 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
High-Level Control of Drum Track Generation Using Learned Patterns of Rhythmic Interaction
Aug 02, 2019
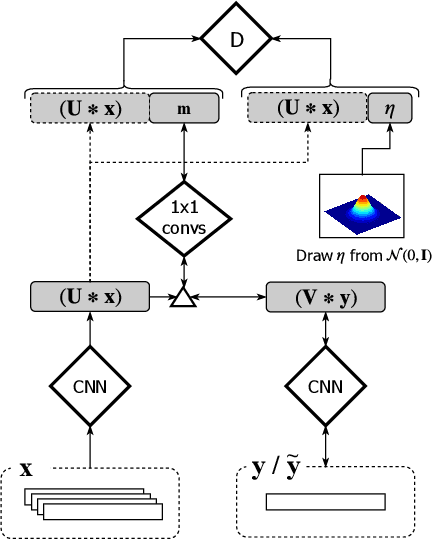


Spurred by the potential of deep learning, computational music generation has gained renewed academic interest. A crucial issue in music generation is that of user control, especially in scenarios where the music generation process is conditioned on existing musical material. Here we propose a model for conditional kick drum track generation that takes existing musical material as input, in addition to a low-dimensional code that encodes the desired relation between the existing material and the new material to be generated. These relational codes are learned in an unsupervised manner from a music dataset. We show that codes can be sampled to create a variety of musically plausible kick drum tracks and that the model can be used to transfer kick drum patterns from one song to another. Lastly, we demonstrate that the learned codes are largely invariant to tempo and time-shift.
Flat latent manifolds for music improvisation between human and machine
Feb 23, 2022
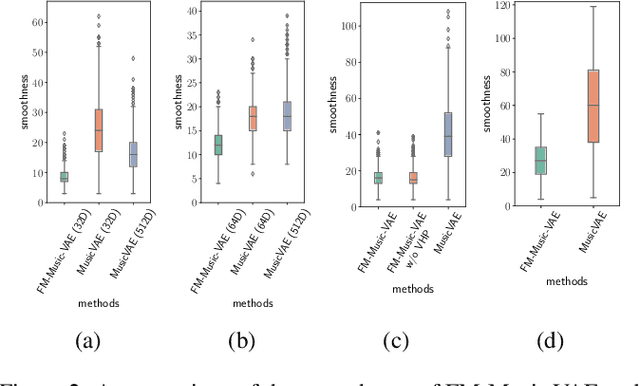
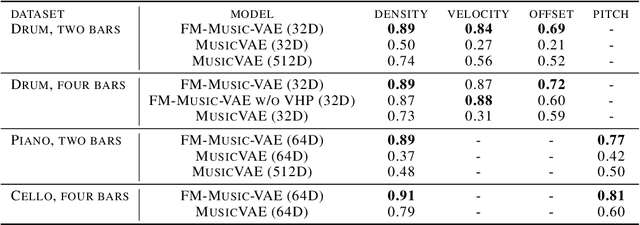
The use of machine learning in artistic music generation leads to controversial discussions of the quality of art, for which objective quantification is nonsensical. We therefore consider a music-generating algorithm as a counterpart to a human musician, in a setting where reciprocal improvisation is to lead to new experiences, both for the musician and the audience. To obtain this behaviour, we resort to the framework of recurrent Variational Auto-Encoders (VAE) and learn to generate music, seeded by a human musician. In the learned model, we generate novel musical sequences by interpolation in latent space. Standard VAEs however do not guarantee any form of smoothness in their latent representation. This translates into abrupt changes in the generated music sequences. To overcome these limitations, we regularise the decoder and endow the latent space with a flat Riemannian manifold, i.e., a manifold that is isometric to the Euclidean space. As a result, linearly interpolating in the latent space yields realistic and smooth musical changes that fit the type of machine--musician interactions we aim for. We provide empirical evidence for our method via a set of experiments on music datasets and we deploy our model for an interactive jam session with a professional drummer. The live performance provides qualitative evidence that the latent representation can be intuitively interpreted and exploited by the drummer to drive the interplay. Beyond the musical application, our approach showcases an instance of human-centred design of machine-learning models, driven by interpretability and the interaction with the end user.
A Survey on Audio Synthesis and Audio-Visual Multimodal Processing
Aug 01, 2021
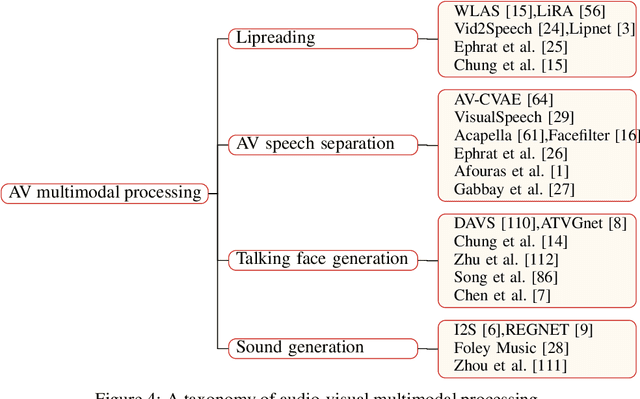
With the development of deep learning and artificial intelligence, audio synthesis has a pivotal role in the area of machine learning and shows strong applicability in the industry. Meanwhile, significant efforts have been dedicated by researchers to handle multimodal tasks at present such as audio-visual multimodal processing. In this paper, we conduct a survey on audio synthesis and audio-visual multimodal processing, which helps understand current research and future trends. This review focuses on text to speech(TTS), music generation and some tasks that combine visual and acoustic information. The corresponding technical methods are comprehensively classified and introduced, and their future development trends are prospected. This survey can provide some guidance for researchers who are interested in the areas like audio synthesis and audio-visual multimodal processing.
Music Composition with Deep Learning: A Review
Sep 07, 2021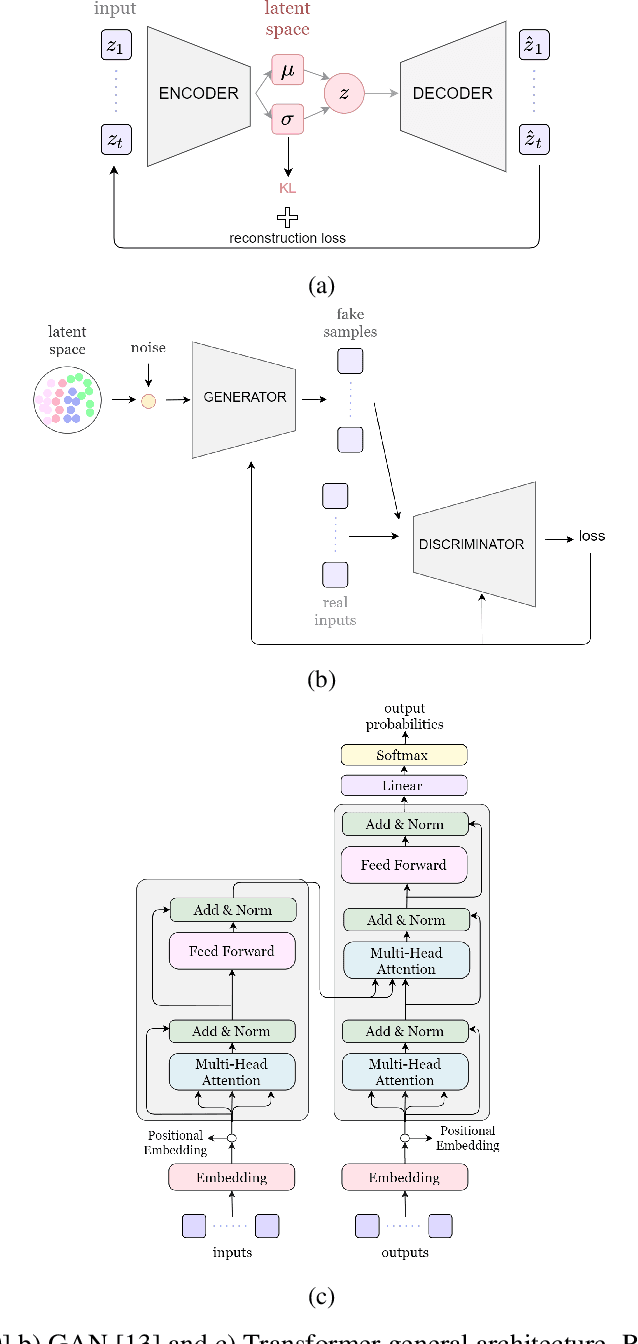
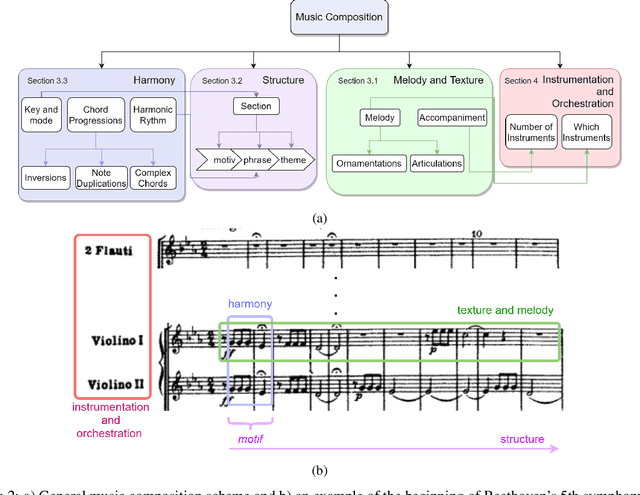
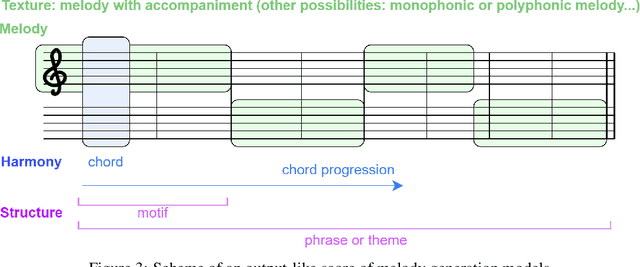
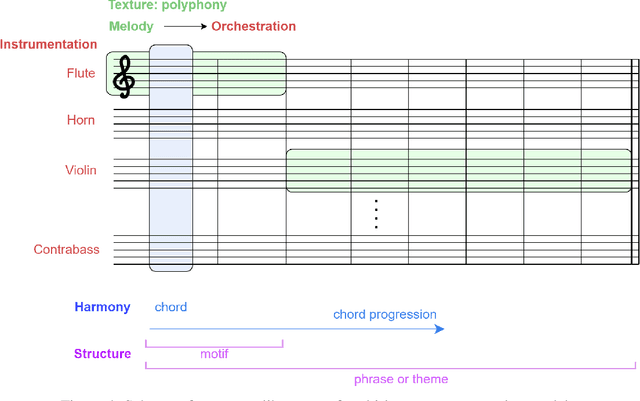
Generating a complex work of art such as a musical composition requires exhibiting true creativity that depends on a variety of factors that are related to the hierarchy of musical language. Music generation have been faced with Algorithmic methods and recently, with Deep Learning models that are being used in other fields such as Computer Vision. In this paper we want to put into context the existing relationships between AI-based music composition models and human musical composition and creativity processes. We give an overview of the recent Deep Learning models for music composition and we compare these models to the music composition process from a theoretical point of view. We have tried to answer some of the most relevant open questions for this task by analyzing the ability of current Deep Learning models to generate music with creativity or the similarity between AI and human composition processes, among others.
A Benchmarking Initiative for Audio-Domain Music Generation Using the Freesound Loop Dataset
Aug 03, 2021
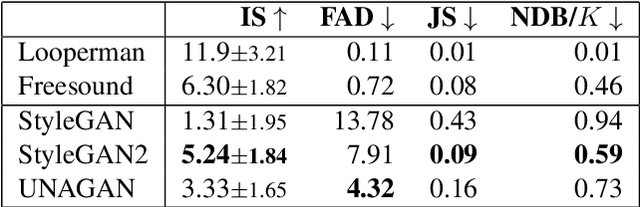
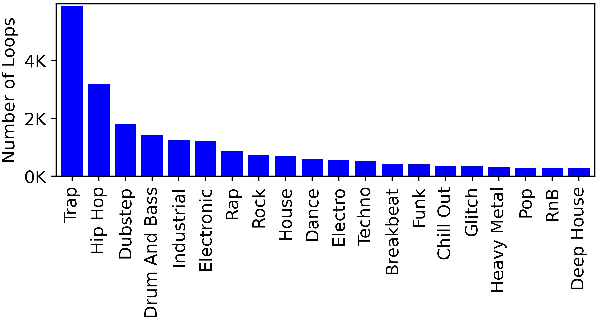

This paper proposes a new benchmark task for generat-ing musical passages in the audio domain by using thedrum loops from the FreeSound Loop Dataset, which arepublicly re-distributable. Moreover, we use a larger col-lection of drum loops from Looperman to establish fourmodel-based objective metrics for evaluation, releasingthese metrics as a library for quantifying and facilitatingthe progress of musical audio generation. Under this eval-uation framework, we benchmark the performance of threerecent deep generative adversarial network (GAN) mod-els we customize to generate loops, including StyleGAN,StyleGAN2, and UNAGAN. We also report a subjectiveevaluation of these models. Our evaluation shows that theone based on StyleGAN2 performs the best in both objec-tive and subjective metrics.
InverseMV: Composing Piano Scores with a Convolutional Video-Music Transformer
Dec 31, 2021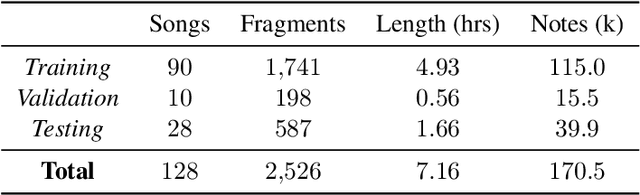
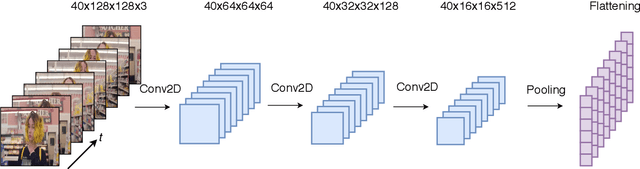
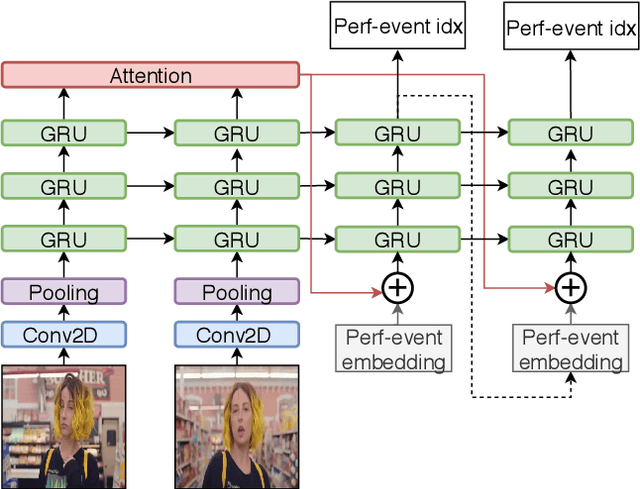
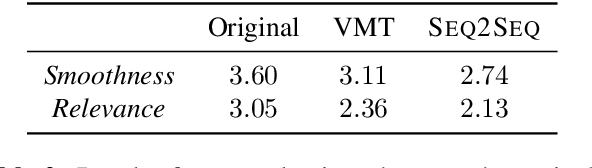
Many social media users prefer consuming content in the form of videos rather than text. However, in order for content creators to produce videos with a high click-through rate, much editing is needed to match the footage to the music. This posts additional challenges for more amateur video makers. Therefore, we propose a novel attention-based model VMT (Video-Music Transformer) that automatically generates piano scores from video frames. Using music generated from models also prevent potential copyright infringements that often come with using existing music. To the best of our knowledge, there is no work besides the proposed VMT that aims to compose music for video. Additionally, there lacks a dataset with aligned video and symbolic music. We release a new dataset composed of over 7 hours of piano scores with fine alignment between pop music videos and MIDI files. We conduct experiments with human evaluation on VMT, SeqSeq model (our baseline), and the original piano version soundtrack. VMT achieves consistent improvements over the baseline on music smoothness and video relevance. In particular, with the relevance scores and our case study, our model has shown the capability of multimodality on frame-level actors' movement for music generation. Our VMT model, along with the new dataset, presents a promising research direction toward composing the matching soundtrack for videos. We have released our code at https://github.com/linchintung/VMT
Pop2Piano : Pop Audio-based Piano Cover Generation
Nov 02, 2022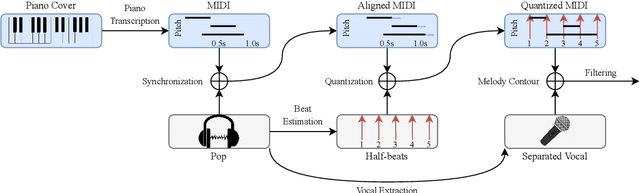

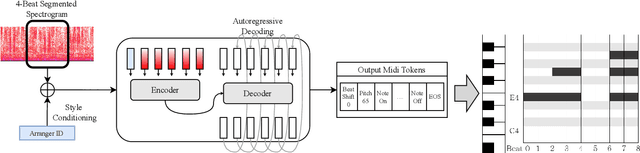
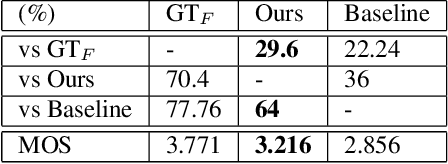
The piano cover of pop music is widely enjoyed by people. However, the generation task of the pop piano cover is still understudied. This is partly due to the lack of synchronized {Pop, Piano Cover} data pairs, which made it challenging to apply the latest data-intensive deep learning-based methods. To leverage the power of the data-driven approach, we make a large amount of paired and synchronized {pop, piano cover} data using an automated pipeline. In this paper, we present Pop2Piano, a Transformer network that generates piano covers given waveforms of pop music. To the best of our knowledge, this is the first model to directly generate a piano cover from pop audio without melody and chord extraction modules. We show that Pop2Piano trained with our dataset can generate plausible piano covers.
Symbolic Music Loop Generation with VQ-VAE
Nov 15, 2021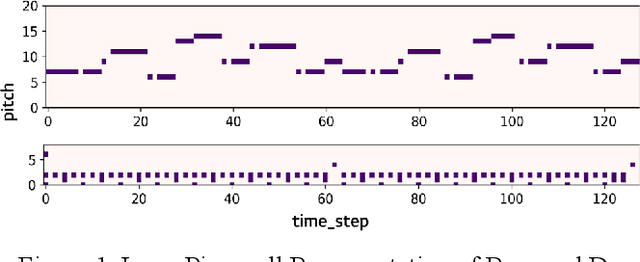
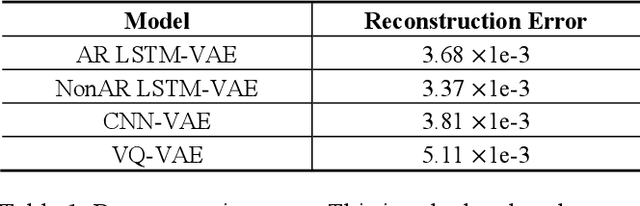
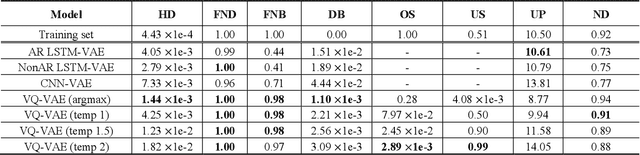
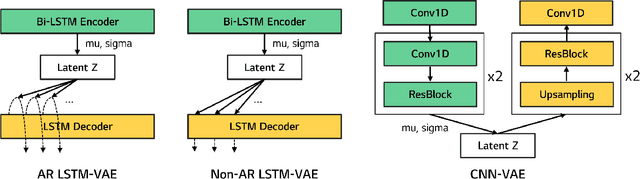
Music is a repetition of patterns and rhythms. It can be composed by repeating a certain number of bars in a structured way. In this paper, the objective is to generate a loop of 8 bars that can be used as a building block of music. Even considering musical diversity, we assume that music patterns familiar to humans can be defined in a finite set. With explicit rules to extract loops from music, we found that discrete representations are sufficient to model symbolic music sequences. Among VAE family, musical properties from VQ-VAE are better observed rather than other models. Further, to emphasize musical structure, we have manipulated discrete latent features to be repetitive so that the properties are more strengthened. Quantitative and qualitative experiments are extensively conducted to verify our assumptions.
LSTM Based Music Generation System
Aug 02, 2019
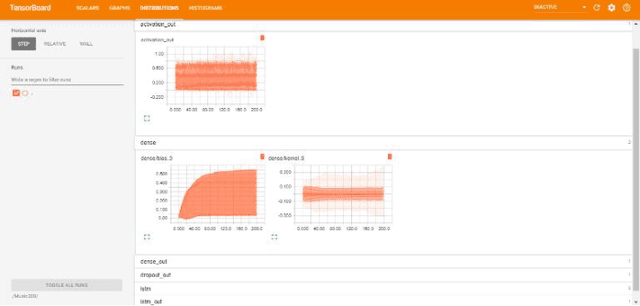
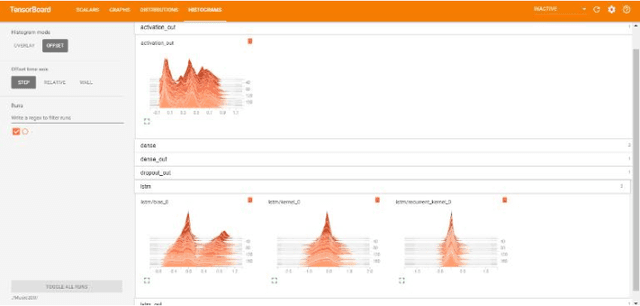
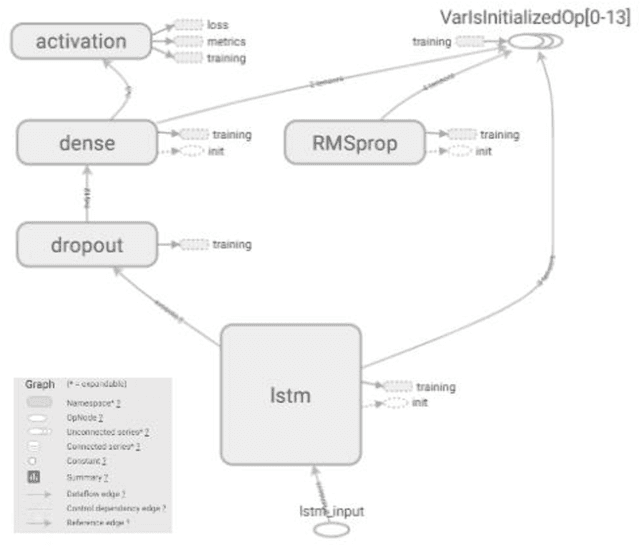
Traditionally, music was treated as an analogue signal and was generated manually. In recent years, music is conspicuous to technology which can generate a suite of music automatically without any human intervention. To accomplish this task, we need to overcome some technical challenges which are discussed descriptively in this paper. A brief introduction about music and its components is provided in the paper along with the citation and analysis of related work accomplished by different authors in this domain. Main objective of this paper is to propose an algorithm which can be used to generate musical notes using Recurrent Neural Networks (RNN), principally Long Short-Term Memory (LSTM) networks. A model is designed to execute this algorithm where data is represented with the help of musical instrument digital interface (MIDI) file format for easier access and better understanding. Preprocessing of data before feeding it into the model, revealing methods to read, process and prepare MIDI files for input are also discussed. The model used in this paper is used to learn the sequences of polyphonic musical notes over a single-layered LSTM network. The model must have the potential to recall past details of a musical sequence and its structure for better learning. Description of layered architecture used in LSTM model and its intertwining connections to develop a neural network is presented in this work. This paper imparts a peek view of distributions of weights and biases in every layer of the model along with a precise representation of losses and accuracy at each step and batches. When the model was thoroughly analyzed, it produced stellar results in composing new melodies.
* 6 pages, 11 figures