 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
PIANOTREE VAE: Structured Representation Learning for Polyphonic Music
Aug 17, 2020

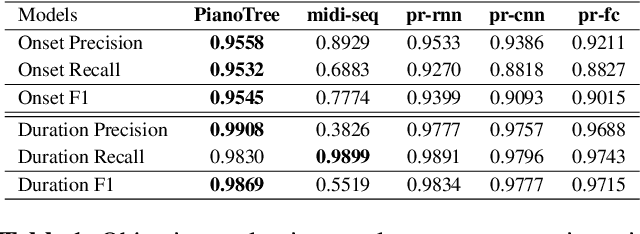
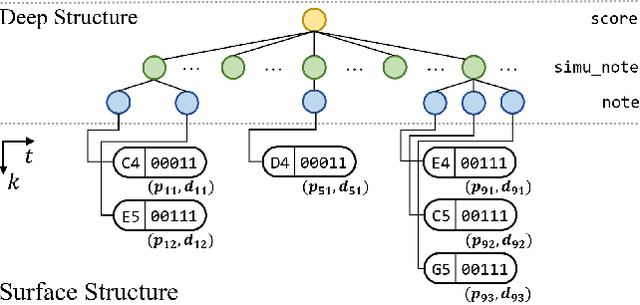
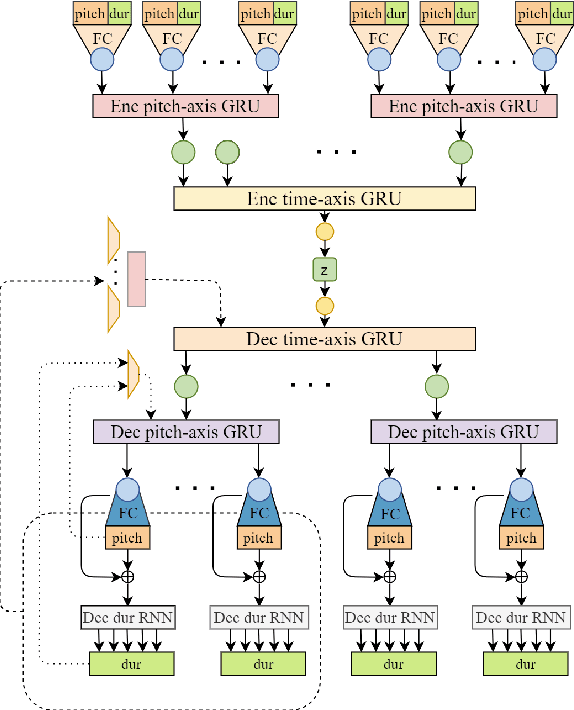
The dominant approach for music representation learning involves the deep unsupervised model family variational autoencoder (VAE). However, most, if not all, viable attempts on this problem have largely been limited to monophonic music. Normally composed of richer modality and more complex musical structures, the polyphonic counterpart has yet to be addressed in the context of music representation learning. In this work, we propose the PianoTree VAE, a novel tree-structure extension upon VAE aiming to fit the polyphonic music learning. The experiments prove the validity of the PianoTree VAE via (i)-semantically meaningful latent code for polyphonic segments; (ii)-more satisfiable reconstruction aside of decent geometry learned in the latent space; (iii)-this model's benefits to the variety of the downstream music generation.
Hallmarks of Human-Machine Collaboration: A framework for assessment in the DARPA Communicating with Computers Program
Feb 09, 2021



There is a growing desire to create computer systems that can communicate effectively to collaborate with humans on complex, open-ended activities. Assessing these systems presents significant challenges. We describe a framework for evaluating systems engaged in open-ended complex scenarios where evaluators do not have the luxury of comparing performance to a single right answer. This framework has been used to evaluate human-machine creative collaborations across story and music generation, interactive block building, and exploration of molecular mechanisms in cancer. These activities are fundamentally different from the more constrained tasks performed by most contemporary personal assistants as they are generally open-ended, with no single correct solution, and often no obvious completion criteria. We identified the Key Properties that must be exhibited by successful systems. From there we identified "Hallmarks" of success -- capabilities and features that evaluators can observe that would be indicative of progress toward achieving a Key Property. In addition to being a framework for assessment, the Key Properties and Hallmarks are intended to serve as goals in guiding research direction.
Hierarchical Timbre-Painting and Articulation Generation
Sep 07, 2020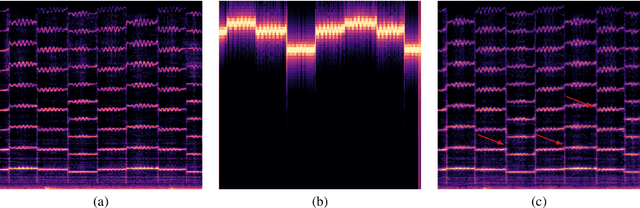
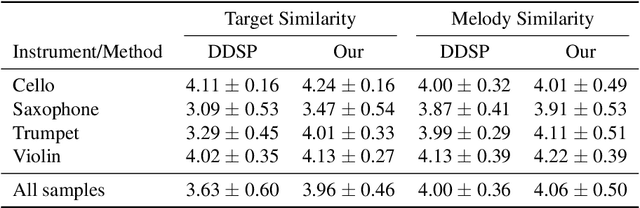
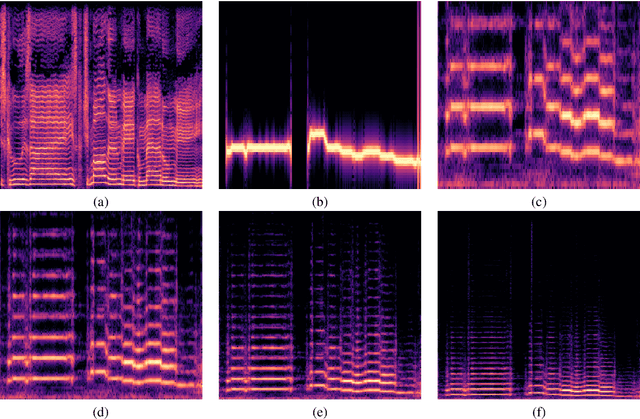
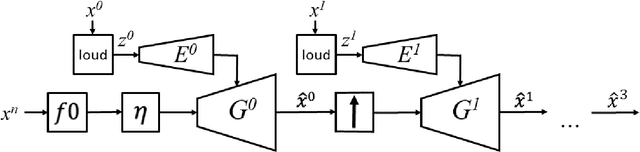
We present a fast and high-fidelity method for music generation, based on specified f0 and loudness, such that the synthesized audio mimics the timbre and articulation of a target instrument. The generation process consists of learned source-filtering networks, which reconstruct the signal at increasing resolutions. The model optimizes a multi-resolution spectral loss as the reconstruction loss, an adversarial loss to make the audio sound more realistic, and a perceptual f0 loss to align the output to the desired input pitch contour. The proposed architecture enables high-quality fitting of an instrument, given a sample that can be as short as a few minutes, and the method demonstrates state-of-the-art timbre transfer capabilities. Code and audio samples are shared at https://github.com/mosheman5/timbre_painting.
Towards Game Design via Creative Machine Learning (GDCML)
Jul 25, 2020



In recent years, machine learning (ML) systems have been increasingly applied for performing creative tasks. Such creative ML approaches have seen wide use in the domains of visual art and music for applications such as image and music generation and style transfer. However, similar creative ML techniques have not been as widely adopted in the domain of game design despite the emergence of ML-based methods for generating game content. In this paper, we argue for leveraging and repurposing such creative techniques for designing content for games, referring to these as approaches for Game Design via Creative ML (GDCML). We highlight existing systems that enable GDCML and illustrate how creative ML can inform new systems via example applications and a proposed system.
CycleDRUMS: Automatic Drum Arrangement For Bass Lines Using CycleGAN
Apr 09, 2021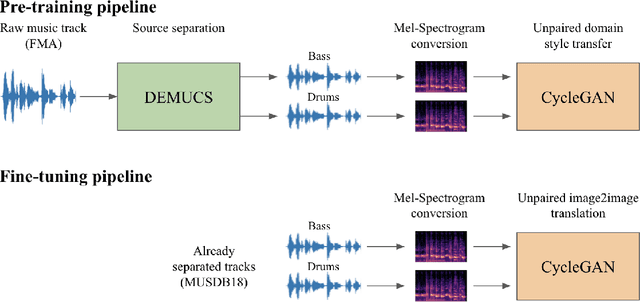
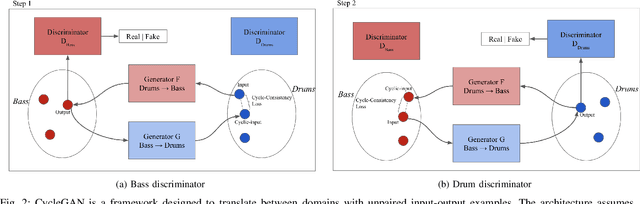
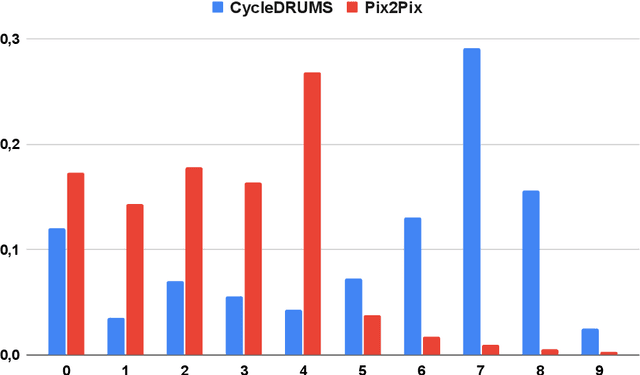
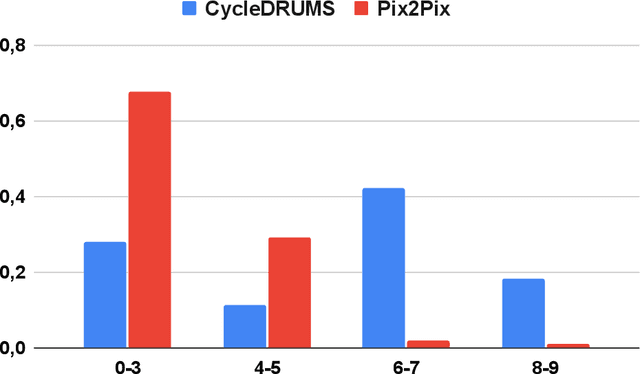
The two main research threads in computer-based music generation are: the construction of autonomous music-making systems, and the design of computer-based environments to assist musicians. In the symbolic domain, the key problem of automatically arranging a piece music was extensively studied, while relatively fewer systems tackled this challenge in the audio domain. In this contribution, we propose CycleDRUMS, a novel method for generating drums given a bass line. After converting the waveform of the bass into a mel-spectrogram, we are able to automatically generate original drums that follow the beat, sound credible and can be directly mixed with the input bass. We formulated this task as an unpaired image-to-image translation problem, and we addressed it with CycleGAN, a well-established unsupervised style transfer framework, originally designed for treating images. The choice to deploy raw audio and mel-spectrograms enabled us to better represent how humans perceive music, and to potentially draw sounds for new arrangements from the vast collection of music recordings accumulated in the last century. In absence of an objective way of evaluating the output of both generative adversarial networks and music generative systems, we further defined a possible metric for the proposed task, partially based on human (and expert) judgement. Finally, as a comparison, we replicated our results with Pix2Pix, a paired image-to-image translation network, and we showed that our approach outperforms it.
Generating Lead Sheets with Affect: A Novel Conditional seq2seq Framework
Apr 27, 2021
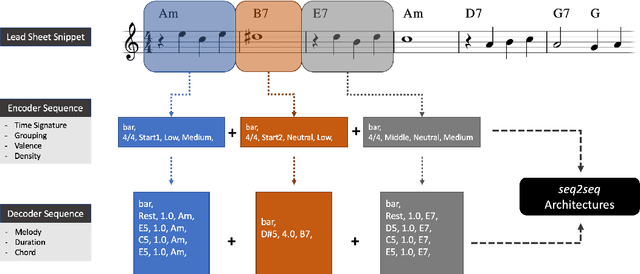
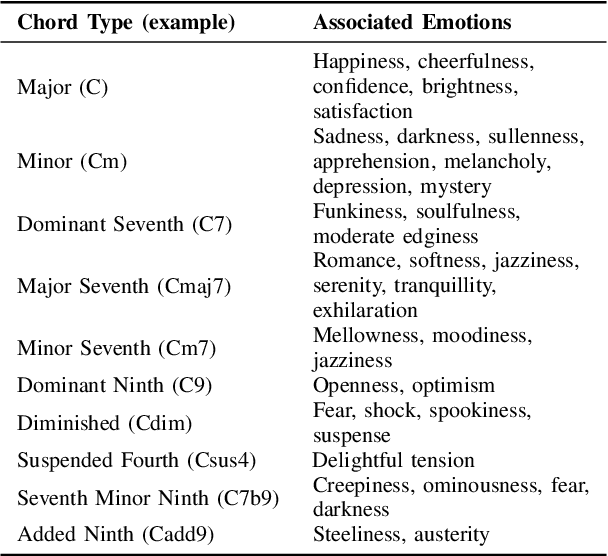
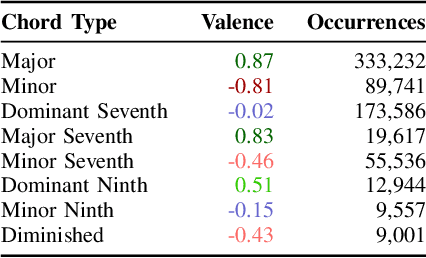
The field of automatic music composition has seen great progress in the last few years, much of which can be attributed to advances in deep neural networks. There are numerous studies that present different strategies for generating sheet music from scratch. The inclusion of high-level musical characteristics (e.g., perceived emotional qualities), however, as conditions for controlling the generation output remains a challenge. In this paper, we present a novel approach for calculating the valence (the positivity or negativity of the perceived emotion) of a chord progression within a lead sheet, using pre-defined mood tags proposed by music experts. Based on this approach, we propose a novel strategy for conditional lead sheet generation that allows us to steer the music generation in terms of valence, phrasing, and time signature. Our approach is similar to a Neural Machine Translation (NMT) problem, as we include high-level conditions in the encoder part of the sequence-to-sequence architectures used (i.e., long-short term memory networks, and a Transformer network). We conducted experiments to thoroughly analyze these two architectures. The results show that the proposed strategy is able to generate lead sheets in a controllable manner, resulting in distributions of musical attributes similar to those of the training dataset. We also verified through a subjective listening test that our approach is effective in controlling the valence of a generated chord progression.
Progressive Generative Adversarial Binary Networks for Music Generation
Mar 12, 2019
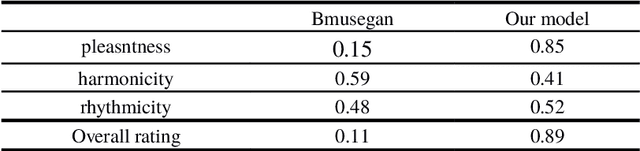
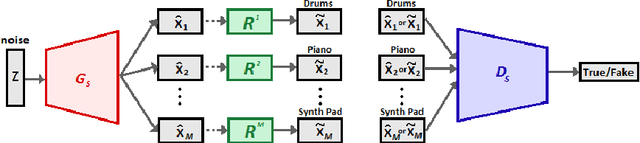

Recent improvements in generative adversarial network (GAN) training techniques prove that progressively training a GAN drastically stabilizes the training and improves the quality of outputs produced. Adding layers after the previous ones have converged has proven to help in better overall convergence and stability of the model as well as reducing the training time by a sufficient amount. Thus we use this training technique to train the model progressively in the time and pitch domain i.e. starting from a very small time value and pitch range we gradually expand the matrix sizes until the end result is a completely trained model giving outputs having tensor sizes [4 (bar) x 96 (time steps) x 84 (pitch values) x 8 (tracks)]. As proven in previously proposed models deterministic binary neurons also help in improving the results. Thus we make use of a layer of deterministic binary neurons at the end of the generator to get binary valued outputs instead of fractional values existing between 0 and 1.
Modeling Baroque Two-Part Counterpoint with Neural Machine Translation
Jun 29, 2020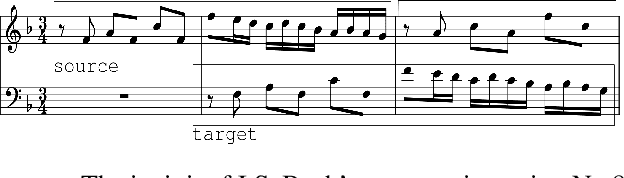
We propose a system for contrapuntal music generation based on a Neural Machine Translation (NMT) paradigm. We consider Baroque counterpoint and are interested in modeling the interaction between any two given parts as a mapping between a given source material and an appropriate target material. Like in translation, the former imposes some constraints on the latter, but doesn't define it completely. We collate and edit a bespoke dataset of Baroque pieces, use it to train an attention-based neural network model, and evaluate the generated output via BLEU score and musicological analysis. We show that our model is able to respond with some idiomatic trademarks, such as imitation and appropriate rhythmic offset, although it falls short of having learned stylistically correct contrapuntal motion (e.g., avoidance of parallel fifths) or stricter imitative rules, such as canon.