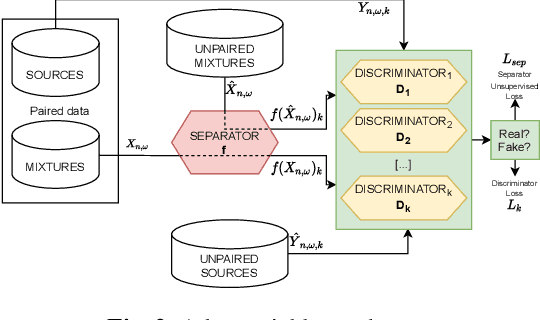
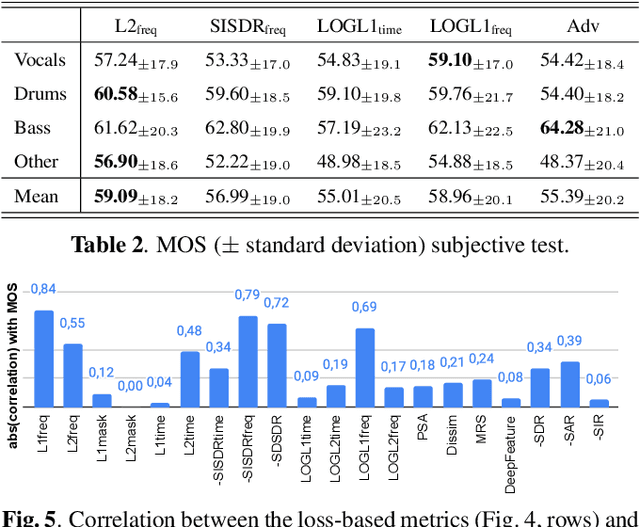
We investigate which loss functions provide better separations via benchmarking an extensive set of those for music source separation. To that end, we first survey the most representative audio source separation losses we identified, to later consistently benchmark them in a controlled experimental setup. We also explore using such losses as evaluation metrics, via cross-correlating them with the results of a subjective test. Based on the observation that the standard signal-to-distortion ratio metric can be misleading in some scenarios, we study alternative evaluation metrics based on the considered losses.
LyricJam: A system for generating lyrics for live instrumental music
Jun 03, 2021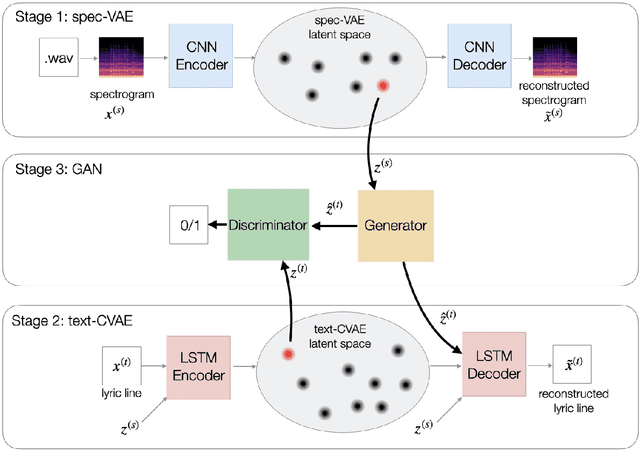

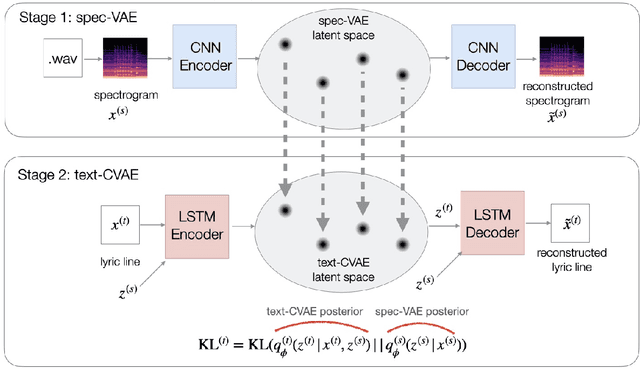
We describe a real-time system that receives a live audio stream from a jam session and generates lyric lines that are congruent with the live music being played. Two novel approaches are proposed to align the learned latent spaces of audio and text representations that allow the system to generate novel lyric lines matching live instrumental music. One approach is based on adversarial alignment of latent representations of audio and lyrics, while the other approach learns to transfer the topology from the music latent space to the lyric latent space. A user study with music artists using the system showed that the system was useful not only in lyric composition, but also encouraged the artists to improvise and find new musical expressions. Another user study demonstrated that users preferred the lines generated using the proposed methods to the lines generated by a baseline model.
Melody Infilling with User-Provided Structural Context
Oct 06, 2022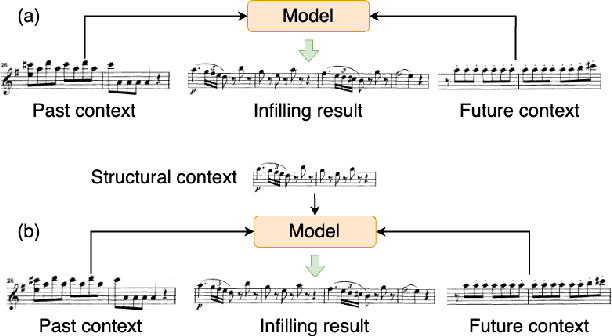
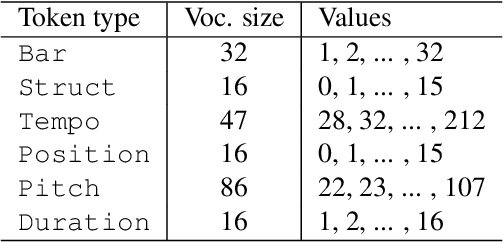
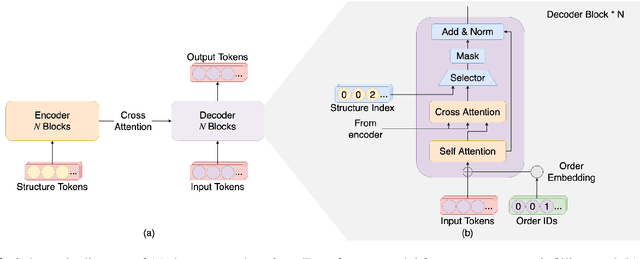
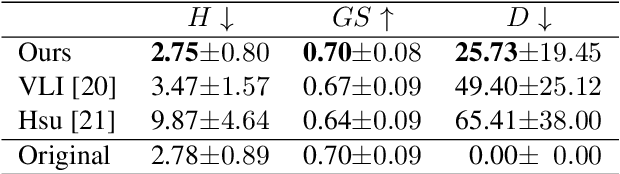
This paper proposes a novel Transformer-based model for music score infilling, to generate a music passage that fills in the gap between given past and future contexts. While existing infilling approaches can generate a passage that connects smoothly locally with the given contexts, they do not take into account the musical form or structure of the music and may therefore generate overly smooth results. To address this issue, we propose a structure-aware conditioning approach that employs a novel attention-selecting module to supply user-provided structure-related information to the Transformer for infilling. With both objective and subjective evaluations, we show that the proposed model can harness the structural information effectively and generate melodies in the style of pop of higher quality than the two existing structure-agnostic infilling models.
Downlink and Uplink Cooperative Joint Communication and Sensing
Nov 08, 2022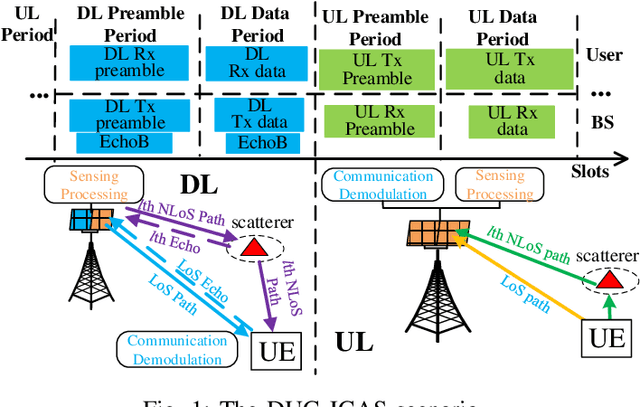
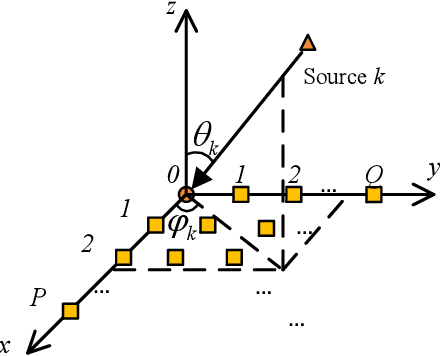
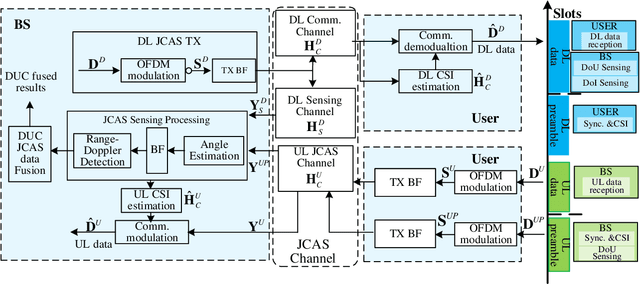
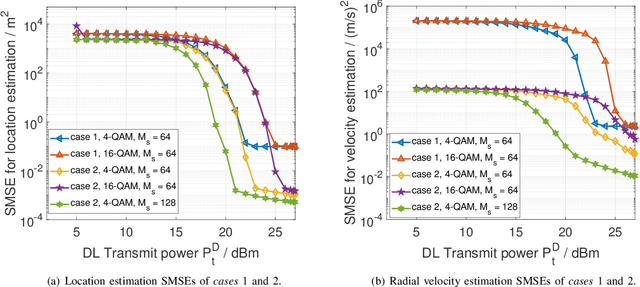
Downlink (DL) and uplink (UL) joint communication and sensing (JCAS) technologies have been individually studied for realizing sensing using DL and UL communication signals, respectively. Since the spatial environment and JCAS channels in the consecutive DL and UL JCAS time slots are generally unchanged, DL and UL JCAS may be jointly designed to achieve better sensing performance. In this paper, we propose a novel DL and UL cooperative (DUC) JCAS scheme, including a unified multiple signal classification (MUSIC)-based JCAS sensing scheme for both DL and UL JCAS and a DUC JCAS fusion method. The unified MUSIC JCAS sensing scheme can accurately estimate AoA, range, and Doppler based on a unified MUSIC-based sensing module. The DUC JCAS fusion method can distinguish between the sensing results of the communication user and other dumb targets. Moreover, by exploiting the channel reciprocity, it can also improve the sensing and channel state information (CSI) estimation accuracy. Extensive simulation results validate the proposed DUC JCAS scheme. It is shown that the minimum location and velocity estimation mean square errors of the proposed DUC JCAS scheme are about 20 dB lower than those of the state-of-the-art separated DL and UL JCAS schemes.
A Modulation Front-End for Music Audio Tagging
May 25, 2021
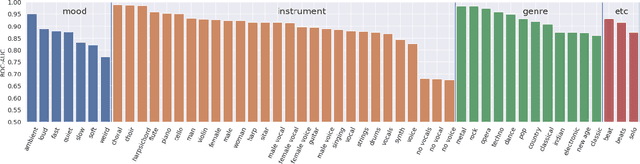
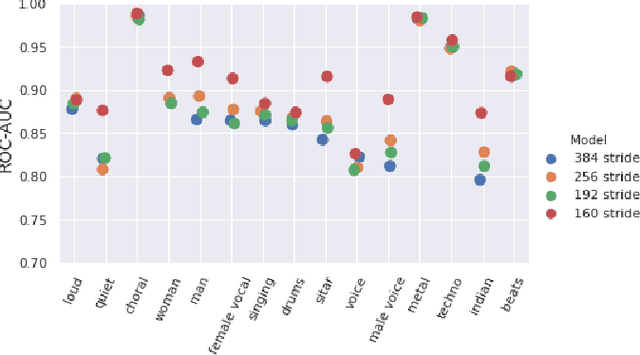
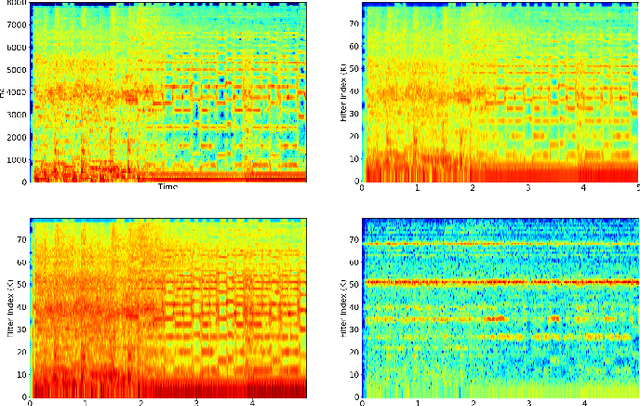
Convolutional Neural Networks have been extensively explored in the task of automatic music tagging. The problem can be approached by using either engineered time-frequency features or raw audio as input. Modulation filter bank representations that have been actively researched as a basis for timbre perception have the potential to facilitate the extraction of perceptually salient features. We explore end-to-end learned front-ends for audio representation learning, ModNet and SincModNet, that incorporate a temporal modulation processing block. The structure is effectively analogous to a modulation filter bank, where the FIR filter center frequencies are learned in a data-driven manner. The expectation is that a perceptually motivated filter bank can provide a useful representation for identifying music features. Our experimental results provide a fully visualisable and interpretable front-end temporal modulation decomposition of raw audio. We evaluate the performance of our model against the state-of-the-art of music tagging on the MagnaTagATune dataset. We analyse the impact on performance for particular tags when time-frequency bands are subsampled by the modulation filters at a progressively reduced rate. We demonstrate that modulation filtering provides promising results for music tagging and feature representation, without using extensive musical domain knowledge in the design of this front-end.
AERO: Audio Super Resolution in the Spectral Domain
Nov 22, 2022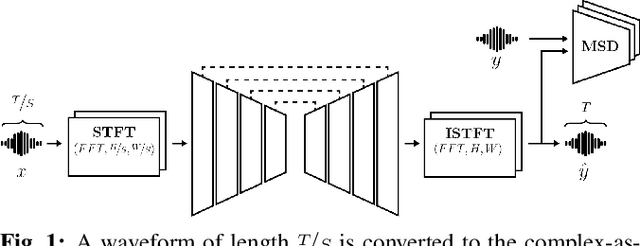
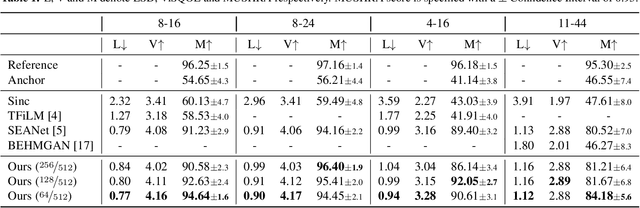
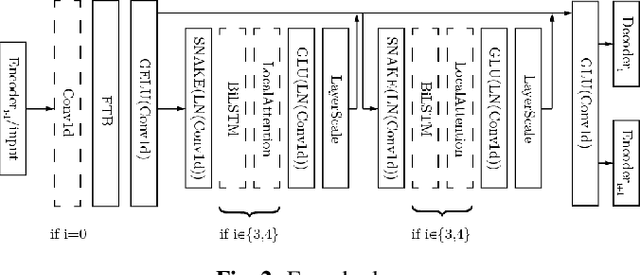
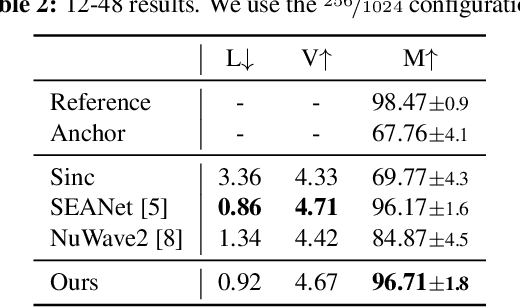
We present AERO, a audio super-resolution model that processes speech and music signals in the spectral domain. AERO is based on an encoder-decoder architecture with U-Net like skip connections. We optimize the model using both time and frequency domain loss functions. Specifically, we consider a set of reconstruction losses together with perceptual ones in the form of adversarial and feature discriminator loss functions. To better handle phase information the proposed method operates over the complex-valued spectrogram using two separate channels. Unlike prior work which mainly considers low and high frequency concatenation for audio super-resolution, the proposed method directly predicts the full frequency range. We demonstrate high performance across a wide range of sample rates considering both speech and music. AERO outperforms the evaluated baselines considering Log-Spectral Distance, ViSQOL, and the subjective MUSHRA test. Audio samples and code are available at https://pages.cs.huji.ac.il/adiyoss-lab/aero
On Narrative Information and the Distillation of Stories
Nov 22, 2022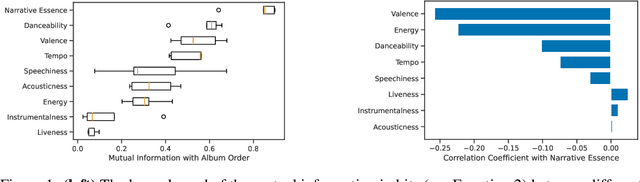
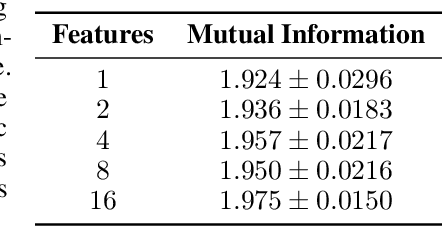
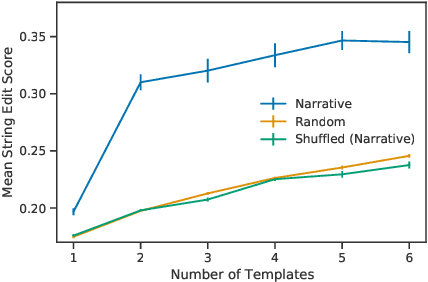
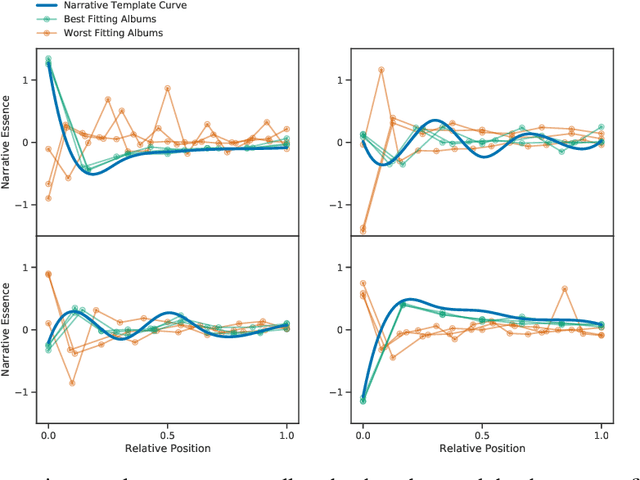
The act of telling stories is a fundamental part of what it means to be human. This work introduces the concept of narrative information, which we define to be the overlap in information space between a story and the items that compose the story. Using contrastive learning methods, we show how modern artificial neural networks can be leveraged to distill stories and extract a representation of the narrative information. We then demonstrate how evolutionary algorithms can leverage this to extract a set of narrative templates and how these templates -- in tandem with a novel curve-fitting algorithm we introduce -- can reorder music albums to automatically induce stories in them. In the process of doing so, we give strong statistical evidence that these narrative information templates are present in existing albums. While we experiment only with music albums here, the premises of our work extend to any form of (largely) independent media.
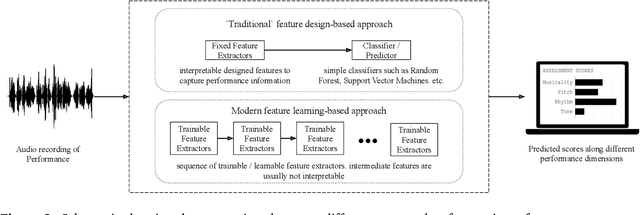
Towards Explainable Convolutional Features for Music Audio Modeling
May 31, 2021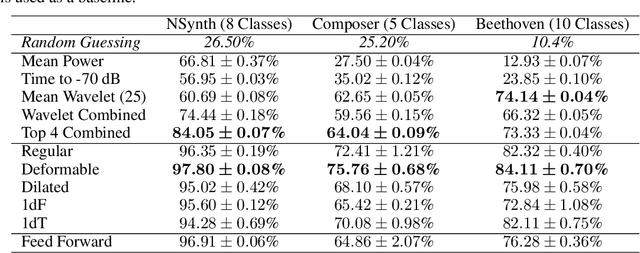
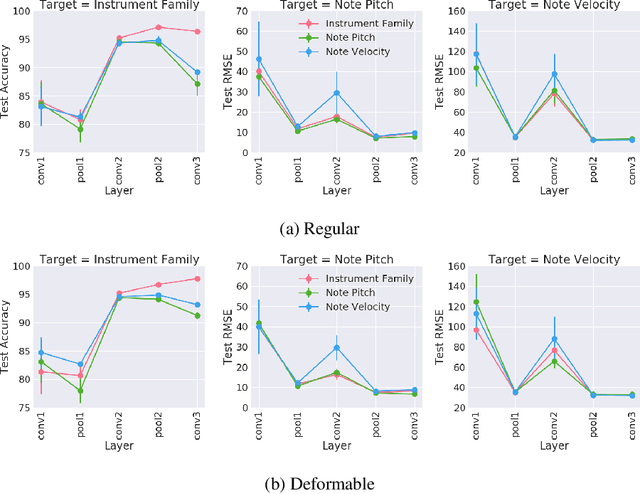

Audio signals are often represented as spectrograms and treated as 2D images. In this light, deep convolutional architectures are widely used for music audio tasks even though these two data types have very different structures. In this work, we attempt to "open the black-box" on deep convolutional models to inform future architectures for music audio tasks, and explain the excellent performance of deep convolutions that model spectrograms as 2D images. To this end, we expand recent explainability discussions in deep learning for natural image data to music audio data through systematic experiments using the deep features learned by various convolutional architectures. We demonstrate that deep convolutional features perform well across various target tasks, whether or not they are extracted from deep architectures originally trained on that task. Additionally, deep features exhibit high similarity to hand-crafted wavelet features, whether the deep features are extracted from a trained or untrained model.
Personalized musically induced emotions of not-so-popular Colombian music
Dec 09, 2021
This work presents an initial proof of concept of how Music Emotion Recognition (MER) systems could be intentionally biased with respect to annotations of musically induced emotions in a political context. In specific, we analyze traditional Colombian music containing politically charged lyrics of two types: (1) vallenatos and social songs from the "left-wing" guerrilla Fuerzas Armadas Revolucionarias de Colombia (FARC) and (2) corridos from the "right-wing" paramilitaries Autodefensas Unidas de Colombia (AUC). We train personalized machine learning models to predict induced emotions for three users with diverse political views - we aim at identifying the songs that may induce negative emotions for a particular user, such as anger and fear. To this extent, a user's emotion judgements could be interpreted as problematizing data - subjective emotional judgments could in turn be used to influence the user in a human-centered machine learning environment. In short, highly desired "emotion regulation" applications could potentially deviate to "emotion manipulation" - the recent discredit of emotion recognition technologies might transcend ethical issues of diversity and inclusion.
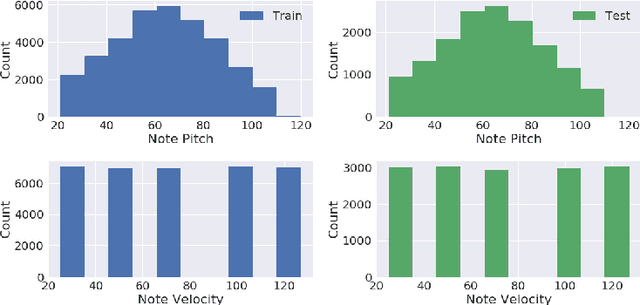
An Interdisciplinary Review of Music Performance Analysis
Apr 19, 2021
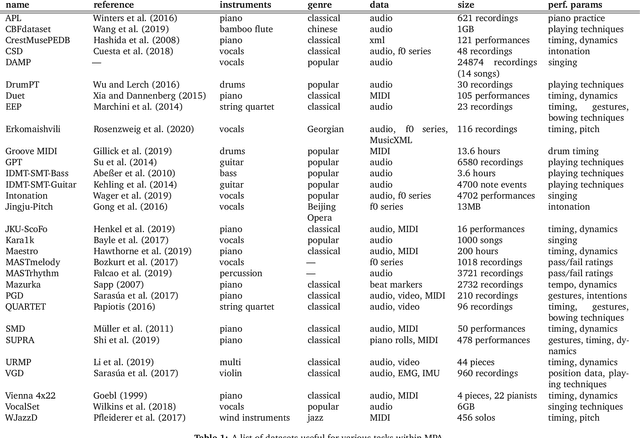
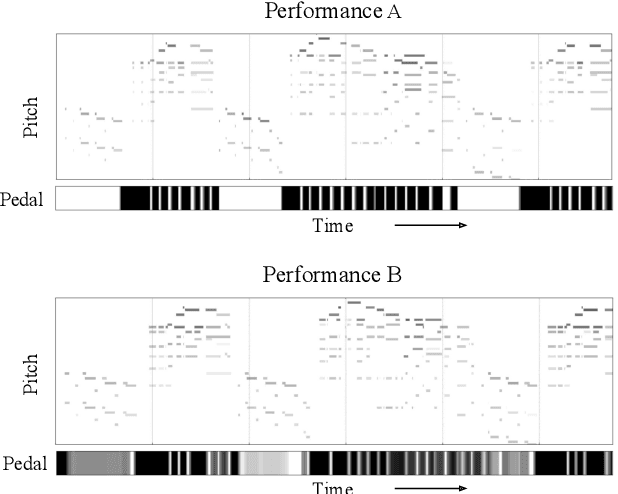
A musical performance renders an acoustic realization of a musical score or other representation of a composition. Different performances of the same composition may vary in terms of performance parameters such as timing or dynamics, and these variations may have a major impact on how a listener perceives the music. The analysis of music performance has traditionally been a peripheral topic for the MIR research community, where often a single audio recording is used as representative of a musical work. This paper surveys the field of Music Performance Analysis (MPA) from several perspectives including the measurement of performance parameters, the relation of those parameters to the actions and intentions of a performer or perceptual effects on a listener, and finally the assessment of musical performance. This paper also discusses MPA as it relates to MIR, pointing out opportunities for collaboration and future research in both areas.
* arXiv admin note: substantial text overlap with arXiv:1907.00178