 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs
Jan 07, 2021
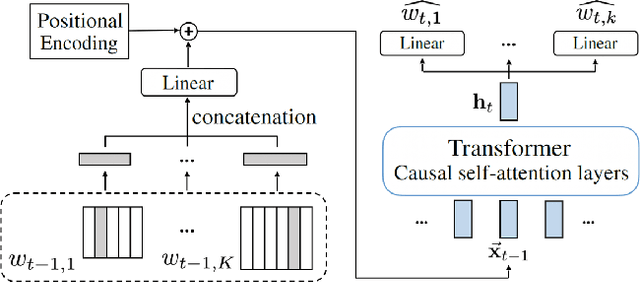
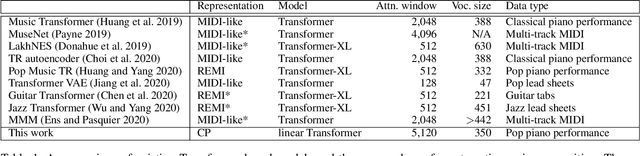
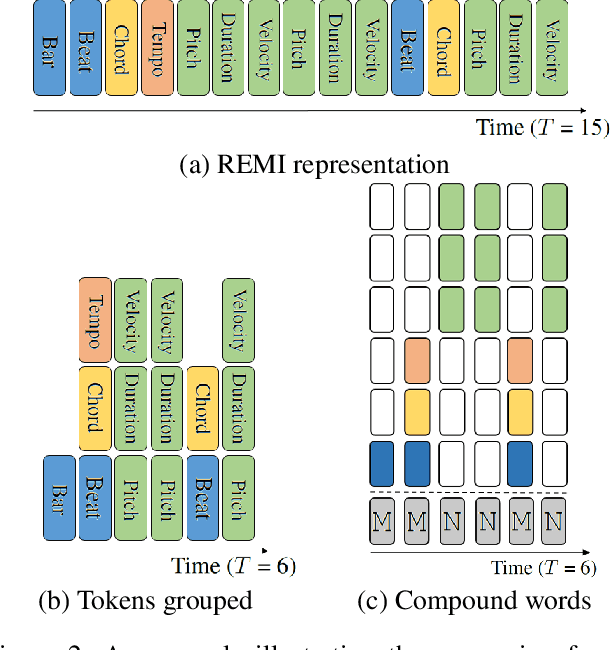

To apply neural sequence models such as the Transformers to music generation tasks, one has to represent a piece of music by a sequence of tokens drawn from a finite set of pre-defined vocabulary. Such a vocabulary usually involves tokens of various types. For example, to describe a musical note, one needs separate tokens to indicate the note's pitch, duration, velocity (dynamics), and placement (onset time) along the time grid. While different types of tokens may possess different properties, existing models usually treat them equally, in the same way as modeling words in natural languages. In this paper, we present a conceptually different approach that explicitly takes into account the type of the tokens, such as note types and metric types. And, we propose a new Transformer decoder architecture that uses different feed-forward heads to model tokens of different types. With an expansion-compression trick, we convert a piece of music to a sequence of compound words by grouping neighboring tokens, greatly reducing the length of the token sequences. We show that the resulting model can be viewed as a learner over dynamic directed hypergraphs. And, we employ it to learn to compose expressive Pop piano music of full-song length (involving up to 10K individual tokens per song), both conditionally and unconditionally. Our experiment shows that, compared to state-of-the-art models, the proposed model converges 5--10 times faster at training (i.e., within a day on a single GPU with 11 GB memory), and with comparable quality in the generated music.
Foley Music: Learning to Generate Music from Videos
Jul 21, 2020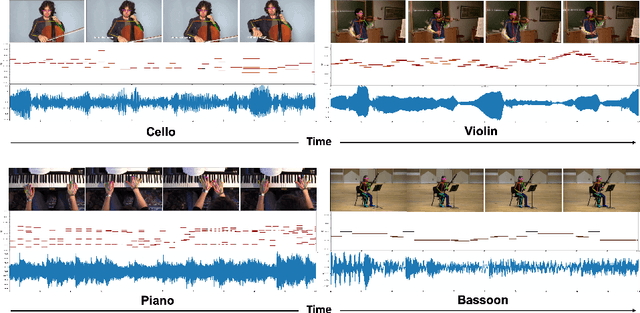
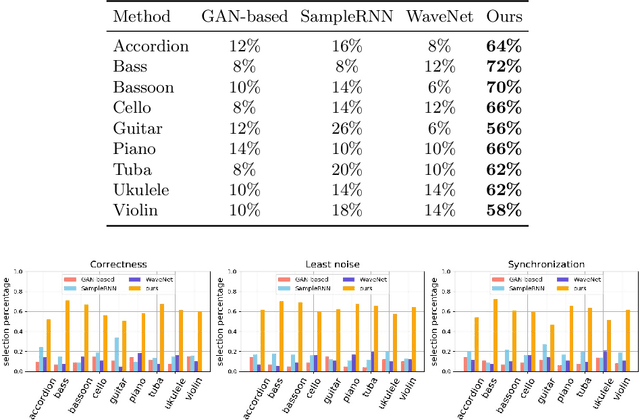
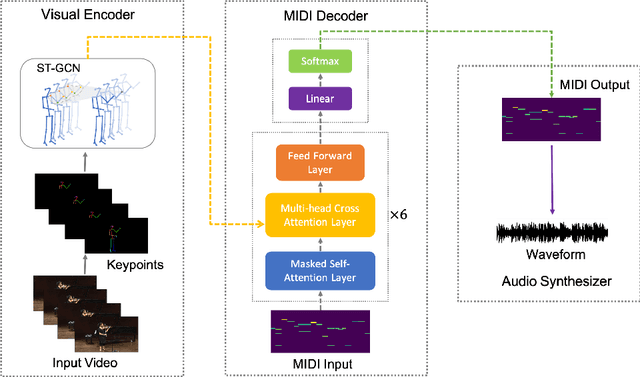

In this paper, we introduce Foley Music, a system that can synthesize plausible music for a silent video clip about people playing musical instruments. We first identify two key intermediate representations for a successful video to music generator: body keypoints from videos and MIDI events from audio recordings. We then formulate music generation from videos as a motion-to-MIDI translation problem. We present a Graph$-$Transformer framework that can accurately predict MIDI event sequences in accordance with the body movements. The MIDI event can then be converted to realistic music using an off-the-shelf music synthesizer tool. We demonstrate the effectiveness of our models on videos containing a variety of music performances. Experimental results show that our model outperforms several existing systems in generating music that is pleasant to listen to. More importantly, the MIDI representations are fully interpretable and transparent, thus enabling us to perform music editing flexibly. We encourage the readers to watch the demo video with audio turned on to experience the results.
Multi-instrument Music Synthesis with Spectrogram Diffusion
Jun 11, 2022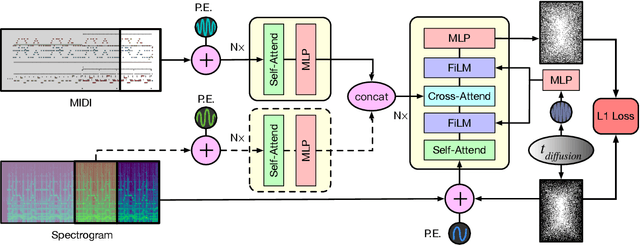
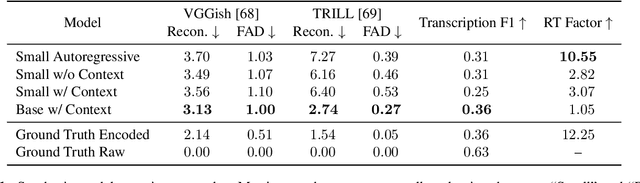

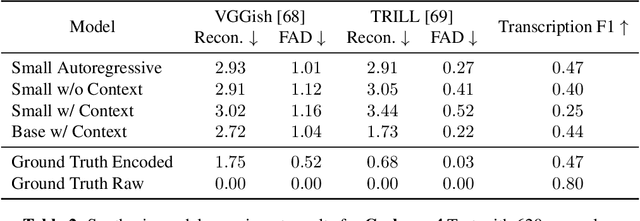
An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on all of music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fr\'echet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
Adaptive Music Composition for Games
Jul 02, 2019
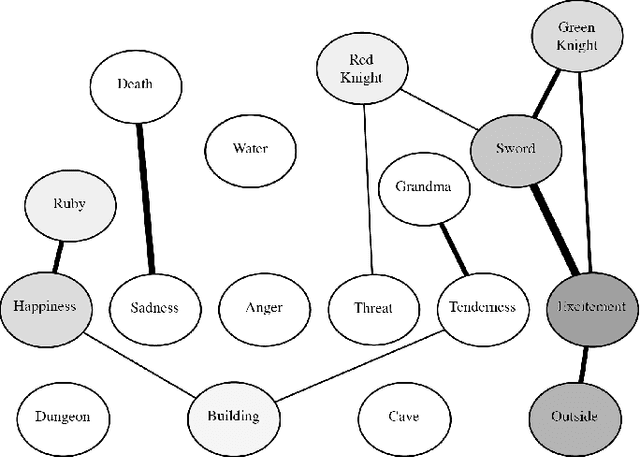
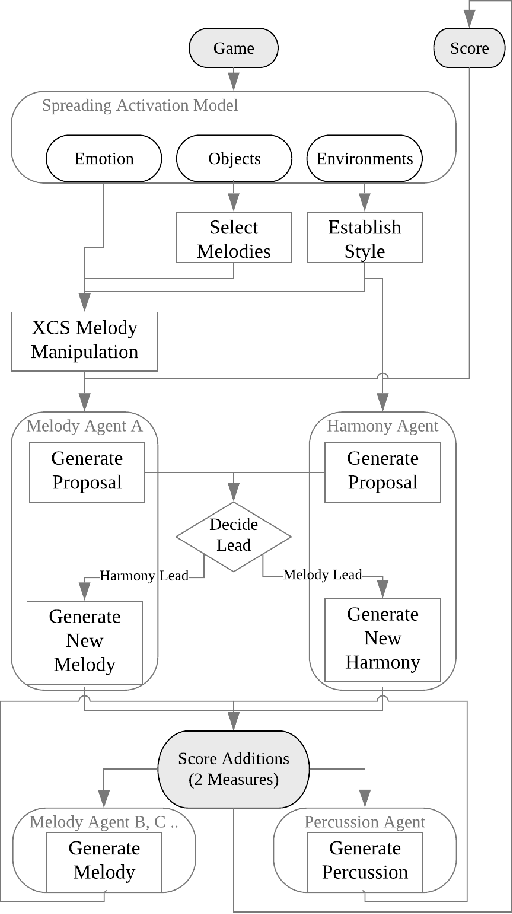
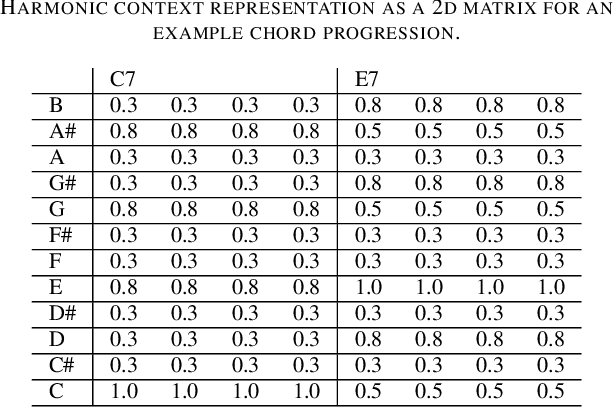
The generation of music that adapts dynamically to content and actions has an important role in building more immersive, memorable and emotive game experiences. To date, the development of adaptive music systems for video games is limited by both the nature of algorithms used for real-time music generation and the limited modelling of player action, game world context and emotion in current games. We propose that these issues must be addressed in tandem for the quality and flexibility of adaptive game music to significantly improve. Cognitive models of knowledge organisation and emotional affect are integrated with multi-modal, multi-agent composition techniques to produce a novel Adaptive Music System (AMS). The system is integrated into two stylistically distinct games. Gamers reported an overall higher immersion and correlation of music with game-world concepts with the AMS than with the original game soundtracks in both games.
LakhNES: Improving multi-instrumental music generation with cross-domain pre-training
Jul 10, 2019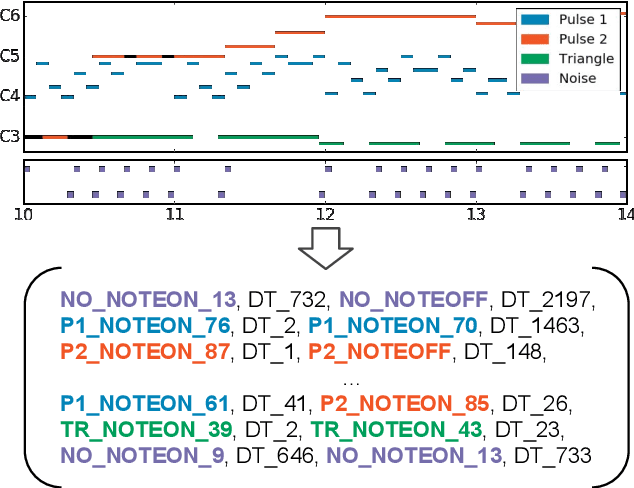
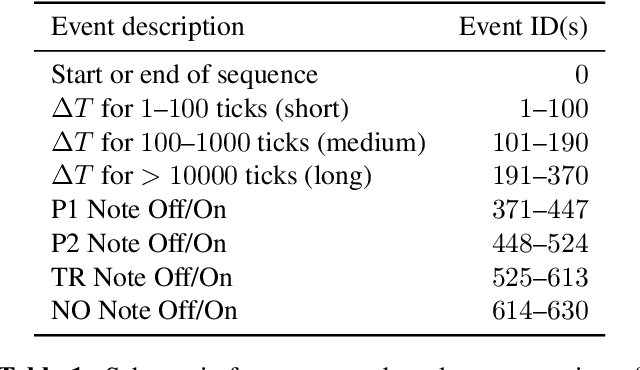
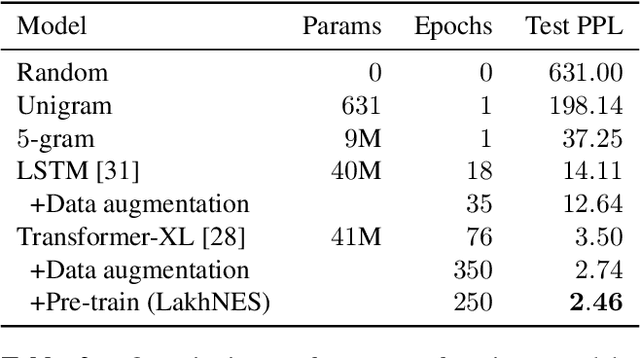
We are interested in the task of generating multi-instrumental music scores. The Transformer architecture has recently shown great promise for the task of piano score generation; here we adapt it to the multi-instrumental setting. Transformers are complex, high-dimensional language models which are capable of capturing long-term structure in sequence data, but require large amounts of data to fit. Their success on piano score generation is partially explained by the large volumes of symbolic data readily available for that domain. We leverage the recently-introduced NES-MDB dataset of four-instrument scores from an early video game sound synthesis chip (the NES), which we find to be well-suited to training with the Transformer architecture. To further improve the performance of our model, we propose a pre-training technique to leverage the information in a large collection of heterogeneous music, namely the Lakh MIDI dataset. Despite differences between the two corpora, we find that this transfer learning procedure improves both quantitative and qualitative performance for our primary task.
Dance Revolution: Long Sequence Dance Generation with Music via Curriculum Learning
Jun 14, 2020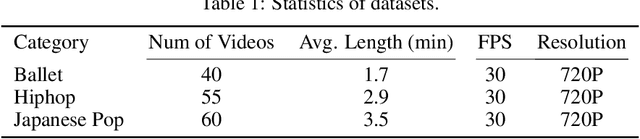
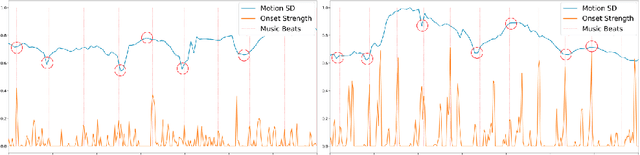

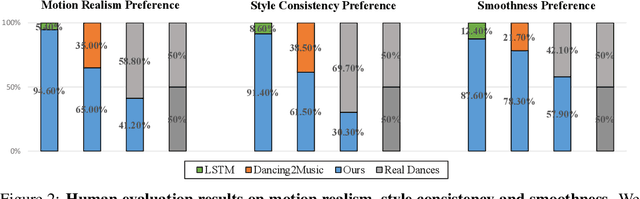
Dancing to music is one of human's innate abilities since ancient times. In artificial intelligence research, however, synthesizing dance movements (complex human motion) from music is a challenging problem, which suffers from the high spatial-temporal complexity in human motion dynamics modeling. Besides, the consistency of dance and music in terms of style, rhythm and beat also needs to be taken into account. Existing works focus on the short-term dance generation with music, e.g. less than 30 seconds. In this paper, we propose a novel seq2seq architecture for long sequence dance generation with music, which consists of a transformer based music encoder and a recurrent structure based dance decoder. By restricting the receptive field of self-attention, our encoder can efficiently process long musical sequences by reducing its quadratic memory requirements to the linear in the sequence length. To further alleviate the error accumulation in human motion synthesis, we introduce a dynamic auto-condition training strategy as a new curriculum learning method to facilitate the long-term dance generation. Extensive experiments demonstrate that our proposed approach significantly outperforms existing methods on both automatic metrics and human evaluation. Additionally, we also make a demo video to exhibit that our approach can generate minute-length dance sequences that are smooth, natural-looking, diverse, style-consistent and beat-matching with the music. The demo video is now available at https://www.youtube.com/watch?v=P6yhfv3vpDI.
DanceNet3D: Music Based Dance Generation with Parametric Motion Transformer
Mar 25, 2021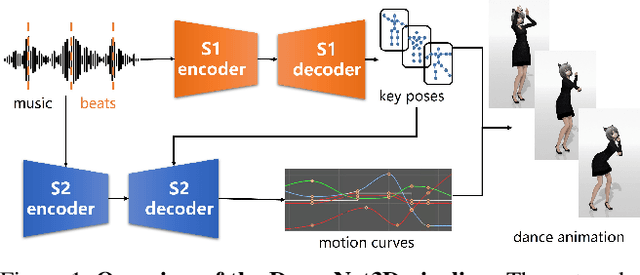

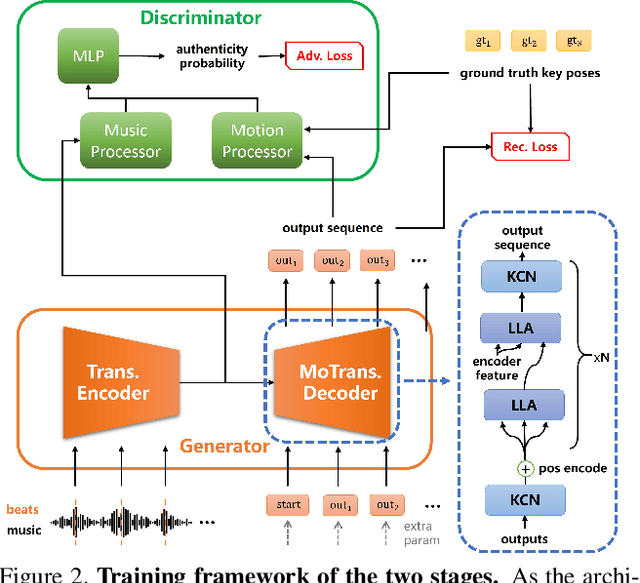
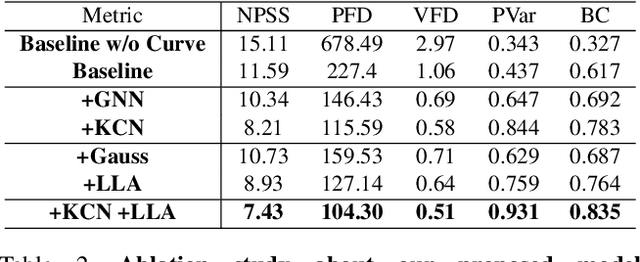
In this work, we propose a novel deep learning framework that can generate a vivid dance from a whole piece of music. In contrast to previous works that define the problem as generation of frames of motion state parameters, we formulate the task as a prediction of motion curves between key poses, which is inspired by the animation industry practice. The proposed framework, named DanceNet3D, first generates key poses on beats of the given music and then predicts the in-between motion curves. DanceNet3D adopts the encoder-decoder architecture and the adversarial schemes for training. The decoders in DanceNet3D are constructed on MoTrans, a transformer tailored for motion generation. In MoTrans we introduce the kinematic correlation by the Kinematic Chain Networks, and we also propose the Learned Local Attention module to take the temporal local correlation of human motion into consideration. Furthermore, we propose PhantomDance, the first large-scale dance dataset produced by professional animatiors, with accurate synchronization with music. Extensive experiments demonstrate that the proposed approach can generate fluent, elegant, performative and beat-synchronized 3D dances, which significantly surpasses previous works quantitatively and qualitatively.
Learn to Dance with AIST++: Music Conditioned 3D Dance Generation
Feb 02, 2021

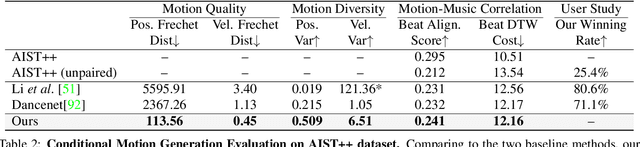

In this paper, we present a transformer-based learning framework for 3D dance generation conditioned on music. We carefully design our network architecture and empirically study the keys for obtaining qualitatively pleasing results. The critical components include a deep cross-modal transformer, which well learns the correlation between the music and dance motion; and the full-attention with future-N supervision mechanism which is essential in producing long-range non-freezing motion. In addition, we propose a new dataset of paired 3D motion and music called AIST++, which we reconstruct from the AIST multi-view dance videos. This dataset contains 1.1M frames of 3D dance motion in 1408 sequences, covering 10 genres of dance choreographies and accompanied with multi-view camera parameters. To our knowledge it is the largest dataset of this kind. Rich experiments on AIST++ demonstrate our method produces much better results than the state-of-the-art methods both qualitatively and quantitatively.