 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Midi Miner -- A Python library for tonal tension and track classification
Oct 03, 2019
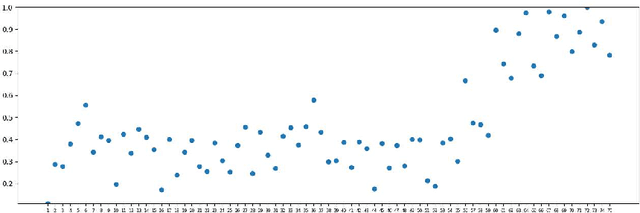
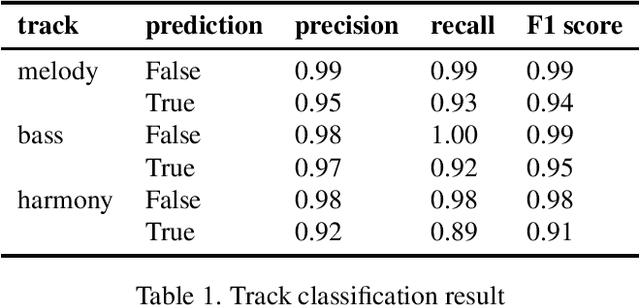
We present a Python library, called Midi Miner, that can calculate tonal tension and classify different tracks. MIDI (Music Instrument Digital Interface) is a hardware and software standard for communicating musical events between digital music devices. It is often used for tasks such as music representation, communication between devices, and even music generation [5]. Tension is an essential element of the music listening experience, which can come from a number of musical features including timbre, loudness and harmony [3]. Midi Miner provides a Python implementation for the tonal tension model based on the spiral array [1] as presented by Herremans and Chew [4]. Midi Miner also performs key estimation and includes a track classifier that can disentangle melody, bass, and harmony tracks. Even though tracks are often separated in MIDI files, the musical function of each track is not always clear. The track classifier keeps the identified tracks and discards messy tracks, which can enable further analysis and training tasks.
Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
Jan 21, 2021

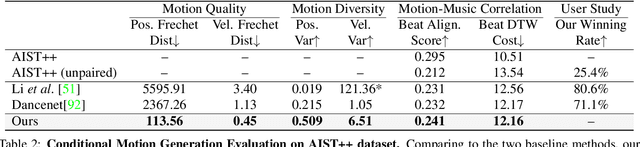

In this paper, we present a transformer-based learning framework for 3D dance generation conditioned on music. We carefully design our network architecture and empirically study the keys for obtaining qualitatively pleasing results. The critical components include a deep cross-modal transformer, which well learns the correlation between the music and dance motion; and the full-attention with future-N supervision mechanism which is essential in producing long-range non-freezing motion. In addition, we propose a new dataset of paired 3D motion and music called AIST++, which we reconstruct from the AIST multi-view dance videos. This dataset contains 1.1M frames of 3D dance motion in 1408 sequences, covering 10 genres of dance choreographies and accompanied with multi-view camera parameters. To our knowledge it is the largest dataset of this kind. Rich experiments on AIST++ demonstrate our method produces much better results than the state-of-the-art methods both qualitatively and quantitatively.
Music2Video: Automatic Generation of Music Video with fusion of audio and text
Jan 11, 2022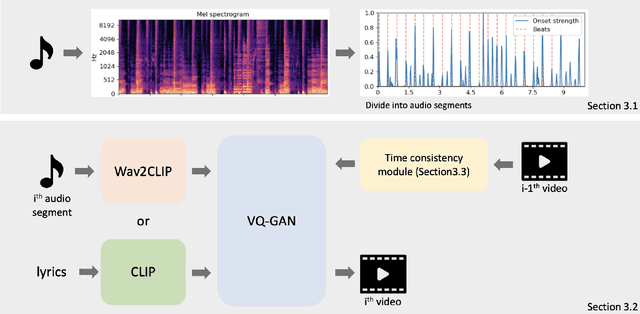


Creation of images using generative adversarial networks has been widely adapted into multi-modal regime with the advent of multi-modal representation models pre-trained on large corpus. Various modalities sharing a common representation space could be utilized to guide the generative models to create images from text or even from audio source. Departing from the previous methods that solely rely on either text or audio, we exploit the expressiveness of both modality. Based on the fusion of text and audio, we create video whose content is consistent with the distinct modalities that are provided. A simple approach to automatically segment the video into variable length intervals and maintain time consistency in generated video is part of our method. Our proposed framework for generating music video shows promising results in application level where users can interactively feed in music source and text source to create artistic music videos. Our code is available at https://github.com/joeljang/music2video.
From Context to Concept: Exploring Semantic Relationships in Music with Word2Vec
Nov 29, 2018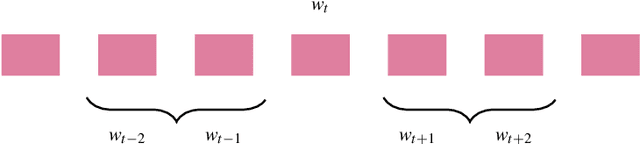

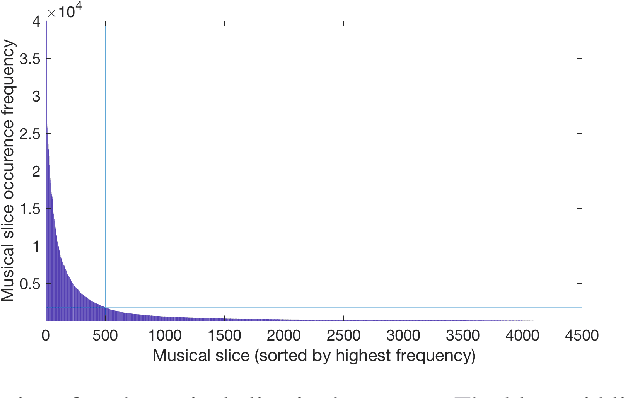
We explore the potential of a popular distributional semantics vector space model, word2vec, for capturing meaningful relationships in ecological (complex polyphonic) music. More precisely, the skip-gram version of word2vec is used to model slices of music from a large corpus spanning eight musical genres. In this newly learned vector space, a metric based on cosine distance is able to distinguish between functional chord relationships, as well as harmonic associations in the music. Evidence, based on cosine distance between chord-pair vectors, suggests that an implicit circle-of-fifths exists in the vector space. In addition, a comparison between pieces in different keys reveals that key relationships are represented in word2vec space. These results suggest that the newly learned embedded vector representation does in fact capture tonal and harmonic characteristics of music, without receiving explicit information about the musical content of the constituent slices. In order to investigate whether proximity in the discovered space of embeddings is indicative of `semantically-related' slices, we explore a music generation task, by automatically replacing existing slices from a given piece of music with new slices. We propose an algorithm to find substitute slices based on spatial proximity and the pitch class distribution inferred in the chosen subspace. The results indicate that the size of the subspace used has a significant effect on whether slices belonging to the same key are selected. In sum, the proposed word2vec model is able to learn music-vector embeddings that capture meaningful tonal and harmonic relationships in music, thereby providing a useful tool for exploring musical properties and comparisons across pieces, as a potential input representation for deep learning models, and as a music generation device.
* Accepted for publication in Neural Computing and Applications, Springer. In Press
Lead Sheet Generation and Arrangement by Conditional Generative Adversarial Network
Jul 30, 2018
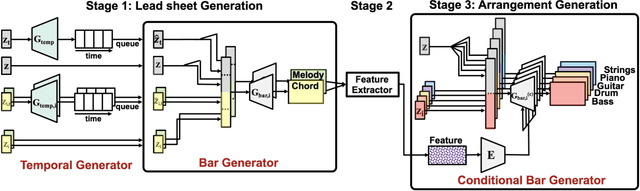
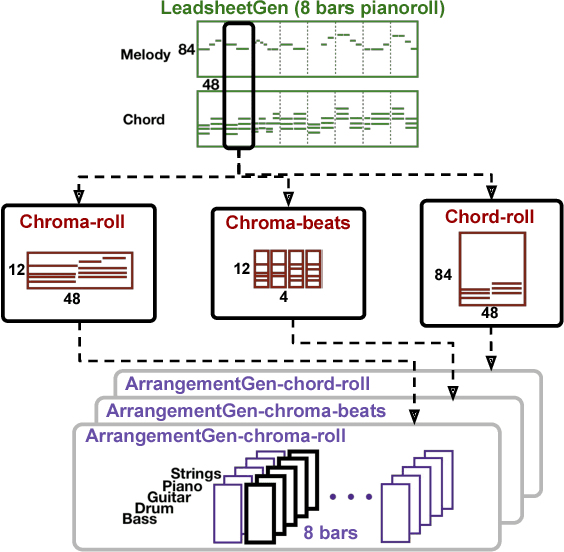
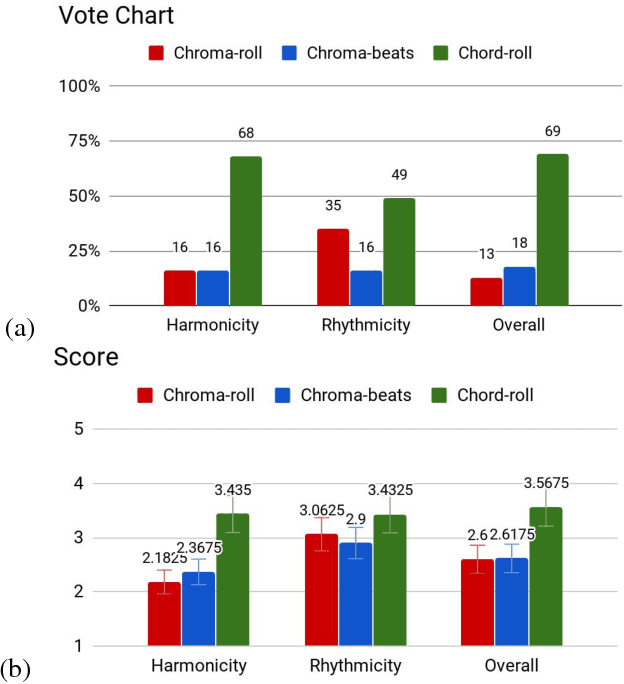
Research on automatic music generation has seen great progress due to the development of deep neural networks. However, the generation of multi-instrument music of arbitrary genres still remains a challenge. Existing research either works on lead sheets or multi-track piano-rolls found in MIDIs, but both musical notations have their limits. In this work, we propose a new task called lead sheet arrangement to avoid such limits. A new recurrent convolutional generative model for the task is proposed, along with three new symbolic-domain harmonic features to facilitate learning from unpaired lead sheets and MIDIs. Our model can generate lead sheets and their arrangements of eight-bar long. Audio samples of the generated result can be found at https://drive.google.com/open?id=1c0FfODTpudmLvuKBbc23VBCgQizY6-Rk
MelNet: A Generative Model for Audio in the Frequency Domain
Jun 04, 2019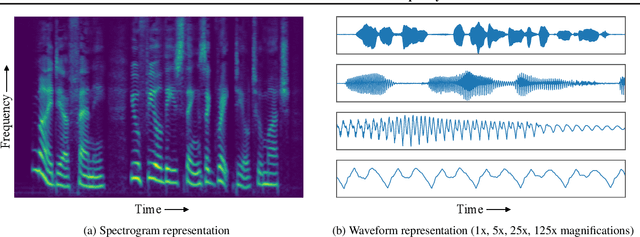
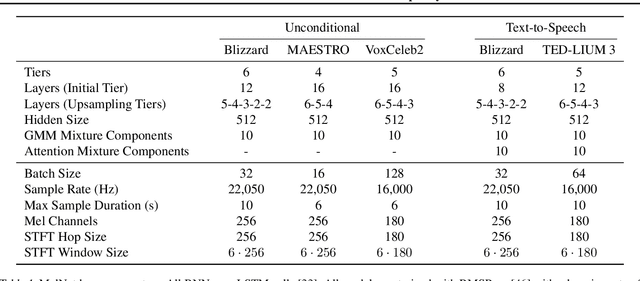


Capturing high-level structure in audio waveforms is challenging because a single second of audio spans tens of thousands of timesteps. While long-range dependencies are difficult to model directly in the time domain, we show that they can be more tractably modelled in two-dimensional time-frequency representations such as spectrograms. By leveraging this representational advantage, in conjunction with a highly expressive probabilistic model and a multiscale generation procedure, we design a model capable of generating high-fidelity audio samples which capture structure at timescales that time-domain models have yet to achieve. We apply our model to a variety of audio generation tasks, including unconditional speech generation, music generation, and text-to-speech synthesis---showing improvements over previous approaches in both density estimates and human judgments.
Score difficulty analysis for piano performance education based on fingering
Mar 24, 2022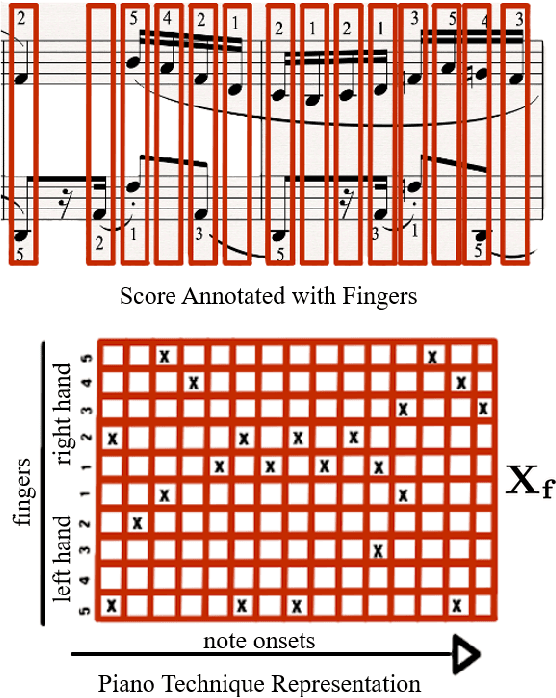

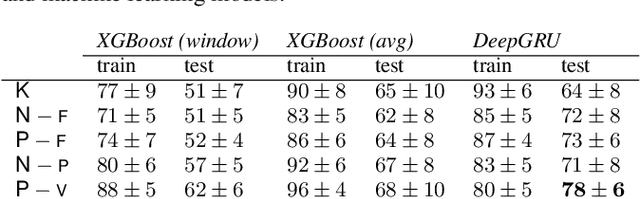
In this paper, we introduce score difficulty classification as a sub-task of music information retrieval (MIR), which may be used in music education technologies, for personalised curriculum generation, and score retrieval. We introduce a novel dataset for our task, Mikrokosmos-difficulty, containing 147 piano pieces in symbolic representation and the corresponding difficulty labels derived by its composer B\'ela Bart\'ok and the publishers. As part of our methodology, we propose piano technique feature representations based on different piano fingering algorithms. We use these features as input for two classifiers: a Gated Recurrent Unit neural network (GRU) with attention mechanism and gradient-boosted trees trained on score segments. We show that for our dataset fingering based features perform better than a simple baseline considering solely the notes in the score. Furthermore, the GRU with attention mechanism classifier surpasses the gradient-boosted trees. Our proposed models are interpretable and are capable of generating difficulty feedback both locally, on short term segments, and globally, for whole pieces. Code, datasets, models, and an online demo are made available for reproducibility
Convolutional Generative Adversarial Networks with Binary Neurons for Polyphonic Music Generation
Oct 06, 2018


It has been shown recently that deep convolutional generative adversarial networks (GANs) can learn to generate music in the form of piano-rolls, which represent music by binary-valued time-pitch matrices. However, existing models can only generate real-valued piano-rolls and require further post-processing, such as hard thresholding (HT) or Bernoulli sampling (BS), to obtain the final binary-valued results. In this paper, we study whether we can have a convolutional GAN model that directly creates binary-valued piano-rolls by using binary neurons. Specifically, we propose to append to the generator an additional refiner network, which uses binary neurons at the output layer. The whole network is trained in two stages. Firstly, the generator and the discriminator are pretrained. Then, the refiner network is trained along with the discriminator to learn to binarize the real-valued piano-rolls the pretrained generator creates. Experimental results show that using binary neurons instead of HT or BS indeed leads to better results in a number of objective measures. Moreover, deterministic binary neurons perform better than stochastic ones in both objective measures and a subjective test. The source code, training data and audio examples of the generated results can be found at https://salu133445.github.io/bmusegan/ .
MG-VAE: Deep Chinese Folk Songs Generation with Specific Regional Style
Sep 29, 2019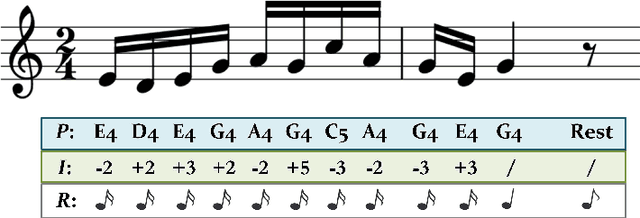
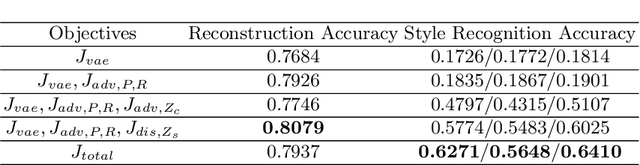
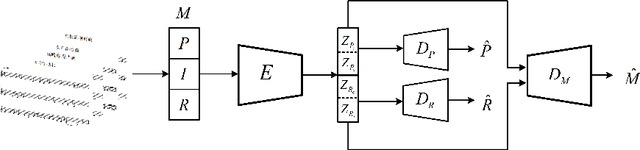
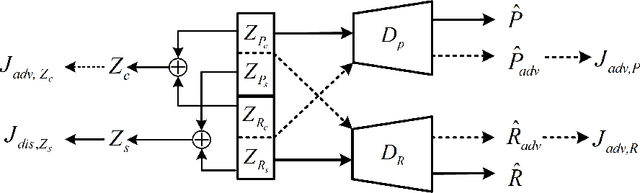
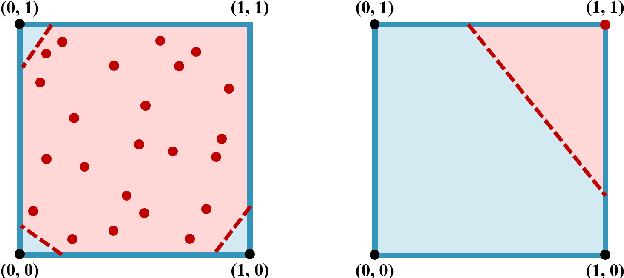
Regional style in Chinese folk songs is a rich treasure that can be used for ethnic music creation and folk culture research. In this paper, we propose MG-VAE, a music generative model based on VAE (Variational Auto-Encoder) that is capable of capturing specific music style and generating novel tunes for Chinese folk songs (Min Ge) in a manipulatable way. Specifically, we disentangle the latent space of VAE into four parts in an adversarial training way to control the information of pitch and rhythm sequence, as well as of music style and content. In detail, two classifiers are used to separate style and content latent space, and temporal supervision is utilized to disentangle the pitch and rhythm sequence. The experimental results show that the disentanglement is successful and our model is able to create novel folk songs with controllable regional styles. To our best knowledge, this is the first study on applying deep generative model and adversarial training for Chinese music generation.
Semi-Recurrent CNN-based VAE-GAN for Sequential Data Generation
Jun 01, 2018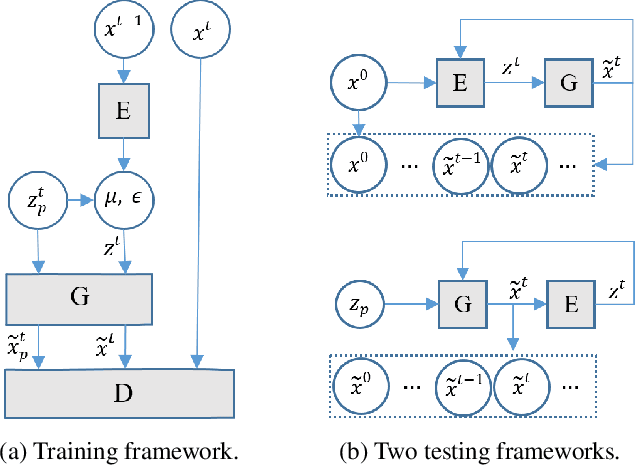
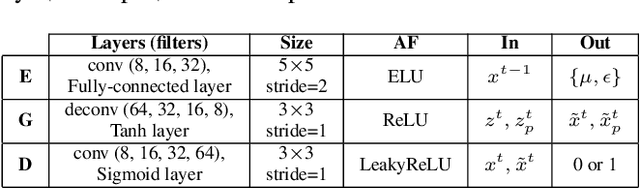
A semi-recurrent hybrid VAE-GAN model for generating sequential data is introduced. In order to consider the spatial correlation of the data in each frame of the generated sequence, CNNs are utilized in the encoder, generator, and discriminator. The subsequent frames are sampled from the latent distributions obtained by encoding the previous frames. As a result, the dependencies between the frames are maintained. Two testing frameworks for synthesizing a sequence with any number of frames are also proposed. The promising experimental results on piano music generation indicates the potential of the proposed framework in modeling other sequential data such as video.
* 5 pages, 6 figures, ICASSP 2018