 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Simple and Controllable Music Generation
Jun 08, 2023
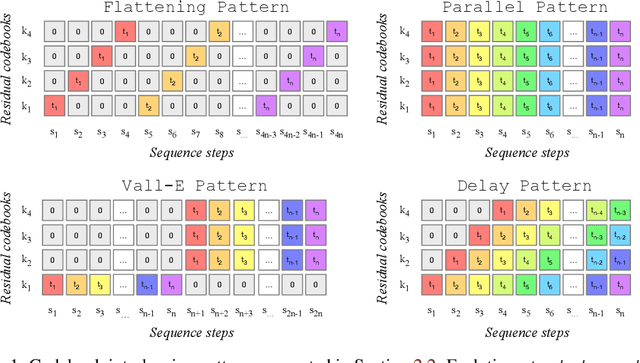
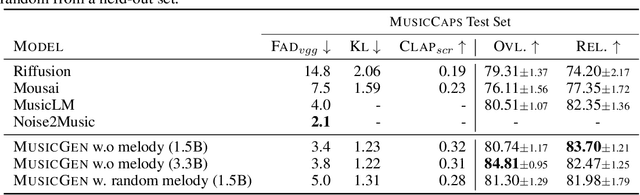
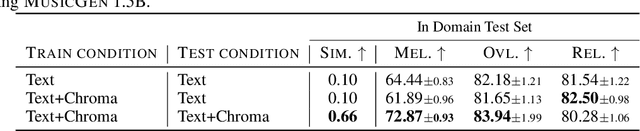
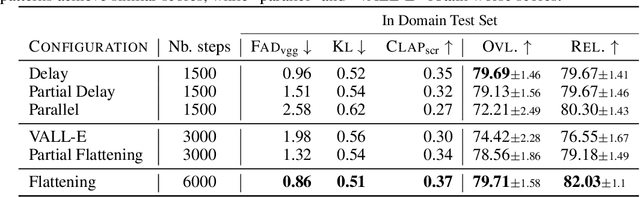
We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark. Through ablation studies, we shed light over the importance of each of the components comprising MusicGen. Music samples, code, and models are available at https://github.com/facebookresearch/audiocraft.
Equipping Pretrained Unconditional Music Transformers with Instrument and Genre Controls
Nov 21, 2023The ''pretraining-and-finetuning'' paradigm has become a norm for training domain-specific models in natural language processing and computer vision. In this work, we aim to examine this paradigm for symbolic music generation through leveraging the largest ever symbolic music dataset sourced from the MuseScore forum. We first pretrain a large unconditional transformer model using 1.5 million songs. We then propose a simple technique to equip this pretrained unconditional music transformer model with instrument and genre controls by finetuning the model with additional control tokens. Our proposed representation offers improved high-level controllability and expressiveness against two existing representations. The experimental results show that the proposed model can successfully generate music with user-specified instruments and genre. In a subjective listening test, the proposed model outperforms the pretrained baseline model in terms of coherence, harmony, arrangement and overall quality.
EnchantDance: Unveiling the Potential of Music-Driven Dance Movement
Dec 26, 2023The task of music-driven dance generation involves creating coherent dance movements that correspond to the given music. While existing methods can produce physically plausible dances, they often struggle to generalize to out-of-set data. The challenge arises from three aspects: 1) the high diversity of dance movements and significant differences in the distribution of music modalities, which make it difficult to generate music-aligned dance movements. 2) the lack of a large-scale music-dance dataset, which hinders the generation of generalized dance movements from music. 3) The protracted nature of dance movements poses a challenge to the maintenance of a consistent dance style. In this work, we introduce the EnchantDance framework, a state-of-the-art method for dance generation. Due to the redundancy of the original dance sequence along the time axis, EnchantDance first constructs a strong dance latent space and then trains a dance diffusion model on the dance latent space. To address the data gap, we construct a large-scale music-dance dataset, ChoreoSpectrum3D Dataset, which includes four dance genres and has a total duration of 70.32 hours, making it the largest reported music-dance dataset to date. To enhance consistency between music genre and dance style, we pre-train a music genre prediction network using transfer learning and incorporate music genre as extra conditional information in the training of the dance diffusion model. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on dance quality, diversity, and consistency.
Composer Style-specific Symbolic Music Generation Using Vector Quantized Discrete Diffusion Models
Oct 21, 2023Emerging Denoising Diffusion Probabilistic Models (DDPM) have become increasingly utilised because of promising results they have achieved in diverse generative tasks with continuous data, such as image and sound synthesis. Nonetheless, the success of diffusion models has not been fully extended to discrete symbolic music. We propose to combine a vector quantized variational autoencoder (VQ-VAE) and discrete diffusion models for the generation of symbolic music with desired composer styles. The trained VQ-VAE can represent symbolic music as a sequence of indexes that correspond to specific entries in a learned codebook. Subsequently, a discrete diffusion model is used to model the VQ-VAE's discrete latent space. The diffusion model is trained to generate intermediate music sequences consisting of codebook indexes, which are then decoded to symbolic music using the VQ-VAE's decoder. The results demonstrate our model can generate symbolic music with target composer styles that meet the given conditions with a high accuracy of 72.36%.
Automatic Time Signature Determination for New Scores Using Lyrics for Latent Rhythmic Structure
Nov 27, 2023There has recently been a sharp increase in interest in Artificial Intelligence-Generated Content (AIGC). Despite this, musical components such as time signatures have not been studied sufficiently to form an algorithmic determination approach for new compositions, especially lyrical songs. This is likely because of the neglect of musical details, which is critical for constructing a robust framework. Specifically, time signatures establish the fundamental rhythmic structure for almost all aspects of a song, including the phrases and notes. In this paper, we propose a novel approach that only uses lyrics as input to automatically generate a fitting time signature for lyrical songs and uncover the latent rhythmic structure utilizing explainable machine learning models. In particular, we devise multiple methods that are associated with discovering lyrical patterns and creating new features that simultaneously contain lyrical, rhythmic, and statistical information. In this approach, the best of our experimental results reveal a 97.6% F1 score and a 0.996 Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) score. In conclusion, our research directly generates time signatures from lyrics automatically for new scores utilizing machine learning, which is an innovative idea that approaches an understudied component of musicology and therefore contributes significantly to the future of Artificial Intelligence (AI) music generation.
Masked Audio Generation using a Single Non-Autoregressive Transformer
Jan 09, 2024We introduce MAGNeT, a masked generative sequence modeling method that operates directly over several streams of audio tokens. Unlike prior work, MAGNeT is comprised of a single-stage, non-autoregressive transformer. During training, we predict spans of masked tokens obtained from a masking scheduler, while during inference we gradually construct the output sequence using several decoding steps. To further enhance the quality of the generated audio, we introduce a novel rescoring method in which, we leverage an external pre-trained model to rescore and rank predictions from MAGNeT, which will be then used for later decoding steps. Lastly, we explore a hybrid version of MAGNeT, in which we fuse between autoregressive and non-autoregressive models to generate the first few seconds in an autoregressive manner while the rest of the sequence is being decoded in parallel. We demonstrate the efficiency of MAGNeT for the task of text-to-music and text-to-audio generation and conduct an extensive empirical evaluation, considering both objective metrics and human studies. The proposed approach is comparable to the evaluated baselines, while being significantly faster (x7 faster than the autoregressive baseline). Through ablation studies and analysis, we shed light on the importance of each of the components comprising MAGNeT, together with pointing to the trade-offs between autoregressive and non-autoregressive modeling, considering latency, throughput, and generation quality. Samples are available on our demo page https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT.
CREPE Notes: A new method for segmenting pitch contours into discrete notes
Nov 15, 2023Tracking the fundamental frequency (f0) of a monophonic instrumental performance is effectively a solved problem with several solutions achieving 99% accuracy. However, the related task of automatic music transcription requires a further processing step to segment an f0 contour into discrete notes. This sub-task of note segmentation is necessary to enable a range of applications including musicological analysis and symbolic music generation. Building on CREPE, a state-of-the-art monophonic pitch tracking solution based on a simple neural network, we propose a simple and effective method for post-processing CREPE's output to achieve monophonic note segmentation. The proposed method demonstrates state-of-the-art results on two challenging datasets of monophonic instrumental music. Our approach also gives a 97% reduction in the total number of parameters used when compared with other deep learning based methods.
Content-based Controls For Music Large Language Modeling
Oct 26, 2023Recent years have witnessed a rapid growth of large-scale language models in the domain of music audio. Such models enable end-to-end generation of higher-quality music, and some allow conditioned generation using text descriptions. However, the control power of text controls on music is intrinsically limited, as they can only describe music indirectly through meta-data (such as singers and instruments) or high-level representations (such as genre and emotion). We aim to further equip the models with direct and content-based controls on innate music languages such as pitch, chords and drum track. To this end, we contribute Coco-Mulla, a content-based control method for music large language modeling. It uses a parameter-efficient fine-tuning (PEFT) method tailored for Transformer-based audio models. Experiments show that our approach achieved high-quality music generation with low-resource semi-supervised learning, tuning with less than 4% parameters compared to the original model and training on a small dataset with fewer than 300 songs. Moreover, our approach enables effective content-based controls, and we illustrate the control power via chords and rhythms, two of the most salient features of music audio. Furthermore, we show that by combining content-based controls and text descriptions, our system achieves flexible music variation generation and style transfer. Our source codes and demos are available online.
DiffuseRoll: Multi-track multi-category music generation based on diffusion model
Mar 14, 2023Recent advancements in generative models have shown remarkable progress in music generation. However, most existing methods focus on generating monophonic or homophonic music, while the generation of polyphonic and multi-track music with rich attributes is still a challenging task. In this paper, we propose a novel approach for multi-track, multi-attribute symphonic music generation using the diffusion model. Specifically, we generate piano-roll representations with a diffusion model and map them to MIDI format for output. To capture rich attribute information, we introduce a color coding scheme to encode note sequences into color and position information that represents pitch,velocity, and instrument. This scheme enables a seamless mapping between discrete music sequences and continuous images. We also propose a post-processing method to optimize the generated scores for better performance. Experimental results show that our method outperforms state-of-the-art methods in terms of polyphonic music generation with rich attribute information compared to the figure methods.
Explore 3D Dance Generation via Reward Model from Automatically-Ranked Demonstrations
Dec 18, 2023This paper presents an Exploratory 3D Dance generation framework, E3D2, designed to address the exploration capability deficiency in existing music-conditioned 3D dance generation models. Current models often generate monotonous and simplistic dance sequences that misalign with human preferences because they lack exploration capabilities. The E3D2 framework involves a reward model trained from automatically-ranked dance demonstrations, which then guides the reinforcement learning process. This approach encourages the agent to explore and generate high quality and diverse dance movement sequences. The soundness of the reward model is both theoretically and experimentally validated. Empirical experiments demonstrate the effectiveness of E3D2 on the AIST++ dataset. Project Page: https://sites.google.com/view/e3d2.