 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Modeling Baroque Two-Part Counterpoint with Neural Machine Translation
Jun 25, 2020
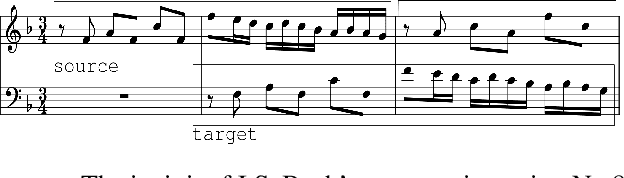
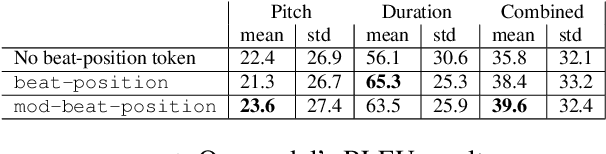
We propose a system for contrapuntal music generation based on a Neural Machine Translation (NMT) paradigm. We consider Baroque counterpoint and are interested in modeling the interaction between any two given parts as a mapping between a given source material and an appropriate target material. Like in translation, the former imposes some constraints on the latter, but doesn't define it completely. We collate and edit a bespoke dataset of Baroque pieces, use it to train an attention-based neural network model, and evaluate the generated output via BLEU score and musicological analysis. We show that our model is able to respond with some idiomatic trademarks, such as imitation and appropriate rhythmic offset, although it falls short of having learned stylistically correct contrapuntal motion (e.g., avoidance of parallel fifths) or stricter imitative rules, such as canon.
Conditioning Deep Generative Raw Audio Models for Structured Automatic Music
Jun 26, 2018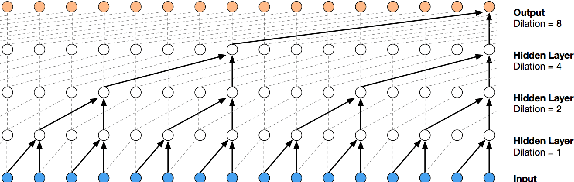
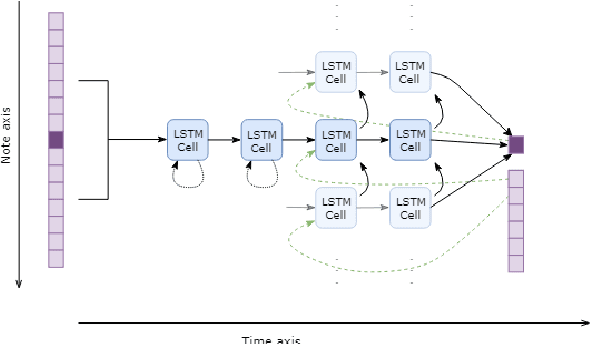
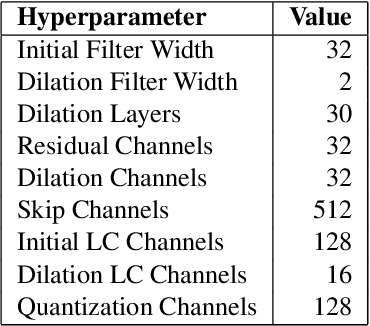
Existing automatic music generation approaches that feature deep learning can be broadly classified into two types: raw audio models and symbolic models. Symbolic models, which train and generate at the note level, are currently the more prevalent approach; these models can capture long-range dependencies of melodic structure, but fail to grasp the nuances and richness of raw audio generations. Raw audio models, such as DeepMind's WaveNet, train directly on sampled audio waveforms, allowing them to produce realistic-sounding, albeit unstructured music. In this paper, we propose an automatic music generation methodology combining both of these approaches to create structured, realistic-sounding compositions. We consider a Long Short Term Memory network to learn the melodic structure of different styles of music, and then use the unique symbolic generations from this model as a conditioning input to a WaveNet-based raw audio generator, creating a model for automatic, novel music. We then evaluate this approach by showcasing results of this work.
ReLyMe: Improving Lyric-to-Melody Generation by Incorporating Lyric-Melody Relationships
Jul 12, 2022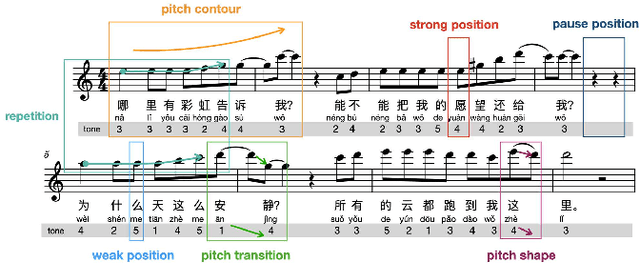
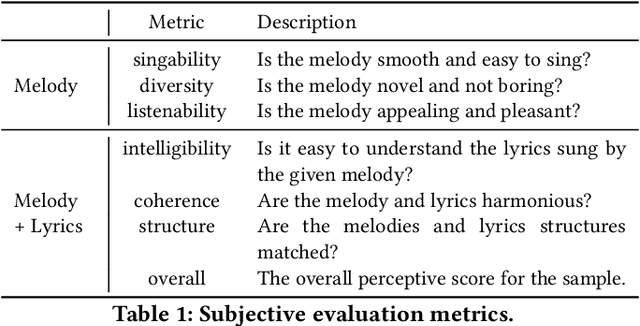
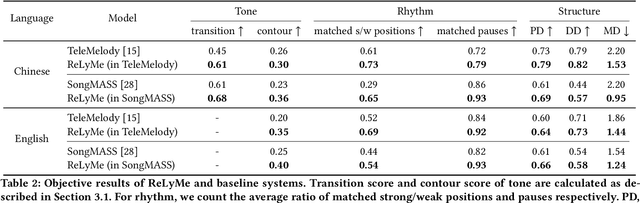
Lyric-to-melody generation, which generates melody according to given lyrics, is one of the most important automatic music composition tasks. With the rapid development of deep learning, previous works address this task with end-to-end neural network models. However, deep learning models cannot well capture the strict but subtle relationships between lyrics and melodies, which compromises the harmony between lyrics and generated melodies. In this paper, we propose ReLyMe, a method that incorporates Relationships between Lyrics and Melodies from music theory to ensure the harmony between lyrics and melodies. Specifically, we first introduce several principles that lyrics and melodies should follow in terms of tone, rhythm, and structure relationships. These principles are then integrated into neural network lyric-to-melody models by adding corresponding constraints during the decoding process to improve the harmony between lyrics and melodies. We use a series of objective and subjective metrics to evaluate the generated melodies. Experiments on both English and Chinese song datasets show the effectiveness of ReLyMe, demonstrating the superiority of incorporating lyric-melody relationships from the music domain into neural lyric-to-melody generation.
NONOTO: A Model-agnostic Web Interface for Interactive Music Composition by Inpainting
Jul 23, 2019
Inpainting-based generative modeling allows for stimulating human-machine interactions by letting users perform stylistically coherent local editions to an object using a statistical model. We present NONOTO, a new interface for interactive music generation based on inpainting models. It is aimed both at researchers, by offering a simple and flexible API allowing them to connect their own models with the interface, and at musicians by providing industry-standard features such as audio playback, real-time MIDI output and straightforward synchronization with DAWs using Ableton Link.
Music Playlist Title Generation: A Machine-Translation Approach
Oct 03, 2021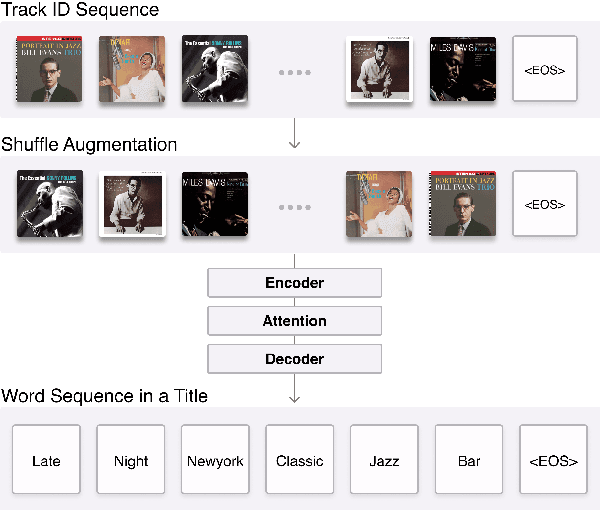
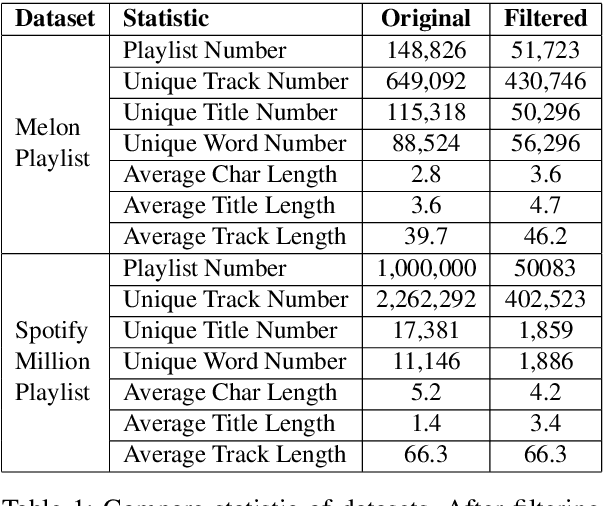
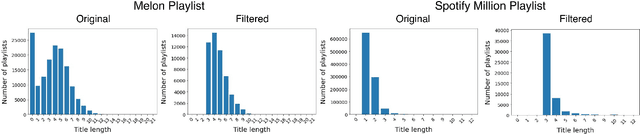
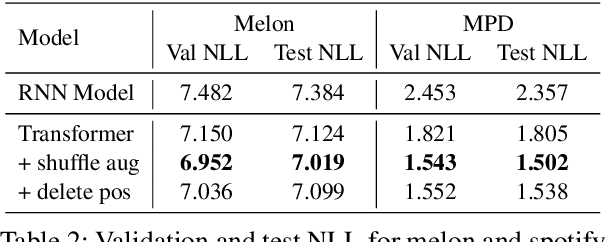
We propose a machine-translation approach to automatically generate a playlist title from a set of music tracks. We take a sequence of track IDs as input and a sequence of words in a playlist title as output, adapting the sequence-to-sequence framework based on Recurrent Neural Network (RNN) and Transformer to the music data. Considering the orderless nature of music tracks in a playlist, we propose two techniques that remove the order of the input sequence. One is data augmentation by shuffling and the other is deleting the positional encoding. We also reorganize the existing music playlist datasets to generate phrase-level playlist titles. The result shows that the Transformer models generally outperform the RNN model. Also, removing the order of input sequence improves the performance further.
Interpretable Melody Generation from Lyrics with Discrete-Valued Adversarial Training
Jun 30, 2022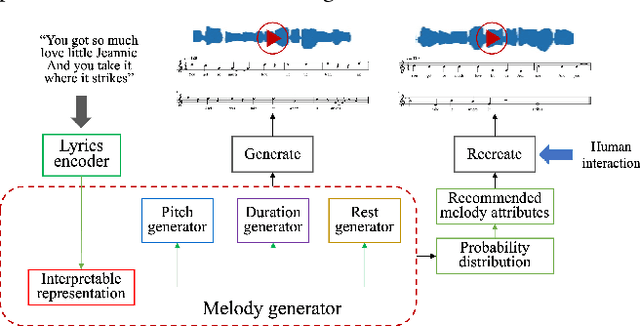
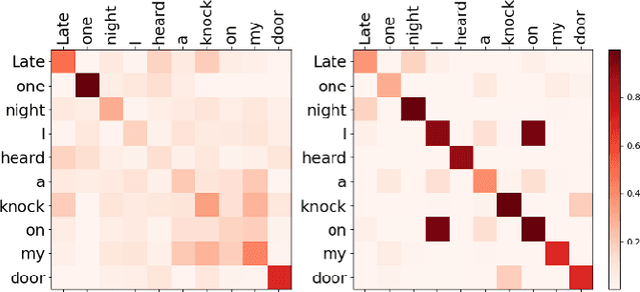

Generating melody from lyrics is an interesting yet challenging task in the area of artificial intelligence and music. However, the difficulty of keeping the consistency between input lyrics and generated melody limits the generation quality of previous works. In our proposal, we demonstrate our proposed interpretable lyrics-to-melody generation system which can interact with users to understand the generation process and recreate the desired songs. To improve the reliability of melody generation that matches lyrics, mutual information is exploited to strengthen the consistency between lyrics and generated melodies. Gumbel-Softmax is exploited to solve the non-differentiability problem of generating discrete music attributes by Generative Adversarial Networks (GANs). Moreover, the predicted probabilities output by the generator is utilized to recommend music attributes. Interacting with our lyrics-to-melody generation system, users can listen to the generated AI song as well as recreate a new song by selecting from recommended music attributes.
Towards democratizing music production with AI-Design of Variational Autoencoder-based Rhythm Generator as a DAW plugin
Apr 01, 2020
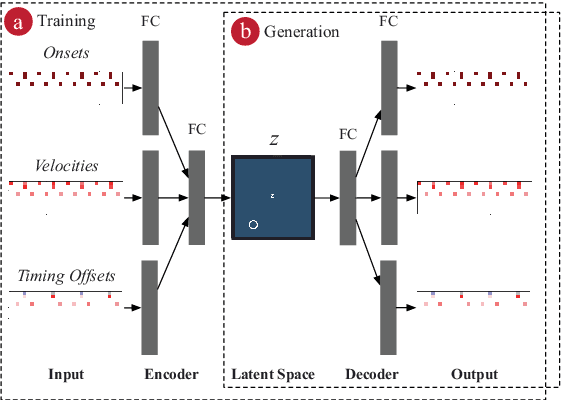
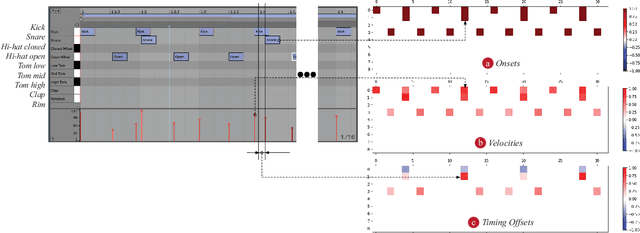
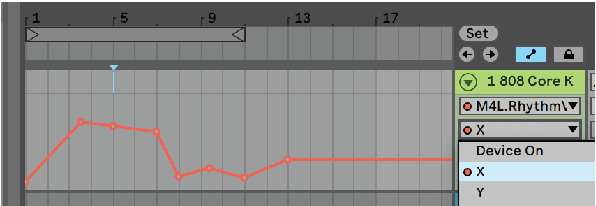
There has been significant progress in the music generation technique utilizing deep learning. However, it is still hard for musicians and artists to use these techniques in their daily music-making practice. This paper proposes a Variational Autoencoder\cite{Kingma2014}(VAE)-based rhythm generation system, in which musicians can train a deep learning model only by selecting target MIDI files, then generate various rhythms with the model. The author has implemented the system as a plugin software for a DAW (Digital Audio Workstation), namely a Max for Live device for Ableton Live. Selected professional/semi-professional musicians and music producers have used the plugin, and they proved that the plugin is a useful tool for making music creatively. The plugin, source code, and demo videos are available online.
Learning long-term music representations via hierarchical contextual constraints
Feb 13, 2022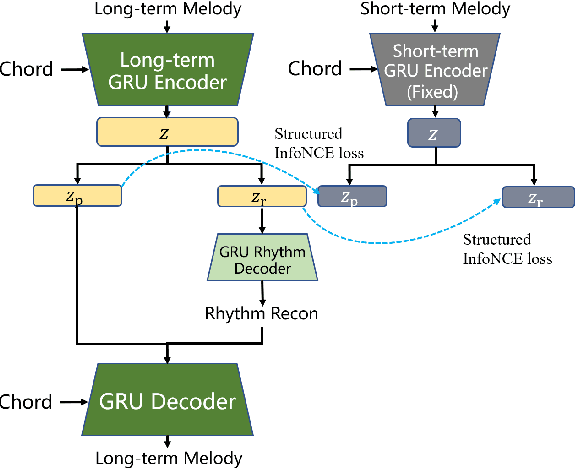
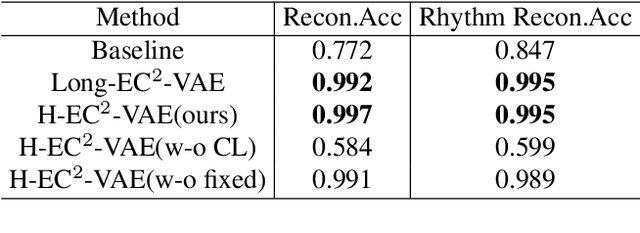
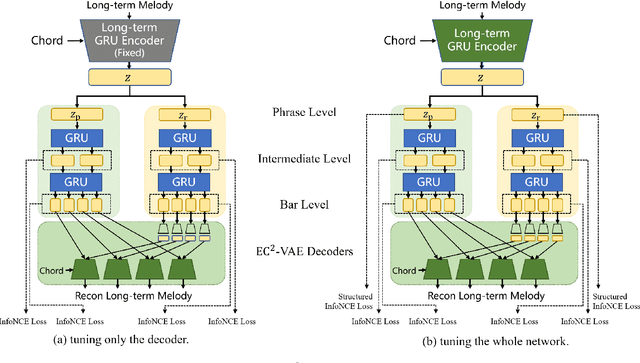
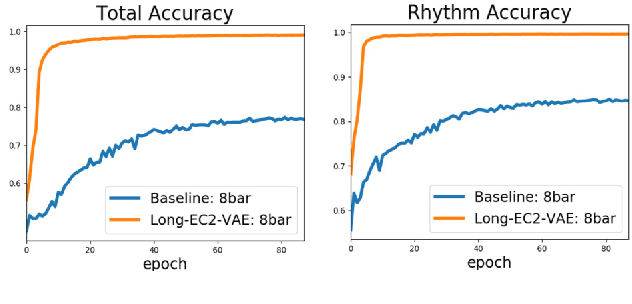
Learning symbolic music representations, especially disentangled representations with probabilistic interpretations, has been shown to benefit both music understanding and generation. However, most models are only applicable to short-term music, while learning long-term music representations remains a challenging task. We have seen several studies attempting to learn hierarchical representations directly in an end-to-end manner, but these models have not been able to achieve the desired results and the training process is not stable. In this paper, we propose a novel approach to learn long-term symbolic music representations through contextual constraints. First, we use contrastive learning to pre-train a long-term representation by constraining its difference from the short-term representation (extracted by an off-the-shelf model). Then, we fine-tune the long-term representation by a hierarchical prediction model such that a good long-term representation (e.g., an 8-bar representation) can reconstruct the corresponding short-term ones (e.g., the 2-bar representations within the 8-bar range). Experiments show that our method stabilizes the training and the fine-tuning steps. In addition, the designed contextual constraints benefit both reconstruction and disentanglement, significantly outperforming the baselines.
Inspecting and Interacting with Meaningful Music Representations using VAE
Apr 18, 2019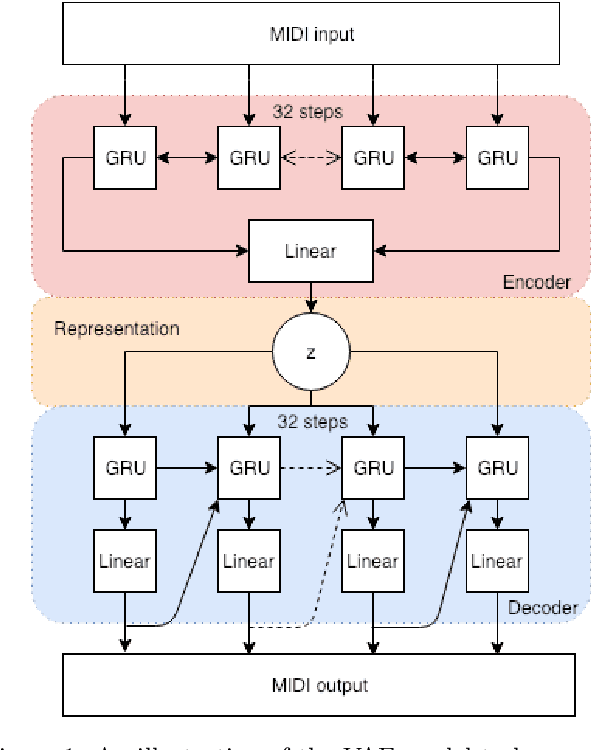
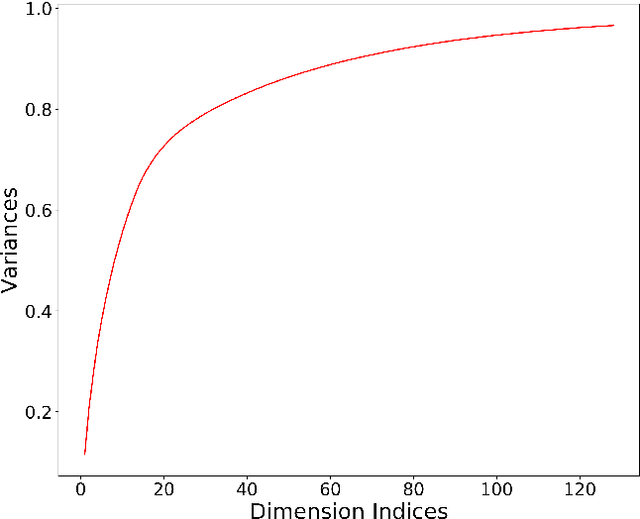
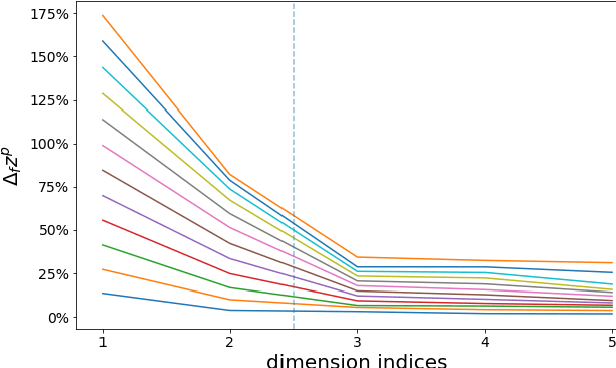
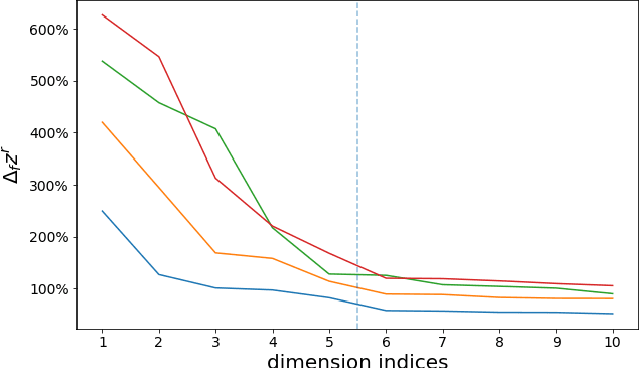
Variational Autoencoders(VAEs) have already achieved great results on image generation and recently made promising progress on music generation. However, the generation process is still quite difficult to control in the sense that the learned latent representations lack meaningful music semantics. It would be much more useful if people can modify certain music features, such as rhythm and pitch contour, via latent representations to test different composition ideas. In this paper, we propose a new method to inspect the pitch and rhythm interpretations of the latent representations and we name it disentanglement by augmentation. Based on the interpretable representations, an intuitive graphical user interface is designed for users to better direct the music creation process by manipulating the pitch contours and rhythmic complexity.
Music FaderNets: Controllable Music Generation Based On High-Level Features via Low-Level Feature Modelling
Jul 29, 2020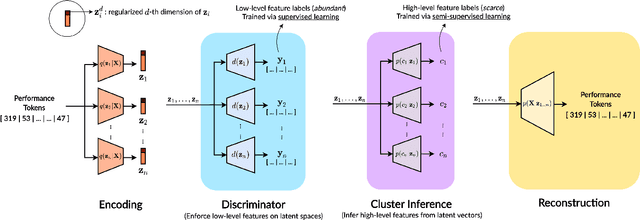
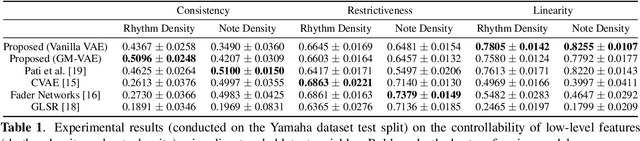
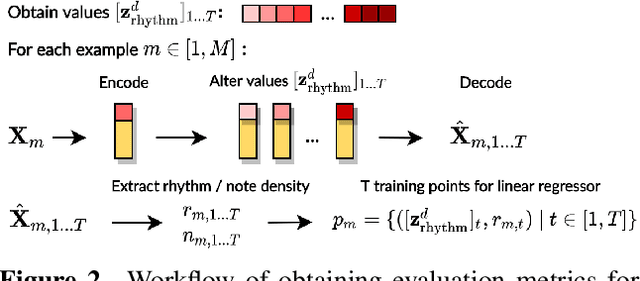
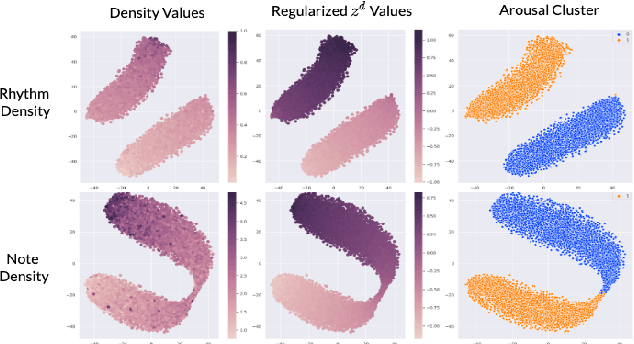
High-level musical qualities (such as emotion) are often abstract, subjective, and hard to quantify. Given these difficulties, it is not easy to learn good feature representations with supervised learning techniques, either because of the insufficiency of labels, or the subjectiveness (and hence large variance) in human-annotated labels. In this paper, we present a framework that can learn high-level feature representations with a limited amount of data, by first modelling their corresponding quantifiable low-level attributes. We refer to our proposed framework as Music FaderNets, which is inspired by the fact that low-level attributes can be continuously manipulated by separate "sliding faders" through feature disentanglement and latent regularization techniques. High-level features are then inferred from the low-level representations through semi-supervised clustering using Gaussian Mixture Variational Autoencoders (GM-VAEs). Using arousal as an example of a high-level feature, we show that the "faders" of our model are disentangled and change linearly w.r.t. the modelled low-level attributes of the generated output music. Furthermore, we demonstrate that the model successfully learns the intrinsic relationship between arousal and its corresponding low-level attributes (rhythm and note density), with only 1% of the training set being labelled. Finally, using the learnt high-level feature representations, we explore the application of our framework in style transfer tasks across different arousal states. The effectiveness of this approach is verified through a subjective listening test.